자기주도학습 시간에 해보던 10 minutes to pandas를 마저 해보며 pandas의 주요 기능을 쑥 훑었다! 아주 겉핥기 식이라서 추가로 공부해야할 내용이 많지만, 앞으로 차차 하게 될 것이다! 일단 고생했다! 그럼 정리하자.
Merge
Concat
df = pd.DataFrame(np.random.randn(10,4))
df
>>>
0 1 2 3
0 -1.345767 0.060268 0.273399 2.933490
1 -0.724019 0.021057 0.133716 -0.565686
2 0.201320 -1.130608 0.661130 -0.948045
3 0.581565 -0.934015 -0.072898 0.190208
4 -1.619333 -0.962170 -2.620479 0.148532
5 0.664873 0.437375 -0.983109 -0.803991
6 0.753616 0.977194 0.100916 -0.662687
7 0.024990 1.472055 0.089708 -0.518602
8 -1.699485 1.018244 0.842714 -0.592658
9 0.289843 0.271469 1.964552 1.090194
pieces = [df[:3],df[3:7],df[7:]] # df를 조각으로 나눈다!
pieces
>>>
[ 0 1 2 3
0 -1.345767 0.060268 0.273399 2.933490
1 -0.724019 0.021057 0.133716 -0.565686
2 0.201320 -1.130608 0.661130 -0.948045,
0 1 2 3
3 0.581565 -0.934015 -0.072898 0.190208
4 -1.619333 -0.962170 -2.620479 0.148532
5 0.664873 0.437375 -0.983109 -0.803991
6 0.753616 0.977194 0.100916 -0.662687,
0 1 2 3
7 0.024990 1.472055 0.089708 -0.518602
8 -1.699485 1.018244 0.842714 -0.592658
9 0.289843 0.271469 1.964552 1.090194]
pd.concat(pieces)
>>>
0 1 2 3
0 -1.345767 0.060268 0.273399 2.933490
1 -0.724019 0.021057 0.133716 -0.565686
2 0.201320 -1.130608 0.661130 -0.948045
3 0.581565 -0.934015 -0.072898 0.190208
4 -1.619333 -0.962170 -2.620479 0.148532
5 0.664873 0.437375 -0.983109 -0.803991
6 0.753616 0.977194 0.100916 -0.662687
7 0.024990 1.472055 0.089708 -0.518602
8 -1.699485 1.018244 0.842714 -0.592658
9 0.289843 0.271469 1.964552 1.090194Concatenate : (사슬같이) 잇다. 라는 뜻
.concat() 함수를 이용해 pandas의 다양한 object 들을 이어 붙일 수 있다!
기본적으로 axis = 0, 열 방향, 공통된 열을 찾아 행을 밑으로 이어붙이며, axis = 1로 변경하여 행 방향 잇기도 가능하다.
Merge(join)
left = pd.DataFrame({"key" : ["foo","foo"], "lval":[1,2]})
left
>>>
key lval
0 foo 1
1 foo 2
right = pd.DataFrame({"key":["foo","foo"],"rval":[4,5]})
right
>>>
key rval
0 foo 4
1 foo 5
pd.merge(left, right, on = "key")
>>>
key lval rval
0 foo 1 4
1 foo 1 5
2 foo 2 4
3 foo 2 5
merge는 concat과 유사하게 합쳐주는 역할을 한다. 단지 concat이 특정 축을 기준으로 그냥 이어 붙여준다는 느낌이면,
merge는 공통된 column을 기준으로 묶어주는 느낌인 것 같다.
on 인자에 공통된 요소 (주로 column)을 주고, how 인자에 left, right, inner, outer 등 다양한 옵션을 준다.
on을 굳이 안써도 된다! 자동으로 찾아서 연결해준다.
저거 inner, outer 뭔가 컴활할때 배운 느낌인데.. inner 는 양쪽 df에 모두 키가 존재하는 데이터만, outer는 하나 쪽 만 있어도 보여준다.
그래 컴활에서 액세스 하면서 배웠던 그거다! left, right는 각각 한쪽의 키를 모두 보여주는 것이다.
결과를 보면 이어붙일때, 총 4개의 행이 만들어지고, 각각의 데이터가 서로 한번씩 연결되는 모습이다.
left = pd.DataFrame({"key": ["foo", "bar"], "lval": [1, 2]})
right = pd.DataFrame({"key": ["foo", "bar"], "rval": [4, 5]})
print(left)
print(right)
pd.merge(left, right)
>>>
key lval
0 foo 1
1 bar 2
key rval
0 foo 4
1 bar 5
key lval rval
0 foo 1 4
1 bar 2 5다음과 같이도 사용할 수 있다. 앞의 예시랑 다른데 뭐라고 설명해야 할지 모르겠네..
음 앞의 것은 공통된 key에 같은 value를 가진 행들이 많아 병합할때 각 value당 모든 자료들이 연결되게 (2번씩) 병합되었다면,
이번 예시에서는 서로 다른 value에 대해 병합되어 데이터들이 한번만 나오며 병합할 수 있다...!? 나도 이해가 안되네..!
일단은 이정도로만 이해해두고(예습이니까!) 본 강의 때 제대로 들어보자(그때 결석이려나..?)
Grouping
By “group by” we are referring to a process involving one or more of the following steps:
splitting the data into groups based on some criteria (나누고)
Applying a function to each group independently (함수를 적용한 후)
Combining the results into a data structure (df에서 볼 수 있게 종합한다.)
라는 세가지 기능을 할 수 있다!
df = pd.DataFrame( {
"A": ["foo", "bar", "foo", "bar", "foo", "bar", "foo", "foo"],
"B": ["one", "one", "two", "three", "two", "two", "one", "three"],
"C": np.random.randn(8),
"D": np.random.randn(8),
}
)
df
>>>
A B C D
0 foo one 0.180907 0.374038
1 bar one -0.752016 -0.983150
2 foo two 1.028086 -0.580275
3 bar three 1.528641 -1.097630
4 foo two -2.553377 -0.648513
5 bar two -0.182320 0.747313
6 foo one 1.312554 0.519598
7 foo three -1.571586 -0.905643df.groupby("A")[["C","D"]].sum()
>>>
C D
A
bar 0.594305 -1.333468
foo -1.603417 -1.240795A에 대해 그룹화 (groupby) 한 후, C와 D 칼럼에 대해 sum 연산을 한 결과를 표시해준다.
이때, 연산 및 표시의 대상이 두개 이상의 컬럼이므로, list를 만들어 사용한다.
df.groupby(["A", "B"]).sum()
>>>
C D
A B
bar one -0.752016 -0.983150
three 1.528641 -1.097630
two -0.182320 0.747313
foo one 1.493461 0.893636
three -1.571586 -0.905643
two -1.525292 -1.228788두 개 이상의 column에 대해서 groupby 할 수도 있다. 다음은 A에 대해 그룹화 한 후, B에 대해서도 그룹화 한 예시이다.
Reshaping
Stack
tuples = list(
zip(
["bar", "bar", "baz", "baz", "foo", "foo", "qux", "qux"],
["one", "two", "one", "two", "one", "two", "one", "two"],
)
)
index = pd.MultiIndex.from_tuples(tuples, names=["first", "second"])
index
>>>
MultiIndex([('bar', 'one'),
('bar', 'two'),
('baz', 'one'),
('baz', 'two'),
('foo', 'one'),
('foo', 'two'),
('qux', 'one'),
('qux', 'two')],
names=['first', 'second'])Multiindex라는 기능이 등장했다! pd.MultiIndex.from_tuples를 사용해 값이 두개인 튜플들의 쌍의 리스트를 받아
'first' 와 'second' 라는 이름을 붙여 준 multiindex를 만들었다.
신기해라...
df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=["A", "B"])
df2 = df[:4]
df2
>>>
A B
first second
bar one 0.269040 -1.893337
two -0.929677 -0.879801
baz one -1.299803 0.452324
two 0.145833 0.733716만든 Multiindex를 df에서 보니까, groupby를 두개의 column에 대해 사용해서 만들었을 때와 같은 형태인 것 같다.
같은 느낌의 기능인 듯하다.
stacked = df2.stack()
stacked
>>>
first second
bar one A 0.269040
B -1.893337
two A -0.929677
B -0.879801
baz one A -1.299803
B 0.452324
two A 0.145833
B 0.733716
dtype: float64stack 메소드를 사용한다.
Df를 series 형태로 압축해버린다!
stacked.unstack()
>>>
A B
first second
bar one 0.269040 -1.893337
two -0.929677 -0.879801
baz one -1.299803 0.452324
two 0.145833 0.733716multiindex를 가진 stacked series 혹은 df에 대해, unstack()기능을 사용하여 원래대로 돌릴 수 있다.
이때, 인자를 몇을 넣어주느냐에 따라 특정 index만 unstack 시킬 수 있다.
stacked.unstack(1)
>>>
second one two
first
bar A 0.269040 -0.929677
B -1.893337 -0.879801
baz A -1.299803 0.145833
B 0.452324 0.733716
stacked.unstack(0)
>>>
first bar baz
second
one A 0.269040 -1.299803
B -1.893337 0.452324
two A -0.929677 0.145833
B -0.879801 0.733716pivot tables
# 느낌상 아주 중요한 기능 중 하나인 피봇테이블!
df = pd.DataFrame(
{
"A": ["one", "one", "two", "three"] * 3,
"B": ["A", "B", "C"] * 4,
"C": ["foo", "foo", "foo", "bar", "bar", "bar"] * 2,
"D": np.random.randn(12),
"E": np.random.randn(12),
}
)
df
>>>
A B C D E
0 one A foo 0.674129 -0.450293
1 one B foo 0.053113 0.184874
2 two C foo 0.415151 -0.638119
3 three A bar -0.379065 2.032709
4 one B bar 0.060208 0.516138
5 one C bar 0.698962 -1.359319
6 two A foo 1.352213 1.051065
7 three B foo 0.388009 -0.217108
8 one C foo 1.026507 -0.324780
9 one A bar 0.216833 0.211656
10 two B bar 1.001016 1.598097
11 three C bar 0.687781 0.387419
pd.pivot_table(df, values="D", index=["A", "B"], columns=["C"])
>>>
C bar foo
A B
one A 0.216833 0.674129
B 0.060208 0.053113
C 0.698962 1.026507
three A -0.379065 NaN
B NaN 0.388009
C 0.687781 NaN
two A NaN 1.352213
B 1.001016 NaN
C NaN 0.415151.pivot_table()을 사용하면, dataframe의 특정 value, index, column 들을 pivot(회전) 시킨다.
원하는 값, 인덱스, 컬럼을 골라 테이블을 만든다고 생각할 수 있겠다!
Time Series
rng = pd.date_range("1/1/2022",periods=100,freq = "S")
ts = pd.Series(np.random.randint(0,500,len(rng)), index = rng)
ts.resample("5Min").sum()
>>>
2022-01-01 24776
Freq: 5T, dtype: int32date_range() : 앞에서 나왔던 것 처럼, 시작할 날짜, peridos = 기간(몇개나?) freq = s(초),t(분),d(일)등 다양
여기선 또 randint를 썼네? randint는 정수 한개를 뽑아내는 것이란다! randint(start, stop, 몇개)
resample method로는 시간 단위별 그룹화가 가능하다. 여기서 ts라는 series는 index가 시간으로 1월 1일부터 1초씩
100개의 데이터가 있는데, 그럼 5분이 안되니까, 1월 1일 이라는 하나의 index로 다 묶인다.
rng = pd.date_range("3/6/2012 00:00", periods = 5, freq = "D")
ts = pd.Series(np.random.randn(len(rng)),rng)
ts
>>>
2012-03-06 -0.233984
2012-03-07 -1.769242
2012-03-08 1.695777
2012-03-09 0.570224
2012-03-10 -0.218507
Freq: D, dtype: float64
ts_utc = ts.tz_localize("UTC")
ts_utc
>>>
2012-03-06 00:00:00+00:00 -0.233984
2012-03-07 00:00:00+00:00 -1.769242
2012-03-08 00:00:00+00:00 1.695777
2012-03-09 00:00:00+00:00 0.570224
2012-03-10 00:00:00+00:00 -0.218507
Freq: D, dtype: float64.tz_localize() 함수는 현재의 시간을 시간대로 현지화하는 메소드이다. 뭔소리지 이게..?
변수에 저장된 시간(timestamp)가 있는데, 그 시간이 따르는 시간대와 다른 시간대를 사용하고 싶은 경우
tz_localize() 함수를 통해 시간대를 바꾸어 주어 사용하는 느낌인 것 같다.
밑의 tz_convert를 하니 이해가 조금 가는데, 시간이 저장된 변수에 대해 이 시간이 어떤 시간대를 따르고 있는 변수인지를 정해주는 함수이다! 해당 시간대가 정해지면 tz_convert를 통해 다른 시간대에서는 몇시인지 알 수도 있고!
ts_utc.tz_convert("Asia/Seoul")
>>>
2012-03-06 09:00:00+09:00 -0.233984
2012-03-07 09:00:00+09:00 -1.769242
2012-03-08 09:00:00+09:00 1.695777
2012-03-09 09:00:00+09:00 0.570224
2012-03-10 09:00:00+09:00 -0.218507
Freq: D, dtype: float64반면 .tz_convert()는 변수에 저장된 시간을, 다른 시간대의 시간으로 바꾸어주는 함수이다.
예를 들어 우리나라의 경우 UTC + 9:00 이므로 그렇게 변환된다.
rng = pd.date_range("1/1/2012", periods=5, freq="M")
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts
>>>
2012-01-31 -0.299616
2012-02-29 1.002966
2012-03-31 -0.859367
2012-04-30 0.421615
2012-05-31 2.197092
Freq: M, dtype: float64
ps = ts.to_period()
ps
>>>
2012-01 -0.299616
2012-02 1.002966
2012-03 -0.859367
2012-04 0.421615
2012-05 2.197092
Freq: M, dtype: float64.to_period() 함수는 datetimeindex(그동안 저장되던 시간 형식)을 period로 바꾸어준다. period index는 원하는 단위로 시간을 출력할 수 있는 변수이다. freq = M, D 등으로 다양하게 바꾸면 해당 freq에 맞춰진 단위로 출력된다.
시간표현을 기간표현으로 바꾸어준다고 생각할 수 있다.
ps.to_timestamp()
>>>
2012-01-01 -0.299616
2012-02-01 1.002966
2012-03-01 -0.859367
2012-04-01 0.421615
2012-05-01 2.197092
Freq: MS, dtype: float64.to_timestamp() 함수는 반대로 period를 datetime으로 변경 할 수 있는 함수이다.
prng = pd.period_range("1990Q1", "2000Q4", freq="Q-NOV")
ts = pd.Series(np.random.randn(len(prng)), prng)
ts.index = (prng.asfreq("M", "e") + 1).asfreq("H", "s") + 9
ts.head()
>>>
1990-03-01 09:00 -0.205130
1990-06-01 09:00 1.028961
1990-09-01 09:00 0.425250
1990-12-01 09:00 -0.269325
1991-03-01 09:00 0.607806
Freq: H, dtype: float64이와 같은 변경은 산술적 연산을 용이하게 하기 위해 주로 사용된다.
헤딩 코드를 살펴보면, periodondex의 경우 freq = "Q-NOV"로, 11월을 기준으로 하는 분기별 표시를 띠고 있는데
.asfreq("M","e")를 통해 월의 마지막으로 변경 후 +1을 해 분기별 익월의 첫날로, .asfreq("H", "s")를 사용해
시간의 시작에 9시간을 더해 9시로 바꾸어 주는 코드였다.
어렵다!
Categoricals
df = pd.DataFrame(
{"id": [1, 2, 3, 4, 5, 6], "raw_grade": ["a", "b", "b", "a", "a", "e"]}
)
df["grade"] = df["raw_grade"].astype("category")
df["grade"]
>>>
0 a
1 b
2 b
3 a
4 a
5 e
Name: grade, dtype: category
Categories (3, object): ['a', 'b', 'e']pandas는 범주형(categorical) 데이터도 데이터프레임에 담을 수 있다.
위와 같이 특정 데이터의 타입을 .astype()을 통해 category로 바꾸어 주면 해당 column은 범주형 데이터가 된다.
new_categories = ["very good","good","very bad"]
df["grade"] = df["grade"].cat.rename_categories(new_categories)
df["grade"]
>>>
0 very good
1 good
2 good
3 very good
4 very good
5 very bad
Name: grade, dtype: category
Categories (3, object): ['very good', 'good', 'very bad']위 에서 나왔었던 내용이다! category 의 method를 .cat 접근자를 이용해 사용할 수 있다.
.rename_categories()를 통해 category의 이름을 바꾸어 줄 수도 있다.
df["grade"] = df["grade"].cat.set_categories(
["very bad", "bad", "medium", "good", "very good"]
)
df["grade"]
>>>
0 very good
1 good
2 good
3 very good
4 very good
5 very bad
Name: grade, dtype: category
Categories (5, object): ['very bad', 'bad', 'medium', 'good', 'very good'].set_categories()를 통해서는 카테고리의 순서를 바꾸고, 데이터에 등장하지 않는 카테고리도 추가할 수 있다.
df.sort_values(by="grade")
df
>>>
id raw_grade grade
0 1 a very good
1 2 b good
2 3 b good
3 4 a very good
4 5 a very good
5 6 e very badsort를 하면, category의 순서에 따라 정렬되는 것을 알 수 있다.
df.groupby("grade").size()
>>>
grade
very bad 1
bad 0
medium 0
good 2
very good 3
dtype: int64category에 대해 그룹화 할 수도 있으며, 그룹화할 시 데이터가 없는 카테고리도 표시된다.
Plotting
import matplotlib.pyplot as plt
plt.close("all")
# 기본 내장에 더해 더 다양한 기능을 사용하기 위해 matplotlib을 import 한다.
ts = pd.Series(np.random.randn(1000), index = pd.date_range("1/1/2000", periods = 1000))
ts = ts.cumsum()
ts.plot()
>>>
<AxesSubplot:>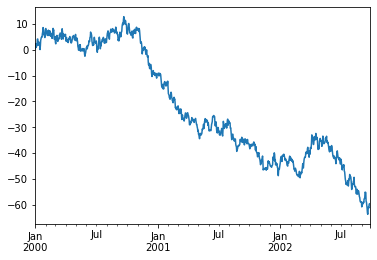
pandas에는 matplotlib이 내장되어 있어 간단한 그래프를 그릴 수 있다.
.plot()을 사용하여 그래프를 표시할 수 있다.
df = pd.DataFrame(
np.random.randn(1000, 4), index=ts.index, columns=["A", "B", "C", "D"]
)
df = df.cumsum()
plt.figure() #figure를 만들어준다. (도화지 같은 존재)
df.plot() #그래프를 그린다.
plt.legend(loc = "best")
>>>
<matplotlib.legend.Legend at 0x1be1aa27f40>
<Figure size 432x288 with 0 Axes>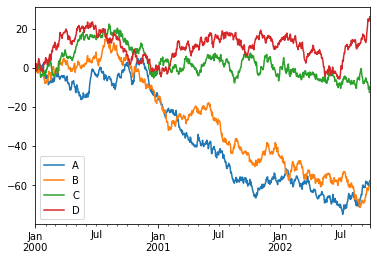
다음과 같이 plt의 메소드를 사용해 범주를 넣는 등의 설정을 할 수 있다. 사실 이건 matplotlib을 이용한거긴 한데!
plot()의 경우 안에 kind인자를 넣어 그래프의 종류를 여러가지로 표시할 수 있다.
Importing and Exporting data
df.to_csv("foo.csv")
pd.read_csv("foo.csv")
>>>
Unnamed: 0 A B C D
0 2000-01-01 -1.131219 0.900540 1.020935 1.168506
1 2000-01-02 -0.837580 0.259674 0.104154 2.321883
2 2000-01-03 -0.154225 -0.665919 1.955652 1.863767
3 2000-01-04 -0.174514 -1.144058 1.207617 1.538545
4 2000-01-05 -0.620681 -1.241339 1.676543 -1.664398
... ... ... ... ... ...
995 2002-09-22 -60.345311 -60.749376 -10.602060 23.737733
996 2002-09-23 -60.007225 -60.655051 -9.578959 24.245110
997 2002-09-24 -58.261700 -60.267391 -12.612838 24.765844
998 2002-09-25 -57.663043 -60.214249 -12.122598 26.101355
999 2002-09-26 -58.653142 -58.372942 -12.148844 26.089489
1000 rows × 5 columns.to_csv() : dataframe을 csv 파일로 내보낸다.
pd.read_csv() :pandas의 method를 사용해 csv파일을 읽을 수 있다. df 형태이므로 df에 저장할 수 있다.
df.to_hdf("foo.h5","df")
pd.read_hdf("foo.h5","df")
>>>
A B C D
2000-01-01 -1.131219 0.900540 1.020935 1.168506
2000-01-02 -0.837580 0.259674 0.104154 2.321883
2000-01-03 -0.154225 -0.665919 1.955652 1.863767
2000-01-04 -0.174514 -1.144058 1.207617 1.538545
2000-01-05 -0.620681 -1.241339 1.676543 -1.664398
... ... ... ... ...
2002-09-22 -60.345311 -60.749376 -10.602060 23.737733
2002-09-23 -60.007225 -60.655051 -9.578959 24.245110
2002-09-24 -58.261700 -60.267391 -12.612838 24.765844
2002-09-25 -57.663043 -60.214249 -12.122598 26.101355
2002-09-26 -58.653142 -58.372942 -12.148844 26.089489
1000 rows × 4 columnsHDF5란 빅데이터 시대의 크고 복잡한 데이터셋을 다루기 위한 파일 형식이라고 한다.
df.to_excel("foo.xlsx",sheet_name = "Sheet1")
pd.read_excel("foo.xlsx","Sheet1",index_col=None, na_values=["NA"])
>>>
Unnamed: 0 A B C D
0 2000-01-01 -1.131219 0.900540 1.020935 1.168506
1 2000-01-02 -0.837580 0.259674 0.104154 2.321883
2 2000-01-03 -0.154225 -0.665919 1.955652 1.863767
3 2000-01-04 -0.174514 -1.144058 1.207617 1.538545
4 2000-01-05 -0.620681 -1.241339 1.676543 -1.664398
... ... ... ... ... ...
995 2002-09-22 -60.345311 -60.749376 -10.602060 23.737733
996 2002-09-23 -60.007225 -60.655051 -9.578959 24.245110
997 2002-09-24 -58.261700 -60.267391 -12.612838 24.765844
998 2002-09-25 -57.663043 -60.214249 -12.122598 26.101355
999 2002-09-26 -58.653142 -58.372942 -12.148844 26.089489
1000 rows × 5 columnsexcel 파일로도 보내고, 읽을 수 있다.
Gotchas
if pd.Series([False, True, False]):
print("I was true")
>>>
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In [149], line 1
----> 1 if pd.Series([False, True, False]):
2 print("I was true")
File ~/work/pandas/pandas/pandas/core/generic.py:1526, in NDFrame.__nonzero__(self)
1524 @final
1525 def __nonzero__(self) -> NoReturn:
-> 1526 raise ValueError(
1527 f"The truth value of a {type(self).__name__} is ambiguous. "
1528 "Use a.empty, a.bool(), a.item(), a.any() or a.all()."
1529 )
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().해당 오류가 나는 경우가 있다. 사실 이해 못했다. 머리가 안돌아간다!
윽악 검색해보니 검색했었던 적이 있었다!
나는 저 오류가 &대신 and를 사용하고 | 대신 or를 사용하여 났던 오류였다. pandas에서는 & 와 |를 사용해 줘야 한다고 했었다. 뭐 그런 경우도 있고...
인터넷을 찾아보니 이렇게 나온다..
This value error is caused by using a mask (boolean series) in the place of a truth value. A mask has values that are either True or False, varying from row to row. As a result, Python can't determine whether a series as a whole is True or False - it is ambiguous.
When searching for dataframe rows that only match a single condition, we can avoid the error with masking, using df[] and placing the statement generating the mask within the brackets, for example, df[df['price'] < 30000].
If looking for rows that match multiple conditions, to avoid the error, we must replace statements like and, or and not with their respective bitwise operators, &, | and ~.
일단 그렇게 알아두자! ㅋㅋㅋ
10 minutes to pandas를 한번 다 보긴 했다!
10 minutes라더니... 4시간이 걸렸다!
어쨌든 이제 pandas 기초를 배우면서, 공부에 큰 도움이 되길 빈다!
앞으로도 파이팅!
[참고] 10 minutes to pandas
