이번 주 SQL 수업은 조건문과 피벗테이블에 대해 배웠다!
지금 막 생각나는 건,,,
조건문은 CASE WHEN THEN END를 이용해 사용했다는 것!과
피벗테이블은 조건문을 통해 열을 나누어주고, 그룹바이를 통해 행을 나누어 만들었다는 것!
그럼 본격적으로 복습을 헤보자! 몇몇 문제풀이 빼고는 간단했었다!
SELECT 절에서의 집계함수
SELECT 절에서 다양한 집계함수를 사용할 수 있었다.
SUM()
MAX()
MIN()
COUNT()
AVG()
등이 있었다!
대량의 데이터셋을 볼 때에는 데이터 자체를 보기보다, 집계함수를 통해 다양한 요약통계 및 기술통계 값들을 보며 데이터를 탐색한다! (결국 EDA)
GROUP BY
- 해커랭크 문제풀이
진짜 애쓰고 애썼던 문제! 근데 되게 허탈했던!
Q. We define an employee's total earnings to be their monthly worked, and the maximum total earnings to be the maximum total earnings for any employee in the Employee table. Write a query to find the maximum total earnings for all employees as well as the total number of employees who have maximum total earnings. Then print these values as space-separated integers.
The Employee table containing employee data for a company is described as follows:
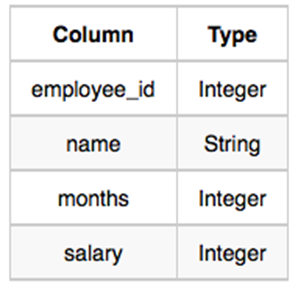
- 내 풀이
SELECT salary*months as total
,COUNT(*)
FROM Employee
GROUP BY total
HAVING total = (SELECT MAX(salary*months) FROM Employee)
일단 SELECT 절에서 우리가 원하는 earning(total)을 정의해줬고, 그 earning에 해당하는 사람을 세주기 위해 count(*) 했다.
그런데, 가장 큰 earning(total)만 가져올 방법을 생각하지 못해, HAVING 절에서 조건을 걸어줬다. 이때, MAX(total)로 최댓값을 구하면 오류가 나서, (SELECT MAX(salary*months) FROM Employee)로 최댓값을 구했다.
- 더 효율적인 풀이
최댓값 혹은 최솟값, 상위 및 하위 몇개의 값만 표시할 때에는...... ORDER BY 를 사용했다! 이걸 까먹네.
SELECT salary*months AS earnings, COUNT(*)
FROM employee
GROUP BY earnings
ORDER BY earnnings DESC
LIMIT 1
그리고 여기서, having절에서 total에 집계함수를 쓸 수 없던 것과 관련하여!
SQL 문의 간단한 동작 순서를 알아보자.
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT -> ORDER BY라고 한다!! 따라서, HAVING 절이나 WHERE절 에서는 Alias를 못 쓰는것이 맞다. 원칙적으로는 GROUP BY 에서도 사용하지 못하지만, MySQL에서는 사용할 수 있다고 한다.
조건문(CASE, If)
오늘의 본격적인 주제! 바로 조건문이었다.
조건문은 크게 두가지가 있다. 바로 if와 case이다.
If
IF문은 다음과 같이 사용한다.
IF (조건, 참일때의 값, 거짓일 때의 값)CASE
CASE문은 다음과 같이 사용한다.
CASE WHEN 조건 THEN 참일때의 값
WHEN 조건2 THEN 참일때의 값
...
ELSE 모두 거짓일때의 값
ENDCASE문은 여러 조건에 대해 사용할 수 있다.
첫번째 조건부터 검사하며, 만족하지 않을 경우 다음 조건을 검사하는 형식으로 이루어진다.
ELSE를 써주지 않으면 조건이 거짓일 때 NULL값이 반환된다.
따라서, IF문은 조건이 하나이면서, 거짓일때 특정 값을 반환해야할 때 사용하고,
CASE문은 조건이 여러개거나,
조건이 하나이면서 거짓일 때에는 NULL로 남겨놓아야 할 경우에 사용하곤 한다.
주의해야할 점이 있는데, SQL에서 조건을 줄 때, 두가지 이상의 조건을 한번에 적을 수 없다!
무슨 소리냐면, A=B=C와 같이 쓰면 안된다는 뜻이다.
반드시 A=B AND B=C와 같은 방식으로 사용한다.
피봇 테이블
피봇테이블!
최근에 판다스에서도 보고, SQL에서도 보고 아주 많이 보고있다.
근데 사실 이때까진 피봇테이블이 뭐고, 왜 사용하는 지 감이 안 왔었다.
그런데 생각해보자. 데이터를 살펴보는데, 두 가지 기준에 대해 살펴보고 싶다. 이때 그 두가지 조건에 대해 그룹화 해 살펴본다면, 행에서만 조건이 나누어져 뭔가 보기 어지러울 것이다.
반면, 피봇테이블을 사용해 행에서 하나의 기준, 열에서 하나의 기준에 대해 나눌 수 있다면, 훨씬 보기 편해질 것이다.
심지어 피봇테이블을 이용해 두가지 기준에 대해 평균이나 최댓값, 개수 등 집계함수를 적용한 값을 알 수 있다.
SQL을 이용해 피봇테이블을 만드는 방법은, 방금 위에서 말한 피봇테이블의 제작 목적을 생각하면 쉽게 알 수 있다.
먼저 CASE 등의 조건문을 통해, 여러 열(column)을 만들어준다. 열 방향의 기준을 생성해주는 것이다! 이때 집계함수를 적용할 수도 있다.
그리고 GROUP BY를 통해, 행 방향으로 나눌 기준을 정하고 여러 행으로 나누어준다!
그렇게 간단하게 SQL에서 피봇테이블을 만들 수 있다.
예시는 다음과 같다.
SELECT AVG(CASE WHEN Categoryid= 1 then price ELSE NULL END) AS category1_price
, AVG(CASE WHEN Categoryid= 2 then price ELSE NULL END) AS category2_price
, AVG(CASE WHEN Categoryid= 3 then price ELSE NULL END) AS category3_price
FROM Products
GROUP BY region- 리트코드 문제풀이(1179)
또 애먹은 문제! 음.. 그룹바이 하는 과정에서 어려움이 있었다!
문제를 간단히 요약하자면, 자료에는 id, 월, 그리고 revenue가 담겨있었다.
문제는 피봇테이블을 통해 id별, 각 월별 revenue를 확인하는 것이었다.
그래서 이렇게 풀었다.
SELECT id
,(CASE WHEN month = "Jan" THEN revenue ELSE NULL END) AS Jan_Revenue
,(CASE WHEN month = "Feb" THEN revenue ELSE NULL END) AS Feb_Revenue
, ...
,(CASE WHEN month = "Nov" THEN revenue ELSE NULL END) AS Nov_Revenue
,(CASE WHEN month = "Dec" THEN revenue ELSE NULL END) AS Dec_Revenue
FROM Department
GROUP BY id
그랬더니 틀렸다!
답은 이거였다.
SELECT id
,SUM(CASE WHEN month = "Jan" THEN revenue ELSE NULL END) AS Jan_Revenue
, SUM(CASE WHEN month = "Feb" THEN revenue ELSE NULL END) AS Feb_Revenue
, ...
, SUM (CASE WHEN month = "Nov" THEN revenue ELSE NULL END) AS Nov_Revenue
, SUM (CASE WHEN month = "Dec" THEN revenue ELSE NULL END) AS Dec_Revenue
FROM Department
GROUP BY id
사람들이 GROUP BY 한 값에는 무조건 집계함수를 써줘야 합니다! 라고 했는데 이해가 되지 않았다.
알고 보니 이런 문제가 있었다.
내가 쓴 코드에서, 처음에 들어오는 데이터가 id 1번의 1월 revenue 데이터였다면, SELECT문을 거치며, id 1번의 2월부터 12월까지 revenue는 NULL이라는 값을 가지게 된다.
마찬가지로 코드가 진행하다보면, 해당 데이터에서 나타나는 월이 아니라면 그 id의 다른 월의 revenue들은 모두 NULL이라는 값을 가지게 된다.
따라서 내가 쓴 코드로는 각 id에 대해 처음(혹은 마지막으로) 나오는 월들에 대해서만 revenue가 출력되고, 나머지 월들에 대해서는 모두 NULL이 출력되게 되는 것이다!
와 이럴수가...! 진짜 충격이었다. 전혀 생각하지 못했다.
따라서, CASE 연산 과정에서 생겼을 NULL 값 들이 아니라, 우리가 진짜로 원하는 revenue 값을 최종 테이블에 표시하기 위해, 각각의 월에 대해 SUM을 해줘야 한다.
각각의 월은 revenue값으로 여러개의 NULL값과, 데이터에서 존재하는 실제 revenue값을 가지기 때문이다! 따라서 SUM으로 우리가 진짜 원하는 값을 구해준다.
와 이건 진짜 충격적이었다. 꼭 기억해놓고 있어야 할 문제 같다. 그룹화하고 조건문 연산을 했을 때 이런 문제가 생길 수 있다!
그래서 사람들이 한 말이 이해가 된다. 그룹화 한 후엔 무조건 집계함수를 쓰라고!
RFM Segmentation
고객 세분화 모형 중 실무에서 자주 사용하는 모형
R은 Recency, 얼마나 최근에 구매했는지.
F는 Frequency, 얼마나 자주 구매했는지.
M은 Monetary, 얼마나 많은 금액을 구매했는지를 의미한다.
고객에 대한 데이터가 있을때, SQL을 통해 RFM Segmentation을 수행할 수 있다.
이렇게 얻은 결과로, 고객들을 특성에 따라 구분하여 적절한 마케팅 전략을 펼칠 수 있다! 아주 중요하다.
R,F,M에 대해 각각을 나누는 기준은 상황에 맞게 사용한다.
뭐 한달 사이 구매가 있으면 R이 1 아니면 0이라던지, 더 나누어 0,1,2로 나눈다던지!
아주 재미있고 흥미로웠다!
데이터셋을 이용해서 직접 나누어보기도 했다!
SQL에서의 EDA
파이썬에서와 마찬가지로, 전체 데이터의 구성을 살펴보고, 몇개의 자료만 살펴보고, 통계값을 살펴보고 하는 등 다양한 탐색을 진행할 수 있다. 아주 중요하다!
이 정도가 이번주 SQL 수업에서 배운 내용이다.
확실히 파이썬이랑은 다른데 생각보다 재미있다.
아 과제 있는거 까먹지 말자!
JOIN까지 강의 듣기랑, 연습문제 풀기!
문제 많이 풀면서 감을 익히자! 파이팅!
