22.10.04.
오늘은 데이터 수집에 대한 수업 마지막 날!
여태까지 배운 내용을 총 정리하면서, 웹에서 데이터를 수집할 때 사용할 만한 스킬들을 더 배웠다.
시작!
0205 - 게시글 목록 스크래핑
먼저 지난 주 실습에 이어서, 간단히 목록에 있는 게시글들의 정보를 스크래핑 하는 실습을 진행했다.
이번 실습에서는 서울정보소통광장 페이지의 다산콘센터 주요 민원 목록을 스크래핑했다. 120 주요질문 페이지
정확히 어떤 정보를 스크래핑하냐면, 목록 번호, 제목, 생산일, 조회수, 내용번호, 내용, 분류 를 스크래핑 할 것이다.
먼저, 데이터를 어떻게 스크래핑 할 지 생각해봐야겠다.
여태까지 배운 내용을 생각해보자.
-
GET과 POST 요청.
GET요청은 쿼리스트링에 정보를 담아 전송하는 방법이었고, POST 요청은 Form Data에 정보를 담아 전송하는 방법이었다. 따라서 Get 요청을 사용할 경우 URL을 바꾸어가며 정보를 요청한다.
-
pd.read_html vs requests + bs
수집하려는 데이터가 웹 페이지 내 table 태그에 들어있다면, pandas의 read_html 함수를 통해서 간단히 데이터프레임 형태로 스크래핑 할 수 있었다.
그렇지 않고 다른 태그에 들어있다면, requests로 요청을 보낸 후 beautifulsoup로 parsing하여 태그를 찾는 과정을 진행해야 했다.
이번 사이트에서는, 목록의 페이지 번호가 바뀔때마다, URL의 page = 1, 2, 3, ... 으로 바뀌는 것을 보아 GET 요청을 이용한다. 그리고, 우리가 원하는 게시글 목록 정보가 table 태그에 들어있으므로 read_html 함수를 이용한다.
코드는 다음과 같다.
import numpy as np
import pandas as pd
import requests
from bs4 import BeautifulSoup as bs
import time
base_url = "https://opengov.seoul.go.kr/civilappeal/list?items_per_page=50&page=1"
table = pd.read_html(base_url,encoding = "utf-8")이때, encoding = 'utf-8'을 넣어주었다. 거의 모든 파일의 기본 인코딩이 utf-8이라고 하였는데, 굳이 또 써준 이유는 colab에서의 인코딩이 맞지 않아 글씨가 깨져 보였기 때문이다.
이 코드의 실행 결과로, 해당 url의 html에 들어있는 모든 table 태그가 table이라는 list안에 저장된다. 운 좋게도 table 태그가 하나밖에 없다.
그런데 문제가 있다. '내용 번호'와 '내용', '분류'는 해당 table에 존재하지 않는 정보이다. 해당 정보들은, 목록의 각 민원들을 클릭했을 때 이동하는 url에 존재하고, 그 url에 접속했을때 나오는 페이지에 존재한다.
이런 table에 존재하지 않는 정보들은, requests와 BeautifulSoup를 이용하여 스크래핑한다.
requests, BeautifulSoup
사용법은 이미 많이 공부했었고! 그럼 한 번 사용해보자.
URL은 이미 정의해놨고, get 요청을 보내야한다는 것도 파악했고. 요청을 보내고 response를 parsing 한다.
response = requests.get(base_url)
html = bs(response.text,'html.parser')자 일단 찾을 준비는 되었다.
그럼 이제 무얼 어떻게 찾을지를 생각해보자.
먼저, '내용 번호'는 요소를 클릭했을 때 연결되는 URL의 마지막에 존재한다고 하였다.
그럼 해당 정보는 a 태그의 href를 통해 알 수 있을 것이다. 그럼 href를 가지고 있는 a 태그를 찾아서 내용번호를 수집할 수 있다.
그 후에 그 내용번호를 이용해 민원의 상세 정보 페이지를 요청하여, 그 페이지 내부에서 우리가 원하는 '분류'를 찾아낼 수 있을 것이다.
일단 a 태그를 찾아 '내용 번호'를 찾는 것에 집중하자.
find_all 함수도 사용할 수 있고, select 함수도 사용할 수 있다.
SELECT
먼저 SELECT 함수이다. 많이 안써봐서 많이 낯설다!
크롬 브라우저의 '검사' 메뉴를 통해 원하는 a 태그의 소스코드에 접근한다. 그 후 copy selector를 통해 해당 태그의 CSS Selector를 복사하고, select 함수에 사용할 수 있다.
그렇게 복사해낸 selector는 다음과 같다.
#content > div > div.view-content > div > table > tbody > tr:nth-child(1) > td.data-title.aLeft > a뭐가 굉장히 복잡하다. 다시 상기해보자면, #은 ID를 의미하고, .은 클래스를 의미한다.
그러니까 위의 selector는 대충 id가 content인 요소 내부 div 태그 내부 class가 view-content인 div 태그 내부
...
class가 data-title 과 aLeft인 td 태그 내부 a태그 라는 것이다.
이해할 만 한가? 일단 뭐 그럭저럭 이해 된다.
그런데, 중간에 보면 tr:nth-child(1)가 있다.
여기서 중요한 점, SELECT 함수에 사용하는 selector에는 자식 또는 형제 정보를 포함하지 않는다.
따라서, tr:nth-child(1) 는 tr로 바꾸어준다.
그리고, 너무 길다. 보통 마지막 한 두개의 셀렉터만 써도 제대로 선택되는 경우가 많다. 선택되지 않는다면 유동적으로 조정한다!
실습을 하며 다른 사람들이 쓴 코드를 보니, 기계적으로 copy selector를 이용하지 않고, 태그의 구조적인 위치를 파악하여 복사한 값을 잘 수정해 쓰는 것이 중요하다 느꼈다! 예를 들면 우리가 원하는 태그가 특정 id를 가지고 있어도, copy selector는 그 id를 selector에 담아주지 않는다.
돌아돌아왔지만, select를 이용해 우리가 원하는 a 태그를 이렇게 찾는다.
a_list = html.select('td.data-title.aLeft > a')select는 그 selector에 해당하는 모든 태그를 찾아 list에 저장하는 것이었고, select_one이 처음 나오는 태그만 찾는 것이었다!
find_all
그렇다면, find_all을 이용해서도 한번 찾아보자.
html.find_all('a')find_all을 이용할 때 이렇게 처음부터 너무 광범위한 값에서 찾으면, 원하지 않는 정보가 너무 많이 담긴다.
따라서, 단계별로 find를 사용하여 최대한 검색 범위를 좁힌 뒤 찾거나, class와 id 등을 사용하여 찾는 범위를 좁힌다.
따라서 다음과 같이 원하는 값을 구해낼 수 있다.
a_list = html.find('tbody').find_all('a')진짜로 원하는 값은, 해당 태그의 href에 있는 url 주소(ex : /civilappeal/10924244)의 마지막 숫자 값이다.
이렇게 찾아낼 수 있다.
a_list[0]['href'].split('/')[-1]해당 값들을 list에 저장한 후, 다른 정보들이 담겨있던 table에 저장한다.
a_link_no = []
for a_tag in a_list:
a_link_no.append(a_tag['href'].split('/')[-1])
table[0]['내용 번호'] = a_link_no
# table은 리스트고, 그 안에 들어있는 요소가 df였음에 유의한다.개인적으로 감탄한 부분, 위의 과정들을 아주 쉽게 짧은 코드로 바꾸어 쓸 수 있다. comprehension을 이용한다.
table[0] = [ a['href'].split('/')[-1] for a in a_list ] 와 진짜 생각도 못했다. 어떻게 저렇게 할 생각을 하지?
진짜 짱이다...... 나도 언제쯤 저렇게 할 수 있을까 라고 하기엔 코드를 짜본적이 없으니.. 실습 많이 하자! 진짜로!
함수 제작하기
또 중요했던 부분! 내가 최근에 어려워했던 부분이기도 하다!
우리가 원하는 동작을 구현하는 함수를 제작한다.
오늘 관련해서 아주 중요한 기술을 배웠다.
바로 pseudo code를 쓰는 것이다.
pseudo code
pseudo code란, 실제 코드가 아니라 프로그램이 어떤 동작을 할 것인가를 간단하게 설명하는 코드이다.
프로그래밍을 할 때, 알고리즘의 동작 방식을 설명할 때 등 상당히 많이 사용한다.
pseudo code를 작성하는데 규칙은 없지만, 몇가지 통용적인 rule 이 있었던 것 같은데... 기억이 안난다. 언제 공부했었는지도...! 공부를 제대로..! 하자..!
어쨌든, 오늘 pseudo code를 작성하는 것이 아주 중요하다는 것을 배웠다. 무언가 프로그램을 짜기 전, 어떤 동작을 어떤 순서로, 어떤 방법으로 수행하여 작동하게 할 것인가를 미리 그려본 후, 프로그래밍 해야 체게적이고 효과적으로 잘 할 수 있을 것이다.
그리고 pseudo code를 쓸 때 주의해야 할 점을 확실히 배웠다. 바로, 구체적으로 쓰는 것이다! 최대한 구체적으로 작성한다.
이런 예시를 들어주셨다. 라면을 끓이는 의사 코드(pseudo code)를 작성한다고 할 때, 물 500ml를 끓인다. 스프를 넣는다. 와 같은 형태로 작성했다면, 심각한 오류가 있다.
스프를 뜯지도 않고 통째로 넣어버린 것이다! 이 이야기를 듣고 좀 이해가 갔다. 최대한 구체적으로 작성해야 하겠다!
그럼 다시 돌아가서, 우리가 지금껏 수행했던 기능을 모아놓은 함수를 제작해보자.
결론적으로 몇 페이지인지를 인자로 받아 웹 페이지의 목록에 있는 정보들과, url에 있는 '내용번호' 정보를 담은 dataframe을 반환하는 함수를 제작한다.
먼저 pseudo code를 짜본다.
강사님이 짜주신 코드는 다음과 같다.
1) page_no 마다 url이 변경되게 f-sting 을 사용해 만든다.
2) requests 를 사용해서 요청을 보내고 응답을 받는다.
3) pd.read_html 을 사용해서 table tag로 게시물을 읽어온다.
4) 3번 결과에서 0번 인덱스를 가져와 데이터프레임으로 목록의 내용을 만든다.
5) html tag를 parsing할 수 있게 bs 형태로 만든다.
6) 목록 안에 있는 a tag를 찾는다.
7) a tag 안에서 string 을 분리해서 내용번호만 리스트 형태로 만든다.
8) 4)의 결과에 "내용번호"라는 컬럼을 만들고 a tag의 리스트를 추가한다.구체적이게 작성해야 한다는게 어떤 건지 이걸 보니 좀 이해가 된다!
이 코드를 바탕으로, 실제 함수를 제작하였다.
def get_one_page(page_no):
""" docstirng 쓰는 습관 들이자. 여기선 생략 """
base_url = f"https://opengov.seoul.go.kr/civilappeal/list?items_per_page=50&page={page_no}"
response = requests.get(base_url)
table = pd.read_html(response.text)[0]
html = bs(response.text)
a_list = html.select("td.data-title.aLeft > a")
table["내용번호"] = [a_tag["href"].split("/")[-1] for a_tag in a_list]
return table
기본적으로 위의 코드들을 종합한 코드인데, 좀 더 가독성있고 간단하게 바꾸어주었다.
먼저, 동일한 url에 대해 요청을 두번 보내지 않도록 바꾸어 주었다.
원 코드에서는, pd.read_html과 requests를 각각 url에 대해 사용함으로써, url에 요청을 두 번 보냈었다. 그러나, 지금은 requests를 어차피 사용함을 알고 있으므로, requests로만 요청을 보내고 read_html에는 response.text를 인자로 주었다.
두번째로, table에 애초에 dataframe을 저장해주었다.
read_html을 수행한 결과의 [0]번 인덱스가 우리가 찾는 df 였으므로, table = ~~[0]으로 작성해주었다.
마지막으로, 앞에서도 언급했듯 comprehension을 사용해 df에 새로운 컬럼을 추가하는 과정을 간단하게 만들었다.
Error 처리
그런데, 이 함수에 문제가 있다. 우리가 원하는건 목록에 있는 민원들의 정보이므로, 반복문을 이용해 이 함수를 돌려 모든 페이지에 대한 정보를 확인해야 한다.
하지만, 마지막 페이지를 모르므로 마지막 페이지를 넘어서는 페이지에 대해서는 오류가 발생한다.
해당 오류를 처리해주자.
Error 원인 찾기
오류를 처리하기 위해서는 먼저 함수의 어느 부분에서 오류가 발생하는지를 알아야겠다.
그래서 목록에 아무것도 존재하지 않는 페이지에 접속해봤다. table은 존재하나, 그 안에 아무것도 존재하지 않는 형태이다.
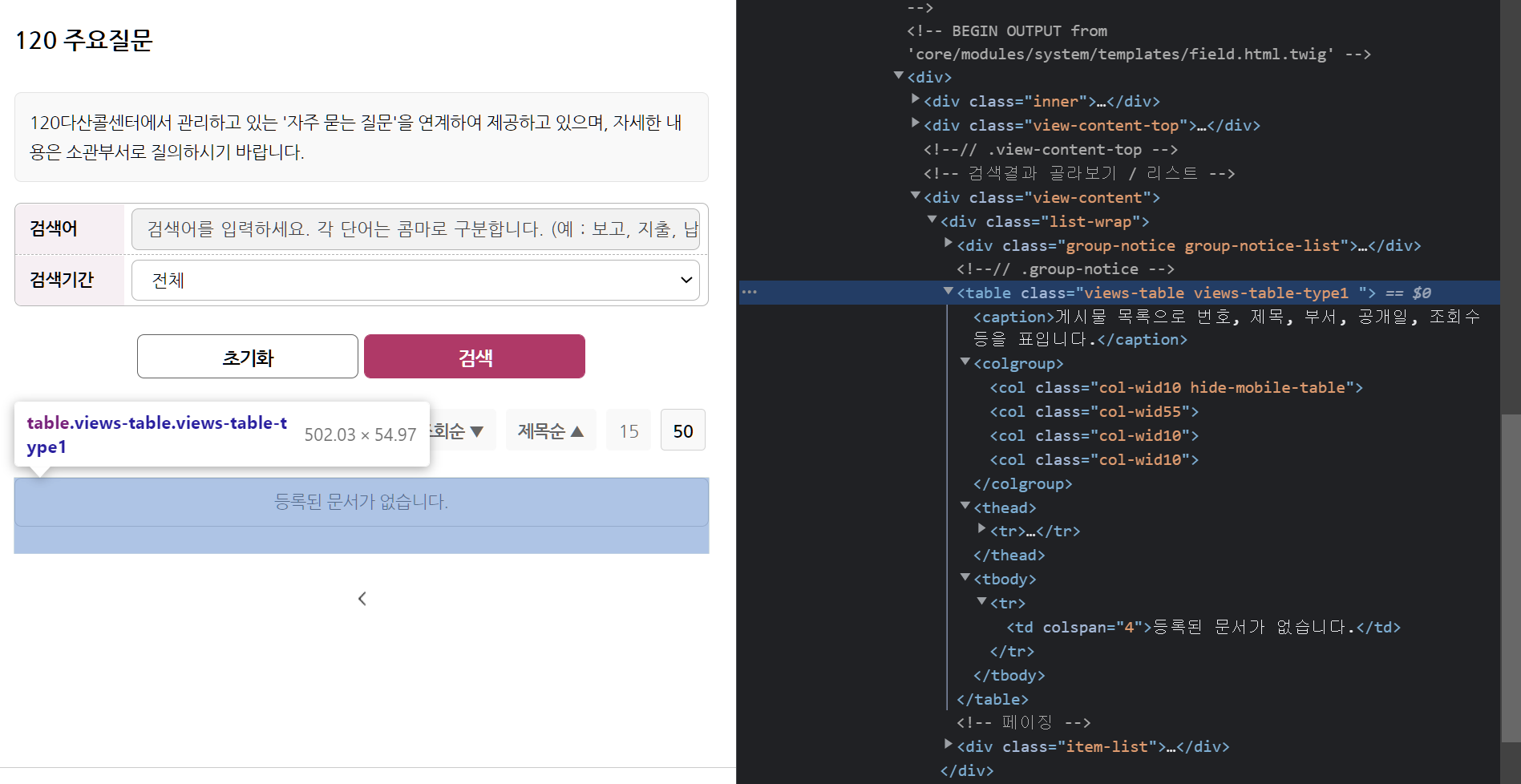
함수를 살펴보면, 이런 페이지에 대해 함수를 실행했을 때 오류가 발생할 만한 부분은 바로
table = pd.read_html(response.text)[0]부분이다. read_html 의 결과가 빈 리스트이므로, 0번 인덱스에 아무것도 존재하지 않는다.
Try - Except 문
그럼 문제가 되는 부분을 처리해주자. 에러 처리에 가장 많이 사용하는 구문은 바로 try - except 구문이다. 다음과 같다.
~~~
try :
실행할 코드
exception :
오류가 나면 실행할 코드
~~~코드가 진행하다 try 구문을 만나면, 해당 코드를 실행한다. 그리고 만약 오류가 발생하면, exception 문 안의 코드를 실행한 후 다음 코드를 실행한다.
오류가 발생하지 않으면 exception 구문은 건너뛴다.
이와 비슷하게 try ~ finally 구문도 있었다.
finally는 except처럼 오류가 발생할 시 실행한다는 점이 같지만, except와는 달리 오류가 발생하지 않아도 실행한다!
이런 try ~ except 구문은 함수를 반복적으로 돌리고 싶을 때, 중간에 오류가 발생하여 멈추는 경우를 방지해준다.
따라서 우리가 짠 함수엔 이렇게 적용할 수 있다.
def get_one_page(page_no):
base_url = f"https://opengov.seoul.go.kr/civilappeal/list?items_per_page=50&page={page_no}"
try :
response = requests.get(base_url)
table = pd.read_html(response.text)[0]
html = bs(response.text)
a_list = html.select("td.data-title.aLeft > a")
table["내용번호"] = [a_tag["href"].split("/")[-1] for a_tag in a_list]
except :
# raise Exception('해당 페이지에 정보가 없습니다.')
return '해당 페이지에 정보가 없습니다.'
return table
except에 raise Exception을 사용하면, 해당 에러메시지와 함께 프로그램의 동작이 종료되어버린다. 이는 우리가 원하는 일이 아니므로 오류 메시지를 return 하여, 프로그램의 동작은 멈추지 않도록 하였다.
그런데, 위 코드는 단지 코드를 수행하여 오류가 나면 오류 메시지를 리턴해주기만 할 뿐이다.
근본적으로 오류가 날 것인지 안 날 것인지 파악하여 코드를 수행하기 이전에 미리 동작을 멈출 수 있다면 훨씬 효율적일 것이다.
따라서, 오류가 날 것인지 파악하는 기준을 만든다.
이 함수의 경우, table이 비어있다면, 즉 table의 행이 0개라면 오류가 발생하는 것이었으므로, 다음과 같은 코드를 추가할 수 있다.
if table.shape[0] == 0:
return f"{page_no}페이지를 찾을 수 없습니다."table.shape의 결과는 (행,열) 이므로 [0]은 행의 개수이다.
try - except 구문 이전에 이 함수를 추가한다면, 훨씬 효율적인 동작이 가능하다. 다음과 같다.
def get_one_page(page_no):
base_url = f"https://opengov.seoul.go.kr/civilappeal/list?items_per_page=50&page={page_no}"
if table.shape[0] == 0:
return f"{page_no}페이지를 찾을 수 없습니다."
try :
response = requests.get(base_url)
table = pd.read_html(response.text)[0]
html = bs(response.text)
a_list = html.select("td.data-title.aLeft > a")
table["내용번호"] = [a_tag["href"].split("/")[-1] for a_tag in a_list]
except :
# raise Exception('해당 페이지에 정보가 없습니다.')
return '해당 페이지에 정보가 없습니다.'
return table이렇게 error 처리까지 가능한 함수를 제작해보았다.
반복문으로 데이터 수집
이제 반복문을 이용해 여러 페이지를 수집하자.
반복문 내에서 함수를 사용하면 되겠다.
반복문을 언제까지 돌릴것인가를 알지 못하는 상황이므로, while문을 이용한다. 그리고 반복문을 멈출 기준을 정해야한다.
어떻게 정할 수 있을까? 앞에서 한 것 처럼 table의 행의 개수가 0개라고 정하면 어떨까?
그렇게 반복문을 작성해보자.
page_no = 1
table_list = []
while True :
df_temp = get_one_page(page_no)
print(page_no, end = ',')
if df_temp.shape[0] == 0:
print("수집이 완료되었습니다.")
break
table_list.append(df_temp)
page_no += 1
time.sleep(0.01)
오류가 발생한다. str은 shape라는 속성을 가지고 있지 않단다.
이게 무슨 소린가 생각해보니, 우리가 위에서 정의한 함수의 리턴값을 df_temp라고 해주었는데, 모든 페이지를 넘어가 더이상 정보가 없는 페이지에 대해, 리턴값은 '해당 페이지에 정보가 없습니다.'라는 str 타입이다.
str 타입에 대해 .shape attribute를 이용하려 했으니, 당연히 오류가 날 수 밖에 없다.
그러면 어떻게 기준을 정해야할까?
앞의 기준을 사용할 수 없던 이유에 집중하자. 더 이상 정보가 없을 경우, 함수의 리턴값이 str 타입이었기에 오류가 났다.
그렇다면, 함수의 리턴값이 str이 되는 순간, 반복문을 더이상 돌리지 않으면 되겠다!
따라서 해당 기준 하에 반복문을 작성한다.
page_no = 1
table_list = []
while True :
df_temp = get_one_page(page_no)
print(page_no, end = ',')
if type(df_temp) == str:
print("수집이 완료되었습니다.")
break
table_list.append(df_temp)
page_no += 1
time.sleep(0.01)이렇게 반복문을 통해 여러 페이지에 대해 원하는 정보를 수집할 수 있었다.
팁이라면, 반복문의 조건을 정하고 실험을 해 볼때에, page_no를 1로 두고 시작한다면 우리가 찾고자하는 부분(오류가 발생하거나 잘 동작하는지 확인할 수 있는 부분, 마지막 페이지)까지 너무 오래걸리므로, 중간 정도의 숫자로 잘 조절하며 시험해본다.
데이터 병합 및 파일 저장
데이터를 병합하고, 파일로 저장하는 부분은 간단하다.
앞의 반복문에서, table_list라는 list 안에 각 페이지별로 함수를 적용하여 얻은 table들을 저장해두었으므로, concat 함수를 통해 다음과 같이 병합한다.
df = pd.concat(table_list)파일로 저장하는 것 역시 쉽다.
file_name = "seoul-120-list.csv"
df.to_csv(file_name,index = False)이렇게 0205 파일의 실습 내용이 끝났다.
정리해보자. 정리! 와 많네 생각보다.
일단 뭐 하는 실습이었냐?
한 사이트에서, 목록에 나와있는 민원에 대한 여러 정보를 수집하는 실습이었다.
수집하고자 하는 정보에는 table에 들어있는 정보도, 들어있지 않은 정보도 있어 read_html과 requests, bs를 적절히 활용하여 수집할 수 있었다.
그리고, 특정 페이지에 있는 정보를 수집하는 함수를 제작했다.
해당 함수를 사용해 반복문을 돌려 모든 페이지에 대해 정보를 수집하고자 했다.
함수를 만들 때, 에러처리를 해주었고, 반복문의 기준을 에러가 발생했다면, 즉 리턴값이 str이라면 멈추는 것으로 정해주어 적절히 활용할 수 있었다.
하지만, 실습에서 아직 하지 않은 부분이 있는데, 바로 각 민원마다 상세 링크로 접속하여 거기에서 또 정보를 수집해야 했다.
해당 실습은 다음파일, 0206에서 진행한다.
0206 - 링크에 접속하여 데이터 수집
(반복문 없이)
와 너무 늦었다...! 이번 실습에서 무엇을 할 지 먼저 간단히 요약하겠다.
앞의 실습에서 미처 끝내지 못한 프로젝트를 진행한다.
앞에서 거의 모든 정보를 수집하여 dataframe으로 저장해두었다. 그러나, '내용번호'를 이용하여 접속할 수 있는 상세 링크에서 확인해야하는 '내용' 및 '분류' 정보는 수집하지 못했다.
이번 실습에서는 따라서 상세 링크에 접속해 '분류' 정보를 수집하여, 우리가 만들어둔 dataframe에 추가해주는 과정을 거칠 것이다. 단, 반복문은 사용하지 않는다! 이게 포인트!
이걸 잘 이해하고, 시작하자!
일부 데이터에 대해서만 먼저! 수집
우리가 데이터를 수집할 때, 처음부터 모든 데이터를 수집하려고 하면 시간도 오래걸리고, 어디서 에러가 발생하는지도 찾기 힘들며, 해당 서버에도 과부하가 올 수 있다.
따라서, 데이터를 수집할 때 항상 일부 데이터에 대해서만 먼저 수집해보며 코드를 작성한 후 모든 데이터를 수집하는 것이 좋다.
먼저, 하나의 상세 민원 사이트에 접속해 살펴보며, 어떤 정보를 어떻게 수집해야 할지 살펴보자.
접속해보면, 우리가 찾으려는 '내용' 정보는 특정 태그 안에, '분류' 정보는 테이블에 저장되어 있다.
따라서 먼저 requests를 이용해 '내용'을 수집하고, 그 다음에 read_html을 통해 '분류'를 수집해보자.
requests, beautifulsoup (내용)
다음과 같이 할 수 있다.
url = "https://opengov.seoul.go.kr/civilappeal/view/?nid=23194045"
response = requests.get(url)
html = bs(response.text)
content = html.select('div.view-content.view-content-article > div > div.line-all')[0].get_text()select를 통해 우리가 원하는 '내용' 이 있는 태그를 선택했다.
그 후, .text attiribute로 해당 태그의 텍스트만 content라는 변수에 저장하였다.
혹은 .get_text() method를 이용할 수도 있다.
read_html (분류)
자 일단, read_html을 이용해 table들을 찾아보자.
table = pd.read_html(response.text)[-1]
table
>>>
0 1 2 3
0 원본시스템 다산콜센터 제공부서 서울산업진흥원
1 작성자(책임자) 120다산콜재단 생산일 2021-06-29
2 관리번호 D0000042894548 분류 경제table 태그가 2개 있는데, 그 중 두번째가 우리가 원하는 '분류' 값이 들어있는 태그이다. 따라서 table이라는 변수에 [-1]로 우리가 원하는 table을 저장해준다.
이때, table의 모양이 좀 이상하다.
우리가 생각하기에 column에 들어가 있어야 할 것 같은 값들이 모두 element로 들어가있다.
심지어, 우리가 찾아야 하는 column인 '분류' 역시 그렇다.
이를 처리해주는 방법을 배웠다.
- 데이터를 예쁘게 만드는 방법!
데이터프레임을 자르고, 인덱스를 바꾸고, 전치시킨다!
다음과 같이 진행해보자.
table[[0,1]].set_index(0)
## 0번과 1번 컬럼만 가져가서 0번 컬럼을 인덱스로 설정해준다.
>>>
1
0
원본시스템 다산콜센터
작성자(책임자) 120다산콜재단
관리번호 D0000042894548ta01 = table[[0,1]].set_index(0).T
## transpose 시켜, 데이터를 이쁘게 만들어준다.
>>>
원본시스템 작성자(책임자) 관리번호
1 다산콜센터 120다산콜재단 D0000042894548[2,3] 컬럼에 대해서도 다음처럼 진행할 수 있다.
ta02 = table[[2,3]].set_index(2).T
>>>
제공부서 생산일 분류
3 서울산업진흥원 2021-06-29 경제이렇게 우리가 원하는 분류 column이 생성되었다.
프로젝트의 목적에 맞게, 그냥 이대로 '내용'을 원래 있던 df에 추가하고, 분류가 있는 dataframe에 '내용 코드'를 추가해주어 이 역시 원래 df에 join(merge?) 할 수 있겠지만,
배우는 김에 저렇게 잘라서 이쁘게 만든 데이터를 다시 이쁘게 합치는 법도 배워야지!
concat을 사용한다. 단, concat은 원래 행방향으로 합쳐주므로 axis =1 인자를 넣어준다.
pd.concat([ta01,ta02],axis =1)
>>>
원본시스템 작성자(책임자) 관리번호 제공부서 생산일 분류
1 다산콜센터 120다산콜재단 D0000042894548 NaN NaN NaN
3 NaN NaN NaN 서울산업진흥원 2021-06-29 경제원하는 결과로 나오지 않는다. 왜 그런가 봤더니 각 df가 가지고 있는 data의 index가 다르다!
따라서 index를 통일시켜준다.
ta02.index = ta01.index
pd.concat([ta01,ta02],axis = 1)
>>>
원본시스템 작성자(책임자) 관리번호 제공부서 생산일 분류
1 다산콜센터 120다산콜재단 D0000042894548 서울산업진흥원 2021-06-29 경제잘 합쳐진 것을 볼 수 있다!
ta02.index = ta01.index 로 인덱스를 동일하게 맞춰주었다.
아마 둘 다 인덱스를 초기화하는 방법도 있을 것 같다.
원래는 ignore_index = True인자를 concat에 추가하면 될거라고 생각했는데!
pd.concat([ta01,ta02],axis = 1,ignore_index=True)
>>>
0 1 2 3 4 5
1 다산콜센터 120다산콜재단 D0000042894548 NaN NaN NaN
3 NaN NaN NaN 서울산업진흥원 2021-06-29 경제얼토당토 않다. ignore_index는 행의 index가 아닌 열의 index를 무시해주는 것이었다! 가 아니라, concat 하는 방향의 index를 무시하여 초기화해주는 것이었다. 잘 기억하자.
위 과정을 함수로 만들면 다음과 같다.
def get_desc(response):
""" 분류 수집하기 """
table = pd.read_html(response.text)[-1]
ta01 = table[[0,1]].set_index(0).T.reset_index(drop=True)
ta02 = table[[2,3]].set_index(2).T.reset_index(drop=True)
df_desc = pd.concat([ta01,ta02],axis=1)
return df_desc
get_desc(response)내일은 concat, merge, join 공부해보자!
어쨌든 이렇게 데이터에 컬럼값이 섞여있는 df를 보기 좋게 만들어주는 법에 대해 배웠다.
다시 실습으로 복귀해서, 여태까지의 동작들을 하나의 함수로 만들어주자.
내용을 수집하고, 분류가 들어있는 테이블을 보기 좋게 수집하는 함수!
def get_view_page(view_no):
"""
내용과 분류를 수집하는 함수 만들기
1) url을 만들어 줍니다.
2) requests를 통해서 요청을 보낸다.
3) 분류를 수집한다. 위에서 만들어놓은 함수 이용
4) 내용을 수집한다. bs를 이용하여 text만 추출.
5) 3)번 내용에 내용, 내용 번호를 함께 데이터 프레임에 추가한다.
### 아아 겹치는 컬럼이 있으면 쉽게 붙일 수 있겠구나.....! join이든! merge든!
6) 반복문 대신 map이나 apply를 사용할 것이기 때문에, time.sleep()을 해준다.
7) 5번까지 수집한 내용을 반환한다.
"""
url = f"https://opengov.seoul.go.kr/civilappeal/view/?nid={view_no}"
response = requests.get(url)
df_desc = get_desc(response)
html = bs(response.text)
content = html.select('div.view-content.view-content-article > div > div.line-all')[0].get_text()
df_desc["내용"] = content
df_desc['내용 번호'] = view_no
return df_desc
까지 하고 오늘 수업이 끝났다. 급박하게 끝나서 뒤의 실습 내용은 숙제로 내주셨다.
일단 작성은 해봤는데, 너무 어려워서 내일 수업 듣고 정리하도록 하자!
개인적으로 많이 아쉬운 하루!
뭔가 배운 내용이 많은데, 복습할 시간이 부족해 실습 내용을 정리하는 것에 그친 것 같아 아쉽다.
실습 내용도 무언가 빼먹은 느낌?
특히 웹 스크래핑에 대해 다양한 이야기를 많이 해주셨는데, get과 post, 비동기식 요청에 대해 데이터를 수집하는 법 등. JS에서 json 데이터를 수집할 때 나오는 payload가 뭔지도 더 공부해보고 싶었는데!
너무 실습 코드 위주로만 복습한 것 같아 아쉬움이 있다!
뭔가 정신이 없다. 뭔가 잊어버리고 사는 느낌?
그래도 나름 오늘 한 내용 거의 빼먹지 않고 복습 했다!
고생했고, 내일은 정신 좀 차리고 파이팅하자!
