Lightening (경량화)
- 모델을 가볍고 반응이 빠르게 만듬
Pruning
- 영향이 적은 weight를 삭제하여 파라미터 수를 최소화
- 정확도 손실이 거의 없이 AlexNet 9배, VGG-16 13배의 파라미터 수를 줄임
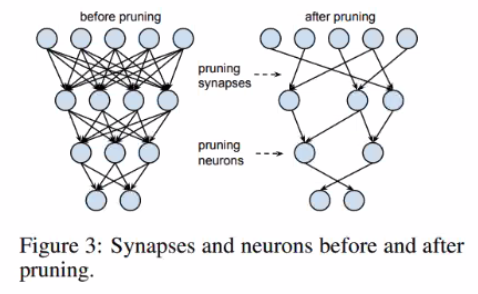
Light weight architecture
- SqueezeNet : Fire Module 구조로 Alexnet 대비 50배 적은 파라미터
- MobileNet: Depthwise Separable Convolution구조를 적절히 사용해 모바일 디바이스에서도 사용 가능할 정도로 경량화
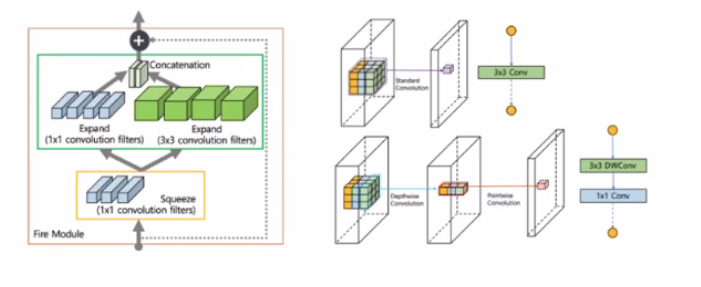
Knowledge Distillation
- 규모가 크고 잘 학습된 네트워크를 활용해 더 작은 네트워크를 학습
- 주로 여러 teacher model들을 ensemble하여 하나의 student 모델을 학습
- 학습할 때 Teacher 모델의 Loss와 Student 모델의 Loss를 동시 반영하는 방법으로 Teacher 모델을 학습에 활용
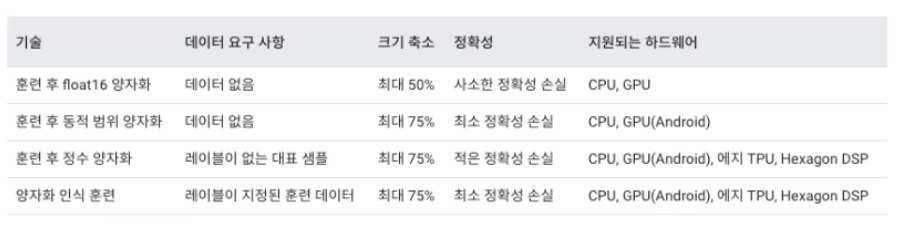
Quantization
-
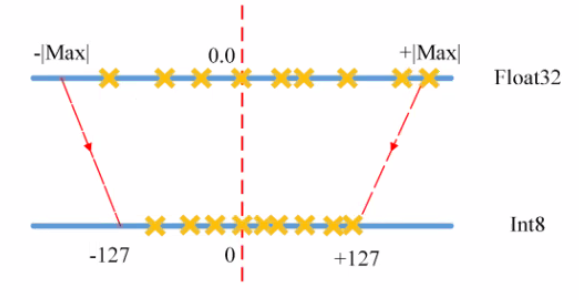
양자화 : 모델의 파라미터를 lower bit로 표현하여, 계산과 메모리 access 속도를 높이는 경량화 기법
-
Post Training Quantization : Training 후 quantize 적용하는 기법
-
Quantization Aware Training : Training 과 정 중에서 quantize 수행, Fake Qunatization Node를 첨가하여 quntize시 어떻게 동작할 시 시뮬레이션 진행
-
Dynamic Quantization: 모델의 weight만 양자화 진행, activations는 추론할 때만 floating-points kernel로 dequantize후, 동적으로 양자화 진행, 모델을 메모리상으로 로딩하는 속도 개선에 적합, 추론 속도 향상은 미비함
-
Static Quantization : 모델의 weight, activations 모두 양자화를 사전에 진행함, Weight와 Activations를 fusion시킴, Representative Dataset을 통해 Calibration 진행, Activation 설정 및 정확도 손실 최소화, 연산속도 향상, 추론에 Activations가 영향이 큰 CNN 모델 계열에서 적합함
-
Quantization aware training : 학습 중에 모델의 weight, activations를 양자화 진행
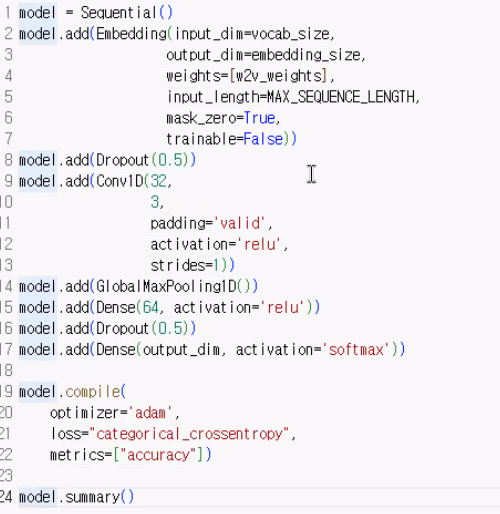
자연어 처리 cnn

한걸음씩 배워나갑니다