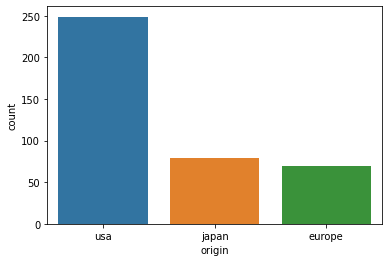
결석했다! 공부하자!
22.10.02 합니다!
0107-범주형 변수 EDA
범주형 변수의 EDA와 수치형 변수의 EDA가 막 크게 다르진 않다.
다루는 기술 통계 값들이 조금 다르고, 시각화 할때 사용하는 그래프의 종류가 조금 다르다.
범주형 변수 역시 df.shape df.info() df.describe(include = "object")를 사용하여 간단한 정보 및 기술통계 값을 확인할 수 있다. 주의할 점은 범주형 변수가 꼭 object dtype이 아니라, bool, int, float으로 되어있을 수도 있다.
수치형변수의 기술통계 값으로는 평균, 표준편차, 4분위값 등이 나왔던 반면,
범주형 통계에서는 도수, 고유값의 수, 최다 출현 값 및 그 빈도수 가 나온다.
결측치 역시 수치형 변수와 마찬가지고 .isnull()을 통해 확인한다.
결측치의 수와 비율 역시 .sum()과 .mean()을 통해 확인할 수 있다.
.unique()의 경우 Series 에만 적용할 수 있는 메소드지만, .nunique()의 경우 Series와 DataFrame 모두에 적용할 수 있다.
Countplot
countplot을 이용해 범주형 변수의 빈도수를 시각화할 수 있다.
sns.countplot(data=df, x="origin")
도수 구하기
1개 변수의 도수는 .value_counts()를 이용해 구할 수 있다.
df["origin"].value_counts()2개 이상의 변수에 대한 도수는, countplot으로 시각화하여 확인하거나, crosstab()을 사용하여 구한다.
sns.countplot(data=df, x="cylinders", hue="origin")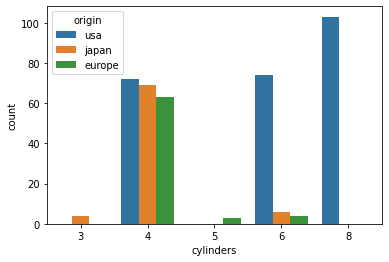
pd.crosstab(index=df["origin"], columns=df["cylinders"])
>>>
cylinders 3 4 5 6 8
origin
europe 0 63 3 4 0
japan 4 69 0 6 0
usa 0 72 0 74 103위가 바로 crosstab 기능이다. 약간 피벗테이블 같은 느낌으로, 2개 변수에 대한 도수를 표현할 수 있다.
bar plot
bar plot에 대해 생각해보자.
sns.barplot(data=df, x="origin", y="mpg", ci=None)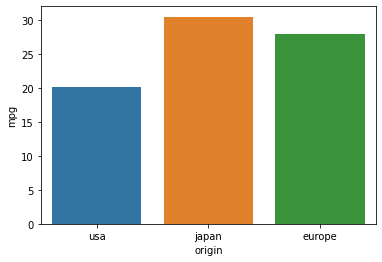
위의 bar plot 에서 y축이 의미하는 것은 다름 아닌 origin 별 mpg의 평균이다. 개별 도수가 아니다.
origin은 범주형 변수이고, mpg는 수치형 변수이다.
group by
group by를 통해 범주형 변수에 대해 그룹화 한 후 수치형 변수에 대해 연산할 수 있다.
df.groupby("origin")["mpg"].mean()
>>>
origin
europe 27.891429
japan 30.450633
usa 20.083534
Name: mpg, dtype: float64위 코드는 bar plot 에서 나타나는 y 값과 동일한 코드이다.
다시 한번 주의 할 점은, 저렇게 하면 Series 형태이고,
df.groupby(["origin"])[["mpg"]].mean()
>>>
mpg
origin
europe 27.891429
japan 30.450633
usa 20.083534이렇게 ['origin']으로 사용하면 DataFrame 형태가 된다는 것이다.
- Pivot table
피벗테이블은 사실 그룹바이를 통해서도 충분히 구할 수 있는 값들을 더욱 쉽게 보여준다.
위에서 그룹바이로 구한 값을, 아래 피벗 테이블을 통해 동일하게 구한다.
pd.pivot_table(data=df, index="origin", values="mpg")
>>>
mpg
origin
europe 27.891429
japan 30.450633
usa 20.083534그룹바이로 구하면 좀 복잡한 느낌이 있지만, 피벗 테이블을 활용한다면 직관적이고 간단하게 구할 수 있기에 다음과 같이 사용한다.
pivot table의 기본 연산은 mean으로 설정되어 있다.
그룹 바이를 여러 컬럼에 대해 수행해 Multi index를 만들 수 있다. 이를 통해 Stack 시킬 수도 있다.
df.groupby(["origin", "cylinders"])["mpg"].mean()
>>>
origin cylinders
europe 4 28.411111
5 27.366667
6 20.100000
japan 3 20.550000
4 31.595652
6 23.883333
usa 4 27.840278
6 19.663514
8 14.963107
Name: mpg, dtype: float64stack된 모습이다.
다시 unstack 할 수도 있다.
df.groupby(by=["origin", "cylinders"])["mpg"].mean().unstack()
>>>
cylinders 3 4 5 6 8
origin
europe NaN 28.411111 27.366667 20.100000 NaN
japan 20.55 31.595652 NaN 23.883333 NaN
usa NaN 27.840278 NaN 19.663514 14.963107unstack(0) 또는 unstack(1)로 어떤 index를 column으로 바꾸어줄 지 결정할 수 있다.
위의 값은 아래 피벗테이블의 실행 값과 동일하다.
pd.pivot_table(data=df, index="origin", columns="cylinders", values="mpg")
>>>
cylinders 3 4 5 6 8
origin
europe NaN 28.411111 27.366667 20.100000 NaN
japan 20.55 31.595652 NaN 23.883333 NaN
usa NaN 27.840278 NaN 19.663514 14.963107시각화해서 보고자 한다면 다음과 같이 수행할 수 있다.
# cylinders 와 mpg 의 x, hue 값을 변경해서 시각화
sns.barplot(data=df, x="cylinders", y="mpg", hue="origin", ci=None)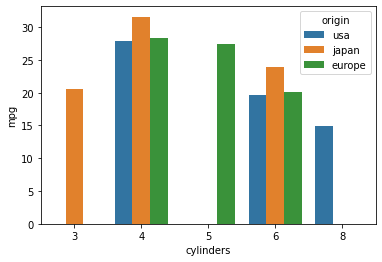
.pivot_table() 말고 .pivot() 기능도 있는데, 피벗테이블은 sum이나 mean 등 연산 값을 보여준다면, pivot은 연산 없이 해당하는 값을 보여준다고 한다.
Box plot
# europe 에 해당되는 값에 대해 boxplot 그리기
plt.figure(figsize=(10, 2))
sns.boxplot(data=df[df["origin"] == "europe"], x="mpg")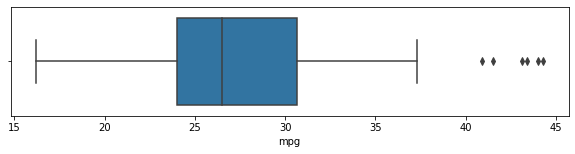
box plot 에서 등장하는 다양한 기술통계 값을 직접 구할 수도 있다. 다음과 같이 구한다.
# groupby로 origin 값에 따른 mpg의 기술통계 구하기
# 결과를 변수에 할당하여 재사용하기
desc = df.groupby("origin")["mpg"].describe()
eu = desc.loc["europe"]
# 기술통계값 구하기
Q3 = eu["75%"]
Q1 = eu["25%"]
IQR = Q3 - Q1
OUT_MAX = (1.5*IQR) + Q3
OUT_MIN = Q1 - (1.5*IQR)boxen plot
boxen plot은 또 처음보는 plot이다.
box plot에 좀 추가적인 자료들이 더해진 형태이다. box plot 과 violin plot이 더해진 느낌?
구체적인 설명을 찾지 못했다... 강사님은 box plot의 수염 부분을 더 자세히 표현한 것이라고 설명하셨나 보다.
box plot -> boxen plot -> violin plot의 순으로 구체적이라 볼 수 있겠다.
# boxenplot 그리기
plt.figure(figsize=(10, 2))
sns.boxenplot(data=df[df["origin"] == "europe"], x="mpg")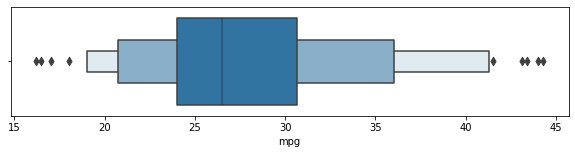
산점도를 통한 범주형 데이터 표현
scatterplot
sns.scatterplot(data=df, x="origin", y="mpg")
점이 겹쳐서 보여 제대로 파악할 수 없다는 단점이 있다.
stripplot
sns.stripplot(data=df, x="origin", y="mpg")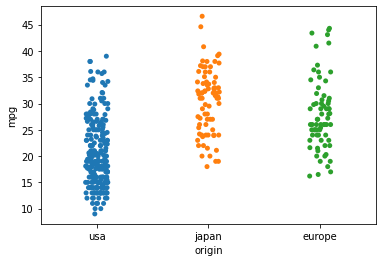
scatterplot에 비해 좀 퍼져 있어 파악하기 비교적 쉽지만, 여전히 어렵다.
Swarmplot
plt.figure(figsize=(12, 4))
sns.swarmplot(data=df, x="origin", y="mpg")
점이 겹쳐지지 않고 옆으로 펼쳐져 있어 빈도수까지 비교하기 쉽다.
Catplot
catplot을 통해 stripplot, swarmplot, boxplot, violinplot 등 다양한 그래프를 Facetgrid를 이용해 subplot으로 표시할 수 있다.
# catplot 으로 boxplot그리기
sns.catplot(data=df, x="origin", y="mpg", kind="box", col="cylinders", col_wrap=3)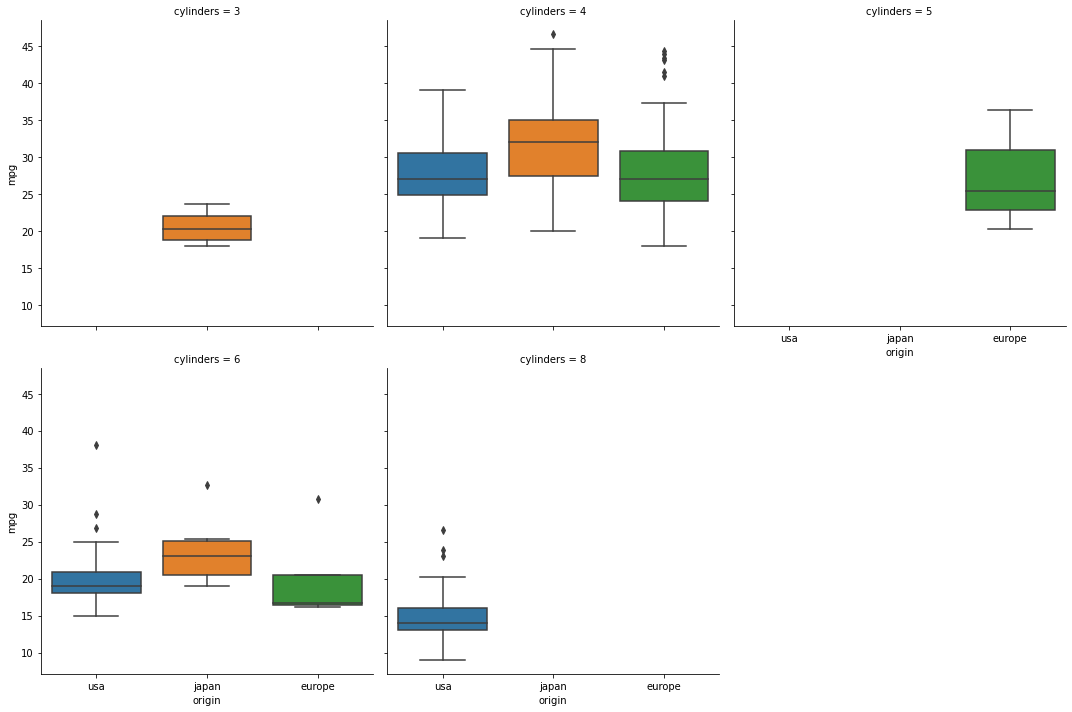
# catplot 으로 violinplot그리기
sns.catplot(data=df, x="origin", y="mpg", kind="violin", col="cylinders", col_wrap=3)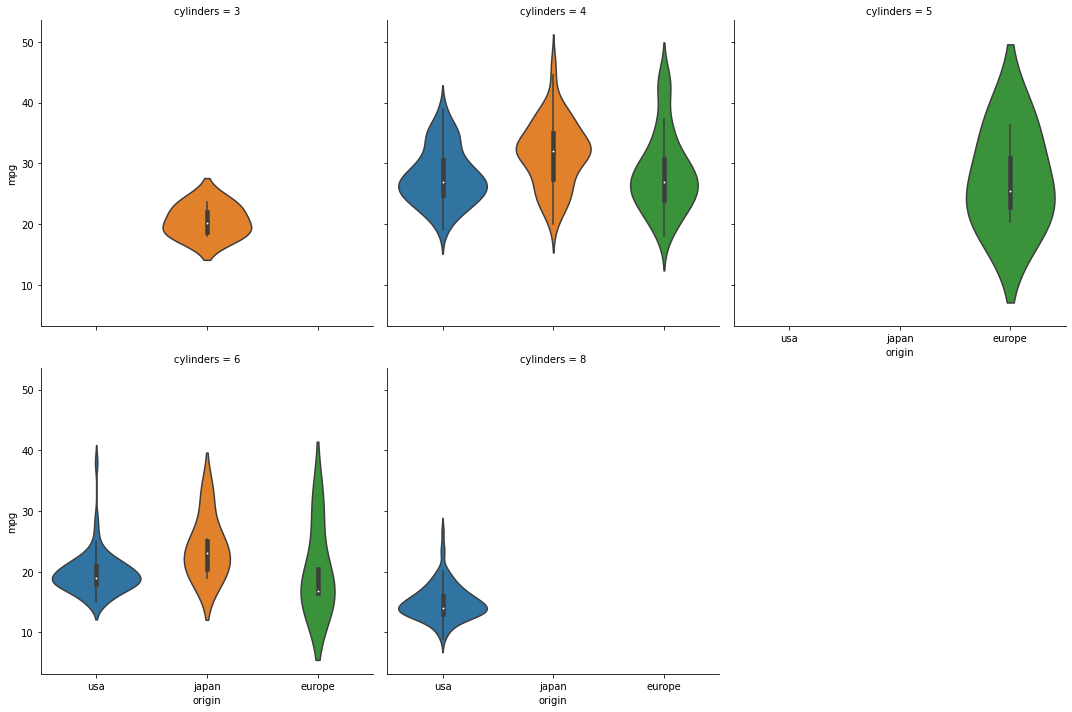
# catplot 으로 countplot그리기
sns.catplot(data=df, x="origin", kind="count", col="cylinders", col_wrap=3)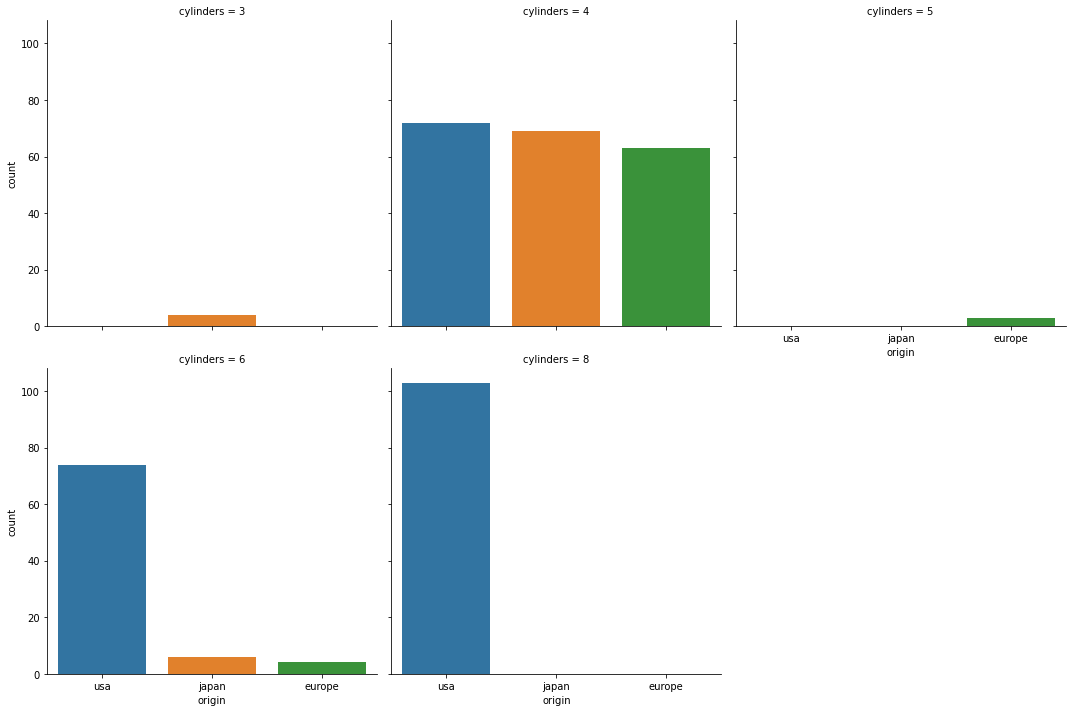
violinplot
violonplot의 split 옵션에 대해 더 알아보고싶은데!
violon plot을 그릴때, hue를 이용해 두 가지 데이터를 표시하지만 subplot을 나누어주진 않았을 때, split =True 옵션을 추가하면, violinplot의 왼쪽과 오른쪽에 각각 다른 데이터가 보여지게 된다.
예시는 다음과 같다.
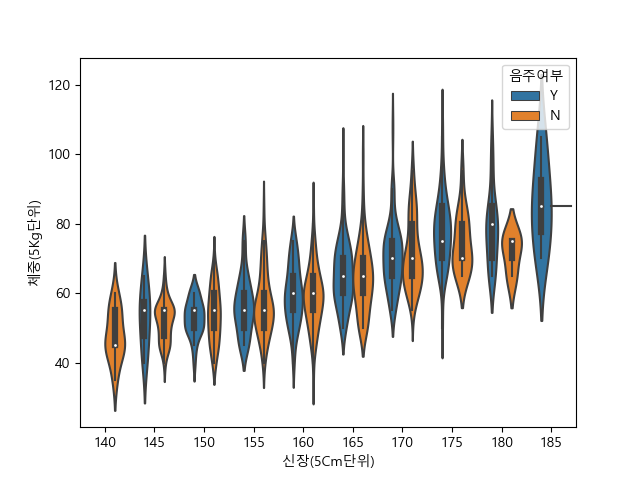
해당 그래프에서, split = True를 추가하면?
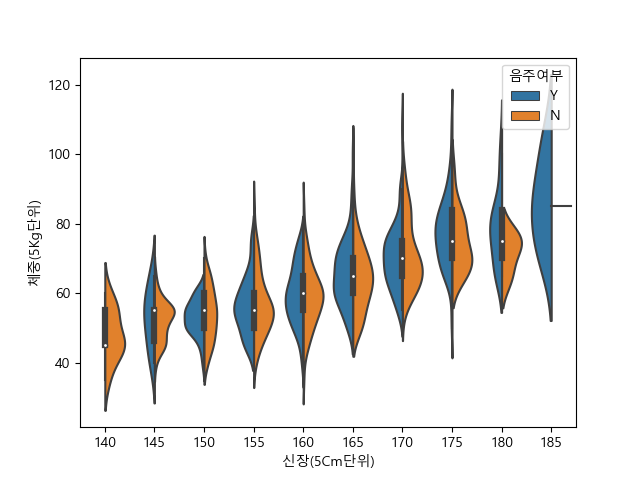
요렇게 된다!
실습 파일 중 마땅하게 hue를 넣어 violinplot을 그릴 게 없더라..
EDA
그렇게 EDA 파트가 모두 끝났다.
강사님이든, 멘토님이든, EDA의 중요성을 정말정말 여러번 말씀해 주셨다. 실무에서도 사실상 EDA를 위해 사용하는 시간이 전체의 70%는 된다고도 하셨고, 좋은 모델을 찾아 적용하는 것 만큼 데이터의 전처리를 잘해주는 것이 중요하다는 것을 알게 되었다.
그런데! 아직 EDA가 뭔지 감이 잘 오지 않아서! 1주차에 다른 팀이 발표했던 자료를 참고하며 추가적으로 공부해보려 한다! 자료를 너무 잘 만들어 주셨더라...!
시작해보자.
EDA, exploratory data analysis : 탐색적 데이터 분석 이다.
탐색적, 데이터, 분석? 흠... 무슨 말일까?
지금까지 공부한 느낌 상으로 볼때는, 정제되지 않은 raw data를 탐색하여 우리가 어떤 주제로 어떤 분석을 할지 결정하기 위해 하는 작업이 EDA일 것 같다.
다시 말해서, 데이터 자체를 보고 여러가지 통계값들이나 결측치, 이상치를 탐색하여 데이터 분석을 위한 밑작업을 해나가는 과정이 EDA인 것 같다!
기술통계를 활용해 데이터의 분포와 이상치를 탐색하고, 시각화하는 과정을 거쳐 주어진 데이터에서 증거를 찾는 일. 데이터를 이해하고, 어떻게 분석할지 결정하고 가설을 세우는 것. 이 바로 EDA라고 한다.
EDA는 분석하고자 하는 데이터가 Univariate냐, Multivariate냐 에 따라서 목적과 방법이 달라진다. 또한 그래픽을 사용하느냐 사용하지 않느냐에 따라서도 방법이 달라진다.
- 단변량 비그래픽
표본분포에 대한 이해와 이상치 발견을 목표로 함.
평균, 중앙값, 최빈값, 분산, IQR, 왜도, 첨도 등을 파악 - 단변량 그래픽
히스토그램, 박스플롯 등 시각화의 방법을 사용해 데이터의 전체적인 분포를 이해하고 이상치를 확인하는 등을 목표로 함 - 다변량 비그래픽
변수 사이의 관계를 보여주기 위해 교차표, 상관계수 등의 통계량 사용 - 다변량 그래픽
변수간 분포 관계를 확인하기 위한 boxplot, heatmap 등의 그래프 사용
EDA의 분석 수단으로는,
원본 데이터의 관찰, 요약 통계량 관찰, 데이터 시각화 등이 있다.
EDA의 절차를 간단히 살펴보면,
먼저 전체적인 데이터를 분석하며 분석의 목적과 사용할 변수를 정하고,
데이터의 type과 이상치, 결측치를 확인하는 등의 행위를 한다.
그 후 데이터의 개별 속성값을 관찰하여, 전체적인 추세와 특이사항을 관찰한 후 데이터에 개별 속성에 어떤 통계 지표가 적절한지 결정한다.
마지막으로는 속성간의 관계를 분석해 개별 속성만 볼 때에는 알지 못했던 것을 파악한다.
kaggle - EDA 예시를 참고해보자! 우와 진짜 대단하네... 기가 막힌다.. 공부 열심히 해야겠다 진짜.. 언제 저런거 해보냐!
최근 데이터 분석 관련 공부를 시작하며, 새삼 들었던 생각이 이 분야에서 일을 하기 위해서는 데이터 자체를 이해하고, 잘 활용하는 능력이 필수적이겠구나 였다. 그게 결국 EDA를 잘 한다는 말인 것 같다.
EDA에 대해 확실히 공부하고, 계속 연습하여 실제 데이터 분석 능력을 길러보자! 말로만 말고! 헤보면서 공부하면 되는거지!
0201 - financedatareader
다음으로 나가는 진도는 웹 크롤링이다! 엄밀히 말하자면 데이터 수집! 을 배웠나보다.
FinanceDataReader
FinanceDataReader 사용자 안내서 | FinanceData
이번 실습에서는 FinanceDataReader 라이브러리를 사용했다. (아직까지도 라이브러리랑 모듈이 막 헷갈린다. ㅠㅠㅠ)
어쨌든, 해당 라이브러리는 다양한 주식시장의 정보를 가져올 수 있는 라이브러리이다.
라이브러리 설치 및 import
!pip install -U finance-datareader
import pandas as pd
import numpy as np
import FinanceDataReader as fdr한국거래소 상장 전체 종목 가져오기
df = fdr.StockListing("KRX")사실 모든 실습에서, 우리는 데이터의 EDA를 어느정도 진행했었다.
시작은 항상 df의 shape, head, tail, info, describe를 보았다.
좀 신기한걸 해본 듯 하다. 해당 library의 github에 들어가서, 소스코드를 살펴보며 한국거래소 종목을 어떻게 가져오는지 알아낸다.
다음과 같다.
url = 'http://kind.krx.co.kr/corpgeneral/corpList.do?method=download&searchType=13'
df_listing = pd.read_html(url, header=0, flavor='bs4', encoding='EUC-KR')[0]따라서 해당 url을 이용해 직접 read_html()을 통해 데이터를 가져와보는 실습을 했나보다.
url = 'http://kind.krx.co.kr/corpgeneral/corpList.do?method=download&searchType=13'
pd.read_html(url)잠깐, pd.read_html()에 대해 알아보자.
pandas의 함수로, html문서를, 정확히는 html 문서 내부의 table 태그를 읽어와 pandas의 dataframe 형태로 저장할 수 있다. 정확히는 존재하는 table 들을 list 형태로 가져오고, 그 table들이 df 형식이다.
따라서 html 태그에 table 이 있고, 우리가 그 데이터만 수집하려고 하는 경우에는 굳이 requests와 bs를 사용하지 않고 pd.read_html 로도 충분히 동작을 해낼 수 있다.
0202 - 네이버금융 기사 수집
본격적인 웹크롤링에 대해 배운다.
url
그렇기 위해 먼저 url의 구성에 대해 배웠다.
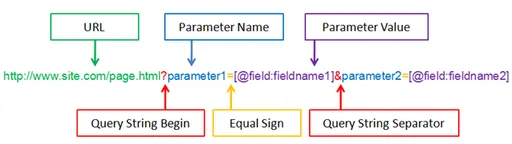
URL은 이렇게 기본 URL에 query string이 덧붙여져 있는 형태로 구성되어있다.
url 뒤에 ?가 쿼리 스트링의 시작을 의미한다.
그 후 parameter name = parameter value 형태로 스트링이 진행되고, & 기호로 parameter와 paremeter를 이어준다.
위와 같이 query string을 사용해 데이터를 전달하는 방식은, http 요청 중 GET 방식에 해당된다. 따라서 해당 url을 통해 요청을 보낼 때에는 get을 사용하면 되겠다.
그런데, 이런 querystring이 변화하는 것이 브라우저 창에서 보이지 않는 경우가 있다. 이럴 경우 page url을 어떻게 해야할까?
첫번째로는 selenium을 사용하여 스크래핑 하는 방법이 있다.
selenium을 사용하면 이런 변하지 않는 url에 대해서도 스크래핑 할 수 있다.
하지만 그러지 않고도, url을 찾아낼 수 있다.
바로 크롬 개발자도구의 network 탭에서 찾을 수 있다.
우리가 페이지를 바꾸어가며 데이터를 추출할 거라면, network 탭을 켜놓고 페이지를 바꿀 때 생기는 여러 요소들을 살펴보면 된다.
주로 doc에 html 파일이, jS에 json 형식의 데이터가 있으므로, 해당 요소의 header에 있는 url을 이용할 수 있다.
자세한 설명은 다음에!
pandas로 데이터 수집
차치하고, pandas만을 사용해 데이터를 먼저 수집해 보았다. 앞에서 배운 pd.read_html을 사용했다.
url의 parameter가 들어갈 자리에 f-string을 이용해 변수를 넣어 url을 설정해준다.
item_code = 403550
page_no = 1
url = f"https://finance.naver.com/item/news_news.nhn?code={item_code}&page={page_no}&sm=title_entity_id.basic&clusterId="
table = pd.read_html(url, encoding="cp949")
그럼 위와 같이 table이라는 변수에 스크래핑한 결과를 담을 수 있고, 해당 변수는 list 형태를 가진다.
해당 url에 존재하는 모든 table들을 담고 있기 때문!
그럼 이제 우리가 원하는 table이 몇 번째 table인지를 알아내어, 그것만 사용하면 된다. 여기서는 0번째 테이블이 우리가 원하는 기사들이 있는 테이블이다.
마지막 테이블은 페이지가 넘어갈 수 있게 버튼이 있는 테이블이며, 그 사이 테이블들은 연관기사가 담겨 있는 테이블들이다.
아래 사진 참고!
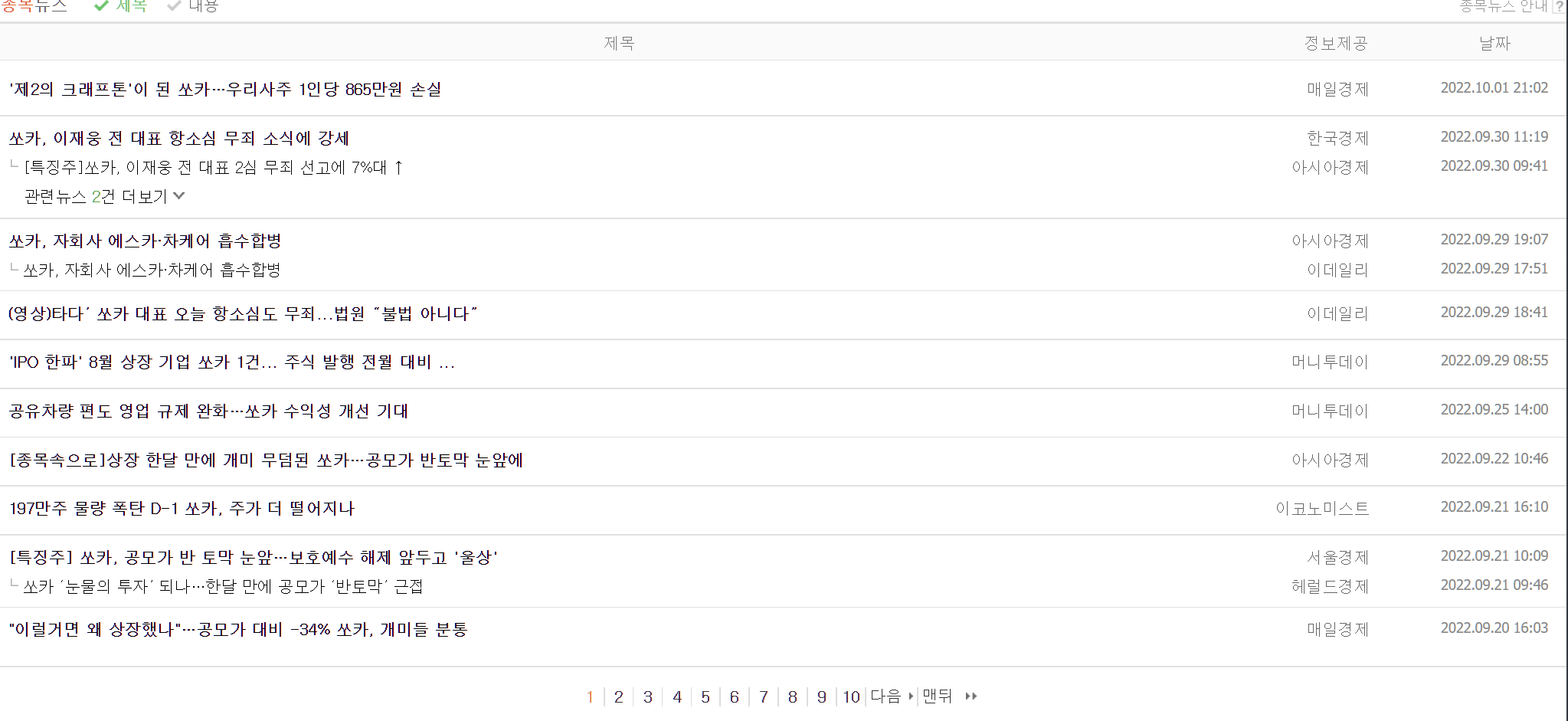
우리는 연관기사 까지 모두 포함해 기사 목록을 스크래핑 하려고 한다. 따라서 마지막 테이블인 page navigation을 제외한 모든 테이블들을 하나로 병합한다! 다행히도 각 column에 담겨있는 내용이 동일하니까!
해당 과정은 for문을 이용한다. temp_list라는 list를 만들어, 해당 list에 우리가 원하는 데이터프레임들을 요소로 추가한다. 이때 컬럼 이름을 같게 해주는 작업까지 한다.
이렇게 하는 이유는, 이 데이터프레임들을 하나로 합치기 위해 concat을 사용할 것인데, concat의 입력값으로 df들이 들어있는 list가 가능하기 때문이다.
공식문서를 보면, concat의 objs로는 a sequence or mapping of Series or DataFrame objects가 가능하다고 나와있다.
temp_list = []
cols = table[0].columns
for news in table[:-1]:
news.columns = cols
temp_list.append(news)이렇게 temp_list를 만든 후, concat한다.
df_news = pd.concat(temp_list)이제 원하는 데이터의 수집은 완료했고, 데이터들을 탐색하고 이상치 등을 처리해주는 작업이 남아있다.
먼저, concatenate하는 과정에서 index가 이상하게 꼬였으므로, reset_index를 해준다. 이때, 본래 index가 column이 되면 안되고 사라져야 하므로, drop = True 파라미터를 잊지 않는다.
df_news = df_news.reset_index(drop=True)결측치를 제거하는 과정도 거친다.
df_news = df_news.dropna()그리고, 데이터를 살펴보면, 기사가 아니라 '연관기사 목록'이 포함되어 있는 데이터들이 있다. 이런 원하지 않는 데이터를 삭제해주는 과정을 거친다.
'연관기사 목록' 이라는 문자열이 포함되는 데이터를 찾기 위해서는 str method를 사용해야 하므로, 접근자를 사용한다.
.str.contain을 사용하면 된다.
df_news = df_news[~df_news["정보제공"].str.contains("연관기사")].copy()해당 코드를 살펴보면, .str.contains("연관기사")를 통해 df_news에서 정보제공 column에 연관기사가 들어가있는 행들을 찾았다.
그 후, ~(not)을 사용하여, df_news중 정보제공 column에 연관기사가 들어가있지 않은 데이터들만! 값을 복사해 df_news에 저장해줬다.
복사를 왜 해줬는가! 흠... 왜 해준거지..? 이해가 전혀 안되는데..?
.copy()를 사용하지 않고, 그냥 변수에 대입하게 되면 얕은 복사를 해준 셈이 된다. 그러나, 얕은 복사의 경우 변수의 값이 바뀌면 원본과 복사본 간의 참조가 계속 일어나 오류가 발생할 가능성이 있다. 따라서 안전하게 사용하고자 깊은 복사 .copy()를 사용한다.
얕은 복사와 깊은 복사에 대한 내용은 아래와 같다.
copy
shallow copy(얕은 복사)와 deep copy(깊은 복사)가 있다.
항상 주의해야 한다!!!Shallow copy(얕은 복사)
s2 = s1 과 같이 변수에 다른 변수를 대입시킴으로써 일어난다.변수의 값을 변경시키면, 원본 변수읙 값 역시 변경된다.
Deep copy(깊은 복사)
.copy()를 사용해 복사함으로써 일어난다.
원본 변수와 같은 값을 가지되 메모리 값은 다른 변수가 하나 생기는 것이다.
따라서 변수의 값이 변화되어도 원본의 값에 영향을 끼치지 않는다.
마지막으로, 중복 값이 있다면 제거한다.
df_news = df_news.drop_duplicates()사실 잘 이해가 안가는 부분. 원래 테이블[0]만 보아도, 연관기사가 모두 들어있었는데, 굳이 concat을 해야할 이유가 있었을까?
아마 concat에 대해서 설명해주려고 그러셨을 것이다!
함수 만들기
그럼 이제 위에서 진행한 내용을, 하나의 함수로 만들어보자.
먼저, url 주소를 만들어주는 함수부터!
def get_url(item_code, page_no):
"""
item_code, page_no 를 넘기면 url 을 반환하는 함수
"""
url = f"https://finance.naver.com/item/news_news.nhn?code={item_code}&page={page_no}&sm=title_entity_id.basic&clusterId="
return url
item_code="035720"
page_no = 5
temp_url = get_url(item_code, page_no)
print(temp_url)함수 만들때, """ """ 으로 doc string 넣는 것을 습관화하자!
다음은 이제, 한 페이지에 있는 기사들을 모두 긁어오는 함수!
def get_one_page_news(item_code, page_no):
"""
get_url 에 item_code, page_no 를 넘겨 url 을 받아오고
뉴스 한 페이지를 수집하는 함수
1) URL 을 받아옴
2) read_html 로 테이블 정보를 받아옴
3) 데이터프레임 컬럼명을 ["제목", "정보제공", "날짜"]로 변경
4) temp_list 에 데이터프레임을 추가
5) concat 으로 리스트 병합하여 하나의 데이터프레임으로 만들기
6) 결측치 제거
7) 연관기사 제거
8) 중복데이터 제거
9) 데이터프레임 반환
"""
url = get_url(item_code, page_no)
table = pd.read_html(url, encoding="cp949")
temp_list = []
cols = table[0].columns
for news in table[:-1]:
news.columns = cols
temp_list.append(news)
df_news = pd.concat(temp_list)
df_news = df_news.dropna()
df_news = df_news.reset_index(drop=True)
df_news = df_news[~df_news["정보제공"].str.contains("연관기사")].copy()
df_news = df_news.drop_duplicates()
return df_news함수를 만들때, 먼저 이 함수가 어떤 순서로 어떤 동작을 할 지 pseudo code를 짠 후 만든다.
예를 들어, 이 함수의 pseudo code는 다음과 같다.
1) URL 을 받아옴
2) read_html 로 테이블 정보를 받아옴
3) 데이터프레임 컬럼명을 ["제목", "정보제공", "날짜"]로 변경
4) temp_list 에 데이터프레임을 추가
5) concat 으로 리스트 병합하여 하나의 데이터프레임으로 만들기
6) 결측치 제거
7) 연관기사 제거
8) 데이터프레임 반환그렇게 체계적으로 함수를 만드는 능력을 잘 길러봐야겠다! 라는 생각이 막 들었다.
웹 스크래핑
그리고 웹 스크래핑 관련 여러 이론 설명도 하셨나보다!
get이 아까 앞에서 말한대로 query-string을 이용해 데이터를 전달하는 방식이라면, post는 body의 form data에 담아 전송하는 방식이라는 것!
데이터를 수집할때 robots.txt를 확인하여 수집해도 되는 페이지인지를 확인한 후 진행해야 한다는 것! 등!
그리고 html과 css에 대한 간단한 설명과, css에서 id는 #으로, class는 .으로 접근하는 것!
웹 스크래핑시 time.sleep()을 통해 무리한 네트워크 요청을 방지하여 서버가 다운되거나 ddos 공격으로 오인받는 일을 막아야 한다 등!
을 배운 것 같다!
이렇게 결석한 둘째 날 까지의 수업내용 따라잡기가 모두 끝났다!
흠... 실습을 제대로는 한 것 같지 않아서.. 열심히 한번 해봐야겠다.
내일은 수요일 수업 내용 복습하고, 그동안 공부했던 내용들을 제대로 한번 velog에 정리해보는 시간을 가지자! 프로젝트 마무리하고!
고생했다!
