
오늘은 무슨 날? 드디어 전역하는 날!
드디어 군 생활이 끝나고 전역을 했다. 수고했다 나 자신!
아침에 부대에서 나와서 집에 오자마자 강의를 들었다. 또 수고했다 나 자신!
어제랑 그제 빠진것 때문에 엄청 걱정했는데, 걱정할만 했다. 수고해라 나 자신!
파이팅!
10.03. 시작!
0202 - 네이버 금융 기사 수집(이어서)
전날에 웹 크롤랑을 통해 기사를 수집하는 법과, 이를 판다스의 데이터프레임에 저장하는 방법에 대해 배웠다.
이번에는 해당 과정을 하나의 함수로 만들어보았다.
# get_one_page_news 함수 만들기
def get_one_page_news(item_code, page_no):
"""
get_url 에 item_code, page_no 를 넘겨 url 을 받아오고
뉴스 한 페이지를 수집하는 함수
1) URL 을 받아옴
2) read_html 로 테이블 정보를 받아옴
3) 데이터프레임 컬럼명을 ["제목", "정보제공", "날짜"]로 변경
4) temp_list 에 데이터프레임을 추가
5) concat 으로 리스트 병합하여 하나의 데이터프레임으로 만들기
6) 결측치 제거
7) 연관기사 제거
8) 중복데이터 제거
9) 데이터프레임 반환
"""
url = get_url(item_code, page_no)
table = pd.read_html(url, encoding="cp949")
temp_list = []
cols = table[0].columns
for news in table[:-1]:
news.columns = cols
temp_list.append(news)
df_news = pd.concat(temp_list)
df_news = df_news.dropna()
df_news = df_news.reset_index(drop=True)
df_news = df_news[~df_news["정보제공"].str.contains("연관기사")].copy()
df_news = df_news.drop_duplicates()
return df_news
그 후, 페이지를 바꾸어가며 10페이지까지의 데이터를 크롤링하는 실습을 하였다.
이때, tqdm이라는 라이브러리를 사용하였다.
tqdm
tqdm 라이브러리는 파이썬에서 progress bar를 표시해줄 수 있게 해주는 라이브러리이다.
시간이 오래 걸리는 작업, 예를 들면 대용량 데이터 처리 작업을 할때 사용한다.
tqdm(range(20))같은 방법으로 사용할 수도 있고,
from tqdm import trange하여
for i in trange(20):과 같이 사용할 수도 있다.다음과 같은 결과를 볼 수 있다.

이를 이용해 10 패이지까지 기사를 수집하는 코드는 다음과 같다.
import time
from tqdm import trange
item_name = "기아"
item_code = df_krx.loc[df_krx["Name"] == item_name, "Symbol"].values[0]
news_list = []
for page_no in trange(1, 11):
temp = get_one_page_news(item_code, page_no)
news_list.append(temp)
time.sleep(0.1)time.sleep(0.1)을 사용하는걸 잊지 말자!
이렇게 0202 실습 파일을 마쳤다!
0203 - 네이버 금융 시세 크롤링
이번 실습은 네이버 금융에서 원하는 종목의 일별 시세를 크롤링하는 실습이었다.
여기서 문제!
일별 시세를 크롤링하기 위해 네이버 금융에 접속해 보았다. 그런데, 일별 시세의 페이지를 아무리 바꾸어보아도, 브라우저 창의 URL이 변화하지 않는다!
그럼 어떻게 크롤링해야 할까?
첫번째는 셀레니움을 이용하는 방법이 있을 것이다. 간단하고 어디에도 적용할 수 있는 방법이지만 효율이 떨어지고 리소스를 많이 사용해 추천하지 않는다.
두번째 방법으로는, 개발자 도구의 network 탭을 사용해 우리가 원하는 데이터를 찾아내는 것이 있다! 이게 핵심이다.
개발자도구 - network 탭 활용(데이터 찾기)
먼저 개발자 도구를 연다. 그 후 network 탭에 들어간다.
모든 값을 초기화해준 후, 우리가 원하는 '일별 시세'의 페이지를 바꾸어가며 네트워크 탭에 나타나는 정보를 확인한다.
사진으로 보자. 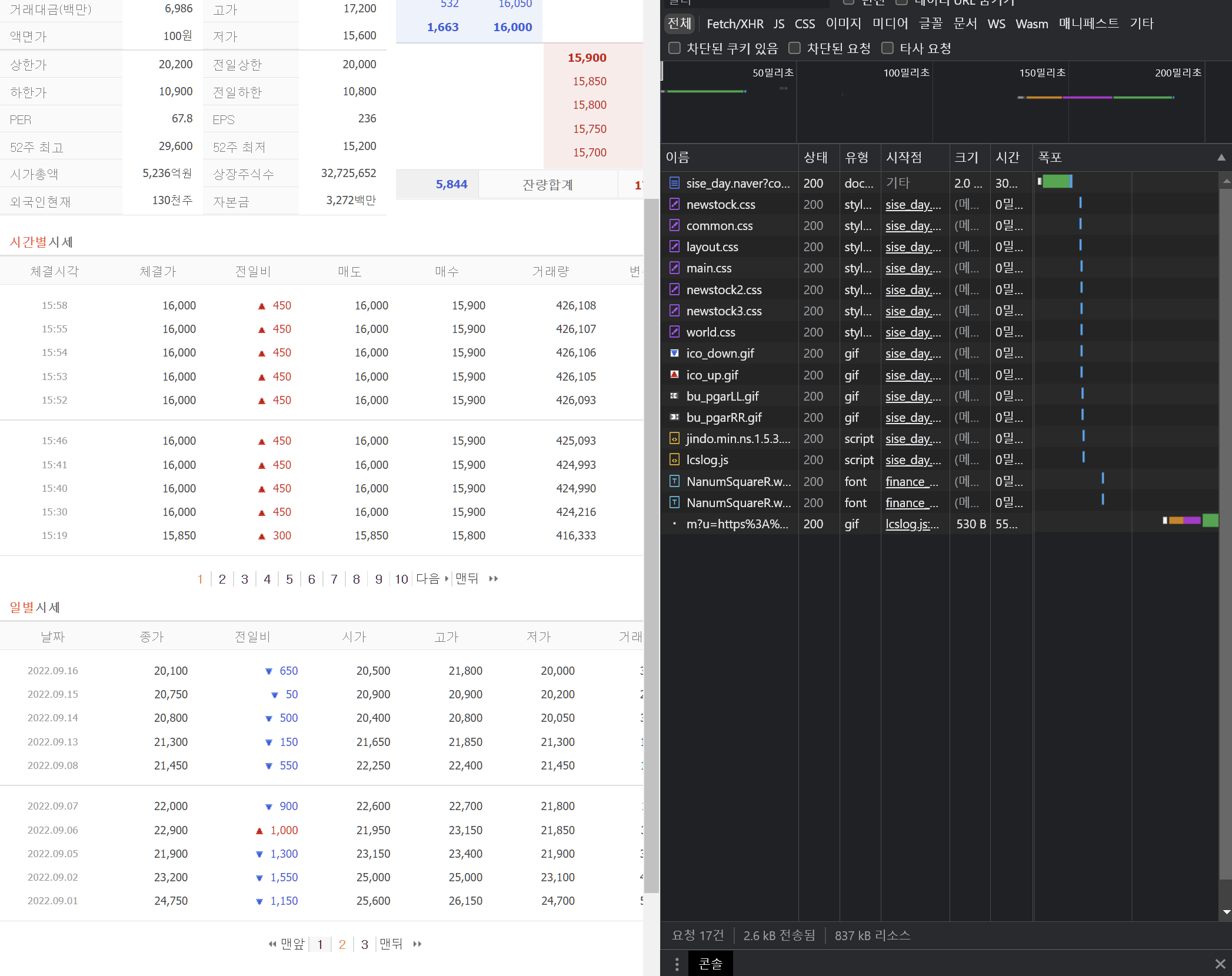
위와 같이, network 탭에 다양한 데이터들이 나타나는 것을 볼 수 있다. 일부는 doc, 일부는 미디어, 일부는 css, 일부는 script 형식이다.
우리가 원하는 데이터의 대부분은 doc 혹은 script에 존재한다. doc에서는, 우리가 원하는 html 정보, 혹은 url을 얻을 수 있는 경우가 많다.
script에서는, 우리가 원하는 데이터를 비동기형식으로 가져온 Json 문자열을 얻을 수 있는 경우가 많다.
해당 데이터들을 클릭한 후, 헤더를 선택하면 해당 정보를 요청하는 메소드가 무엇인지 (get, post 등)를 알 수도 있다.
비동기 형식이란?
문서의 전체를 새로고침하며 정보를 요청하고 받아오는 것이 아니라, 일부분만 새로고침하며 정보를 요청하고 받아오는 형식을 말한다. 요청한 후 응답이 있기까지 기다리며 아무것도 할 수 없는 동기형식에 비해, 요청한 후 응답이 있던 없던 상관하지 않아 다른 동작을 자유롭게 할 수 있다는 차이점이 있다고 한다.
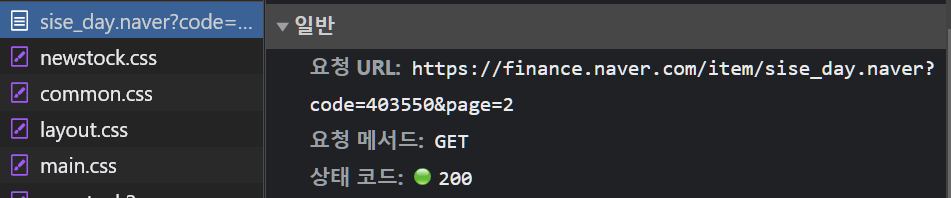
이렇게 해서 우리가 원하는 일별 시세의 정보가 담겨있는 HTML의 URL 주소를 알아냈다. GET 메소드를 사용해 query stirng의 parameter를 바꾸어가며, 여러 페이지의 시세를 모두 알아볼 수 있는 url 이다!
해당 url을 활용해 이번 크롤링을 진행하였다.
강사님이 추가로 추천해주신 유튜브 강의를 보니, 우리가 이전까지 해왔던 정적 html 크롤링이 아니라, 이와 같은 크롤링을 Ajax 렌더링의 크롤링이라고 한단다. Ajax 렌더링이란, 자바스크립트를 사용하여 브라우저가 서버에게 비동기 방식으로 데이터를 요청하고, 서버가 응답한 데이터를 수신하여 웹페이지를 갱신하는 방식을 말한다고 한다.
따라서 이와 같은 형식으로 동작하는 웹페이지에 대해서는, network 탭을 활용해 json 데이터를 찾거나, 원하는 html을 찾는 방식으로 requests를 통한 크롤링을 진행할 수 있다. 물론 Selenium을 이용하는 방법도 있다.
requests.get(url, headers = headers)
그럼 이제 얻어낸 url을 토대로, requests.get을 통해 요청을 보내 데이터를 크롤링해 볼 차례이다.
그런데, 아래와 같은 코드를 실행하면 문제가 발생한다.
response = requests.get(url)
response.text바로 서버가 우리가 python을 통해 웹페이지에 접근하고 있다는 사실을 파악하고, 접근을 막아버리는 것이다.
따라서 headers에 User-Agent 정보를 추가해줘야 한다.
다음과 같이 사용한다.
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'}
requests.get(url, headers = headers)이 외에도, 어디서 웹페이지에 접근했는지 알 수 있는 정보인 referer 등이 headers에 추가될 수 있다!
BeautifulSoup4
그럼 이제 본격적으로 크롤링을 시작해보자!
BeautifulSoup를 사용해, requests로 얻은 html을 parsing한 후 원하는 정보를 찾아낼 수 있다.
from bs4 import BeautifulSoup as bs
# bs는 html을 parsing하여, 예쁘게 계층적으로 구조화하여 원하는 태그를 찾아 사용할 수 있게 한다.
html = bs(response.text) #이렇게만 써도 많이 이뻐진다!찾고자 하는 태그를 다음과 같은 방법으로 찾을 수 있다.
html.title
>>>
<title>네이버 금융</title>
html.table다음과 같이 find 혹은 find_all 함수를 사용할 수 도 있다.
html.find('a')
>>>
<a href="/item/sise_day.naver?code=005930&page=1">1</a>find 함수는 원하는 태그 중 가장 첫번째로 나오는 것을 찾아주고,
find_all 함수는 원하는 태그들을 모두 찾아 list로 반환해준다.
html.find_all("a")
>>>
[<a href="/item/sise_day.naver?code=005930&page=1">1</a>,
<a href="/item/sise_day.naver?code=005930&page=2">2</a>,
<a href="/item/sise_day.naver?code=005930&page=3">3</a>,
<a href="/item/sise_day.naver?code=005930&page=4">4</a>,
<a href="/item/sise_day.naver?code=005930&page=5">5</a>,
<a href="/item/sise_day.naver?code=005930&page=6">6</a>,
<a href="/item/sise_day.naver?code=005930&page=7">7</a>,
<a href="/item/sise_day.naver?code=005930&page=8">8</a>,
<a href="/item/sise_day.naver?code=005930&page=9">9</a>,
<a href="/item/sise_day.naver?code=005930&page=10">10</a>,
<a href="/item/sise_day.naver?code=005930&page=11">
다음<img alt="" border="0" height="5" src="https://ssl.pstatic.net/static/n/cmn/bu_pgarR.gif" width="3"/>
</a>,
<a href="/item/sise_day.naver?code=005930&page=660">맨뒤
<img alt="" border="0" height="5" src="https://ssl.pstatic.net/static/n/cmn/bu_pgarRR.gif" width="8"/>
</a>]id나 class에 특정한 값을 가지고 있는 태그를 찾고 싶다면 다음과 같이 사용한다.
html.find('h4', 'tlline2')
# h4 태그 중 id나 class가 tlline2인 태그만 찾는다.찾은 태그의 특정 속성이나 텍스트를 얻고 싶다면, 다음과 같이 사용한다.
html.find('a')['href']
>>>
/item/sise_day.naver?code=005930&page=1
html.find('a').text
>>>
1find 함수가 아니라, SELECT 함수도 존재한다. 해당 함수는, css selector를 사용하여 원하는 정보를 찾아낼 수 있는 함수이다.
CSS selector는 말 그대로 css에서 어떤 요소에 속성을 적용할 지 정해줄 때 사용하는 값이다. ID의 경우 #을 사용하고, class의 경우 .을 사용한다.개발자도구에서 복사를 통해 쉽게 알아낼 수 있어서, 태그를 쉽게 특정할 수 있다는 장점이 있다.
html.select("table > tr > td")
# table 아래, tr 아래의 td만 가져온다. 구조 및 주소를 주는 것이라 볼 수 있다!
# table 은 표, tr 은 행, td는 열이다.select 역시, select 함수 뿐 아니라 select_one 함수가 존재한다.
다음과 같이 find와 select를 비교할 수 있다.
#find
html.find('table').find('td')
#select
html.select_one('table > td')Pandas로 데이터 수집하기
지난 실습에서 했듯이, pd.read_html을 통해 html의 table 태그를 읽어올 수 있다. 따라서 table 태그만 필요한 경우에는 굳이 requests나 bs4 같은 라이브러리가 필요 없기도 하다.
table = pd.read_html(response.text, encoding = "cp949")과 같이 pandas를 이용해 데이터를 수집한다.
전에도 언급했듯이, html에 존재하는 모든 table들을 DataFrame 형태로 list에 담아서 반환한다.
따라서 원하는 table만 고르고, 결측치 제거 등 전처리를 실시한다.
temp = table[0]
temp = temp.dropna()따라서 일별 시세를 수집하는 함수는 다음과 같다.
def get_day_list(item_code, page_no):
"""
일자별 시세를 페이지별로 수집
pseudo code
1) url을 만든다.
2) requests를 통해 html 문서를 받아온다.
3) read_html을 통해 table 태그만 읽어온다.
4) 결측 행을 제거한다.
5) 데이터프레임을 반환한다.
"""
url = f"https://finance.naver.com/item/sise_day.naver?code={item_code}&page={page_no}"
response = requests.get(url, headers = {'User-Agent': 'Mozilla/5.0'})
return pd.read_html(response.text)[0].dropna()반복문을 이용해 전체 일자에 대해 데이터를 수집해보자.
여기서 중요한 논점은, 과연 몇 페이지까지 존재하는지를 어떻게 파악할 것인가에 대한 것이다.
크롤링을 할때마다 우리가 일일이 파악한 후 그것에 대해 for문을 돌린다면, 유지보수 측면에서 볼때 상당히 불리하다.
따라서, 페이지 수가 바뀌어도 프로그램에서 파악하여 마지막 페이지까지 크롤링 할 수 있게 만드는 것이 필요하다.
생각해보고 이것 저것 해보다보면, page_no에 마지막 페이지 번호를 넣었을 때와, 그 다음 페이지 번호를 넣었을 때에 출력되는 table이 동일하다는 것을 알 수 있다.
따라서 마지막 페이지의 기준을, 이번 페이지와 다음 페이지에서 크롤링 할 수 있는 값이 같을때. 라고 정할 수 있다. df와 df 전체를 비교하기 힘드므로, 더 구체적으로 생각해보자. 일별 시세 테이블에서, 페이지를 넘겼을 때 가장 상단의 날짜가 서로 같다면, 두 페이지는 같은 내용을 담고 있고, 해당 페이지가 마지막 페이지라고 할 수 있을 것이다.
해당 코드는 while문을 통해 구현할 수 있다.
import time
# web page 시작번호
page_no = 1
# 데이터를 저장할 빈 변수 선언, list에 저장한 후 concat으로 합친다.
item_list = []
prev_day = ""
while True:
df_item = get_day_list(item_code,page_no)
last_day = df_item.iloc[-1]["날짜"]
if last_day == prev_day: # 비교 기준이다. 핵심이었다.
last_page = page_no - 1
break
item_list.append(df_item) # 먼저 list에 다 저장한 후, concat 기능을 사용하여 하나의 df로 만들 수 있다! 그렇군그렇군
page_no = page_no +1
prev_day = last_day # 역시 핵심적인 코드 2!
df_table = pd.concat(item_list).reset_index()
print(df_table)와 실습 시간 때 구현하는데 꽤나 까다로웠다.....! 힘들었다...!
뭔가 착착착 체계적으로 하고 싶은데 한번에 그렇게는 안되더라. 연습 또 연습!
음, 일단 df들을 굳이 list에 저장하고 나중에 concat으로 합친다는게 이해가 안되었었던 것 같은데, 지금 생각해보면 당연하다.
모든 페이지에서 추출해낸 table들을 합치는 방법이, concat 말고 또 뭐가 있을까! 그리고 concat에는 Seires나 DataFrame 을 담고 있는 sequence가 인자로 들어가야 하고! 이해가 된다!
그리고 현재 페이지의 table의 내용과 다음 table의 내용이 같은지를 어떻게 파악해야 할지 많이 고민했던 것 같다. df == df 로는 안되었었다. table을 대표할 수 있는 특정한 값을 뽑아내어 비교한다는 방식이 아주 인상깊었다!
concat으로 합치는 코드는 다음과 같다. reset_index(drop = True)를 사용했다. drop = True! 를 꼭 써줘야 했다!
df_day = pd.concat(item_list).reset_index(drop = True)그 후에는, 데이터프레임을 보기 좋게 바꾸어주는 작업을 했다. 사소하지만 중요하게 알아둬야 할 부분인 것 같다!
먼저, 종목 코드와 종목 명 컬럼을 추가한다. 값은 broadcasting 되도록 하나씩만 넣어 준다.
df_day["종목코드"] = item_code
df_day["종목명"] = item_name그리고 여기가 좀 인상깊었던 부분!
column의 순서를 바꾸어준다!
그러기 위해서 cols라는 리스트를 정의한 후,
df = df[cos]와 같이 사용했다... 이게 되네..?
cols = ['종목코드', '종목명', '날짜', '종가', '전일비', '시가', '고가', '저가', '거래량']
df_day = df_day[cols]왜 이렇게 하면 되는거지..?
뭔가 df.columns = cols 이런식으로 할 줄 알았는데...!
실행 해봤더니, 이렇게하면 안된다!!!!!
내용은 그대로고, 단지 column의 이름만 바꾸는 코드다!
df = df[cols] 이렇게 해줘야, column들의 순서가 바뀐다고 생각하면 되겠다! 좀 알아둬야겠다!!!
중복 데이터 제거는 drop_duplicates()를 사용한다.
df_day.drop_duplicates()하나의 함수로 만들기
실습 중에서 이 과정이 가장 어려웠다.
여태까지 했던 내용을 바탕으로, 하나의 함수로 만들어보려는데 생각보다 많이 안되더라................ 더 열심히 해야겠다는 걸 느꼈다.
그리고 앞으로 함수나 코드를 짤 때에도 이런식으로 진행하면 되겠구나 라는 생각도 했다. 일단 전체적으로 구현해야 할 기능을 정하고, 어떤 방법을 통해서 구현할지 결정한 다음, 차례차례 한 부분 씩 코드를 짜보고, 마지막의 병합하는 형식으로? 한번에 막 짜내려갈 수 있으면 좋겠지만! 그렇게하면서 코드를 짜는 연습을 많이 해야겠다!
어쨌든 완성한 함수는 다음과 같다.
def get_item_list(item_code, item_name):
"""
일별 시세를 수집하는 함수
기능 : item_code를 지정해주면, 해당 종목의 일별 시세를 모두 읽어와 df로 만든 후 csv로 내보낸다.
"""
page_no = 1
sise_list = []
prevday = ""
while True:
now = get_day_list(item_code,page_no)
nowday = now.iloc[0]["날짜"]
if(nowday == prevday):
break
page_no += 1
prevday = nowday
sise_list.append(now)
time.sleep(0.1)
df = pd.concat(sise_list)
df["종목코드"] = item_code
df["종목명"] = item_name
cols = ['종목코드', '종목명', '날짜', '종가', '전일비', '시가', '고가', '저가', '거래량']
df = df[cols]
df = df.drop_duplicates()
file_name = f"{item_name}_{item_code}_{date}.csv"
df.to_csv(file_name,index = False)
return file_name막상 해보면 또 그렇게 어려운건 아니다! 할 수 있다! 파이팅!!!
그렇게 0203 실습 파일의 내용도 끝났다!
웹 스크래핑과 크롤링을 할 수 있는 전반적인 기술들에 대해 배우고, 그를 통해 얻은 데이터를 dataframe으로 처리할 수 있는 기초적인 방법에 대해 배울 수 있어 좋았다.
0204 - Json 데이터 수집
0204 파일은 json 데이터를 수집하는 실습이었다!
앞에서 다양한 크롤링 방식에 대해 언급한 바 있는데,
정적 html을 수집하는 것 말고, Ajax 방식으로 비동기식 요청과 응답으로 웹페이지상의 정보를 주고받는 페이지에 대해서는, 개발자 도구에서의 network 탭을 활용해 JSON 정보를 수집할 수 있다고 했었다.
실습을 통해 좀 더 자세히 알아보자!
먼저, 우리가 그동안 크롤링해왔던 방법처럼, url을 get 요청을 통해 요청을 보내자.
response = requests.get(url)
그 후, response.text로 html을 살펴보면, 우리가 개발자 도구를 통해 본 html 과는 다르다.
이는, 페이지 자체에서 우리가 원하는 데이터를 표시하고 있는 것이 아니라, 자바스크립트를 통해 추가 요청을 보낸 후 그 결과를 웹페이지 상
에 표시하고 있기 때문이다.
강사님 추천 강의에서 들은 내용을 조금 덧붙이자면, 우리가 웹페이지를 요청할 때, 웹페이지만 요청을 보내는 것이 아니라, 웹 페이지에서 요구하는 CSS파일들, JS파일들 등 아주 다양한 파일에도 요청을 보낸다. 따라서 그 응답으로 받은 파일들이 모두 동작하여 우리가 눈으로 보는 웹페이지가 완성된다.
하지만 requests라는, 파이썬 내의 작은 브라우저는, CSS나 JS 파일 등을 요청하지 않는다. 그저 처음에 요청하여 얻을 수 있는 html 자체만 요청을 보낸다. 따라서, JS로 요청을 보내 비동기 형식으로 데이터를 표시하는 웹페이지에 대해서, 우리는 정적인 html에서 크롤링을 해왔던 것 처럼 크롤링할 수 없다.
이를 어떻게 파악할 수 있냐면, 페이지 소스보기는 가장 처음에 요청하는 html을 표시하고, 개발자 도구는 JS등에 요청을 모두 보낸 후 지금 보고있는 페이지의 소스를 표시하므로, 그 두개가 다르다면 비동기형식으로 데이터를 주고받는 웹페이지라고 생각할 수 있겠다.
따라서 이런 경우에 data를 수집하기 위해서는, Network 탭에서 JS 파일을 찾아내 그 안에 담겨져있는 JSON 문자열, 그 데이터를 수집해야 한다! 그것이 바로 우리가 원하는 데이터이다.
그럼 그걸 어떻게 하느냐!
역시 위에서 언급한 것 처럼, network 탭을 켜고, 우리가 원하는 데이터가 있는 부분에 변화를 주면서 나타나는 JS 파일을 찾는다.
해당 파일의 헤더에 있는 요청 URL을 requests를 통해 요청을 보낸다!
그 요청으로 받은 응답에 대해, response.json()으로 json을 확인하면, 그것이 바로 우리가 원하는 데이터이다!
그럼 실습을 통해 한번 자세히 알아보자!
앞에서 말한 방법으로, 요청 URL을 알고 있다고 가정한다!
내가 그렇게 구한 URL (네이버 금융 ETF 시세 페이지)은 다음과 같다.
https://finance.naver.com/api/sise/etfItemList.nhn?etfType=0&targetColumn=market_sum&sortOrder=desc&_callback=window.__jindo2_callback._7759그런데 사실, 이 URL의 뒷부분, callback 부분은 필요하지 않은 부분이다.
jindo라는 것이 네이버에서 사용하는 자바스크립트 프레임워크라고 강사님께서 말씀하신 것 같다. 자바스크립트 공부를 해야 callback이 뭔지 알 수 있을 것 같으므로.. 일단 과감히 패스!
대강 이해하기로는, 특정 함수가 시행된 후, 특정 시점에 일어나는 함수가 callback 함수라고 한다. 뭔가 어쨌든 응답을 한 후 client에서 특정 함수를 수행할 것을 의미하는데, 없어도 아무 일도 안생긴다!
따라서 과감히? URL에서 빼준다.
(정확히 이해는 못했고, 각 사용자마다 다른 크게 의미없는 부분이어서 빼도 된다고 하셨던 것 같다ㅠㅠ)
따라서 다음과 같이 수행한다.
url = "https://finance.naver.com/api/sise/etfItemList.nhn?etfType=0&targetColumn=market_sum&sortOrder=desc"
response = requests.get(url)
etf_json = response.json()결과로 받은 데이터는 다음과 같다.
etf_json
>>>
{'resultCode': 'success',
'result': {'etfItemList': [{'itemcode': '069500',
'etfTabCode': 1,
'itemname': 'KODEX 200',
'nowVal': 28275,
'risefall': '5',
'changeVal': -125,
'changeRate': -0.44,
'nav': 28315.0,
'threeMonthEarnRate': -8.2219,
'quant': 5333958,
'amonut': 151187,
'marketSum': 47290}
,
...
,
{'itemcode': '287310',
'etfTabCode': 2,
'itemname': 'KBSTAR 200경기소비재',
'nowVal': 8820,
'risefall': '5',
'changeVal': -245,
'changeRate': -2.7,
'nav': 8814.0,
'threeMonthEarnRate': -5.3649,
'quant': 160,
'amonut': 1,
'marketSum': 7}]}}JSON 데이터를 얻어온 것을 확인할 수 있다!
type은 dictionary이다. 친절도 해라! 바로 dict로 가져와주다니!
따라서 딕셔너리를 다루듯이 다루며 원하는 데이터를 가져올 수 있다.
json을 보기 힘들다면 크롬에 익스텐션을 설치하든, 다양한 방법으로 잘 보도록 하자.
여기는 가장 큰 밖에 resultcode와 result라는 키가 있고,
result의 value(dict)에 etfitemList라는 키가 있고,
그 value(list)에 각 etf들의 정보가 담겨있는 dict들이 들어있다!
복잡해라! 이 정도는 파악해보자!
어쨌든 그래서 원하는 데이터를 이렇게 얻어온다.
etfItemList = etf_json["result"]["etfItemList"]
print(len(etfItemList))
etfItemList[-1]
>>>
622
{'itemcode': '287310',
'etfTabCode': 2,
'itemname': 'KBSTAR 200경기소비재',
'nowVal': 8820,
'risefall': '5',
'changeVal': -245,
'changeRate': -2.7,
'nav': 8814.0,
'threeMonthEarnRate': -5.3649,
'quant': 160,
'amonut': 1,
'marketSum': 7}이 JSON 역시 데이터프레임으로 바꿀 수 있다.
데이터프레임을 만드는 방법으로 nparray, series, 마지막으로 dictionary 가 있던 것을 떠올려보자!
우리가 원하는 etfitemList(딕셔너리들이 모여있는 리스트였다.)를 인자로 주고 데이터프레임을 제작한다! 각 딕셔너리들의 키가 모두 동일하고, 그것들이 데이터프레임의 column이 된다!
df = pd.DataFrame(etfItemList)여기서 또 신기한 걸 배웠다... 바로 split! 그 문자열 메소드 split 맞다.
데이터프레임의 한 컬럼(시리즈)에 대해 .str 접근자로 split()을 사용하여 그 컬럼에 있는 문자열들을 모두 split 해준다.
근데 이 때! split(expand = True)라는 인자를 주게되면, 나누어진 문자열들이 list로 존재하지 않고, dataFrame의 새로운 column으로 나타나게 된다! 와!
예시로 보자.
df["itemname"].str.split()
>>>
0 [KODEX, 200]
1 [TIGER, 차이나전기차SOLACTIVE]
2 [KODEX, KOFR금리액티브(합성)]
3 [KODEX, 200선물인버스2X]
4 [TIGER, 미국나스닥100]
...
617 [ARIRANG, 코스닥150]
618 [KBSTAR, 200커뮤니케이션서비스]
619 [KBSTAR, 200에너지화학]
620 [KBSTAR, 200산업재]
621 [KBSTAR, 200경기소비재]
Name: itemname, Length: 622, dtype: object반면, expand = True를 주면,
df["itemname"].str.split(expand=True)
>>>
0 1 2 3 4
0 KODEX 200 None None None
1 TIGER 차이나전기차SOLACTIVE None None None
2 KODEX KOFR금리액티브(합성) None None None
3 KODEX 200선물인버스2X None None None
4 TIGER 미국나스닥100 None None None
... ... ... ... ... ...
617 ARIRANG 코스닥150 None None None
618 KBSTAR 200커뮤니케이션서비스 None None None
619 KBSTAR 200에너지화학 None None None
620 KBSTAR 200산업재 None None None
621 KBSTAR 200경기소비재 None None None
622 rows × 5 columns데이터프레임의 컬럼들로 나뉘어진다! 뭐 알고 있자!
이를 이용해 데이터프레임에 새로운 컬럼을 추가한다.
df["운용사"] = df["itemname"].str.split(expand=True)[0]와 이런거 진짜 잘 하고 싶다... 어떻게 잘하지?
데이터 프레임을 좀 잘 다루고 싶다! 파이팅!
이렇게 json 데이터를 크롤링하고, 데이터프레임에 저장하는 방법까지 배웠다.
그리고 마지막으로는 파일로 보내고, 읽어오는 과정을 했다.
그 과정에서 배운것은 흠
Datetime의 .strftime() 메소드에 관한 것!
today = datetime.today().strftime("%Y-%m-%d")저렇게 지정해주면 yyyy-mm-dd형식으로 출력된다.
그리고 또, 읽어올때 컬럼의 dtype을 지정해서 읽어올 수 있다는 것!
이건 좀 잘 알아둬야 할 듯!
pd.read_csv(file_name, dtype={"itemcode":"object"})그렇다!
이렇게 2주차! 아직 2주차였네! 수업이 모두 끝났다.
이번 주에는 결석이 많아서 따라잡는데 애 좀 썼지만, 그래도 재밌는 내용들을 많이 다루었던 것 같다. 그리고 좀 더 실전적이어서 좋았다!
웹 크롤링을 하는 기초적인 방법에 대해 알게 된 것 같고, 그렇게 수집한 정보를 데이터프레임으로 저장하고, 그 데이터프레임을 보기 좋도록 가공하는 방법까지 배웠다.
데이터의 수집도 신기하고 공부 많이 해야겠다 생각했지만, 특히 데이터프레임을 다루는 부분에 대해 많이 공부해야겠다는 생각을 했다! 판다스 파이팅!
음 아쉬운게 있다면,,, API! 이번 주에 API에 대해서도 강의를 해 주셨는데, 솔직히 REST API가 뭔지 전혀 이해하지 못했다... 전혀!
차차 시간 날때 꼭 그 부분 보충 공부를 해야겠다. 고생했다!
