11.15 / 11.16
피쳐 엔지니어링과 부스팅에 대해 배웠다.
해당 내용은 멋쟁이사자처럼 AI School 오늘코드 박조은 강사님의 자료를 참고하였습니다.
feature engineering
0702 파일
log 변환
왜도와 첨도 혹은 히스토그램을 통해 데이터의 분포를 파악한 후, 분포가 너무 치우쳐있는 형태라면 해당 feature를 log 변환 해주는게 좋을 수 있다.
분포가 고를 수록 학습과 예측에 도움이 되기 때문!
polynomial features
언제 사용했지? uniform 한 데이터여서 특성이 너무 드러나지 않을때, 제곱을 하거나 곱해주는 방식으로 여러 특성을 살펴보고 학습과 예측에 도움이 되기 위해 사용했었다.
sklearn의 polynomialfeatures를 통해서도 구현할 수 있었지만, 이번 실습에서는 직접 제곱을 해주는 방법으로도 구현해보았다.
아주 다양한 방법이 있구나...! 정답은 없고...! 상황에 맞춰 마음대로 잘 선택해가면 되겠다...
어쨌든 값을 강조해서 구분해서 보고자 할 때, 분포의 특성이 더 잘 드러나도록 보고 싶을 때, polynomial features를 사용하거나, 그냥 피쳐에 제곱을 해주어 분포를 더 강조하여 볼 수 있다는 것!! 알아두자….!
이상치 처리
이상치란 너무 크거나 작아 범위를 벗어나는 값으로, 주로 제거 혹은 대체한다.
오류값이란 데이터의 수집 및 입력 과정에서 잘못 입력된 값으로, 역시 주로 제거 혹은 대체한다.
이산화
binning이라고도 부르며, pd.cut과 pd.qcut을 통해 equal width 또는 equal frequency binning을 할 수 있다.
결측치 처리, imputation(결측치 대체)
결측치가 많은 feature라고 해서 무조건 삭제하는게 나은 방법이라는 보장은 없다. 오히려 그것이 중요한 신호일 수 있다!
범주형 변수의 경우 결측치가 있더라도 인코딩할때 저절로 0으로 처리될 것이고,
수치형 변수의 경우 결측치를 잘못 채우게 되면 오해가 생길 수 있으니 주의가 필요하다! 원래의 값을 너무 왜곡시키면 안된다! 회귀와 같은 머신러닝 알고리즘으로 채울 수도 있고, 보간법을 사용하거나 대표값을 이용해 채울 수도 있고, 기준을 잡아 기준에 따라 다른 값으로 채워줄 수도 있다!
결측치를 어떻게 처리해야할지에 대한 판단은, 차차 배워나가고, 여러 노트북을 필사해보며 기준을 스스로 익히고 판단하여 선택하면 된다. 연습이 필요하다!
scaling
지금은 tree 기반의 모델을 사용하고 있기 때문에 scaling을 하고 있지 않지만, 만약 다른 모델들을 사용한다면 꼭!!! standardscaler, minmaxscaler, robustScaler 등을 이용해 scaling 해주어야 한다.
train - test 나누기
이번 실습에서는, 전처리를 한번에 해주기 위해 train과 test를 합친 후 진행했었다. 전처리 완료 후 다시 train 과 test를 나눠줬어야 하는데, 어떻게 하면 될까?
전처리 과정에서 행을 삭제한게 없다면, 합쳐주기 전 train set의 행의 개수를 이용해 iloc으로 슬라이싱하여 나눠주면 될 것이다!
-> 수치형과 범주형 변수에서 전처리할 수 있는 방법이 다르기 때문에 EDA과정에서 데이터를 꼼꼼히 탐색하는 것이 중요하다!
KFold
KFold는 주어진 데이터셋을 여러 개의 Fold로 분할해준다.
from sklearn.model_selection import KFold
kf = KFold(n_splits = 5, shuffle = True, random_state = 42)
kf이렇게 만들어줄 수 있다.
굳이 KFold를 사용하는 이유는, shuffle 인자를 이용해 데이터셋의 순서를 섞은 후 fold를 나눌 수 있으며, random_state를 지정하여 분할이 바뀌지 않도록 해줄 수 있기 때문이다!
따라서 이를 사용하면 점수의 변화가 분할의 변화 때문인지, 모델의 변화 때문인지를 확실하게 알 수 있다.
이렇게 만든 kfold를 cross_validation에는 이렇게 사용할 수 있다.
from sklearn.model_selection import cross_val_predict
y_valid_predict = cross_val_predict(model, X_train, y_train, cv = kf, n_jobs = 10)
y_valid_predict
from sklearn.model_selection import cross_val_score
cross_val_score(model, X_train, y_train, cv = kf, scoring = 'neg_root_mean_squared_error', n_jobs = -1)사실 약간 왜 쓰는지 이해가 안된다!
shuffle한 후에 fold를 나누려고 쓴다면 이해가 되겠지만, randomstate를 통해 분할이 바뀌지 않도록 해주어 분할의 변화가 점수에 영향을 미치지 못하게 하기 위해서라는게 이해가 안된다.
그냥 cross_validate를 할때에도, 분할이 바뀌진 않을 것 같은데? 여러번 시행해봐도 같은 결과가 나오기도 하고.. 순서대로 개수에 맞춰 분할되는 거 아닐까?
그래서 kfold를 shuffle = false, n_splits = 5로 하고
cross_val_score를 cv = kf로 한 후 실행해보았고, cv = 5로 바꿔서도 실행해보았다.
똑같이 나온다! 여러번 실행해도! 똑같다!
그냥 일단은 shuffle 해줄 수도 있고, 미리 나누어놓고 변수에 저장한 후 CV를 할때에는 따로 나눠주는 연산을 하지 않기 위해 사용한다! 라고 이해해야겠다.
KFold
The first n_samples % n_splits folds have size n_samples // n_splits + 1, other folds have size n_samples // n_splits, where n_samples is the number of samples. 라고 한다.
cross_val_score의 user guide에 보면,
The following example demonstrates how to estimate the accuracy of a linear kernel support vector machine on the iris dataset by splitting the data, fitting a model and computing the score 5 consecutive times (with different splits each time):
라고 나와있는데... 내가 해석을 못하는건가... with different splits each time이면 실행할때마다 결과가 달라져야하는거 아닌가..?
근데 cv parameter에 대한 설명을 보면 이렇게도 나와있다!
For int/None inputs, if the estimator is a classifier and y is either binary or multiclass, StratifiedKFold is used. In all other cases, KFold is used. These splitters are instantiated with shuffle=False so the splits will be the same across calls.
그럼 똑같이 나오는게 맞다!
그러면 위에서 쓴 대로! shuffle 해줄 수도 있고, 미리 나누어놓고 변수에 저장한 후 CV를 할때에는 따로 나눠주는 연산을 하지 않기 위해 사용한다! 라고 이해하자.
Linear Regression
실습 파일 0801로 넘어옴!
Kaggle Benz dataset(제조업, 센서데이터)로 실습
EDA
데이터셋의 특이한 점을 보면, 다 익명화되어있다. 이렇게!
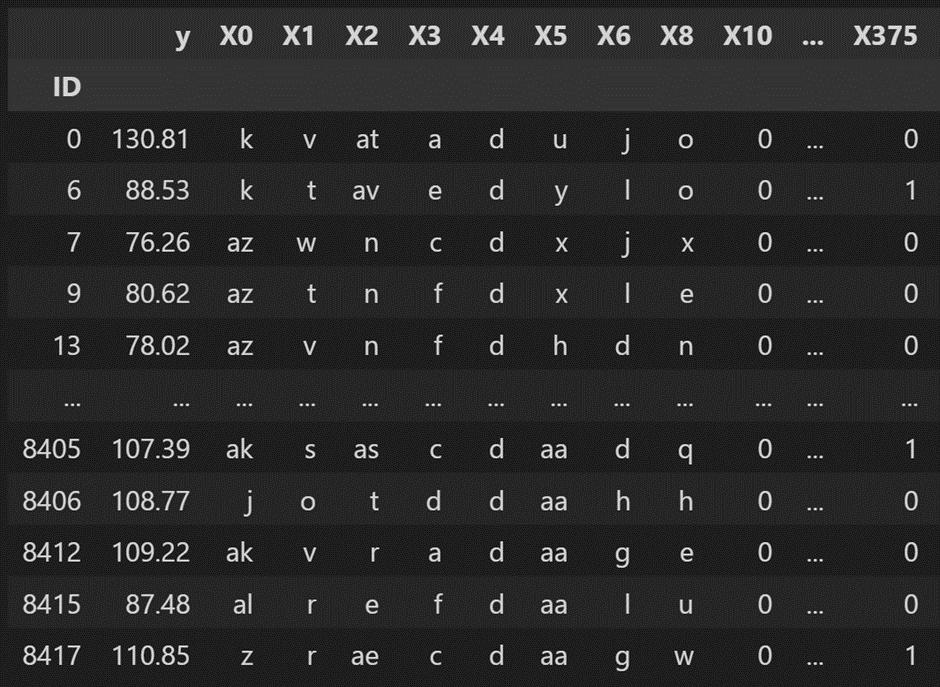
보안을 위해 익명 처리 해주었다고 한다.
- feature가 800여개 존재한다. 피쳐 엔지니어링에 도전해볼 데이터셋이다.
- 그 중 nunique가 1인 변수들이 있다. 이러한 변수들은 예측에 크게 도움이 되지 않을 듯 하므로, 제거해준다.
train_nunique = train.nunique().sort_values() train_one_idx =train_nunique[train_nunique == 1].index train = train.drop(columns = train_one_idx)
test = test.drop(columns = train_one_idx)
test에도 전처리 해주는거 잊지 말고, 해줄 때 train data 기준으로 해주는거 헷갈리지 말고!
- heatmap을 꼭 corr()를 시각화할때만 사용하지 않는다. 옛날에 미드프로젝트에서 나도 그냥 피벗테이블 시각화를 heatmap으로 한 적 있었듯이, 다양하게 활용할 수 있다.
여기서는 전체 변수들의 분포를 확인해보고자 전체 수치형변수들을 heatmap으로 그렸다.
-> describe에서도 알 수 있긴 하지만, 모든 값들이 다 0~1 사이에 존재하는 값임을 알 수 있다.
### One Hot Encoding
이 날 배운 내용 중 가장 새로웠던 내용 중 하나.
sklearn의 OneHotEncoder를 제대로 사용해보았다.
전에 사용했던 것, 정리했던 것과 사용법은 동일하다.
handle_unknown = 'ignore'를 통해서 test에만 있는 범주의 경우 결측치 처리하도록 해주는 것이 필요했었다. ode를 사용한다면 'use_encoded_value'로 사용한다.
여기서 배운 중요한 건, pd.get_dummies()와 달리 OneHotEncoder()는 범주형 변수만 스스로 골라 인코딩을 해주는 것이 아니라, **수치형 변수까지 모두 인코딩해준다**는 것!
이걸 명심하고, 범주형만 인코딩하고 다시 붙이던가 하는 방식으로 사용해야 한다.
또한, OneHotEncoder와 같은 sklearn.preprocessing의 일부 모듈들은 transform 한 결과물로써 데이터프레임이 아닌, matrix를 반환하였었다.
따라서 get_feature_names_out()을 통해 피쳐의 이름과 합쳐 데이터프레임을 만들었어야 했다. 그런데 이때, 만약 원 데이터프레임의 index가 지정되어있었다면, 그러니까 그냥 0 1 2 등 값이 아니라, 하나의 컬럼을 index로 만들어놓은 상태였다면, DataFrame으로 만들때 index도 지정해줘야함을 잊지 말자!
사실 그냥 저 numpy array 상태로 머신러닝 모델들에 줘도 된다. 근데 나는 내가 보기에 데이터프레임이 더 좋은 것 같다.
수치형 변수들로 이루어진 데이터프레임과, 범주형 변수들의 인코딩 결과 데이터프레임을 합칠 때 index가 맞지 않아 오류가 났었었다. 오늘(11.23)도 그랬었고! 까먹지 말자.
```python
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(handle_unknown='ignore')
train_ohe = ohe.fit_transform(train.select_dtypes(exclude = 'number')).toarray()
test_ohe = ohe.transform(test.select_dtypes(exclude = 'number')).toarray()
print(train_ohe.shape, test_ohe.shape)
df_train_ohe = pd.DataFrame(train_ohe, columns = ohe.get_feature_names_out(), index= train.index)
df_test_ohe = pd.DataFrame(test_ohe, columns = ohe.get_feature_names_out(), index= test.index)
display(df_train_ohe)
df_test_ohe
df_train = pd.concat([train.select_dtypes(include= 'number'),df_train_ohe], axis = 1)
df_test = pd.concat([test.select_dtypes(include= 'number'),df_test_ohe], axis = 1)
display(train.shape, df_train.shape, test.shape, df_test.shape)
display(df_train.head())
df_test.head()그리고, drop이라는 parameter도 있는데, 만약 이 값을 if_binary 로 설정해주면, 이진형 변수에 대해 하나의 피쳐만 만들어주고, 나머지 하나는 버린다. 그래도 의미는 유지되니까!
그리고 만약에 first로 설정해주면, 모든 피쳐의 첫번째 고유값 피쳐를 버린다. 역시 결측치를 제외하면 의미는 유지될 수 있을테니!
hold-out validation
Cross-validation을 그동안 많이 사용했는데, 시간이 너무 오래걸리기도 하고, hold out validation을 많이들 사용한다고 한다.
train_test_split을 통해 train set과 valid set을 나누어 Hold_out validaion을 진행할 수 있다.
Linear Regression
Linear Regression에 대해 배웠다.
수업들으면서 그럼 DecisionTree Regressor같은건 선형회귀가 아닌건가? 선형 회귀 식을 만드는게 아닌가? 라는 의문이 들었었는데... 이제는 알고 있다!
KMOOC 들으면서 Decision Tree 와 랜덤포레스트 회귀의 원리를 알았으니까!
선형회귀와는 다른 메커니즘이라는 것을 이해했다.
- Linear regression은 종속변수 y와 한 개 이상의 독립변수 X의 선형상관관계를 모델링하는 회귀분석 기법이다.
- 둘 이상의 설명변수에 기반하는 경우 다중 선형회귀라고 한다.
- 만약 여러개의 설명변수가 X, X^2, X^3 등이라면 꼭 직선은 아닐수도 있다. X^2 라는 것을 그냥 하나의 변수 X2라고 보면, X2에 대해 선형인 것이므로! 지난번에 얼핏 배운 kernel이 생각난다!
- 그래도 선형 회귀는 결국 선을 만드는 알고리즘. 기울기(계수)와 절편을 예측하는 것! 선형 모델을 예측한다!
- 최소자승법(least square)(RSS(Residual sum of squares)가 최소가 되도록 하는법)을 통해 주로 회귀 모델을 예측한다. 손실 함수(loss function)을 최소화하는 방식으로 세우기도 한다.
특징
- 간단하고 빠르다! 이해하기 쉽다.
- 조정해줄 파라미터가 적다.
- 이상치의 영향이 크며, 스케일링의 영향을 좀 받는다! 회귀모델은 모두 이상치에 민감하다!!!!
- 데이터 전처리가 많이 필요하다.
- 데이터의 수치형 변수가 이루어져 있을 경우나 경향성이 뚜렷할 경우 사용하기 좋다.
- Ridge, Lasso, ElasticNet과 같은 선형 회귀 모델의 단점을 보완한 모델들도 있다.
sklearn에서
from sklearn.linear_model import LinearRegression
model = LinearRegression(n_jobs = -1)
model간단하게 사용할 수 있다!
공식문서
fit_intercept 를 통해 절편을 사용할건지 안할건지 결정할 수 있다.
예측하고 난 후에, 실제 값과 valid로 예측한 값을 scatterplot으로 그려 예측의 결과를 살펴보는 것도 좋은 아이디어이다!
결정 트리 모델과 앙상블
최근에 자주 보고 있다! 바로 어제 공부했던 내용
결정트리모델
어제 KMOOC 들어보니 CART 알고리즘이라는 것이 결정트리를 구성하는 알고리즘의 종류 중 하나였다. gini 계수를 이용하는!
결정트리 모델은
- 만들어진 모델에 대해서 시각화가 가능하다.
- 시각화가 가능하므로 비전문가도 이해하기 쉽다.
- 데이터의 스케일에 구애받지 않는다. (각 특성이 개별적으로 처리됨)
- 데이터의 내 변수의 종류가 달라도 잘 작동한다. (선형회귀에서는 수치형 변수만 사용 가능했음)
- 학습용 데이터에 과대적합되는 단점이 있다.
- 그래도 이상치는 처리 해주는게 좋다! 스케일링은 안해도!
어제 배운 바로는, 트리에서 회귀는 해당 노드에 속하는 학습 데이터들의 label의 평균값으로 예측한다고 하였다.
앙상블 기법
앙상블기법을 통해 결정트리 모델의 단점을 보완한다.
- 앙상블 기법이란?
여러 머신러닝 모델을 연결하여 더 강력한 모델을 만드는 기법
앙상블 기법을 이용한 머신러닝 모델은 대표적으로 랜덤포레스트와 그래디언트 부스팅 두 가지가 있다.
둘은 각각 bagging, boosting 의 앙상블을 이용한다.
bagging은 부트스트랩을 통해 조금씩 다른 훈련데이터에 대해 훈련된 기초 분류기들을 결합시키는 방법이었고, 편향은 유지하면서 분산은 감소시키기 때문에 포레스트의 성능을 향상시켰다.
따라서 이는 과대적합이 있는 경우 사용하기 적합했다.
랜덤포레스트가 bagging을 활용한 대표적인 예였고
-
성능이 뛰어나고 매개변수 튜닝을 많이 필요로 하지 않는다.
-
결정 트리와 달리 시각화가 불가능하고 비전문가가 이해하기 어려울 수 있다.
-
데이터의 크기가 커지면 다소 시간이 걸릴 수 있다.
-
랜덤성이 있기 때문에 random_state 변수를 지정하지 않으면 매번 결과가 달라질 수 있다.
-
차원이 높고(high-dimensional) 희소한(sparse) 데이터에는 잘 작동하지 않을 수 있다.
라는 특징이 있었다. -
Extratree 모델
Extremely Randomized Tree(극도로 무작위화된 모델)이다.
어제 공부했던 내용이 맞다! each tree를 build하는데 whole dataset이 사용되고, 각각의 트리는 최선의 분할이 아닌 랜덤의 분할로 나누어지는 것!
편향은 조금 늘어나지만, 분산을 더 줄일 수 있다!
분할이 랜덤이기 때문에 더 빠르다! 따라서 많은 특성을 고려할 수 있다!
일반적으로 randomforest보다 성능이 조금 더 좋다!
from sklearn.ensemble import ExtraTreesRegressor
model_et = ExtraTreesRegressor(random_state=42, n_jobs = 10, n_estimators=400, max_depth = 13)
model_et
model_et.fit(X_train,y_train).predict(X_test)boosting
bagging은 그동안 충분히 다뤘고, 오늘은 boosting에 대해서 공부하면서 정리해보자!!
boosting이란, 여러 얕은 트리를 연결하며 편향과 분산을 줄여 강력한 트리를 생성하는 기법.
이전 트리에서 틀렸던 부분에 가중치를 주며 지속적으로 학습해나간다.
앞의 모델들을 보완해 나가면서 일련의 모델들을 학습시켜 나가는 것이라고 생각하면 된다.
Bagging : parallel, 동시에 학습, 데이터 셋 모델마다 독립적
Boosting : sequential, 순차적 학습, 앞 모델이 데이터 셋 정해줌
- Gradient descent
경사하강법 - 위키
단순히 생각하면, 손실함수 그래프에서 값이 가장 낮은 지점으로 경사를 타고 하강하며 찾아가는 방법.
어제 이미 공부하고 정리 했었기에 자세한 정리는 패스!
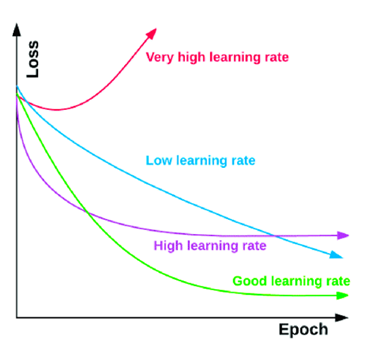
다만 중요한 learning rate에 대해서는 다시 잡고 가자.
너무 작으면 시간이 오래걸리고, 너무 크면 아예 도달을 못할 수 있다는 것!
GBT
회귀 또는 분류 분석을 수행할 수 있는, gradient descent를 boosting에 사용한 tree 모델
계산량이 상당히 많이 필요한 알고리즘이기 때문에, 이를 하드웨어 효율적으로 구현하는 것이 필요하다!
강의자료에 있는 그림으로 이해해보자면,
첫번째 트리로 먼저 예측을 진행하고, 그럼 잔차들이 생길것이다.
그럼 그 잔차들 자체를 두번째 트리로 예측을 진행한다. 거기에서 생긴 잔차들에 대해서 또
세번째 트리로 예측을 진행한다.
그렇게 잔차에 대해서 예측을 진행해나가며 잔차를 줄이고, 각각의 트리(weak learner)들을 결합하여 강한 분류기(strong learner)를 만든다. 이게 gradien boosting tree의 원리라고 한다.
GBT의 특징
- 랜덤 포레스트와 다르게 무작위성이 없다.
- 매개변수를 잘 조정해야 하고 훈련 시간이 길다.
- 데이터의 스케일에 구애받지 않는다.
- 고차원의 희소한 데이터에 잘 작동하지 않는다.
어찌되었든 트리기반이므로 파라미터가 비슷비슷하다. 특별한 파라미터로는
epoch == n_estimators 와 같은 개념, 학습 횟수를 의미한다. 부스팅 트리에서 n_estimators 는 몇 번째 트리인지를 의미한다.
validation_fraction을 통해 validation 비율을 정할 수 잇고, 이 validation을 통헤 loss를 구하게 된다.
loss = 최적화에 사용할 loss function을 설정한다.
'squared_error','absolute_error','huber','quantile'이 있다.
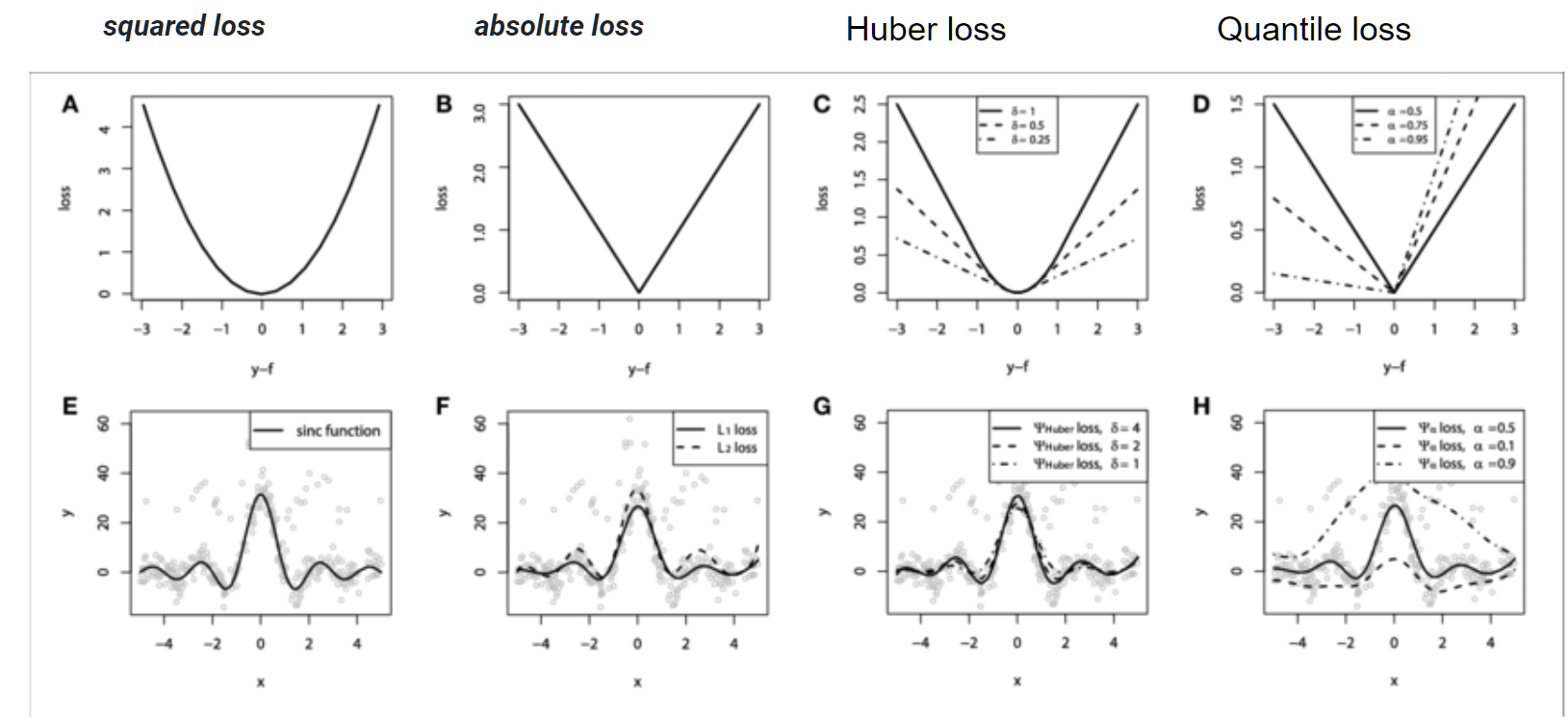
squared_error를 가장 많이 사용한다고 한다.
absolute는 미분한 기울기 값이 크기가 방향에 따라 일정하기 때문에 별로 사용하지 않는다. 그리고 미분 불가능하잖아!
Huber는 square와 absolute를 결합한것이고, quatile은 4분위수를 이용하였다. 따라서 이 두개의 값은 이상치에 강건하다.
사실 이 loss 함수들과, loss 함수들을 어떻게 사용하여 최적화를 한다는 것인지 명확하게 이해가 되지는 않았다. 아마 각 트리마다 저 loss 함수들을 이용해서 잔차를 알아내고, 그 잔차에 대해 다음 트리를 통해 예측을 진행하고, 그런 식으로 이루어지는 것 같긴 하다. 그래도 더 공부해봐야한다. 좀 일찍 일찍 좀 공부하자! In each stage a regression tree is fit on the negative gradient of the given loss function. 이라고 나와있긴 하다.
from sklearn.ensemble import GradientBoostingRegressor
model_gbt = GradientBoostingRegressor(random_state=42)
model_gbt
model_gbt.fit(X_train, y_train).predict(X_test)모델 선언 및 사용에는 여태까지 했던 방식과 크게 다를 것 없다.
이제는 사이킷런이 아닌 다른 패키지에서 사용하는 모델들에 대해 배웠다.
xgboost, lightgbm, catboost가 그것이다! 어려웠으니 정신 똑바로 차리자!
해당 모델들은 GBT에서 단점을 보완해 만들어진 것이다.
상황에 따라 적절한 모델을 사용하는 것이 중요하다!
xgboost
- GBT에서 GPU를 이용한 병렬학습을 지원하여 학습 속도가 빨라진 모델
- 정규화 그래디언트 부스팅을 제공한다.
- 기존 GBT에 비해 더 효율적이고, 다양한 종류의 데이터에 대응할 수 있다.
- Extreme gradient boosting의 약자이다.
- 2차 근사식을 바탕으로 한 손실 함수를 토대로, 매 iteration마다 하나의 leaf로부터 가지를 늘려나간다.
- 손실함수가 최대한 감소하도록 하는 split point(분할점)을 찾는 것이 xgboost의 목표이다.
장점
- GBM 대비 빠른 수행시간(GPU를 이용한 병렬 연산)
- 과적합 규제! 오버피팅 방지를 위해 regularization이 존재한다.
- 분류와 회귀 영역에서 뛰어난 예측 성능을 발휘한다.
- early stopping 기능이 있다.
- 다양한 hyper parameter가 존재한다.
단점
- 여전히 느리다.
특징
- 하이퍼파라미터의 종류가 아주 다양하다.
- scikit learn 스타일 api도 제공하고 있어 쉽게 사용할 수 있다.
xgboost scikit-learn api
특히 learning_rate, n_estimators, max_depth, min_child_weight, gamma 등! 이건 오늘자 복습에서 다루자.
lightgbm
- 결정 트리 알고리즘을 기반으로 하는 분산 그래디언트 부스팅 프레임워크를 제공
- 성능과 확장성에 초점을 맞추어 개발되었다.
- GOSS(Gradient based one side sampling)과 EFB(Exclusive Feature Bundling)을 적용하여 정확도는 유지하며 학습 시간을 상당히 단축시켰다.
GOSS와 EFB?
뭔지 진짜 하나도 모르겠다.
장점
- 더 빠른 훈련 속도와 더 높은 효율성
- 적은 메모리 사용량, 나은 정확도
- 대규모 데이터의 처리
단점
- overfitting에 민감하고, 작은 데이터에 대해서 과적합되기 쉽다!
특징
- 트리 기반이다. 다양한 알고리즘을 지원한다.
- leaf-wise 리프 중심 트리 분할 방식을 사용하여, 균형잡힌 트리를 생성하는 것이 아니라 균형을 맞추지 않고 최대 손실 값을 가지는 리프 노드만 지속적으로 분할한다. 이를 통해 비대칭적인 트리 구조를 생성하여 예측 오류 손실을 최소화한다.
- GOSS
- EFB
원래 GBT의 경우, feature의 차원이 높고 데이터의 크기가 클 경우, 가능한 모든 분할 지점의 information gain을 추정하기 위해 모든 데이터 샘플을 탐색해야해 시간이 오래걸렸다.
이러한 문제를 해결하기 위해, lightgbm에서는 feature의 차원을 줄여주고(EFB) 데이터의 크기를 줄여준다(GOSS)
GOSS
Gradeint based one side sampling
데이터에서 큰 gradient를 가진 모든 인스턴스를 사용해서 무작위로 samping을 수행한다.
-> gradient가 크다는 것은, loss가 크다는 것!(많이 틀렸다는 것)
-> sampling을 진행하여 다뤄야할 행, 데이터의 크기를 줄이되, gradient boosting의 컨셉에 맞게 많이 틀린 데이터(gradient가 큰 데이터)들을 위주로 샘플링하여 행을 줄인다!
EFB
Exclusive feature bundling
feature의 개수가 너무 많은 경우 사용하는 것으로, 희소한 행렬에 대해 feature를 하나로 합쳐주는 방법으로 feature의 개수를 줄여준다.
규호님 : Features의 수를 줄이기 위해서 차별화시켜줘서 features를 줄여준 것 입니다!! feature1은 그대로 가져가고 feature2도 그대로 가져가면 feature를 합치는 과정에서 의미가 겹치기 때문에 feature2를 합쳐줄 때 아에 다른 의미를 가진 숫자를 부여해줘서 의미가 안 겹치게 합쳐준 것입니다. 이해가 갈랑말랑 한다.
catboost
- 범주형 기능에 대한 기본 처리가 가능하고, 빠른 GPU 훈련을 제공하는 그래디언트 부스틍 프레임워크를 제공
기타
-
list에 extend로 요소 추가하기
list에 append(list)를 해주면 list 자체가 요소로 추가되지만, extend(list)해주면 해당 list의 요소들이 각각 요소로 추가된다! 까먹지 말자!!!! -
ETL과 ELT
https://www.itworld.co.kr/news/160710
https://blog.naver.com/freepsw/222276087707 -
데이터 불러오기
압축파일(zip)안에 하나의 csv 파일만 담겨있는 경우, 해당 압축파일을 통해 csv를 읽을 수 있다. 이렇게!
base_path = "data/benz"
train = pd.read_csv(f'{base_path}/train.csv.zip', index_col="ID")- 단기간내에 많은 양을 공부하고 있기 때문이겠지? 공부하다가 보면 전에 한 내용 까먹어있고, 또 하다보면 안하고있는 내용 까먹고.. 꾸준히 실습을 통한 복습을 해줘야겠다..!
더 공부해볼 것
- GBT loss 함수 huber loss와 quantile loss
- 부스팅 3대장 더 공부. 공식문서도 보기.
- 어제 복습
- 히스토그램 기반 부스팅 모델? xgboost와 lightgbm이 히스토그램 기반 그래디언트 부스팅이라는 것 같은데..?
- 예습 과제
- gradient, divergence, curl
- Ridge, Lasso, ElasticNet 등 선형 회귀 보완 모델
참고자료
https://wikidocs.net/21670
https://ko.wikipedia.org/wiki/%EC%84%A0%ED%98%95_%ED%9A%8C%EA%B7%80
https://ko.wikipedia.org/wiki/%EA%B2%B0%EC%A0%95_%ED%8A%B8%EB%A6%AC_%ED%95%99%EC%8A%B5%EB%B2%95
https://ko.wikipedia.org/wiki/%EA%B2%BD%EC%82%AC_%ED%95%98%EA%B0%95%EB%B2%95#:~:text=%EA%B2%BD%EC%82%AC%20%ED%95%98%EA%B0%95%EB%B2%95(%E5%82%BE%E6%96%9C%E4%B8%8B%E9%99%8D,%EB%95%8C%EA%B9%8C%EC%A7%80%20%EB%B0%98%EB%B3%B5%EC%8B%9C%ED%82%A4%EB%8A%94%20%EA%B2%83%EC%9D%B4%EB%8B%A4.
https://en.wikipedia.org/wiki/Gradient_descent
https://angeloyeo.github.io/2020/08/16/gradient_descent.html
https://soobarkbar.tistory.com/33
http://hejunhao.me/archives/2023
일단 지난주 복습은 여기까지 하고. 내일 오늘거 복습하면서 좀 더 자세히 공부해보자 부스팅계열 모델들은...! 어렵네 어려워. 파이팅!
