누군가(?)의 요청으로 크롤링에 대해서 배우게 됐는데, 나름 공부도 되고 재밌어서 기록으로 남기고자한다!
시작전 준비물!
- BeautifulSoup: 스크래핑을 위해 사용하는 패키지
- 스프래핑: 웹 페이지에서 원하는 데이터를 추출하는 작업
- response.text를 통해 가져온 HTML 문서를 탐색해서 원하는 부분을 뽑아내는 역할을 하는 라이브러리
- lxml: 구문을 분석하기 위한 parser
- response.text는 String 형태이기 때문에 의미있는 HTML 문서로 변환한다.
터미널에서 아래 명령어를 작성하면 기본적인 라이브러리 준비는 끝이난다..!
pip install requests BeautifulSoup4 lxml
그럼 본격적으로 CGV 영화 순위를 가져와보자
import requests
from bs4 import BeautifulSoup
url = "https://www.cgv.co.kr/"
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")response = requesets.get(url) : HTML 문서를 반환받는다.
response.raise_for_status() : HTTP 요청시 상태코드로 결과를 확인한다. → 실패시(400, 500번대) 자동 예외처리
soup = BeautifulSoup(response.text, "html.parser") : resonse.text는 단순 문자열이므로 BeautifulSoup을 사용해 HTML 데이터로 파싱하고 탐색 가능한 형태로 반환받는다.
이렇게 반환받은 soup을 통해서 데이터를 가져올 수 있는데 그전에 CGV에서 어떤 식으로 영화 순위를 가져오는지 확인해야한다 (HTML 구조)
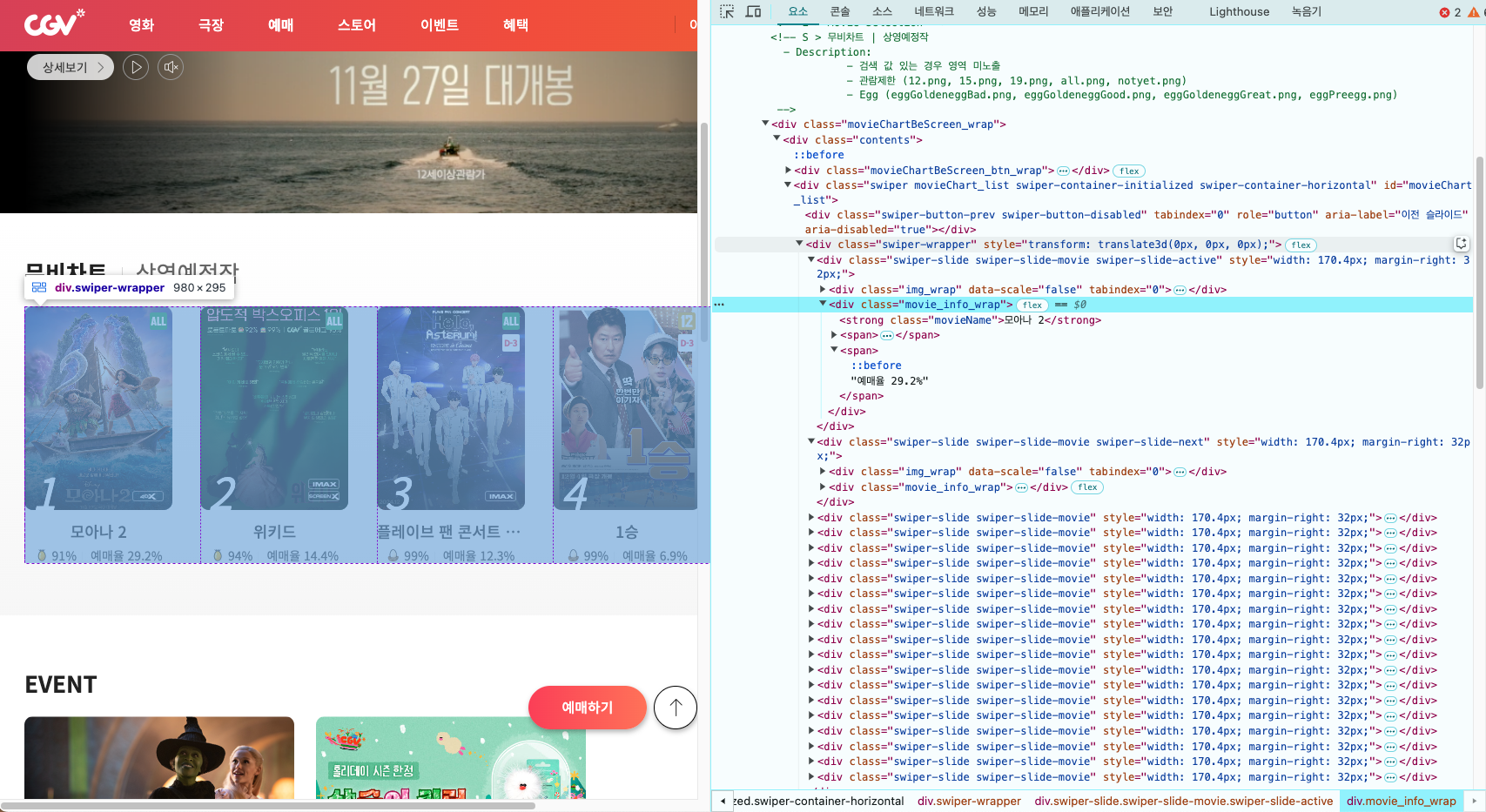
위 사진을 보면 알 수 있듯이 CGV 측에서는 swiper-wrapper라는 큰 틀 안에 영화에 대한 정보를 movie_info_wrap이라는 div안에 관리하고 있는 것을 알 수 있다.
아래는 반복되는 영화 정보의 구조를 가져온 것이다.
<div class="img_wrap" data-scale="false">
<div class="movie_info_wrap">
<strong class="movieName">모아나 2</strong>
<span> <img alt="Golden Egg great"
src="https://img.cgv.co.kr/R2014/images/common/egg/eggGoldenegggreat.png"/> 91%</span>
<span>예매율 30.6%</span>
</div>
</div>위의 구조를 보면 알 수 있듯이 나는 영화 이름과 예매율을 가져오고 싶기때문에 <.strong> 태그와 <.div class="movie_info_wrap"> 내의 <.span> 중 두번째 "예매율"이라는 텍스트가 들어간 공간의 데이터를 가져오면 된다.
자 그럼 모든 준비는 끝났다. 이제 Soup을 통해 데이터를 가져와보자
데이터를 가져오기에 앞서 BeautifulSoup에서 제공하는 메서드들을 살펴보자
- find: 특정 태그로 데이터를 가져올 수 있다.(여러개일 경우 가장 첫번째 태그를 가져온다)
ex)list = soup.find("div", class_ ="swiper-wrapper") - find_all: 특정 태그가 여러개일 경우 리스트로 반환한다.
ex)lists = soup.find("div", class__ ="swiper-wrapper")
위의 기능들을 사용해 데이터를 한번 가져와보자!
코드
import requests
from bs4 import BeautifulSoup
import pandas
url = "https://www.cgv.co.kr/"
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
# list = soup.find("div", class_ ="swiper-wrapper")
lists = soup.find_all("div", class_ ="movie_info_wrap")
idx = 1
movies = []
for list in lists:
# 영화이름
movieName = list.find("strong").text
spans = list.find_all("span")
for span in spans:
if "예매율" in span.text:
movieRate = span.text.replace("예매율","").strip()
movies.append([idx, movieName, movieRate])
idx += 1
for movie in movies:
print(movie)결과
[1, '모아나 2', '29.2%']
[2, '위키드', '14.4%']
[3, '플레이브 팬 콘서트 ‘헬로, 아스테룸!’ 앙코르 인 시네마', '12.3%']
[4, '1승', '6.9%']
[5, '소방관', '5.1%']
[6, '히든페이스', '4.9%']
[7, '원정빌라', '2.3%']
[8, '알엠: 라이트 피플, 롱 플레이스', '2.2%']
[9, '투모로우바이투게더 : 하이퍼포커스 인 시네마', '2.1%']
[10, '청설', '1.7%']
...로 데이터가 잘 들어오는 것을 확인할 수 있다.
참 쉽쥬잉?
