1. send & recv 입출력 함수
1-1. 리눅스에서의 send & recv
리눅스 기반에서 send & recv 함수를 소개하겠다.
이는 window에서의 함수와 똑같다. 하지만 필자는 블로그에서 window 환경에서의 프로그래밍을 다루지 않았기 때문에 마찬가지로 리눅스를 중점으로 설명하겠다.
send
#include <sys/socket.h>
ssize_t send(int sockfd, const void *buf, size_t nbytes, int flags);
// 성공 시 전송된 바이트 수, 실패 시 -1 반환
/*
sockfd : 데이터 전송 대상과의 연결을 의미하는 소켓의 파일 디스크립터 전달
buf : 전송할 데이터를 저장하고 있는 버퍼의 주소 값 전달
nbytes : 전송할 바이트 수 전달
flags : 데이터 전송 시 적용할 다양한 옵션 정보 전달
*/recv
#include <sys/socket.h>
ssize_t recv(int sockfd, const void * buf, size_t nbytes, int flags);
//성공 시 수신한 바이트 수(단 EOF 전송 시 0), 실패 시 -1 반환
/*
sockfd : 데이터 수신 대상과의 연결을 의미하는 소켓의 파일 디스크립터 전달
buf : 수신된 데이터를 저장할 버퍼의 주소 값 전달
nbytes : 수신할 수 있는 최대 바이트 수 전달
flasg : 데이터 수신 시 적용할 다양한 옵션 정보 전달
*/윈도우와 선언된 자료형의 이름만 다를 뿐 나머지는 완전히 동일하다.
send와 recv 함수의 마지막 매개변수에는 데이터 송수신시 적용할 옵션정보가 전달된다.
그런데 옵션정보는 비트 OR 연산자(| 연산자)를 이용해서 둘 이상을 함께 전달할 수 있다.
다음은 매개변수에 전달할 수 있는 옵션의 정보와 그 의미이다.

1-2. MSG_OOB : 긴급 메시지의 전송
옵션 MSG_OOB는 'Out-of-band data'라 불리는 긴급 메시지의 전송에 사용된다.
간단하게 응급실을 생각해보자.
응급환자가 발생시에 기존에 대기하고 있는 환자들에게 양해를 구하고 먼저 진료를 봐야한다.
이러한 문제점 때문에 응급실이 별도로 존재한다.
즉, 긴급으로 무엇인가를 처리할 때는 처리방법 및 경로가 달라야 한다.
이렇듯 MSG_OOB는 긴급으로 전송할 메시지가 있어서 메시지의 전송방법 및 경로를 달리하고자 할 때 사용된다.
간단한 MSG_OOB 사용법을 코드를 통해 설명해보겠다.
1-2-1. oob_send
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#define BUF_SIZE 30
void error_handling(char *message);
int main(int argc, char *argv[]){
int sock;
struct sockaddr_in recv_adr;
if(argc!=3){
printf("Usage : %s <IP> <port>\n", argv[0]);
exit(1);
}
sock = socket(PF_INET, SOCK_STREAM, 0);
memset(&recv_adr, 0, sizeof(recv_adr));
recv_adr.sin_family = AF_INET;
recv_adr.sin_addr.s_addr = inet_addr(argv[1]);
recv_adr.sin_port = htons(atoi(argv[2]));
if(connect(sock, (struct sockaddr*)&recv_adr, sizeof(recv_adr)) == -1)
error_handling("connect() error!");
write(sock, "123", strlen("123"));
send(sock, "4", strlen("4"), MSG_OOB);
write(sock, "567", strlen("567"));
send(sock, "890", strlen("890"), MSG_OOB);
close(sock);
return 0;
}
void error_handling(char *message){
fputs(message, stderr);
fputc('\n', stderr);
exit(1);
}
- 여기서 send 함수를 통해 "4"와 "890"을 긴급 메시지로 전송하고 있다.
일반적은 수신이라면 123 4 567 890이지만 4와 890을 긴급으로 송신하였으니 도착순서에 변화가 생겼다고 예상을 해보자.
1-2-2. oob_recv
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <signal.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <fcntl.h>
#define BUF_SIZE 30
void error_handling(char *message);
void urg_handler(int signo);
int acpt_sock;
int recv_sock;
int main(int argc, char *argv[])
{
struct sockaddr_in recv_adr, serv_adr;
int str_len, state;
socklen_t serv_adr_sz;
struct sigaction act;
char buf[BUF_SIZE];
if(argc!=2) {
printf("Usage : %s <port>\n", argv[0]);
exit(1);
}
act.sa_handler=urg_handler;
sigemptyset(&act.sa_mask);
act.sa_flags=0;
acpt_sock=socket(PF_INET, SOCK_STREAM, 0);
memset(&recv_adr, 0, sizeof(recv_adr));
recv_adr.sin_family=AF_INET;
recv_adr.sin_addr.s_addr=htonl(INADDR_ANY);
recv_adr.sin_port=htons(atoi(argv[1]));
if(bind(acpt_sock, (struct sockaddr*)&recv_adr, sizeof(recv_adr))==-1)
error_handling("bind() error");
listen(acpt_sock, 5);
serv_adr_sz=sizeof(serv_adr);
recv_sock=accept(acpt_sock, (struct sockaddr*)&serv_adr, &serv_adr_sz);
fcntl(recv_sock, F_SETOWN, getpid());
state=sigaction(SIGURG, &act, 0);
while((str_len=recv(recv_sock, buf, sizeof(buf), 0))!= 0)
{
if(str_len==-1)
continue;
buf[str_len]=0;
puts(buf);
}
close(recv_sock);
close(acpt_sock);
return 0;
}
void urg_handler(int signo)
{
int str_len;
char buf[BUF_SIZE];
str_len=recv(recv_sock, buf, sizeof(buf)-1, MSG_OOB);
buf[str_len]=0;
printf("Urgent message: %s \n", buf);
}
void error_handling(char *message)
{
fputs(message, stderr);
fputc('\n', stderr);
exit(1);
}- 29행과 47행에 urg_handler를 등록한 모습을 보자.
MSG_OOB의 긴급 메시지를 수신하게 되면, OS는 SIGURG 시그널을 발생시켜서 프로세스가 등록한 시그널 핸들러가 호출되게 한다. 여기서 주의깊게 볼 점은 시그널이 발생했을 때 일어나는 동작을 구현한 urg_handler를 보자. 여기서 긴급메시지를 처리하기 위해 recv 함수를 호출하여 MSG_OOB 옵션을 주는 것을 볼 수 있다. - 지금까지 본 적 없던 fcntl 함수가 호출되었다.
이 함수는 쉽게 말하면 파일 디스크립터의 컨트롤에 사용된다.
즉, 위 상황에서는 "파일 디스크립터 recv_sock이 가리키는 소켓에 의해 발생하는 SIGURG 시그널을 처리하는 프로세스를 getpid 함수가 반환하는 ID의 프로세스로 변경시키겠다" 이다.
사실 필자는 위에 말이 이해가 가지 않았다.
그래서 코드를 뜯어보고 검색해보고 하며 필자가 이해한 바는 다음과 같다.
송신하는 측에서 MSG_OOB를 통해 긴급메시지를 보낸다고 하자.
그러면 송신받는 프로세스는 SIGURG 시그널이 발생했다는 것을 알고 SIGURG 시그널의 핸들러 함수를 호출해야 한다.
그런데 만약 송신하는 프로세스와 통신하는 소켓의 파일 디스크립터를 가진 프로세스가 한 개가 아니라 여러 개라면 어떻겠는가 ? 프로세스마다 SIGURG 시그널의 핸들러 함수가 다르다면 원하는 결과를 얻지 못할 뿐 아니라 여러 문제가 생길 수 있다.
이러한 경우는 쉽게 발생할 수 있다. 예를 들어 fork() 함수 호출을 통해 파일 디스크립터가 복사되는 경우를 생각해보자.
즉, 이러한 상황에서 SIGUSR 시그널 발생시 어느 프로세스의 핸들러 함수를 호출해야 하는지 SIGURG 시그널을 핸들링 할 때에는 반드시 시그널을 처리할 프로세스를 지정해 줘야 한다.
그래서 fcntl 함수에 인자로 getpid()를 통해 이 함수를 호출할 프로세스의 ID를 반환하여 현재 실행중인 프로세스를 SIGURG 시그널을 처리하는 주체로 만들어주는 것이다.
틀린 내용이 있을 수 있습니다. 혹시나 틀린 내용이 있다면 댓글로 알려주세요 !!
실행 결과
실행 결과를 부면 우리가 oob_send 함수를 작성하며 예상했던 결과와 다르다.
분명 긴급 메시지 전송이라고 했는데 왜 1byte의 문자열만 수신이 되었을까 ?
그리고 해당 실행 결과는 urgent message가 빠르게 수신된 것 처럼 보이지만,
OS에 따라 순서가 다르게 나올 수 있다.
필자는 MAC OS에서 실행하였는데, 이 또한 긴급 메시지의 상황을 보여주기 위해 계속해서 try 한 것이고 Urgent message의 순서는 뒤죽박죽 나왔다.

- MSG_OOB 옵션을 추가한다고 해서 더 빨리 데이터가 전송되는 것도 아니고, 시그널 핸들러를 통해 읽은 데이터도 1byte밖에 되지 않는다.
나머지 MSG_OOB 옵션이 추가되지 않은 일반적인 입력함수의 호출을 통해서 읽히고 만다. - 이유는 TCP에는 진정한 의미의 'Out-Of-band data'가 존재하지 않기 때문이다.
진정한 의미의 Out-of-band 형태로 데이터가 전송되려면 별도의 통신 경로가 확보되어서 고속으로 데이터가 전달되어야 한다. 하지만 TCP는 알다시피 별도의 통신 경로를 제공하지 않는다.
다만 TCP에 존재하는 Urgent mode라는 것을 이용해서 데이터를 전송해줄 뿐이다.
1-3. Urgent mode의 동작원리
먼저 MSG_OOB의 진정한 의미를 설명하고 Urgent mode을 설명하겠다.
MSG_OOB는 다음과 같은 효과를 가져다 준다.
"긴급으로 처리해야 할 데이터가 들어갔으니 지체하지마라"
즉, 데이터를 수신하는 대상에게 데이터의 처리를 독촉하는데 MSG_OOB의 진정한 의미가 있다.
이것이 전부이고 데이터의 전송에는 "전송 순서가 그대로 유지된다"라는 TCP의 전송특성은 유지된다.
빠르게 처리해야할 데이터가 있음을 알려주는 역할만 하고 그것을 빠르게 처리하는 프로그램을 코딩하는 것은 순전히 개발자의 몫이다.
그럼 MSG_OOB 옵션이 설정된 상태에서의 데이터 전송 과정을 간단히 설명해보겠다.
send(sock, "890", strlen("890"), MSG_OOB);
위와 같은 함수 호출 후 출력 버퍼의 상황이다.
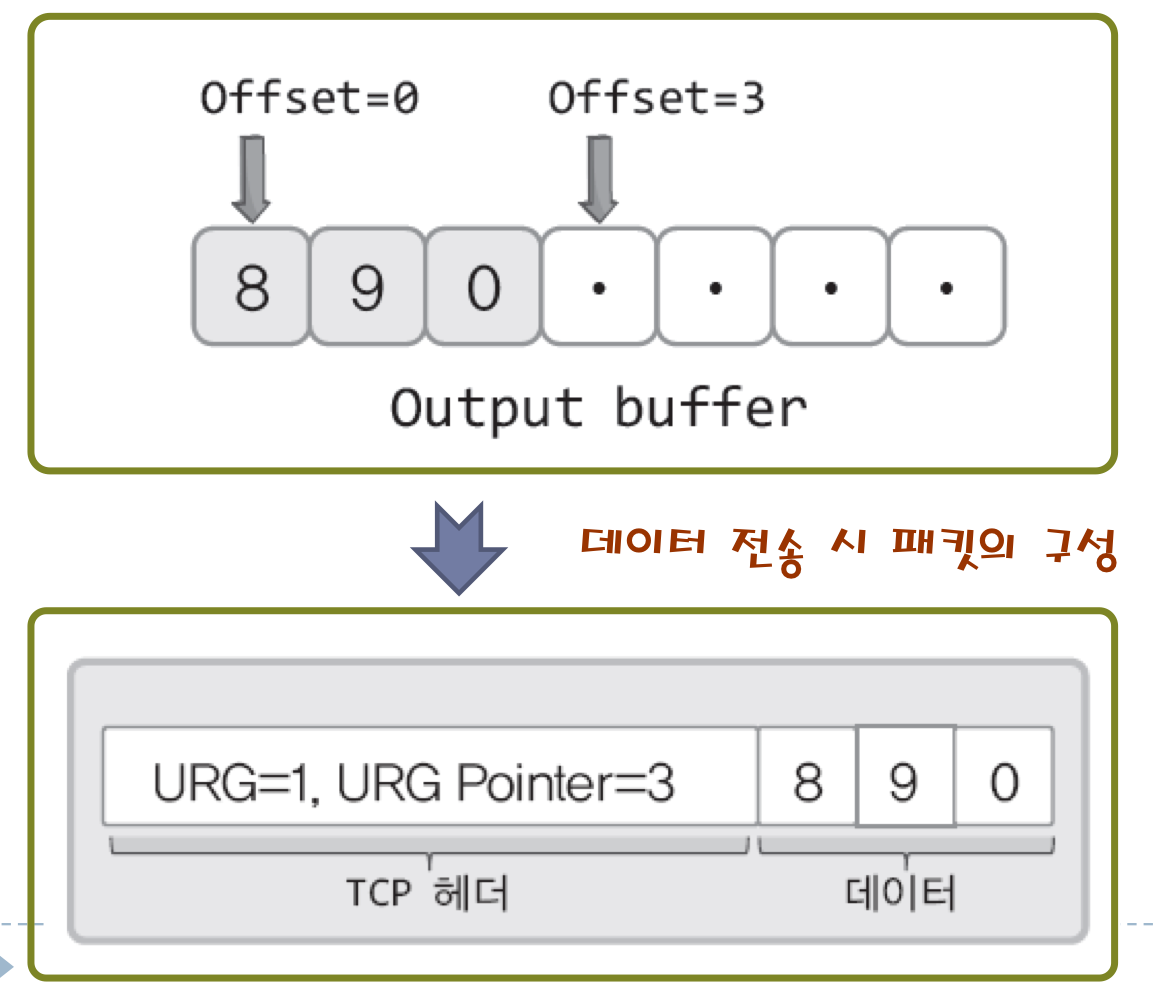
버퍼의 가장 왼쪽 위치를 오프셋 0으로 보면, 문자 0은 오프셋 2의 위치에 저장되어 있다.
그리고 문자 0의 오른편인 오프셋 3의 위치가 Urgent pointer로 지정되어 있다.
Urgent Pointer는 긴급 메시지의 다음 번 위치를 가리키면서 다음의 정보를 상태 호스트에게 전달하는 의미를 갖는다.
"Urgent Pointer가 가리키는 오프셋 3의 바로 앞에 존재하는 것이 긴급 메시지다."
즉, 긴급 메시지 정보는 실제로 하나의 바이트에만 표시가 된다.
아래 그림은 TCP 패킷의 구조이다.
URG = 1은 긴급 메시지가 존재하는 패킷임을 알리는 것이다.
URG pointer = 3은 긴급 메시지가 설정된 위치 정보를 나타내는 것이다.
offset 3의 바로 앞에 존재하는 것이 긴급 메시지이다.
즉, MSG_OOB 옵션이 지정되면 패킷 자체가 긴급 패킷이 되며, Urgent Pointer를 통해서 긴급 메시지의 위치가 표시가 된다.
그리고 MSG_OOB가 설정된 데이터가 전달되면, OS는 SIGURG 시그널을 발생시키고
메시지의 긴급 처리가 필요한 상황을 프로세스에게 알린다.
그리고 실행 결과는 앞에서 본 것처럼 Urgent Pointer의 앞 부분에 위치한 1byte만을 긴급 메시지로 수신받고 나머지는 일반적인 입력함수의 호출을 통해서 읽힌다.
결론은 긴급 메시지는 메시지 처리를 재촉하는데 의미가 있는 것이지 제한된 형태의 메시지를 긴급으로 전송하는데 의미가 있는 것은 아니다.
1-4. 입력 버퍼 검사하기
MSG_PEEK 옵션은 MSG_DONTWAIT 옵션과 함께 설정되어 입력 버퍼에 수신된 데이터가 존재하는 지 확인하는 용도로 사용된다.
MSG_PEEK 옵션을 주고 recv 함수를 호출하면 입력 버퍼에 존재하는 데이터가 읽혀지더라도 입력 버퍼에서 데이터가 지워지지 않는다.
MSG_DONTWAIT 옵션은 입출력 함수 호추 과정에서 블로킹되지 않을 것을 요구하는 옵션이다.
즉 MSG_PEEK | MSG_DONTWAIT는 블로킹 되지 않게 데이터의 존재 유무를 확인하는 것이다.
바로 예제를 보도록 하자.
1-4-1. peek_send
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <sys/socket.h>
#include <arpa/inet.h>
void error_handling(char *message);
int main(int argc, char *argv[])
{
int sock;
struct sockaddr_in send_adr;
if(argc!=3) {
printf("Usage : %s <IP> <port>\n", argv[0]);
exit(1);
}
sock=socket(PF_INET, SOCK_STREAM, 0);
memset(&send_adr, 0, sizeof(send_adr));
send_adr.sin_family=AF_INET;
send_adr.sin_addr.s_addr=inet_addr(argv[1]);
send_adr.sin_port=htons(atoi(argv[2]));
if(connect(sock, (struct sockaddr*)&send_adr, sizeof(send_adr))==-1)
error_handling("connect() error!");
write(sock, "123", strlen("123"));
close(sock);
return 0;
}
void error_handling(char *message)
{
fputs(message, stderr);
fputc('\n', stderr);
exit(1);
}
1-4-2. peek_recv
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <sys/socket.h>
#include <arpa/inet.h>
#define BUF_SIZE 30
void error_handling(char *message);
int main(int argc, char *argv[])
{
int acpt_sock, recv_sock;
struct sockaddr_in acpt_adr, recv_adr;
int str_len, state;
socklen_t recv_adr_sz;
char buf[BUF_SIZE];
if(argc!=2) {
printf("Usage : %s <port>\n", argv[0]);
exit(1);
}
acpt_sock=socket(PF_INET, SOCK_STREAM, 0);
memset(&acpt_adr, 0, sizeof(acpt_adr));
acpt_adr.sin_family=AF_INET;
acpt_adr.sin_addr.s_addr=htonl(INADDR_ANY);
acpt_adr.sin_port=htons(atoi(argv[1]));
if(bind(acpt_sock, (struct sockaddr*)&acpt_adr, sizeof(acpt_adr))==-1)
error_handling("bind() error");
listen(acpt_sock, 5);
recv_adr_sz=sizeof(recv_adr);
recv_sock=accept(acpt_sock, (struct sockaddr*)&recv_adr, &recv_adr_sz);
while(1)
{
str_len=recv(recv_sock, buf, sizeof(buf)-1, MSG_PEEK|MSG_DONTWAIT);
if(str_len>0)
break;
}
buf[str_len]=0;
printf("Buffering %d bytes: %s \n", str_len, buf);
str_len=recv(recv_sock, buf, sizeof(buf)-1, 0);
buf[str_len]=0;
printf("Read again: %s \n", buf);
close(acpt_sock);
close(recv_sock);
return 0;
}
void error_handling(char *message)
{
fputs(message, stderr);
fputc('\n', stderr);
exit(1);
}
- 위에서도 설명했지만 recv 함수를 호출하면서 MSG_DONTWAIT 옵션을 전달하는 이유는 데이터가 존재하지 않아도 블로킹 상태에 두지 않기 위해서이다.
예를 들어 MSG_DONTWAIT 옵션이 없다면 수신할 데이터가 존재하지 않으면 그대로 블로킹 상태에 빠질 것이다. Non-blockg 모드에서 데이터 존재 유무를 확인할 수 있다. - 밑에서 받은 recv 함수에는 아무런 옵션도 주지 않았다.
이번에 읽은 데이터는 입력 버퍼에서 지우기 위함이다.
- 실행 결과

2. readv & writev 입출력 함수
이번에 소개할 입출력 함수는 데이터 송수신의 효율성을 향상시키는데 도움이 되는 함수들이다.
일단 사용방법부터 알고 가자
2-1. readv & writev 함수의 사용
readv & writev 함수의 기능을 한 마디로 정리하자면 다음과 같다.
"데이터를 모아서 전송하고, 모아서 수신하는 기능의 함수"
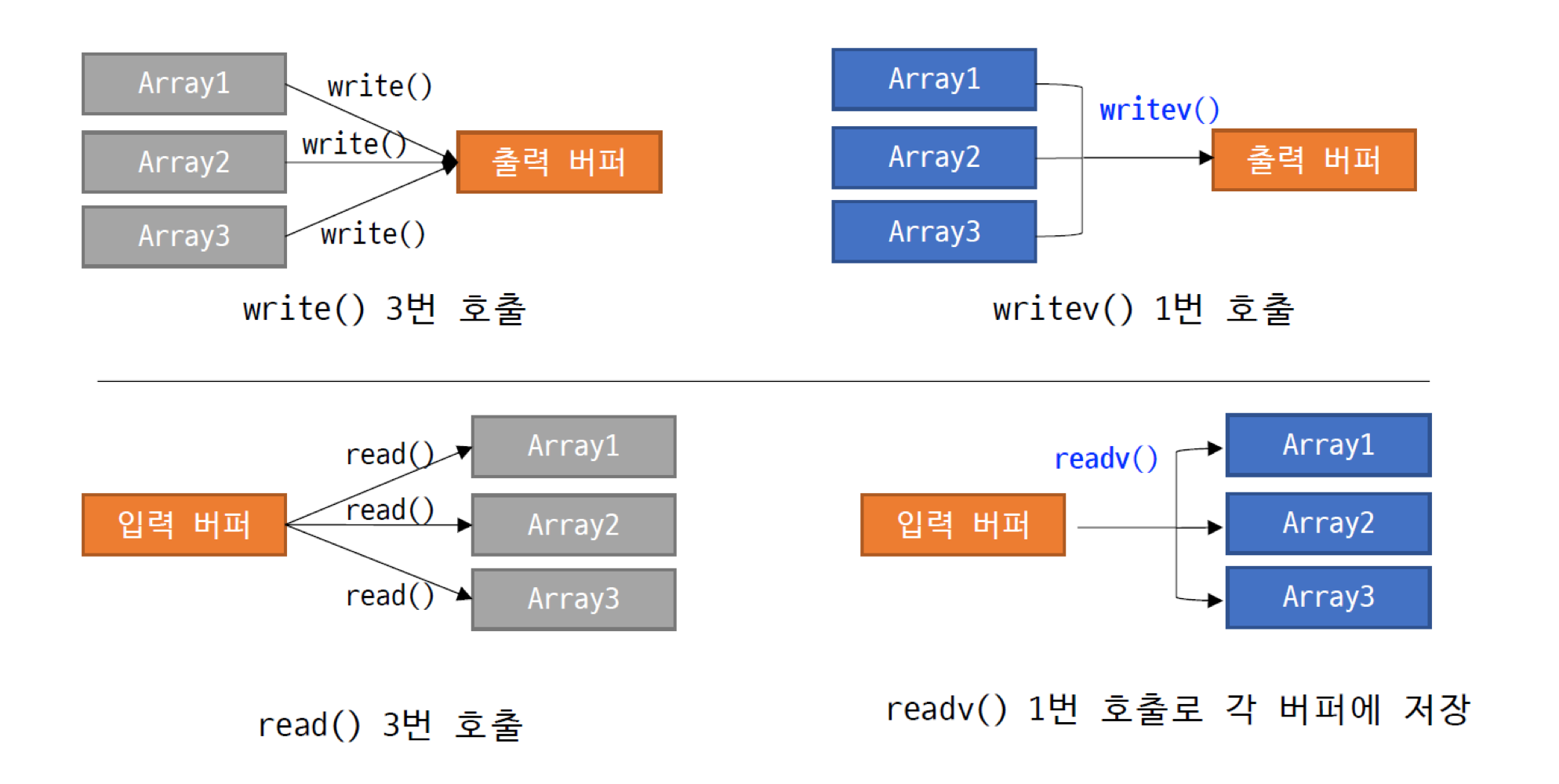
즉, writev 함수를 사용하면 여러 버퍼에 나뉘어 있는 데이터를 한 번에 전송할 수 있고,
readv 함수를 사용하면 데이터를 여러 버퍼에 나눠서 수신할 수 있다.
이렇게 사용을 한다면 입출력 함수 호출의 수를 줄일 수 있다.
2-1-1. writev
#include <sys/uio.h>
ssize_t writev(int fildes, const struct iovec * iov, int iovcnt);
// 성공 시 전송된 바이트 수, 실패 시 -1 반환
/*
filedes : 데이터 전송의 목적지를 나타내는 소켓의 파일 디스크립터 전달.
단, 소켓에만 제한된 함수가 아니기 때문에, read함수처럼 파일이나 콘솔 대상의 파일 디스크립터도 전달
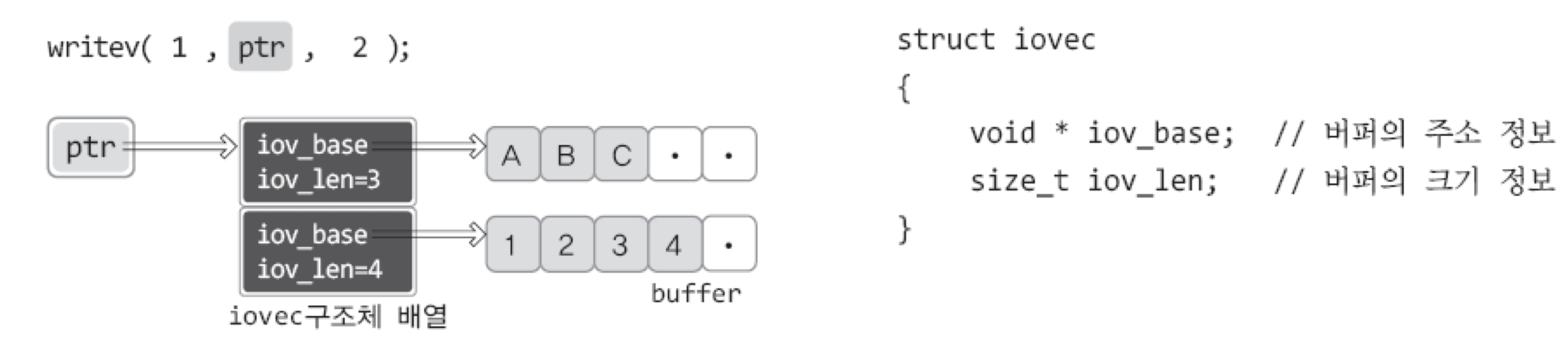
iov : 구조체 iovec 배열의 주소 값 전달, 구조체 iovec의 변수에는 전송할 데이터의 위치 및 크기 정보가 담긴다.
iovcnt : 두 번째 인자로 전달된 주소 값이 가리키는 배열의 길이 정보 전달
*/다음과 같이 그림으로 쉽게 알아볼 수 있다.
구조체 iovec는 전송할 데이터가 저장되어 있는 버퍼(char형 배열)의 주소 값과 실제 전송할 데이터의 크기 정보를 담기 위해 정의되었다.
왼쪽 그림에서 첫 번째 인자 1은 파일 디스크립터를 의미하므로 콘솔에 출력이 이뤄지고,
ptr은 전송할 데이터 정보를 모아둔 iovec 배열을 가리키는 포인터이다.
또한 세 번째 인자가 2이기 때문에 ptr이 가리키는 주소를 시작으로 총 2개의 iovec 변수를 참조한다.
버퍼 그림을 보자.
ptr[0]의 iov_base는 A로 시작하는 문자열을 가리키면서, iov_len은 3이므로 ABC가 전송된다.
ptr[1] 또한 마찬가지이다.
예제를 통해서 실제로 함수를 사용해보자.
여기서 writev의 첫 번째 매개 변수 1이 콘솔에 출력이 이뤄진다는 것은
fd = 0 은 standard input이고
fd = 1 은 standard output
이기 때문이다.
#include <stdio.h>
#include <sys/uio.h>
#include <string.h>
int main(int argc, char *argv[])
{
struct iovec vec[2];
char buf1[]="ABCDEFG";
char buf2[]="1234567";
int str_len;
vec[0].iov_base=buf1;
vec[0].iov_len=strlen(buf1);
vec[1].iov_base=buf2;
vec[1].iov_len=strlen(buf2);
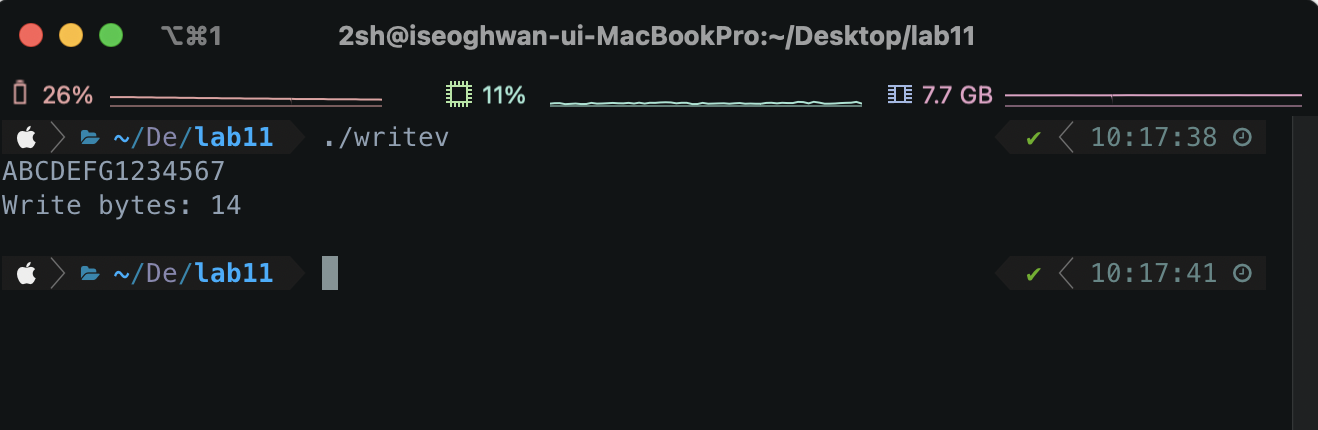
str_len=writev(1, vec, 2);
puts("");
printf("Write bytes: %d \n", str_len);
return 0;
}
- 실행 결과
필자는 위에 그림과 iov_len의 길이를 다르게 주어서 문자열을 모두 읽게 만들었다.
나머지는 충분히 설명했으니 넘어가겠다.
2-1-2. readv
#include <sys/uio.h>
ssize_t readv(int fildes, const struct iovec * iov, int iovcnt);
// 성공 시 수신된 바이트 수, 실패 시 -1 반환
/*
filedes : 데이터를 수신할 파일(혹은 소켓)의 파일 디스크립터도 인자로 전달
iov : 데이터를 저장할 위치와 크기 정보를 담고 있는 iovec 구조체 배열의 주소 값 전달
iovcnt : 두 번째 인자로 전달된 주소 값이 가리키는 배열의 길이 정보 전달
*/readv 함수는 writev 함수를 반대로 생각하면 되니 자세한 설명은 넘어가고 바로 코드를 작성해보자.
#include <stdio.h>
#include <sys/uio.h>
#define BUF_SIZE 100
int main(int argc, char *argv[])
{
struct iovec vec[2];
char buf1[BUF_SIZE]={0,};
char buf2[BUF_SIZE]={0,};
int str_len;
vec[0].iov_base=buf1;
vec[0].iov_len=5;
vec[1].iov_base=buf2;
vec[1].iov_len=BUF_SIZE;
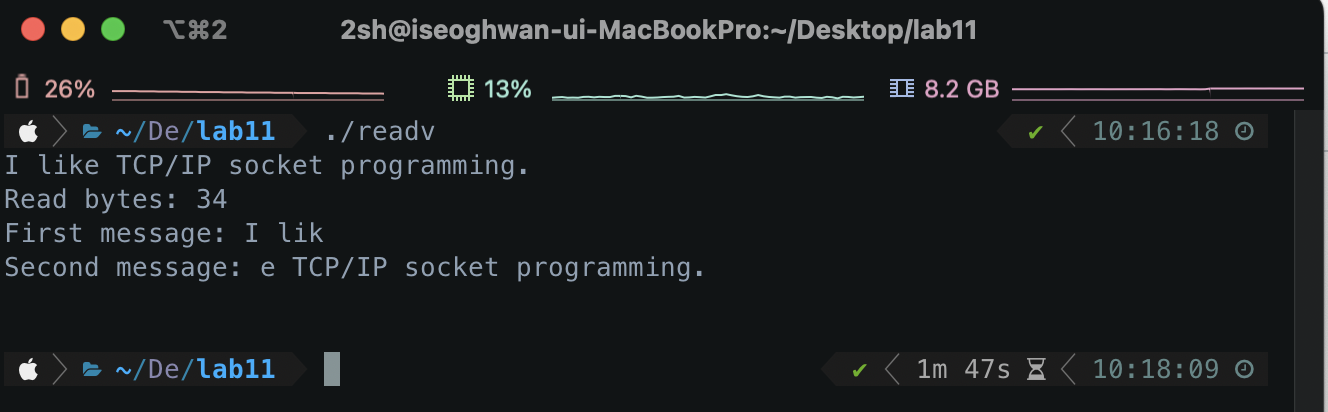
str_len=readv(0, vec, 2);
printf("Read bytes: %d \n", str_len);
printf("First message: %s \n", buf1);
printf("Second message: %s \n", buf2);
return 0;
}
- 첫 번째 저장할 저장소의 위치와 데이터의 크기 정보를 설정한 곳을 보자.
저장할 데이터의 크기를 5로 지정했기 때문에 vec[0]에는 5byte의 데이터가 저장될 것이다. - 두 번째 저장할 저장소의 위치와 데이터의 크기 정보를 설정한 곳을 보자.
저장할 데이터의 크기를 최댓값을 100으로 했기 때문에 100byte까지는 모두 읽을 수 있다. - readv 함수 호출을 보자면 데이터를 수신해야 하기 때문에 첫 번째 매개 변수가 0인 것을 알 수 있다.
- 실행 결과
2-2. readv & writev 함수의 적절한 사용
그렇다면 어떤 상황이 readv와 writev 함수를 사용하기에 적절한 것일까 ?
사용할 수 있는 모든 경우가 적절한 상황이다.
예를 들어 전송해야 할 데이터가 여러 개의 버퍼(배열)에 나눠어 있는 경우, 모든 데이터의 전송을 위해서는 여러 번의 write 함수를 호출해야 한다. 하지만 이를 한 번의 write 함수 호출로 대신할 수 있다면 당연히 효율적이지 않은가 ?
마찬가지로 readv 함수 또한 여러 번 read 함수를 호출하는 것보다 한 번 호출하는 것이 더 효율적이다.
C언어 차원으로 생각해봐도 함수의 호출 횟수가 적으면, 그만큼 성능이 향상된다는 것을 알 수 있다.
그러나 일반적으로 전송되는 패킷의 수를 줄일 수 있다는 데에 더 큰 의미가 있다.
앞에서 공부한 Nagle Algorithm을 명시적으로 중지시킨 상황을 예로 들어보자.
Nagle Algorithm이란 ACK가 오기 전까지 버퍼에 데이터를 모았다가 하나의 패킷으로 전송하는 방법이였다.
writev 함수는 Nagle Algorithm이 중지된 상황에서 더 활용의 가치가 높다.
밑에 사진을 보자.
전송해야 할 데이터가 세 개의 공간으로 나뉘어 저장된 상황에서 데이터 전송을 예로 들고 있다.
이 상황에서 write 함수를 사용한다면 3번의 호출이 필요할 것이다.
그런데 속도 향상을 목적으로 Nagle 알고리즘이 중지ㅏ된 상황이라면, 총 세 개의 패킷으로 생성되어 전송될 확률이 높다.
반면 writev 함수를 사용한다면 한 번에 모든 데이터를 출력 버퍼로 밀어 넣고 하나의 ㅐ패킷만 생성되어서 전송될 확률이 높다.
이는 전송속도의 향상으로 이어질 수 있다.
사진의 오른쪽 부분을 보면 알겠지만 하나의 큰 배열에 3개의 데이터를 모두 옮겨놓고 write 함수를 사용하는 것과 writev 함수를 호출하는 것과 결과는 같다.
하지만 어떤 것이 더 편할지는 누가봐도 알 것이라고 생각한다.
writev 함수와 readv 함수를 사용할 상황이 나오면 적극적으로 사용하자 !

참고 : 윤성우의 열혈 TCP/IP 소켓 프로그래밍
Git : https://github.com/im2sh/Socket_Programming/tree/main/lab11
