22.11.02.
어제에 이어 캐글 타이타닉을 진행하며 kaggle 경진대회에 참여하는 법을 배웠다!
이 과정에서 머신러닝을 배웠다.
특히, pd.get_dummies()를 통해 인코딩하는 법, train set과 test set을 전처리 하는 법, 결측치를 대체하는 법에 대해서도 배웠으며, cross-validation에 대해 공부했다.
머신러닝을 위한 데이터 전처리
파생변수 만들기
- 머신러닝에 사용할 feature를 파생변수로 만들어 준다.
- 이는 여러 수치형 변수 컬럼들을 계산하여 만든 값이 될 수도 있고,
- 범주형 변수 컬럼을 인코딩 하기 좋도록 범주를 정리해 준 것일 수도 있으며
- 간단한 바이너리 인코딩을 통해 범주형 변수를 수치형 변수로 바꾸어 준 것일 수도 있다.
- 전처리를 할 때, 도메인 전문가 등의 의견이나 실제 현업에서 어떻게 쓰이는지 조사를 하고 전처리 해야한다.
머신러닝을 위해 데이터를 전처리 할 때, 주의해야 할 점이 있다.
바로, train set 과 test set에 동일한 전처리를 해주어야 한다는 점이다.
머신러닝을 진행할 때, train set과 test set의 feature의 종류와 개수는 당연히 동일해야한다. 따라서, 전처리를 진행할 때에 train과 test set에 대해 동일하게 진행해 주어야 한다는 것을 항상 유의하자!
실습에서는 이러한 파생변수들을 만들었다.
train['FamilySize'] = train['Parch'] + train['SibSp'] + 1
test['FamilySize'] = test['Parch'] + test['SibSp'] + 1동승한 부모 자식의 수, 형제의 수 컬럼을 이용해 가족의 수 피쳐를 만들었다.
train['Gender'] = (train['Sex'] == 'female')
test['Gender'] = (test['Sex'] == 'female')'Gender'라는 object type의 컬럼을, bool type을 가지도록 변환한 파생변수를 만들어주었다. 머신러닝에서는 object type 데이터를 사용할 수 없기에!
사실 뒤에서는, 이 Gender를 인코딩 하여 사용하기도 하였다.
train['Title'] = train['Name'].apply(lambda x : x.split('.')[0].split()[-1].strip())
test['Title'] = test['Name'].apply(lambda x : x.split('.')[0].split()[-1].strip())Name 피쳐에서, Mr, Miss 등의 호칭만 뽑아내어 새로운 피쳐를 만들어 주었다.
음... 성별과 연령을 동시에 파악할 수도 있는 지표일 것 같다! 그런데 이 피쳐는 좀 더 전처리가 필요하다.
test set에만 존재하는 호칭이 존재하기 때문이다...!
이렇게 파악해볼 수 있다.
set(test['Title'].unique()) - set(train['Title'].unique())
>>>
{'Dona'}와 이걸 어떻게 set으로 바꿔서 차집합을 통해 파악해볼 생각을..! 진짜 짱이다.
잘 기억해두자 이런 방법.
그게 중요한게 아니라, test set에만 존재하는 호칭이 있는게, 왜? 뭐가 문제지?
인코딩을 진행할 것이기 때문에 문제가 된다.
train과 test의 피쳐 맞춰주기
이거! 이거 중요하다.
일부 피처는 범주형 데이터이기에, 머신러닝 모델에서 사용하기 위해서는 인코딩을 진행해야 한다.
그리고 인코딩을 진행하였을 때에, train과 test에서 만들어진 feature의 종류와 수가 동일해야 한다. 그렇기 위해서는, 해당 범주형 데이터에 존재하는 범주들을 통일시켜야 한다.결국, 범주형 변수에 들어있는 범주들이 train과 test set에서 동일해야 한다는 것이다. 동일하게 맞춰줘야 한다.
후... 이걸 꼭 머릿속에 잘 넣고 다니자! train set과 test set에 존재하는 feature는 동일해야 한다! 따라서, 인코딩을 진행하려면, 안에 있는 범주들을 똑같이 맞춰줘야 한다!
그럼 어떻게 맞춰줘야하나? 여기서는, 호칭 피쳐에 대해, train set에서 여러 번 나오는 범주들을 골라내어, 그렇지 않고 몇 번만 나오는 범주들은 모두 '기타'로 만들어주었다.
음.. 좀 더 이해해보자.
실생활의 데이터를 분석할때, 예를 들어 미래를 예측한다면? 우리는 test set에 어떠한 데이터가 있는지 모른다. 아직 모르는 데이터를 예측하는 거니까!
결국, 머신러닝 모델에 사용하기 위해 데이터를 전처리 할때, 우리가 알고 있는 데이터는 train set 밖에 없다. 따라서, 모든 전처리는 train set을 기준으로 진행한다.
그런데 위와 같은 상황에서, train set의 호칭 피처에 존재하지 않는 범주가 test set에 존재할 수 있다. 그러한 test set을 그냥 인코딩한다면, train 과 test set의 피쳐의 종류와 개수는 달라져, 머신러닝 모델을 제대로 활용할 수 없을 것이다.
따라서, train set에서 기준을 잡아 전처리를 진행해준다. train set에서 여러 번 나오는 호칭들은 test set에도 여러번 나올 것이기도 하고, 모델에 영향을 끼칠 확률이 높으니 그대로 두겠고, 몇 번 나오지 않는 호칭들은 그냥 싸그리 '기타'로 묶어버린다.
그러면 test set을 같은 기준으로 전처리할 때, 자주 나오는 호칭들은 그대로 존재하겠고, train set에서 몇번 나오지 않았던 호칭들, 심지어는 train set에 아예 존재하지 않았던 호칭들까지 모두 '기타'라는 범주가 될 것이다.
이렇게 진행해줘야, 머신러닝을 할 때 오류를 방지할 수 있다. train set과 test set의 feature의 종류와 개수를 같게 맞춰준다! 기준은 train set으로!
실습은 다음과 같이 진행했다.
# 2개 이하의 경우 Etc로 묶어주기!
train_Title = train['Title'].value_counts()
Not_etc = train_Title[train_Title >= 3].index.tolist()
display(Not_etc)
train.loc[~train['Title'].isin(Not_etc), 'TitleEtc'] = 'Etc'
train[['Title','TitleEtc']].sample(5)
test.loc[~test['Title'].isin(Not_etc), 'TitleEtc'] = 'Etc'
test[['Title','TitleEtc']].sample(5)이렇게 하면 된다...! 잘 받아들이고, 기억하자.
set으로 변환해 test에만 존재하는 값이 없는지 다시 확인한다.
set(test['TitleEtc'].unique()) - set(train['TitleEtc'].unique())
>>>
set()없다. 이렇게 하면 된다...!
위에서 실생활의 데이터를 처리할때 train set을 기준으로 처리한다 했었다. 그런데 사실 우리는 지금 kaggle에서 경진대회를 참가하고 있으므로, test set에 대해서도 알고 있고, test set과 train set의 유니크값을 합쳐서 전처리를 해주어도 된다.
그래도 어쨌든 기억해둘 것은, test set의 데이터를 모르고 있기 때문에, train set의 데이터를 기준으로 전처리를 진행한다!
위와 같은 과정을 진행한 이유를 강사님은 이렇게 설명하셨다.
Train에만 등장하는 호칭은 학습을 해도 test에 없기 때문에 예측에 큰 도움이 되지 않는다. 또한, one=hot encoding을 진행할 것이기 때문에 train에만 등장하는 호칭을 피처로 만들어주게되면 피처의 개수가 늘어나는데 불필요한 피처가 생긴다. 불필요한 피처가 생기기도 하고 데이터의 크기도 커지기 때문에 학습에도 시간이 더 걸린다. 따라서 트레인에서 별로 등장하지 않는 호칭은 테스트에서도 별로 등장하지 않을 거라는 가정 하에 이를 기타로 빼준다. 너무 적게 등장하는 값을 피처로 만들었을 때, 해당 값에 대한 오버피팅 문제도 있을 수 있습니다.
여기다가, 인코딩을 했을 때 피처가 달라지는 문제!
음 Title의 범주들을 train set에서 2번보다 많이 나오는 것들만 골라준 이유는 다음과 같이 설명하셨다. 이거 잘 기억하면 좋을 듯.
2개보다 큰 값만 가져오도록 했는데 2개보다 작은 값에 대해서만 예외처리를 하게 되면 앞으로 다른 train, test에 없는 값이 들어왔을 때 다시 전처리 해주어야 합니다. 예외에 추가가 필요합니다.
데이터 인코딩
- 머신러닝 모델이 학습을 진행할 때 문자(object type data)는 인식을 하지 못하여 진행할 수 없다. 따라서 문자형 데이터들을 숫자로 바꿔주는 것이 필요하고, 그게 바로 인코딩이다.
- 인코딩의 종류로는 간단히 one-hot encoding과 ordinary encoding이 존재한다.
- one-hot encoding은 각 범주 자체를 하나의 컬럼으로 만들어 범주형 데이터가 해당 범주에 속하면 1, 아니면 0으로 표현해주는 방식이다.
- ordinary encoding은 범주형 변수에 대해, 각 범주들을 0,1,2와 같은 숫자로 표현해주는 방식이다. 이는 주로 순서가 있는 범주형 데이터(순위형 자료)에 대해 많이 사용한다. 명목형 자료에 대해 이 방식을 사용한다면, 의도치 않은 가중치가 부여되어 원하는 결과를 얻지 못할 수 있다.
- 인코딩은 주로 pandas의 pd.get_dummies()를 사용하거나, 사이킷런에서 encoder를 사용하여 진행한다. 오늘은 pd.get_dummies()를 배웠다.
pd.get_dummies()
pd.get_dummies()는 데이터를 one-hot encoding 시켜주는 판다스 함수이다.
이 함수의 대표적인 특징은, 인코딩 해야하는 범주형 변수를 자동으로 골라내어 인코딩 해준다는 점이다.
즉, 수치형 변수와 범주형 변수가 섞여있는 데이터프레임을 인자로 넣어줄 경우, 수치형 변수는 그대로 두고, 범주형 변수만 인코딩해 만든 데이터프레임을 반환한다.
게다가, 결측치가 있어도 인코딩을 진행할 수 있다.
인코딩을 진행할 범주형 변수에 결측치가 존재하면, 인코딩으로 만들어진 모든 컬럼의 값을 0으로 표현함으로써, 결측치 처리가 진행되게 된다.
만약 dummy_na = True로 하면, NaN 컬럼이 따로 생긴다.
따라서 매우 강력한 함수이다!
실습에서는 이렇게 사용했다.
X_train = pd.get_dummies(train[feature_names])
print(X_train.shape)
X_train.head(2)
X_test = pd.get_dummies(test[feature_names])
print(X_test.shape)
X_test.head(2)사용법도 아주 간단하다!
인코딩을 위한 전처리
머신러닝을 진행할 때, train set과 test set의 feature의 종류와 개수는 당연히 동일해야한다. 그런데, 하나의 범주형 변수에 대해, train set과 test set에 존재하는 범주의 종류들이 다르다면? Encoding을 진행하면 피쳐의 종류와 개수가 달라지게 된다.
따라서, 인코딩을 진행하기 전 train set과 test set에 대해 전처리가 필요하다.
앞에서 설명했다. ### train과 test set의 피쳐 맞춰주기에서 설명한 내용을 사실 여기서 하려고 했던 것..!
여기서는 강사님의 말을 첨부하겠다.
현실세계에서 pandas의 get_dummies를 사용한다면 train 따로 test 따로 만들어주겠죠. 왜냐하면 미래에 앞으로 어떤 데이터가 들어올지 모르기 때문입니다!
train과 test에 다른 값이 존재하면, 서로 다른 피처를 만들 수 있습니다.
그러나 보통 경진대회에서는 train,test set이 정해져 있습니다. 따라서 하나로 합쳐서 전처리하고 같은 피처를 만든 후, 다시 나누어주는 방법을 사용하기도 합니다!
결측치 대체
- 결측치를 대체하는 방법에는 정답이 없다.
- 머신러닝을 위해 전처리를 할 때, 결측치를 어떻게 대체할지는 자유이다.
- 단지, 성능을 더 잘 낼 수 있는 값으로 대체하면 된다.
- 결측치 행 제거
- 결측치를 중앙값 등으로 대체
- 결측치를 보간법 등을 이용하여 대체 등의 방법이 존재한다.
- 예를 들어 나이의 경우, 그냥 중앙값으로 채울수도 있고, 여성과 남성 별 평균 나이를 구해 성별에 따른 나이의 평균으로 채울 수도 있고, 좌석의 종류에 따른 평균 나이로 채울수도 있고… 그 중 가장 적절한 방법을 찾아서 채우면 된다.
- 그리고 결측치를 채울 때, 오류도 막고 원래 값과의 비교도 위해 새로운 컬럼을 만들어서 채우는 것을 추천한다.
- 현실세계에서 분석하는 데이터에선 함부로 결측치를 채우는 일에 주의해야 한다!!!! 분석이 완전히 달라질 수 있다!!!!
일단은 중앙값으로 채웠다.
train['Age_fill'] = train['Age'].fillna(train['Age'].median())
test['Age_fill'] = test['Age'].fillna(test['Age'].median())
train['Fare_fill'] = train['Fare']
test['Fare_fill'] = test['Fare'].fillna(test['Fare'].median())
train['Fare_fill'].isnull().sum(), test['Fare_fill'].isnull().sum()'Fare'의 경우, test set에만 결측치가 존재하나, train set에도 전처리를 진행해준다.
또한, fillna의 메소드를 이용하는 방법과, pandas의 interpolate를 사용하는 방법도 배웠다. 해당 방법들은 주로 시계열 데이터나 센서 데이터와 같이 앞 뒤의 데이터끼리 연관이 있는 경우 사용한다.
-
fillna
method라는 매개변수에 다음과 같은 값이 들어갈 수 있다.method : {'backfill','bfill','pad','ffill',None}
'backfill'과 'bfill'의 경우,use next valid observation to fill gap, 결측치 이후에 오는 값으로 결측치를 채워준다.
'ffill','pad'의 경우,propagate last valid observation forward to next valid, 결측치 이전에 오는 값으로 결측치를 채워준다. -
interpolate (보간법)
알려진 데이터 지점의 고립점 내에서 새로운 데이터 지점을 구성하는 방식이 바로 보간법이다.
즉, 이전 및 이후 데이터들을 통해 결측치에 들어갈 데이터를 파악하여 채워준다.
간단히는 다음과 같이 사용한다.
DataFrame.interpolate(method='linear', limit_direction=None)
method에는 linear, polynomial, spline 등 다양한 값이 들어갈 수 있다.
linear를 사용하면 간단한 선형 관계식을 통해 이전 이후 데이터를 토대로 결측치 자리에 들어갈 데이터를 파악한다. (Ignore the index and treat the values as equally spaced. This is the only method supported on MultiIndexes.)
limit_direction의 경우,{{‘forward’, ‘backward’, ‘both’}}가 들어갈 수 있다. Consecutive NaNs will be filled in this direction. 해당 방향으로 진행하며 결측치가 채워지게 된다. 예를 들어 맨 앞에 결측치가 존재하면, limit_direction이 forward이면 채워지지 않는다. 우리는 주로 both를 사용한다.
기억하자!
- train set에 해준 전처리는 test set에도 동일하게 진행해줘야 한다.
- train set과 test set의 feauture의 종류와 개수는 동일해야 한다.
- test set의 데이터는 모르고 있기 때문에, train set의 데이터를 기준으로 전처리를 진행한다!
모델 생성 및 학습, 예측과 제출
feature, label 나눠주기
- feature_names, label_name을 지정해주어 feature와 label을 정한다.
Train, test set 만들기
- 캐글 타이타닉 대회의 경우 애초에 train, test로 나누어져 있는 데이터를 제공한다.
- 여기서 우리가 전처리를 진행하였고, 사용할 feature와 label만 골라 머신러닝에 실제 사용할 train, test data를 만든다.
- 전처리를 마친 후, 이 과정에서 Encoding을 진행하면 편하다.
- 다음과 같이 진행했다.
X_train = pd.get_dummies(train[feature_names])
print(X_train.shape)
X_train.head(2)
X_test = pd.get_dummies(test[feature_names])
print(X_test.shape)
X_test.head(2)
y_train = train[label_name]
y_train머신러닝 알고리즘 불러와 학습하기
- 다양한 알고리즘을 불러와, 모델을 fit 시킨다.
- 첫번째 실습 파일에서는 DecisionTreeClassifier를 사용했다.
성능은 랜덤포레스트가 더 좋지만, 그냥 빨리빨리 베이스라인 모델을 만들어보기 위해 사용했다. cross-validation을 진행할 건데 시간이 너무 오래걸리면 안되기도 하였고! - 두번째 실습 파일에서는 RandomForestClassifier를 사용했다.
랜덤포레스트는, 의사결정나무 알고리즘의 단점을 보완한다. 오류가 하강적으로 전파되는 의사결정나무와 달리, 랜덤포레스트는 여러 트리를 만들어 종합한 결과를 사용하기 때문에, 오류값에 대해 비교적 강건하다. 일반화하여 사용하기도 좋다. 이는 배깅과 같은 앙상블 기법에 의한 효과이다. - 이 과정에서 GridSearchCV나, RandomizedSearchCV를 사용해 하이퍼파라미터 최적화도 진행한다.
- Cross-validation을 통해 모델의 대략적인 성능도 파악해본다.
- 그냥 accuracy를 파악해볼 수도 있다.
- 모델의 성능이 안나오면 모델을 변경하거나, 피쳐 엔지니어링을 진행하는 등의 방법으로 최적화 시킨다.
- feature_importance 도 살펴보며 잘 활용한다!
예측하기
- fit 시킨 모델을 이용해 predict한다.
y_predict = model.predict(X_test)
제출 파일 만든 후 제출하기
- 제출 파일 양식을 불러오고, Survived 자리에 y_predict를 넣어준다.
- 해당 파일을 csv로 내보낸 후 캐글에 제출해, 점수를 본다!
이때 팁이라면, 파일 이름에 우리가 cross-validation 등으로 파악한 모델의 성능 점수를 넣어주어 캐글에서 test set에 대한 점수와 비교할 수 있다.
cross_val....
이거. 진짜 모르겠더라! 아니 cross-validation의 개념은 알겠는데, 각 함수가 어떤 기능을 하는건지가 이해가 안 되었다.
그래서 열심히 공부를 한번 해봤다....
일단 간단한 개념 정리. 강사님이 해주신거!
- cross_validate : Evaluate metric(s) by cross-validation and also record fit/score times. 학습결과에 대한 점수와 시간이 나옵니다. 점수를 보고자 할 때는 편리하지만 지정한 metric에 의해서만 점수가 계산됩니다.
- cross_val_score : Evaluate a score by cross-validation. 각 valid set에 대한 점수가 나옵니다.
- cross_val_predict : Generate cross-validated estimates for each input data point. 예측 값이 그대로 나와서 직접 계산해 볼 수 있습니다. 직접 다양한 측정 공식으로 결과값을 비교해 볼 수 있습니다.
실습 코드는 다음과 같다.
from sklearn.model_selection import cross_validate, cross_val_predict, cross_val_score
# cross_validate : 시간, 점수 계산 시간, 점수가 나옵니다.
pd.DataFrame(cross_validate(model, X_train, y_train))
# cross_val_score : 조각 별 스코어
cross_val_score(model, X_train, y_train)각 함수들의 사용법에 대해서는 익숙해졌다! 각 함수들이 반환하는 값도 무엇인지 알았다.
그런데 여기서부터 의문이 생겼다.
# cross_val_predict : 예측 결과 값, 그 결과로 직접 다양한 방법으로 정확도 계산이 가능하다.
y_valid_pred = cross_val_predict(model, X_train, y_train)
y_valid_pred[:5]
valid_accuracy = (y_train == y_valid_pred).mean()
valid_accuracycross_val_predict를 사용하여 전체 데이터의 예측값을 알아내고, 이 예측값을 이용해 모델의 정확도를 파악했다...!
이게 대체 뭐지...?
의문 1
cross_val_predict의 결과 예측값은, 어떤 모델을 사용하여 예측한 값인가?
cross_val_predict는 어쨌든 cross-validation의 일종이다.
cross-validation은
train data 전체를 여러개의 fold로 나눈다.
그리고 fold 하나가 valid set, 나머지 fold들은 모두 train set이 되도록 하여 학습 및 평가를 진행한다.
모든 fold가 한번씩 valid set의 역할을 진행하도록 한다.
의 과정으로 이루어진다. 그런데 cross_val_predict는 전체 데이터를 예측한 값을 반환한다니..? 대체 무얼 가지고 어떻게 예측한 값을 반환하는 것인가..?
공식 api guide에는 그냥 아주 짧게 method 인자가 predict면 예측한 값을 반환한다고만 나와있었다. 그에 대한 설명은 없더라.
그래서 내가 생각한건 두개였다.
1. X_train, y_train 으로 학습한, 원래 model로 X_train에 대한 예측을 진행한 값
2. 각 fold를 valid로 하고, 나머지를 train 으로 하여 학습, 평가한 모델 중 최고 성능을 낸 모델로 전체 데이터에 대한 예측을 진행한 값.
그래서 각각 검증을 해보았다.
1번 가설이 맞다면, 그냥 model.fit 한 후 model.predict한 값과 y_valid_pred가 같아야하는데, 다르다. 기각!
2번 가설이 맞다면, 모델에서 train set으로 사용한 fold에 대한 정확도는 높고, test set으로 사용한 fold에 대한 정확도는 떨어지지 않을까? 라고 생각했다. 그래서
맞은 것과 틀린 부분을 시각화 해보았더니, 틀린 부분이 아주 고르게 분포하고 있더라.. 그래서 기각!

(사실 시각화에 더 좋은 방법이 있었을 것 같긴 한데..! 일단 저렇게 했다.)
# 1. 모델로 예측한 값과, cross_val_predict로 예측한 값이 같은지.
y_cross_pre = cross_val_predict(model, X_train, y_train)
model.fit(X_train, y_train)
y_model_pre = model.predict(X_train)
print('model accuarcy : ', (y_train == y_model_pre).mean())
print('cross accruacy : ', (y_train == y_cross_pre).mean())
print('모델과 cross 사이의 정확도 : ' ,(y_cross_pre == y_model_pre).mean())
>>>
다 다르다.아주 좌절... 결국 뭔지 못찾는건가..? 하다가 공식 문서에서 이어지는 User guide를 읽어보았다..!
User-guide
사실 user guide까지는 제대로 읽어본 적 없었는데.. 영어에 대한 막연한 거부감! 오늘 읽어보니까 어렵긴 한데 생각보다는 읽을 만 하더라! 그리고 되게 설명도 잘 되어 있었다! 이렇게 공식문서랑 좀 더 친해졌다.
여기서 발견했다.
returns, for each element in the input, the prediction that was obtained for that element when it was in the test set.
와...! 수업시간에도 이거 때문에 그렇게 헤매고.. 알아냈다..! 뿌듯해라.
cross_val_predict를 통해 반환되는 예측값은, 각 부분이 test set(valid set)으로 사용되었던 모델에 의해 예측된 값이다!
그러니까, 아래 그림에 대해서
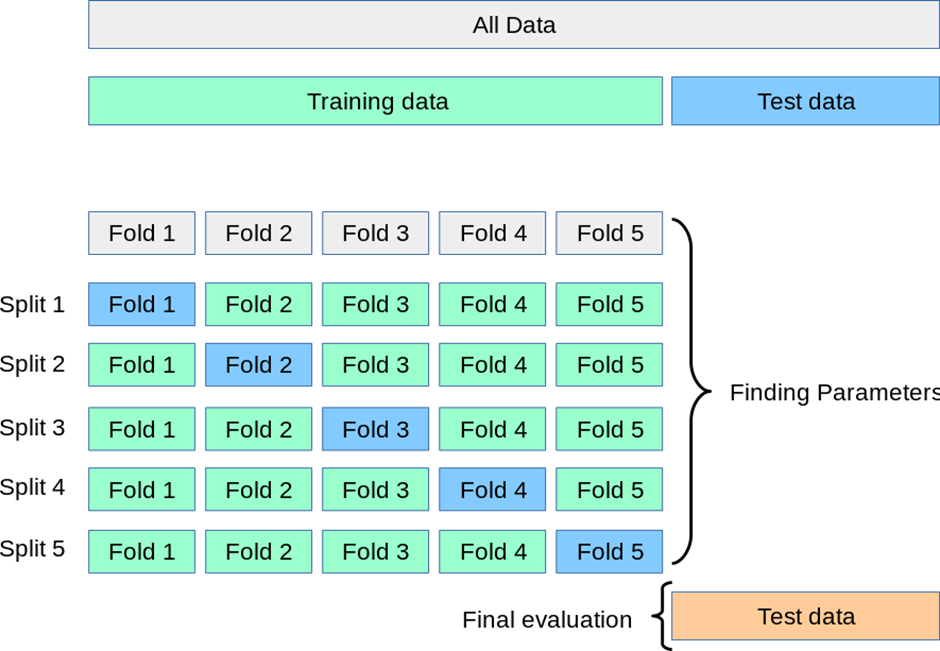
Fold 1 부분에 대한 예측값은 split 1에서 만들었던 모델에서 예측한 값,
Fold 2 부분에 대한 예측값은 split 2에서 만들었던 모델에서 예측한 값,,,
이런 식으로 하여! 각 부분에 대한 예측값들을 합친 값을 반환한 것이다!
와 이해했다..!
의문 2
아니 근데 왜.. 왜... 그럼 cross_val_predict를 사용하는 거지?
실습에서는 cross_val_predict로 예측한 값과 원래 값을 비교해 정밀도를 파악했다. 굳이 model로 예측하여 얻은 값과 비교하지 않고, 이 값으로 정밀도를 파악한 이유는?
Warning
Note on inappropriate usage of cross_val_predict
The result of cross_val_predict may be different from those obtained using cross_val_score as the elements are grouped in different ways. The function cross_val_score takes an average over cross-validation folds, whereas cross_val_predict simply returns the labels (or probabilities) from several distinct models undistinguished. Thus, cross_val_predict is not an appropriate measure of generalization error.
공식문서에는 이런 내용도 있다.
Results can differ from cross_validate and cross_val_score unless all tests sets have equal size and the metric decomposes over samples.
The function cross_val_predict is appropriate for:
Visualization of predictions obtained from different models.
Model blending: When predictions of one supervised estimator are used to train another estimator in ensemble methods.
역시 user guide에 있는 내용. 영어...
대강 중요한 내용은, cross_val_predict는 단순히 여러 개별 모델들에 의해 반환된 값들을 가지고 있기 때문에, 일반화된 오류를 파악하기에 적절한 기준은 아니다 라는 것.
그리고 이는 다양한 모델에서 얻은 예측의 시각화 등에 사용하면 좋다는 것 이다.
그렇단다... 솔직히 이해 잘 못했다... ㅎ 특정 조건을 만족시키지 못하면 cross_val_score와 cross_validate의 결과와는 조금 차이가 있을 수 있다는 것 같다..! 알아만 두자.
그냥 위와 별개로 내가 이해한 내용은, cross-validation이라는 것 자체가, test set으로 모델의 성능을 검증할 수 없을 때, train set만 이용하여 모델의 성능을 검증하기 위한 방법이라는 것!
사실 X_train과 y_train으로 학습한 모델에, X_train을 넣어 예측한 결과의 accuracy가 무슨 큰 의미가 있을까..! 검증의 지표라고 보긴 어려울 것이다. cross-validation을 통해서 test set의 label이 없는 지금 같은 상황에서 어느정도나마 모델의 성능을 평가해 볼 수 있다.
cross validation을 이용하기 위해, validate, score등의 다양한 함수를 사용할 수 있겠지만, cross_val_predict를 사용한다면 각 부분에 대해서는 학습하지 않은 모델들로 부분들을 예측한 값의 모음, 즉 비교적 평가의 지표로 사용할 수 있는 예측값을 얻을 수 있다. 또한 이 예측값으로는 직접 다양한 계산이나 함수를 통해 여러가지 측정 지표를 계산할 수 있다. 따라서 cross_val_predict를 사용한다!
이렇게 이해했다! cross-validation 끝!
기타
- 전처리 등을 진행하며 항상 display 등을 이용해 확인해 보는 것을 추천 또 추천!
- 주피터 노트북에서 esc + f를 누르면 해당 셀에 존재하는 특정 단어를 찾아 다른 단어로 바꿔줄 수 있다.
- 캐글에서 좋은 솔루션 찾는 법
- Top 키워드로 검색
- 솔루션에 대한 투표수가 많은 것
- 프로필 메달의 색상(금색이 젤 조아요, 금색, 빨강, 보라 순!)
- 헷갈린 부분. X_train 과 y_train으로 학습시킨 모델에 대해, X_train으로 예측한 값을 y_train이랑 비교하면 다 맞아야하는거 아닌가? 응 아니다! 아니지 아니지. 왜 그런 생각을..!
- cross validation도, 하이퍼파라미터 튜닝도... model_selection에서 가져오면 된다.
- 랜덤포레스트는 ensemble에서!
더 공부해볼 것
- pd.DataFrame으로 데이터 프레임 만드는 방법. 기본부터 다시!
- 복습 진짜 열심히 해야겠다 기억도 안나고, 머릿속에서 섞이고. 난리다 난리
- 뭔가 많았는디..? 흠... 일단 과제랑 미니플젝..!
그래도 오늘 집중 좀 다시 올라오고, 혼자 복습도 나름 만족스럽게 한 것 같다!
시간이 너무 늦어져서 그렇지 피곤한데.. 내일도 파이팅!
해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사의 자료를 인용하였습니다.
https://pandas.pydata.org/docs/reference/api/pandas.get_dummies.html
https://scikit-learn.org/stable/modules/cross_validation.html
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_predict.html
https://thebook.io/080223/ch06/02/02-04/
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.interpolate.html
https://stats.stackexchange.com/questions/502037/why-should-we-use-cross-val-predict-instead-of-just-normally-predicting-our-inst
다음은 퀴즈 시간에 간단히 요약한 내용!
- pd.get_dummies를 이용하여 one-hot-encoding 하는 법을 배웠다.
-> 이때, train set과 test set에 인코딩 결과 같은 피쳐들이 존재하도록 두 데이터를 전처리 해주는 과정이 필수적임을 알게 되었다. (예시 : 호칭에 대해, 한 쪽에만 존재하는 호칭이 존재하므로, 주로 나오는 호칭과 그렇지 않은 '기타'호칭을 구분하여 '기타' 라는 값을 만들어주었다.)
- 전처리를 할 때, 실제 상황에서는 test data는 모르고 있으므로, train 데이터를 기준으로 전처리 한다.
- 머신러닝을 위해 전처리를 진행 할 때에, train data에 진행한 전처리를 반드시 test data에도 동일하게 진행해줘야 한다는 것을 기억하자.
- get_dummies 함수는, 수치형 데이터는 그냥 놔두고 범주형 데이터만 골라내어 one - hot encoding을 진행해준다. 심지어 결측값이 있어도 가능하다. 따라서, get_dummies 함수를 이용한 인코딩은 전처리가 모두 끝난 후 학습 및 평가 데이터를 나눌 때 진행한다.
- 결측치 대체 방법에 대해서도 배웠다.
- 결측치는 제거하거나, 중앙값 등 다른 값으로 대체하거나, 보간법을 이용해 대체하는 방법이 있다.
- 오늘은 fillna의 method를 이용하거나 interpolate를 이용해 보간법을 통해 앞, 뒤의 데이터를 사용해 결측치를 대체하는 법을 배웠다.
- 이는 주로 시계열 데이터 등에서 앞 뒤의 데이터와 연관이 있을때 사용한다.
- cross_val_predict 에 대해서 배웠다.
