GOSS와 EFB
어제 lightgbm 복습하다 난관에 봉착했던 GOSS와 EFB에 대해서 오늘 으쌰 복습 시간에 공부했다.
특히 GOSS는 발표까지 할뻔했어서 열심히 공부했다! EFB는 좀 더 어렵네...!
GOSS(Gradient based one side sampling)
GOSS, gradient based one side sampling은 데이터의 행을 효과적으로 줄이는 방법입니다.
- 의의
gradient boosting은 데이터의 행의 개수와 열의 개수가 많으면 시간이 오래걸린다는 문제가 있었습니다. 이러한 문제를 해결하기 위해 데이터의 행의 개수를 줄여주는 방법이 바로 GOSS입니다.
GOSS는 큰 그라디언트를 가진 모든 인스턴스, 즉 행들은 유지하고 작은 그라디언트를 가진 인스턴스들은 무작위로 샘플링을 수행하는 방법을 통해 행의 개수를 줄입니다.
- 아이디어
GOSS는 기울기 기반 단측 표본 추출법이라고 할 수 있습니다. 말이 좀 어렵지만,
결국 gradient를 기반으로 어떤 데이터가 학습에 많이 도움이 되는 데이터인지 또 어떤 데이터가 학습에 별로 도움이 되지 않는 데이터인지를 파악하는 것.
그리고 학습에 도움이 되는 데이터 위주로 데이터를 샘플링하여 행의 개수를 줄이는 방법이라고 할 수 있습니다.

출처: https://www.slideshare.net/suman_lim/boostingsuman
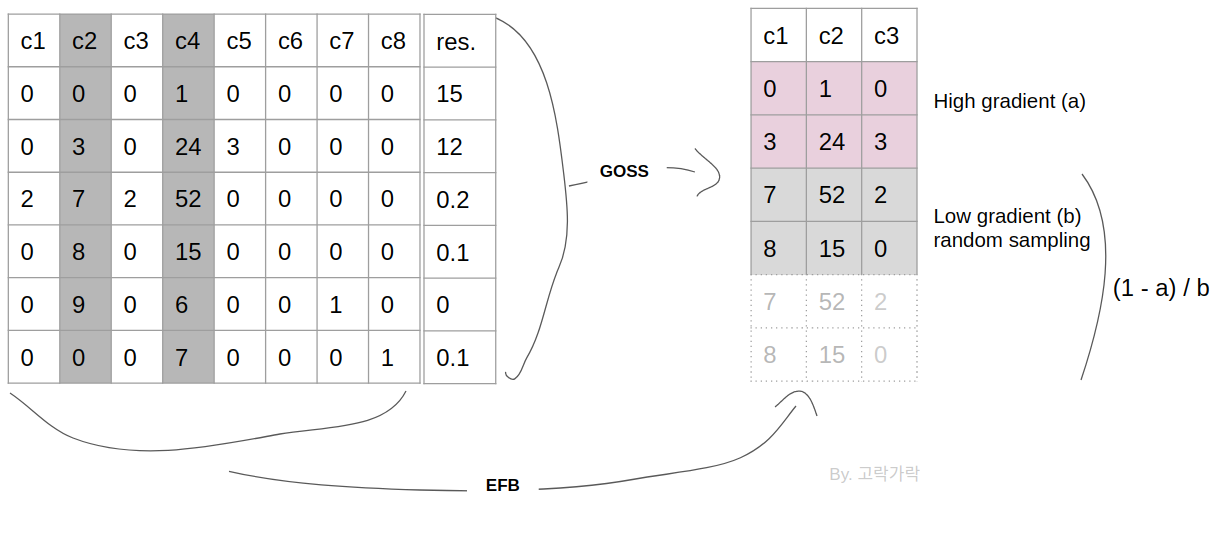
이 사진이 GOSS를 잘 설명 해주고있는 사진인데, 초록색으로 표시된 데이터들은 gradient가 큰 데이터들이고, 노란색으로 표시된 데이터들은 그라디언트가 작은 데이터들입니다. 따라서 GOSS에서는 초록색 데이터들은 모두 사용하고, 노란색 데이터들은 일부만 샘플링하여 오른쪽과 같은 데이터를 만들었습니다. 이게 바로 GOSS입니다. 그라디언트가 큰 데이터들은 모두, 작은 데이터들은 일부만 샘플링하여 사용함으로써 데이터의 행의 개수를 줄입니다.
- 좀 더 자세한 이해!
좀 더 자세하게 살펴보겠습니다.
GOSS는 lightgbm의 대표적인 특징입니다. 그리고 이 lightgbm이라는 모델은 gradient boosting Decision Tree, GBDT를 기반으로 하는 모델입니다. 그러니까 그 말은, gradient boosting을 활용하고 있는 모델이라는 뜻입니다. 즉, 하나의 트리로 예측을 한 후 생긴 잔차들을 경사하강법을 이용해 학습해나가며 boosting을 통해 예측을 진행하는 모델입니다.
따라서, GOSS에서 데이터의 행의 개수를 줄일 때에도 gradient를 참고하여, 덜 훈련된 데이터 위주로 줄여주는 것이 효과적일 것입니다.
만약에 데이터의 gradient가 크다면, 해당 데이터는 loss 함수의 값이 크고, 충분히 훈련되지 못한 인스턴스일 것입니다.
반면에 gradient가 작다면, 해당 인스턴스는 충분히 훈련되어 loss역시 작은, 학습이 잘 된 인스턴스일 것입니다.
그렇다면 Boositng을 진행하면서 데이터의 행의 개수를 줄일 때, 당연히 덜 훈련된 데이터, 즉 gradient가 큰 데이터 위주로 줄인다면, 더욱 효과적인 학습을 진행할 수 있을 것입니다.
그런데 그렇다고 해서 작은 gradient를 갖는 인스턴스들을 모두 없애버린다면, 데이터 전체의 분포가 달라져 문제가 생길 수 있습니다. 따라서, 그라디언트가 작은 인스턴스들은 랜덤하게 샘플링하여 일부만 사용합니다.
그리고 분기를 위한 계산 같은 때에, 해당 인스턴스들에 가중치를 주는 방식으로 사용하여 분포를 유지하며, 실질적인 데이터의 행의 개수를 줄일 수 있습니다.
잠시 위의 사진으로 돌아가, 오른쪽 데이터를 보면, weights라는게 있습니다. 데이터를 모두 사용한 초록색에 비해, 절반만 사용한 노란색 데이터의 weights가 큰 걸 알 수 있습니다. 이 weights가 바로 분포를 유지하면서 행의 개수를 줄이기 위해 사용하는 가중치라고 생각하시면 될 것 같습니다.

이 알고리즘은, lightgbm 발표 논문에 포함되어 있는 내용입니다.
GOSS의 알고리즘을 설명해주고 있습니다.
- 각 instance들의 gradient 계산 및 정렬
- gradient 상위 a×100% 만큼의 instance 선택
- 남은 instance들 중에서 b×100% 만큼을 무작위로 선택하고, 이 instance들에 상수 (1−a)/b 을 곱하여 데이터의 전체 개수를 맞춰준다.
- 이 instance들은 모델이 이미 충분히 학습한 데이터지만, 데이터셋의 분포를 유지하기 위해 일부분을 포함시킨다.
- (1−a)/b는 트리 Split 과정에서 information gain을 계산할 때 가중치를 곱해주는 역할을 한다.
- b의 값이 적을수록 큰 가중치를 곱해주게 된다.
- 이를 통해 원래 데이터셋의 분포를 크게 변화시키지 않고 데이터셋의 크기를 줄일 수 있다.
- 분기 계산 시 작은 gradient를 가지는 랜덤 샘플링된 데이터들을 여러 번 반복하여 들어있는 형태로 생각하고 가중치를 주어 계산한다. → 분포를 유지
- 선택한 instance 들로 GBDT 생성
출처 : http://machinelearningkorea.com/2019/09/25/lightgbm%EC%9D%98-%ED%95%B5%EC%8B%AC%EC%9D%B4%ED%95%B4/
그래서 다시 한번 요약하자면, 큰 그라디언트를 가진 모든 인스턴스를 유지하고, 작은 그라디언트를 가진 인스턴스를 무작위로 샘플링하는 방법으로 행을 줄이는 것이 바로 GOSS 였습니다.
EFB(Extra Feature bundling)
어제 공부한바로는, Exclusive한, 즉 동시에 0이 되지 않는 feature들을 하나의 bundle으로 묶어주는 것이 바로 EFB였다.
그리고 이건 히스토그램 기반 그라디언트 부스팅의 특징을 이용한 것이었다.
- EFB란
변수를 줄여 차원을 효과적으로 감소시키는 새로운 방법이 EFB라고 한다.
feature들을 하나로 묶어, 0의 개수가 적은 feature를 생성한다.
이를 통해 트리의 가지를 뻗어나가면서 사용되는 feature의 가짓수를 줄여 트리가 overfitting 되는 것을 방지한다.
- 어떻게?
Greedy하게 진행해야한다.
그래프 색칠 알고리즘을 통해 해결한다.

해당 알고리즘에서, 최소한으로 필요한 색깔의 수는 EFB에서 최소로 필요한 bundle 개수이다.
배타적인 features로 이루어진 bundle이 동일한 색상을 가진 vertex의 집합인 것이다.
알고리즘은 다음과 같다.
1. 변수들의 상호배타여부를 고려하여 그래프 생성
- 데이터셋의 각 변수들을 그래프의 vertex(꼭짓점)로 치환
- 서로 상호배타적인 변수들은 Edge로 연결되어 있지 않음
- 각 Edge의 Weight는 Edge와 연결된 두 Vertex 사이의 conflict
2. 그래프의 각 Vertex들의 Degree를 계산하고, Degree의 크기에 따라 정렬
- Vertex의 Degree는 해당 Vertex에 연결된 모든 Edge들의 weight의 합
3. bundle을 만들고, Degree가 큰 변수 순서대로, 나머지 다른 변수들간의 conflict 계산
4. conflict의 합이 전체 데이터셋 개수 r 100% 미만이 될 때까지 bundle에 추가
5. bundle의 conflict 합이 기준을 넘어가면 새로운 bundle을 만들고, 모든 변수를 다 쓸 때까지 3, 4과정을 반복
- 음? ㅠㅠ
그러니까... 저런 방식을 통해 진행한다..
그래프 색칠 알고리즘이라는 방식과 동일하게 진행되면서, 히스토그램 방식을 데이터프레임에 차용하고 있다.
각각의 데이터를 그래프에 존재하는 꼭짓점(vertex)라고 생각하고, 그래프를 그려준다.
해당 그래프에서 상호배타적인(Exclusive)한 데이터들은 서로 연결되어있지 않다.
그 후 그래프에서 degree, 즉 연결된 Edge가 많은 순으로 데이터를 정렬한 후
해당 feature들을 bundle로 만든다.
기존에 존재하는 bundle이 있고 그것과의 conflict(상호배타적이지 않은 instance의 개수) 가 작다면 기존의 번들로 묶고, 그렇지 않다면 새로운 번들로 만든다.
한 번들 내에서 값을 합쳐 하나의 변수로 만드는 것은?
- bundle 내에서 기준 변수 설정
- 모든 instance에 대해서, conflict 한 경우는 기준 변수 값 그대로 가져감
- 모든 instance에 대해서, conflict가 아닌 (상호배타적인) 경우 기준 변수의 최대값 + 다른 변수 값을 취함

출처 : https://kicarussays.tistory.com/38
만약 한 feature의 분포가 0~20이고 한 feautre의 분포가 0~30이면 뒤쪽 feature 에다가 10을 더해서 10~40이되도록 만들고 이를 합칠 수 있다. 이렇게 되면 트리모델에서는 feature마다 서로 간섭이 없으며 기존의 충돌이 났던 부분에 있어서도 커버가 가능하다.
feature의 수가 수백만개를 넘어가 너무 많다면 어려움이 있을 수 있다고 한다.
흠.. 조금은 이해가 된다! 복잡하고 어렵긴 하다....
lightgbm은 히스토그램 기반 그라디언트 부스팅 알고리즘인데, 즉 입력 feature를 256개의 bins로 나누어 사용하는 것이다. 이때 bins 중 하나는 떼어놓고 결측치를 처리하기 위해 사용한다.
히스토그램 기반 알고리즘은 연속적인 Feature 값 대신 이산적인 Bins를 저장하기 때문에, bins에 배타적인 Features를 넣어서 Feature Bundle을 구축할 수 있다.
sparse(희소한) feature들을 하나의 bins에 넣어 bundle로 사용함으로써, 각각의 feature가 어디에 있는지 tracking이 가능함과 동시에, sparse하지 않은 하나의 feature로 (번들) 만들 수 있는 것!
feature와 관련된 정보를 유실하지 않고도 효과적으로 feature의 수를 줄일 수 있다
어찌 되었든!
GOSS와 EFB를 통해서, lightgbm은 데이터의 사이즈를 줄여 속도 측면에서 획기적인 발전을 이루어내었다!
GOSS는 그라디언트를 기반으로, 높은 그라디언트는 유지, 낮은 것은 샘플링하여 행을 줄이는 것!
EFB는 그래프 방식을 통해 Exclusive한 feature 들끼리 하나의 bundle로 만들어주어 feature가 특성을 잃지 않으면서도 feature의 개수를 줄여준다. 이는 lightgbm이 히스토그램 기반 작동방식을 사용하고 있기 때문에 가능한 것이다!
