
1. INTRODUCTION
1-1. Basic Definitions
What is “data”?
- Known facts that can be recorded and have an implicit meaning. • E.g., Names, phone numbers, and addresses of your acquaintances
What is “database” (DB)?- A(n) (organized) collection of related data
Data Base Management System (DBMS)?- A “software package/system” to enable users to create and maintain a database: e.g. Oracle, MySQL, ...
Database system?- DB + DBMS (+ DB Applications)
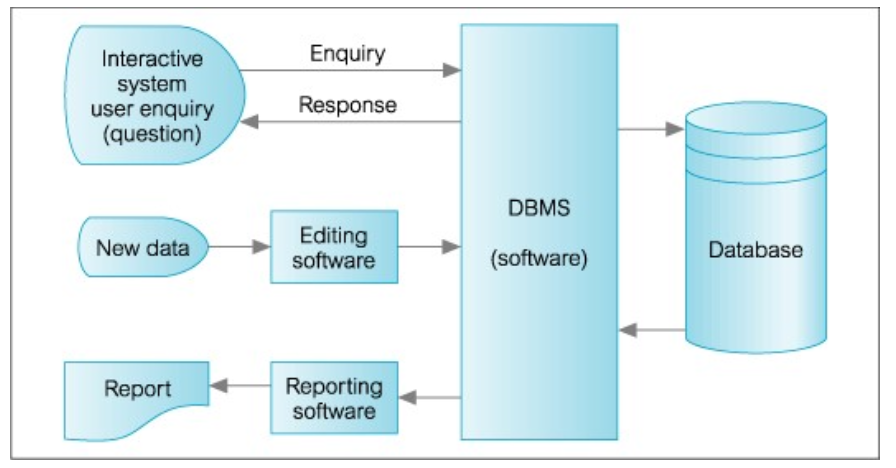
1-2. Types of Databases and Database Applications
Traditional Applications
- Numeric and Textual Databases : mainly used in financial/banking, reservation, library systems, etc.
More Recent Applications
- Multimedia Databases: e.g. images, audio clips, video streams
- Geographic Info. Syst. (GIS): e.g. maps, weather data, satellite images
- Biological and Genome Databases: e.g. DNA Sequencing
- Data Warehouses: e.g. Business decision-making
- Mobile Databases: e.g. Data on mobile computing devices over network
- Real-time/IIoT Databases: e.g. Industrial/manufacturing process control
- Active Databases: event-driven architecture (with Event-Condition- Action rules)
- Database search: e.g. Web search via browser
1-3. Impact of DBs and DB Technology
Businesses, Service Industries, Education, More recent applications (Social Networks ... ), Personalized Applications (Based on smart mobile devices, in which databases ard embedded)
1-4. Recent Developments
- 지난 몇년 간 Social media Websites (e.g., Facebook, Twitter, LinkedIn ...)이 nontraditional data(posts, tweets, images ...) 등의 저장이 필요해지면서 big data storage systems or NoSQL이 선호되기 시작했다.
- Google, Amazon, Yahoo 등 또한 그들의 검색 엔진에 필요한 데이터를 관리하기 위해 이러한 타입의 시스템을 사용한다.
1-4-1. NoSQL DB
• NoSQL is a term used for a broad group of data management technologies varying in features and functionality
• An SQL database is concrete concept, but NoSQL is NOT.
Features
• High performance writes and massive scalability:
E.g., MongoDB, Elasticsearch, Cassandra
• Do not require a defined schema for writing data; See the next slide.
• Primarily eventually-consistent by default
• Support of wide range of modern programming languages (Python, Scala, Go, ...) and tools
• Support of fault tolerance; typically, distributed computing
Example
MongoDB
- Uses the document data model

[Source : MongoDB_Architecture_Guide.pdf]
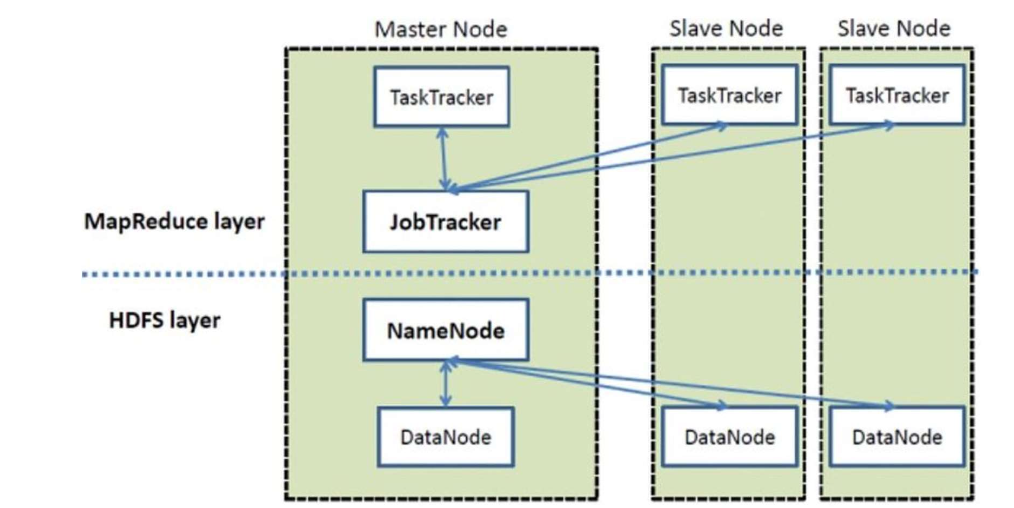
1-4-2. Hadoop
Actual Impletmetation of MapReduce Programming Model for Big Data Processing
[Source : https://www.edureka.co/blog/mapreduce-tutorial/]
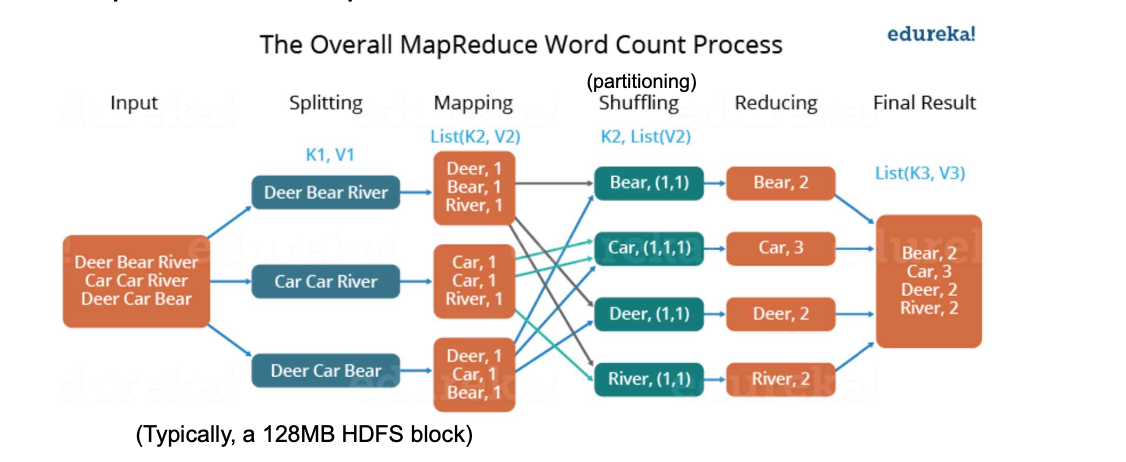
Features
- High-level Technical Architecture
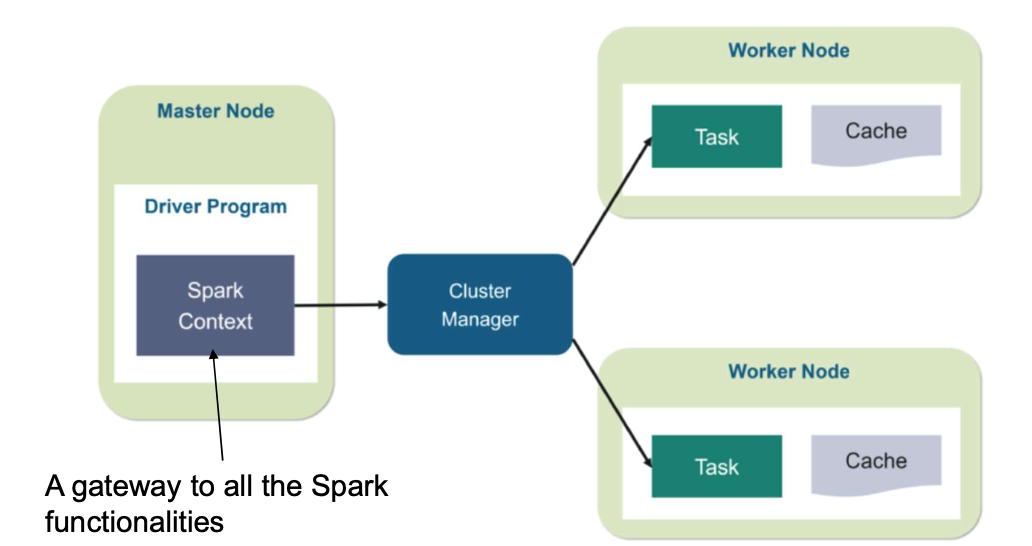
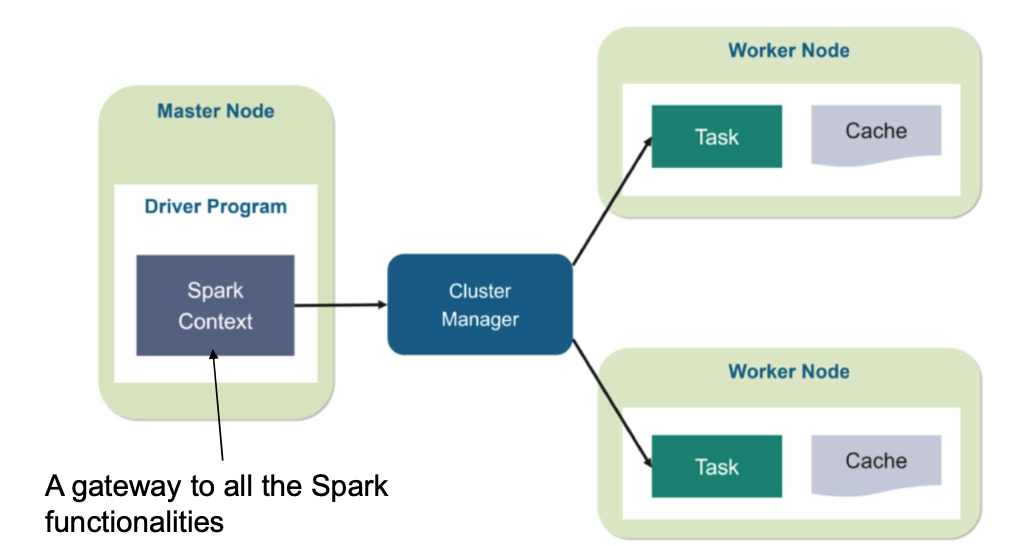
1-4-3. Apache Spark
Architecture
1-4-4. Example) Big Data Analytics Arch
For road situation collection/analysis/diagnosis
2. DATABASE SYSTEM ENVIRONMENT
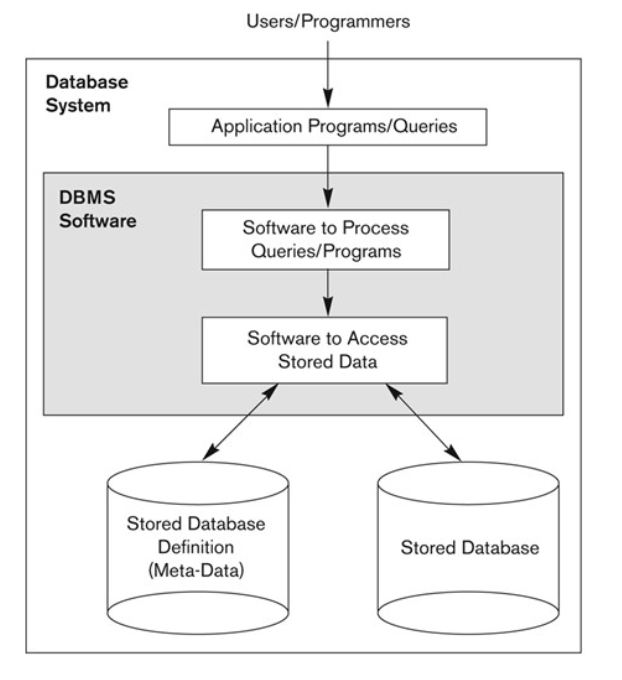
2-1. A "Simplified" Database System Environment
1) Applications interact with a DB by generating:
Query: typically causes some data to be retrieved
Transaction: may cause some data to be read and/or to be written into the database atomically
2) Applications must not allow unauthorized users to access data: provide data protection.
3) Applications must keep up with changing user requirements against the DB; ex) password policy change, authorization change
2-2. Typical DBMS Functionality
- DB의 특정 데이터 유형, 구조, 및 제약 조건을 정의하는 것
- 초기 DB 콘텐츠를 secondary storage medium(HDD, SSD)에 물리적으로 생성하거나 로드하는 것
- Manipulating the database:
- Retrieval : Querying, generating reports
- Modification : Insertions, deletions and updates to its content
- Access : Having access to the database through Web applications
- 모든 Data는 유효성과 일관성은 유지하면서, 동시 사용자와 application programs의 집합 단위로 processing AND sharing을 수행한다.
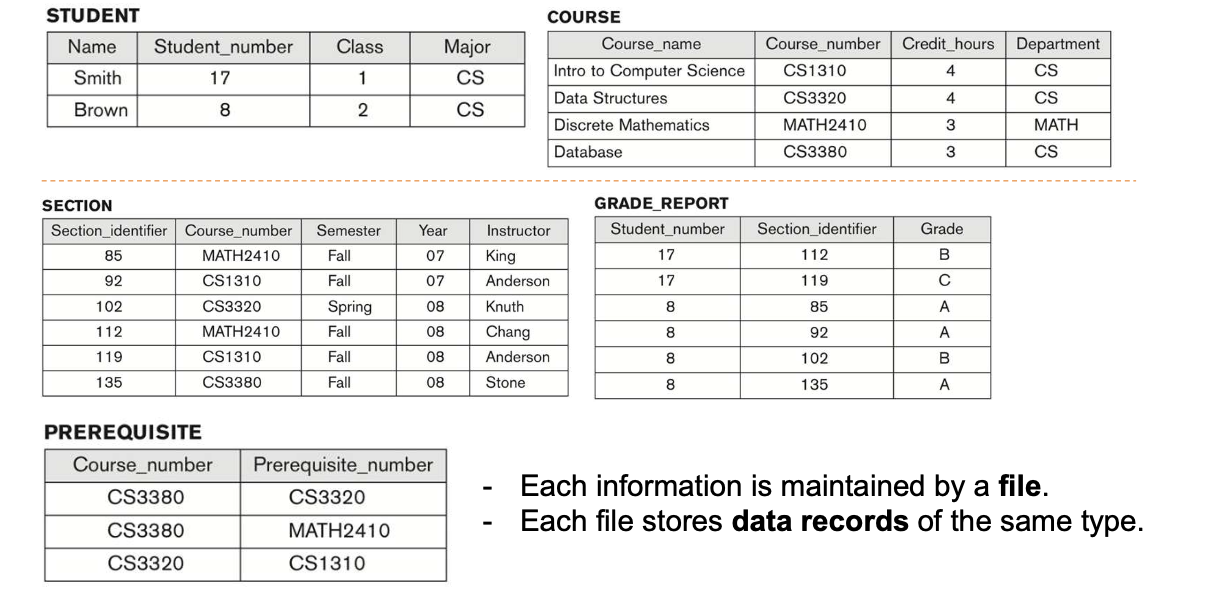
2-3. Example of a Database (with a Conceptual Data Model)
- Mini-world for the example
Like a University environment


위에 표시한 'Entities'와 'Relationships'는 입란적으로 Conceptual data model에 표현된다.
Consider a UNIVERSITY (relational) database
2-4. Database Design Phases
- Design of a new application for and existing database or design of a brand new database needs the following stages:
- Stage 1: Requirement specification and analysis
- Stage 2: Conceptual design (for easily being transformed into a database implementation)
- Stage 3: Logical design (for a data model implemented in a DBMS)
- Stage 4: Physical design (for storing and accessing the database)
3. MAIN CHARACTERISTICS OF THE DATABASE APPROACH
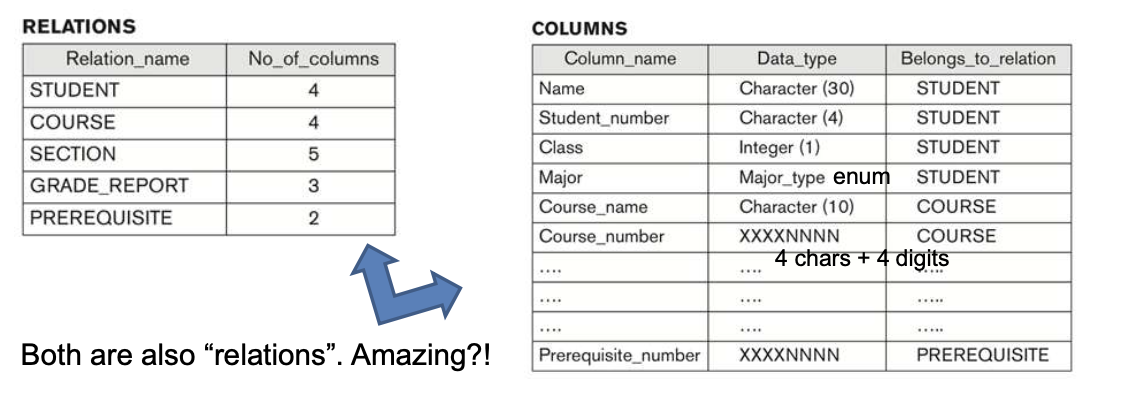
3-1. Self-describing nature of a DB system
- DB System은 DB 자체뿐만 아니라 DB Structure, types, constraints를 포함한다.
- Catalog : stores the description, called metadata, of a particular DB
That said, some newest systems (a few NoSQL ones: MongoDB, Cassandra, Redis) don’t need metadata.
Why?
-> They store the data definition within its structure so that it makes it self-describing (e.g. ‘key’ : ‘value’)
3-2-1. Insulation between programs and data
Called program-data indepence
- DBMS Access program에서 변경하지 않고 데이터 구조 및 저장 구성을 변경할 수 있게 한다.
- In file-processing systems, you “have to” change your program if the structure of a file accessed by the program gets altered.
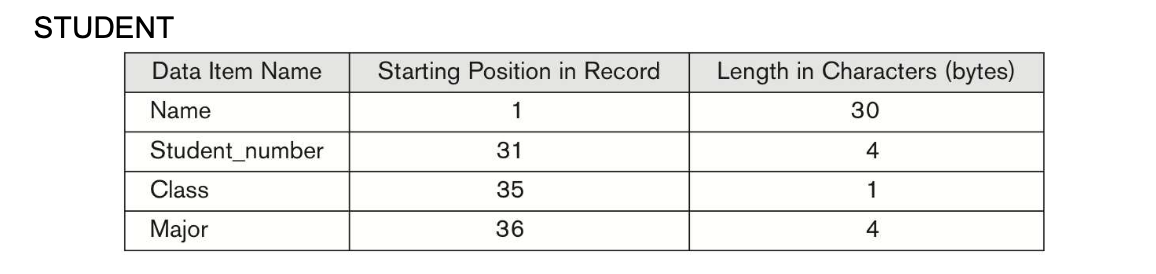
Whay if you try to insert a Birth_Date attribute in the STUDENT record ?
-> Starting Position in Record : 40
If, you want to use VARCHAR, 한국의 주민 번호 기준 980509 -> 6 bytes
3-2.2. Data abstraction
- program-data와 program-operation(on objects) independence를 허용해주는 특성
- Data model의 비공식적인 정의: data 추상화의 한 유형
- storage details를 숨기고 conceptual view of the DB를 users에게 보여주기 위해 사용
- Data가 어떻게 저장되고 접근되는지는 알 필요가 없다. -> Declarative property
- Application programs는 data storage 세부 정보가 아닌 data model 구성을 참조한다.
3-3. Support of multiple views of the data
- Each user may see a different view(or, a virtual data) of the DBMS
- Then, 각 유저는 해당 유저가 관심있는 Data만을 보고 싶어한다.
- EX1) 한 사용자는 각 학생의 수강신청 내용을 확인하고 출력하는 데 관심이 있을 수 있다.
- EX2) 다른 사용자는 각 학생이 수강 신청한 각 과목의 선수과목을 모두 이수했는지 확인하는 데만 관심이 있을 수 있다.
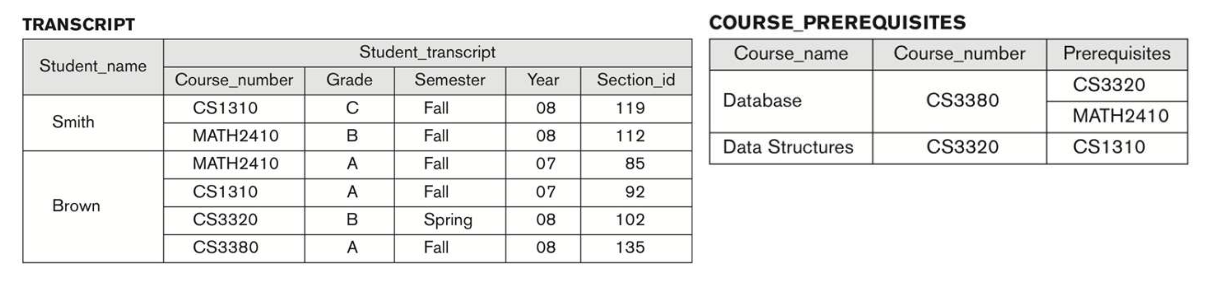
3-4. Sharing of data and multiuser transaction processing
- concurrent users의 집합이 DB로부터 데이터를 검색하고 DB를 갱신하는 것을 가능하게 한다.
E.g. U1(read) - U2(write) - U3(read) - U4(update) ...- DBMS의 Concurrency control(동시성 제어)은 각 transaction이 정상적인 경우에는 정확하게 실행되고, 이상이 있는 경우에는 중단되도록 보장한다.
- Transaction: DB 접근을 포함하는 일련의 statements로 구성되어 실행중인 프로그램이나 프로세스
- ACID (Atomicity, Consistency, Isolation, Durability) 특성을 만족해야 한다.
- Recovery subsystem은 완료된 각 transaction이 DB에 영구적으로 기록되는 것을 보장한다.
- OLTP (OnLine Transaction Processing)은 DB application이 주요 파트이다.
- 매 초단위로 수 백개의 동시적인 transactions가 실행되도록 한다.
- E.g. airline/train reservation, stock market, class reg, etc...
4. ADVANTAGES OF USING THE DB APPROACH
4-1. Controlling redundancy
- 중복을 제어함 : 데이터 중복을 효과적으로 관리 가능
- 데이터 저장 및 개발/유지 관리하는 노력을 절약할 수 있다.
- UNIVERSITY DB와 같이 여러 사용자 그룹이 공유하는 경우, 예를 들어 수강신청 담당자와 회계부에서 사용하는 데이터베이스를 고려해보자.
- 이상적으로, 데이터베이스 설계는 각 논리 데이터 항목(예: 학생의 이름 또는 생년월일)을 데이터베이스 내에서 한 곳에만 저장해야 한다. 이것을 데이터 정규화라고 한다.
4-2. Restricting un authorized access
- 권한이 없는 접근을 제한함 : 무단 엑세스를 방지
- E.g. 기밀적인 금융 데이터, 읽기 및 업데이트
- DBMS는 보안 및 권한 하위 시스템을 제공해야 한다.
- DBA Staff만이 해당 시스템을 이ㅣ용하여 privileged commands와 facilities를 통해 계정 생성 및 계정 제한을 지정할 수 있다.
4-3. Providing persistent storage for program objects
- 객체의 영속적 저장
- Object-oriented DBMS는 Program object(wirtten in C++ OR Jave)를 영구화할 수 있다.
- Impedance mismatch problem: DBMS에서 제공되는 데이터 구조가 프로그래밍 언어의 데이터 구조와 incompatible한 문제를 의미한다.
- 이러한 문제점은 OODBMS(BLOB, CLOB)를 통해 해결된다.
4-4. Providing storage structures (e.g., indexes) for efficient query processing
- 효율적 질의 처리를 위한 저장 구조(E.g. Indexes) 제공
- 주어진 쿼리와 일치하는 대상 record의 디스크 검색의 속도를 향상하기 위함
- DBMS는 효율적인 search를 위해 indexes (보조 파일 저장)을 활용한다.
- tree-based or hash-basedsms disk-block에 optimized
- DB는 스스로의 buffering/caching을 사용할 수 있다.
- Why not OS's one?
- 1K buffer page를 사용하여 1M disk block을 스캔하는 경우 sequeential Flooding 발생
4-5. Besides, a lot of benefits
- 효율적인 처리를 위한 query 최적화
- Catastrophic disaster(재해)를 피하기 위한 Backup AND Recovery Service 지원
- 다양한 Class를 위한 여러 Interface 지원 (E.g. mobile users, causal users ...)
- Data 간의 복잡한 Relationship 표현
- DB의 일관성 및 무결성을 위해 무결성 제약 조건 적용
- 참조 무결성 제약 조건: Section 레코드와 관련된 Course 레코드
- 고유 무결성 제약 조건: Course 번호/학기/Section 번호 => Unique
- 저장된 데이터로부터 추론과 작업을 수행하기 위해 귀납 및 액티브 규칙 및 Trigger 사용
- Trigger : table의 갱신으로 인해 동작되는 규칙의 한 형태로서, 다른 tables에 대한 추가적인 operations를 수행한다.
- E.g. 학생이 휴학 또는 퇴학하는 경우
- 특정 테이블에 INSERT, DELETE, UPDATE 같은 DML 문이 수행되었을 때, DB에서 자동으로 동작하도록 작성된 프로그램
- 사용자가 직접 호출하는 것이 아니라, DB에서 자동적으로 호출하는 것이 가장 큰 특징
5. WHEN NOT TO USE A DBMS
5-1. The overhead costs of using a DBMS
- 초기 투자 비용이 높다. (HW, SW, Training ... )
- Oracle Enterprise Edition 라이센스 비용: $47,500 (클러스터 머신 당)
- DBMS가 데이터 정의와 처리를 위해 제공하는 generality
- Overhead for providing security, concurrency control, recovery, and
integrity functions
5-2. When a DBMS may be unnecessary
- 데이터베이스와 응용 프로그램이 간단 or 명확하게 정의되어서 전혀 변경되지 않을 것으로 예상될 때
- No multiple-user access to data
5-3. When running a DBMS may not be possible
- 저자 용량이 제한된 Embedded system에서, 일반 목적의 DBMS가 맞지 않을 경우, SQLite와 같은 경량 데이터베이스를 고려
5-4. When no general-purpose DBMS may be necessary
-
어떤 응용 프로그램의 엄격한 real-time 요구를 DBMS의 Overhead때문에 만족하지 못할 때
- communication & switching systems like AT&T
- quick access and routing of calls을 위해 hierarchically organized data로 구성된 매우 빠르게 실행되는 특수 Software를 이미 보유하고 있음.
-
Modeling limitations으로 인해 DB system이 data의 Complexity를 처리할 수 없는 경우
-
E.g. 복잡한 유전체 및 단백질 데이터베이스
-
DBMS에서 지원하지 않는 특별한 작업이 필요한 경우 (예: GIS 및 위치 기반 서비스),
- 결과적으로 R-tree 인덱스를 사용하는 공간 DBMS를 사용하는 경우
Reference
Database System Concepts | Abraham Silberschatz
데이터베이스 시스템 7th edition
