Image and Pixel array
- For computer, image is array of numeric pixel values
Example : 7 x 7 image
0 0 0 0 0 0 0
0 0 0 0 0 0 0
0 0 255 255 255 0 0
0 0 255 255 255 0 0
0 0 255 255 255 0 0
0 0 0 0 0 0 0
0 0 0 0 0 0 0
- For a colored images, we can save each RGB value as array
Red:
150 150 150 150 150 150 150
150 150 150 150 150 150 150
150 150 255 255 255 150 150
150 150 255 255 255 150 150
150 150 255 255 255 150 150
150 150 150 150 150 150 150
150 150 150 150 150 150 150
Green:
0 0 0 0 0 0 0
0 0 0 0 0 0 0
0 0 255 255 255 0 0
0 0 255 255 255 0 0
0 0 255 255 255 0 0
0 0 0 0 0 0 0
0 0 0 0 0 0 0
Blue:
255 255 255 255 255 255 255
255 255 255 255 255 255 255
255 255 0 0 0 255 255
255 255 0 0 0 255 255
255 255 0 0 0 255 255
255 255 255 255 255 255 255
255 255 255 255 255 255 255
Using filter to process image
- common way to perform image processing, apply filter
- Filter is defined by one or more arrays of pixel values, called filter kernel
-1 -1 -1
-1 8 -1
-1 -1 -1- convolves across the image, calculating weight sum of each 3 * 3 patch of pixel, assign the new value to new image
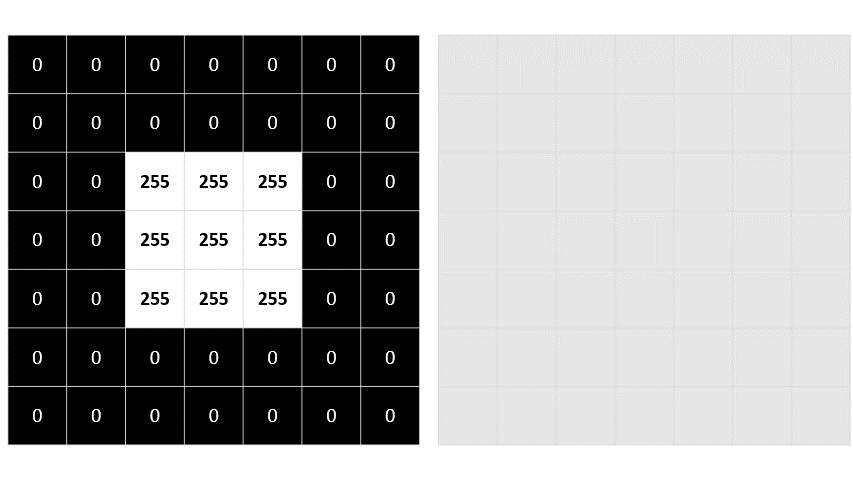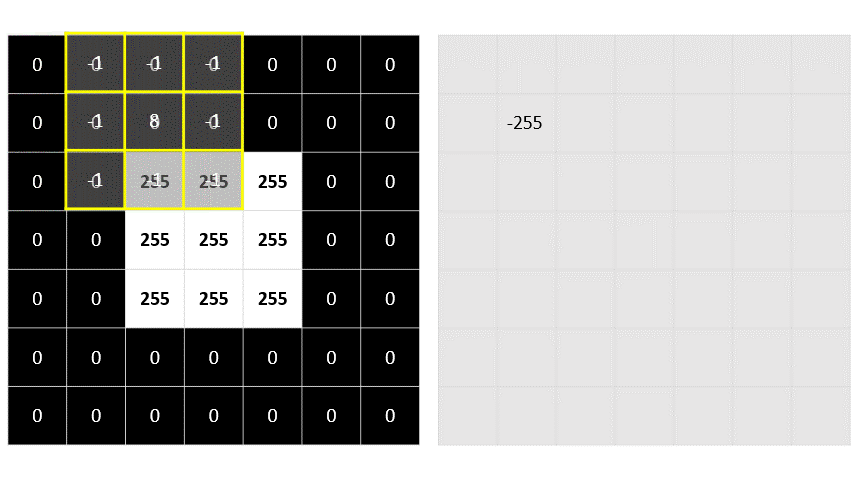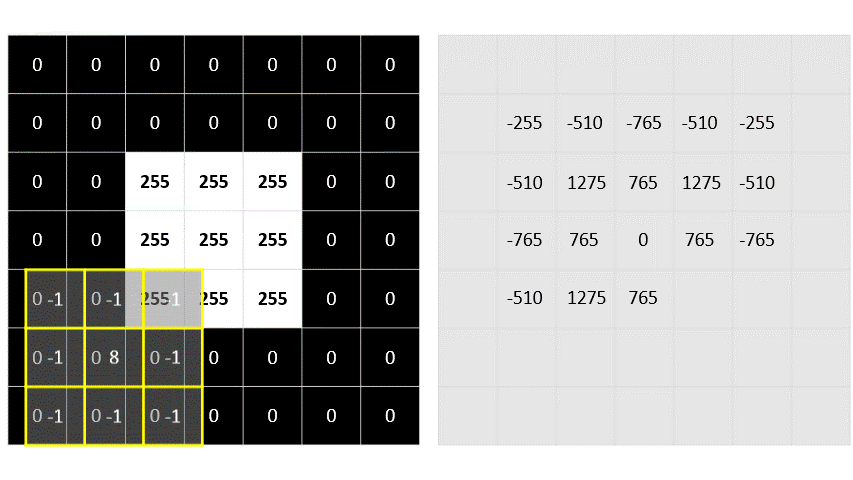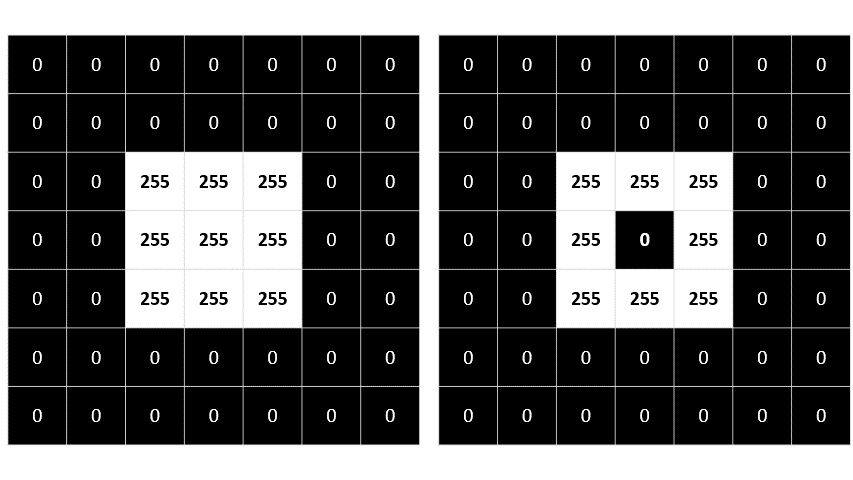
- Calculating a new array of values
- adjust values to fit into 0 ~ 255 range
- not calculated part of image has a padding value (0)
- negative value become 0

- image under same filter, highlights on edges
CNN / Convolutional Neural Network
- filters to extract numeric feaature map from image
- feed the feature values into a deep learning model to generate label prediction
HOW?
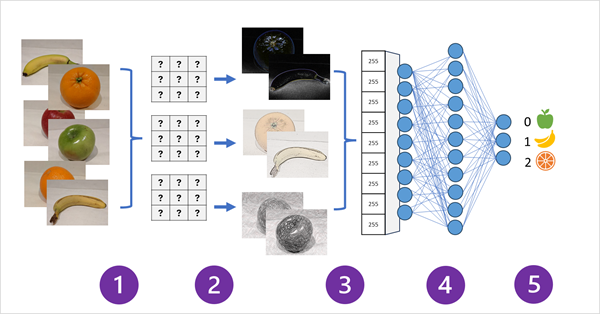
- Images with known labels are fed into the network to train the model
- One or more layers of filters is used to extract features from each image.
The filter kernel starts with randomly assigned weights and generate array of numeric values called feature maps - The feature maps are flattend into a single dimensional array of feature values
- The feature values are fed into a fully connected neural network
- The output layer of the neural network uses a softmax or similar function to produce a result that contains a probability for each possible class
- The score difference with predicted output and actual value is used to calculate the loss of this model
CNN includes multiple convolutional filter, layers to reduce size of feature mapTransformer & multi-modal model
- Processing huge volumes of data, encoding language token as vector-based embeddings
- Embedding : Representing a set of dimensions, each represent some semantic attribute of the token
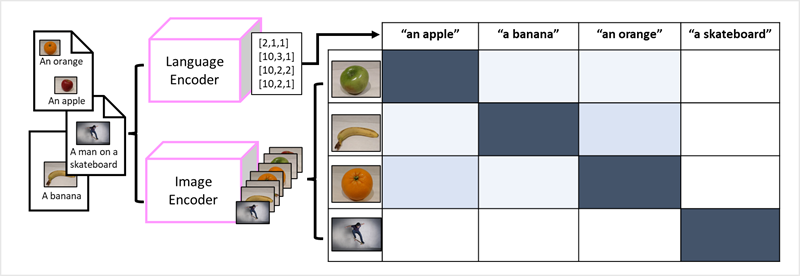
Multi-modal models
- Model is trained using a large volume of captioned images with no fixed labels
- Image encoder extracts features from images bsed on pixel values, combine them with text embeddings created by language encoder
Azure AI Vision
Analyzing image
OCR
- Extract text from image
- Arrange results in following hierarchy
- Pages
- Lines
- Words
- Each line and word includes bounding box coordinates indicating its position on page
Generating captions and descriptions of image
Detection of thousands of common object in images
Tagging visual features in images
Other features
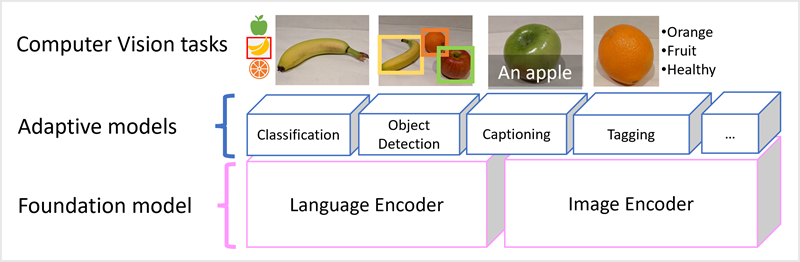
1. Training custom models
- Image classification
- Object detection
Azure AI Face
- include Azure AI Vision, Azure AI Video encoder, Azure AI Face

만능 컴덕후 겸 번지 팬