세번째 논문 리뷰.
사실 이번주 너무 바쁘고 정신없고 스트레스 받아서.
좀 쉽게 가려고 했는데 생각보다 많이 어려웠다.
그래서 더 스트레스 받은건,,,
그래도 열심히 읽고 정리해보았다...
파이팅..!
Visualizing and Understanding Convolutional Networks : ZFNet
- 2013년 발표된 논문.
- ILSVRC 대회에서 AlexNet에 이어 우승을 차지한 모델
- 모델 자체의 구조는 AlexNet과 크게 달라지지 않았고, 논문의 제목에서 볼 수 있듯이 시각화 기법을 도입해 CNN의 동작 원리를 이해하는데 초점을 맞춘 논문이다.
Abstract
- Image classification에 있어 CNN은 좋은 성능을 내고 있다.
- 그러나, CNN이 어떤 방식으로 동작하는지, 왜 좋은 성능을 내는지에 대한 명확한 이해는 이루어지고 있지 않다.
- 본 논문에서는 새로운 시각화 기술을 도입하여 convolutional layer의 feature를 시각화하여 convolutional network가 어떻게 동작하는지 이해하고, 더 좋은 모델 구조를 고안한다.
- 또한 classifier에 대한 실험을 진행해 CNN이 어떻게 동작하는지 더 깊은 이해를 제공한다.
- 마지막으로 ImageNet 데이터로 학습한 feature가 다른 데이터 셋에도 일반화여 사용될 수 있음을 보인다.
1. Introduction
- 2012년도 ILSVRC에서 AlexNet이 우승하면서, CNN이 복잡한 이미지 분류 문제에 좋은 성능을 낼 수 있음을 보였다.
- 매우 큰 데이터셋이 생기고, GPU의 계산 성능이 강력해지고, dropout 같은 regularization 방법이 발전하면서 CNN이 재발견 되었다.
- 그러나 CNN이 어떻게 내부에서 동작하고 좋은 성능을 내는지는 알려져 있지 않다.
- 따라서 이 논문에서는 Deconvolutional Network를 사용한 새로운 시각화 기법을 도입하여 input Image가 모델 내부의 feature map을 어떻게 활성화시키는지를 시각화한다.
- 추가적으로 학습이 진행되는 동안 feature가 어떻게 학습되는지 과정 역시 시각화하고, 이를 통해 모델의 어느 부분을 개선해야 성능이 더 좋아질지에 대해 고민한다.
- 그리고, Input Image의 특정 부분들을 가린 채 classification을 진행해보며 CNN에서 classification이 어떻게 진행되는지에 대한 분석 역시 진행한다.
1.1. Related Work
- 여태까지 feature를 Input Image Pixel space에 투영하여 시각화하려는 시도는 대부분이 첫 번째 층의 레이어에서만 진행되었다.
- 높은 층의 layer에서는 그러한 방법이 작동하지 않았고, Hessian등을 사용한 몇몇 수치적 계산 방법으로만 feature가 어떻게 형성되는지에 대한 대략적인 이해를 제공하였다.
- 본 논문에서는 이러한 문제를 해결하기 위해 비모수적인 방법을 사용해 Input pixel space에 feature map을 투영하여, 이미지의 어떤 부분이 feature map을 활성화시키는지 시각화한다.
2. Approach
- AlexNet의 Convolutional layer 구조를 먼저 살펴보면, convolution → relu → max pooling 의 순서로 이루어져있다.
2.1. Visualization with a Deconvnet
-
CNN의 작동 방식을 이해하기 위해서는 각 layer에서 feature map이 어떻게 activation되는지에 대한 해석을 해야한다.
-
따라서 논문에서는 이러한 activation들을 input pixel space로 매핑시켜, 어떤 input pattern이 해당 activation을 유발했는지를 보여주는 방법을 제시한다.
-
앞에서 Conv → relu → Max pooling의 과정으로 이어지는 AlexNet의 동작방식을 언급하였는데, 이와 정확히 반대의 과정을 수행함으로써 activation을 input space에 매핑시킨다.
-
이는 Deconvnet 을 통해 이루어진다.
-
각각의 convolutional layer에 해당하는 만큼 deconvnet을 부착한다고 생각하면 된다.
-
원하는 activation을 input space에 매핑시키기 위해서, feature map의 다른 activation은 모두 0으로 만든 후 feature map을 deconvnet에 통과시킨다.
-
deconvnet에서는 unpooling → rectify → deconvolution을 거친다.
-
연속된 여러 deconvnet layer를 거쳐 목표로 하는 activation을 input space에 매핑시킬 수 있다.
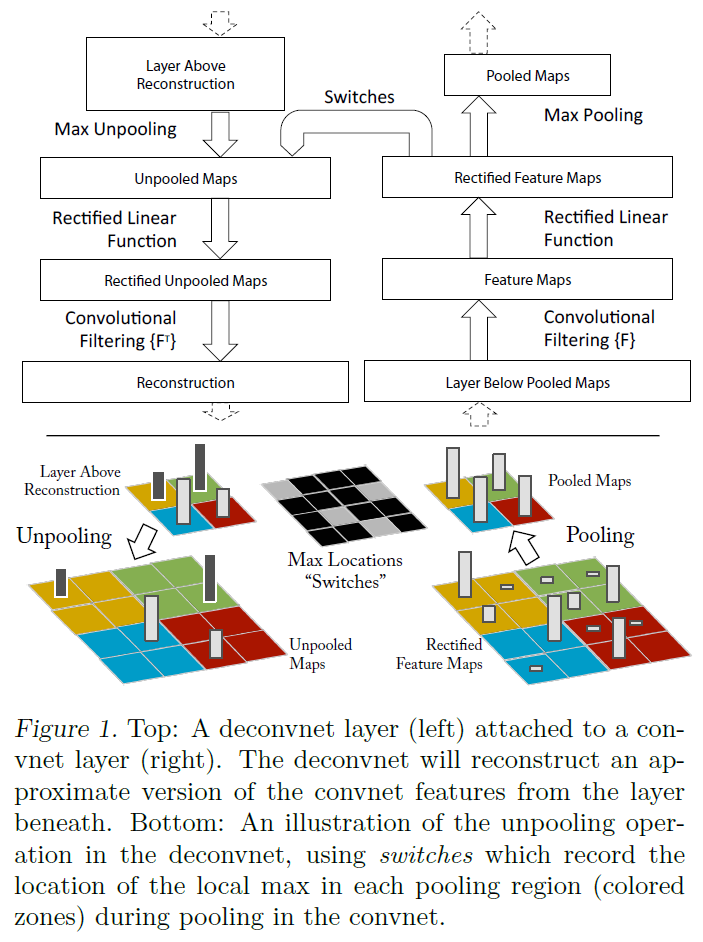
- Deconvnet에서 일어나는 연산들을 조금 더 자세히 살펴보자.
Unpooling
- Max Pooling의 역 연산에 해당하는 것이 바로 Unpooling이다.
- 하지만 Max pooling은 여러 값들 중 최대값만을 남기는 연산이므로 완벽한 역연산을 수행할 수 없다.
- 따라서 역연산을 위해 switch라는 방법론을 도입하는데, 이는 pooling이 일어나는 과정에서 최대값의 위치를 기록하는 방법이다.
- 각각의 pooling region에서의 최대값의 위치를 swtich를 통해 알고 있으므로, unpooling에서는 해당 위치에 pooling 된 값들을 매핑시키고, 나머지 위치는 0으로 채워준다.
- 이를 통해 원래 input의 위치 정보 및 이미지 구조가 보존된 상태로 unpooling을 진행할 수 있다.
Rectification
- Activation function인 ReLU의 역연산에 해당하는 부분이다.
- ReLU는 양수인 값들만 남기는 활성함수이므로, 역연산에서도 단지 ReLU 그대로를 적용해준다.
- 이렇게하면 음수인 값들을 복원하지 못하는 문제가 발생하지만, 결과에 큰 영향을 미치지 않는다.
Filtering
- convolution layer에서는 filter들에 대해 이미지와 convolution 연산을 수행한다.
- 이 과정의 역연산을 위해서, filter를 transpose 시킨 transpose filter들과 이미지를 convolution 연산한다.
- convolution 연산을 filter를 sparse matrix로 만들어 이미지와 행렬 곱 하는 연산과 동일하게 생각할 수 있기 때문에, transpose와 filtering 해준다면 역연산을 하는 효과가 있다.
3. Training Details
논문에 사용된 모델과 학습 방법에 대해서 설명하고 있다. AlexNet과 대체적으로 유사하지만, 하나의 차이점은 layer 3,4,5 사이에 사용된 sparse connections이다. (2개의 GPU에서 연산을 진행하기 때문에) ZFNet에서는 이 sparse connection을 dense connection으로 변경하였다.
모델은 imagenet 2012 training set에 대해 학습되었고, 각각의 RGB image는 256*256의 사이즈로 resizing 되었다. mini batch size 128의 stochastic gradient descent 방법이 사용되었고, 0.01의 learning rate로 시작하였다. momentum의 값은 0.9이다. dropout 역시 fully connected layer에 0.5의 비율로 사용되었다. 모든 weights는 0.01의 값으로 초기화되었다.
Fig 6.(a)를 보면 알 수 있듯이, 첫번째 layer의 filter를 시각화해보면 그들 중 아주 일부만이 dominate 함을 알 수 있다. 즉, 몇개의 필터만이 다른 필터에 비해 매우 높은 값을 가진다. 이러한 상황은 모델의 효율성을 감소시킬 수 있으므로, 이를 해결하기 위해 필터의 RMS vlaue가 0.1의 범위를 초과하는 필터를 0.1로 normalize 시킨다. 이것은 특히 모델의 첫번째 층에 있어서 매우 중요한 과정이다. 모델의 효율성을 저하시키는 것을 방지하고, 각 필터의 크기를 조절하여 모델이 더욱 효과적으로 학습하도록 한다.
4. Convnet Visulization
Feature Visulization
- 모델을 학습하고 앞서 언급한 시각화 기법을 사용하여 시각화를 진행하였다.
- 주어진 feature map의 상위 9개 activation에 대해서 deconvolutional network를 통해 input space로 매핑한 결과와 해당 부분에 해당하는 input image의 patch를 시각화하였다.
- network의 깊이에 따라 계층적인 구조를 띄고 있음을 확인할 수 있다.

- layer 1과 2에서는 주로 corner, edge, 색상에 반응을 하고 있다.
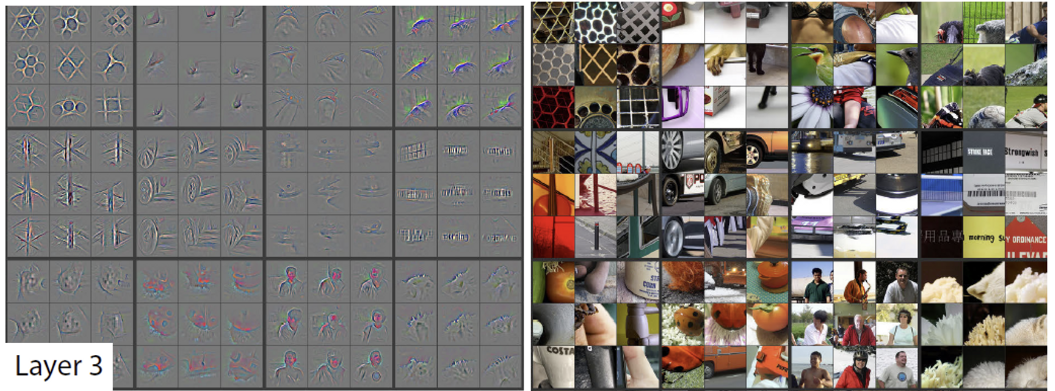
- layer 3에서는 mesh pattern과 같은 비교적 더 복잡한 texture에까지 반응을 하고 있다.

- layer 4와 5에서는 더욱 구체적인 형상에 반응하여, 개의 얼굴, 새의 다리 등의 class specific한 feature와 포즈 변화가 있는 전체 객체에까지 반응을 하는 모습을 확인할 수 있다.
Feature Evolution during Training

- 각 layer에서 epoch에 따라 feature를 시각화한 결과이다.
- 낮은 층의 layer에서는 몇 에포크만에 feature가 수렴하지만, 높은 층의 layer로 올라갈수록 40 에포크가 넘어가서야 feature가 수렴하는 모습을 확인할 수 있다.
- 즉 높은 층의 layer에서 더 오랜 시간에 걸쳐 학습이 이루어진다.
Feature Invariance
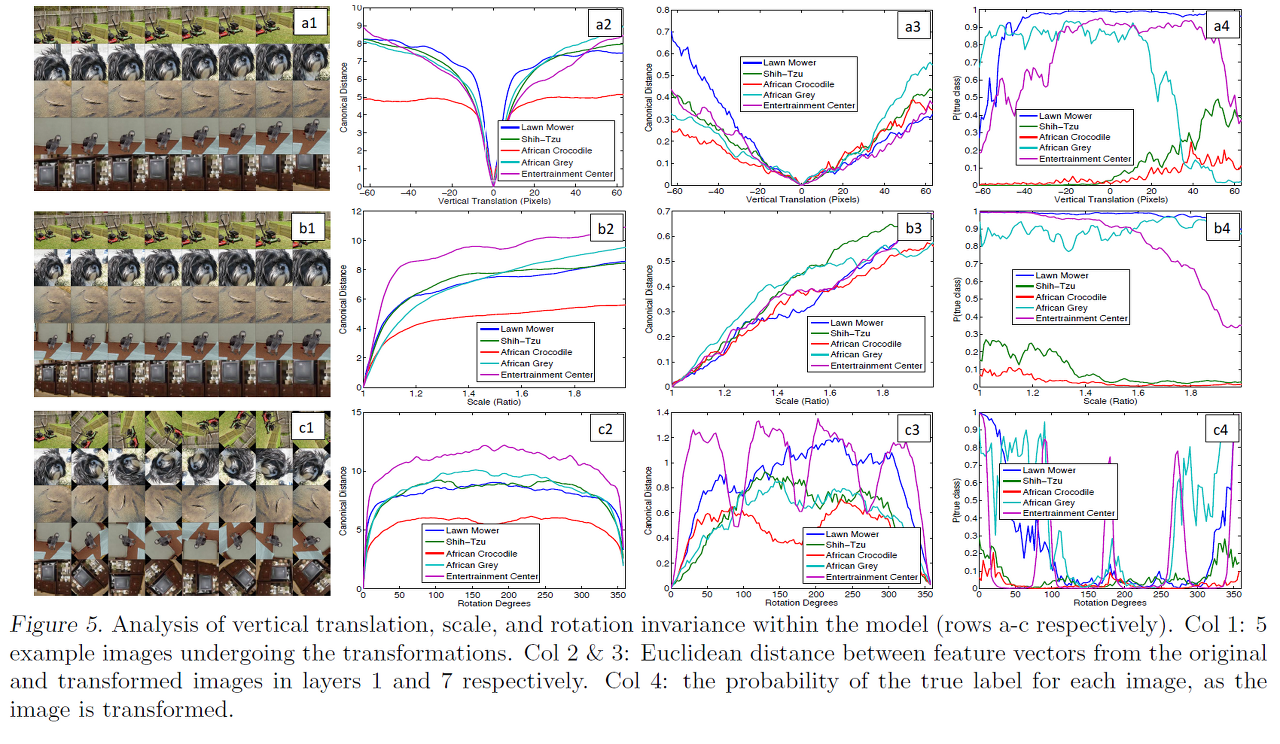
-
5개의 샘플 이미지를 각각 이동, scaling, rotation 하여 원래 feature와의 차이를 나타낸 그래프이다.
-
layer가 낮을때에는 작은 이미지 변형도 큰 영향을 끼치지만, layer가 높아짐에 따라서 점차 영향이 줄어든다.
-
결론적으로는 translation과 scaling에 대해서는 output에 영향이 존재하지 않았다.
-
다만 rotation의 경우 원래 회전에 대해 대칭적인 물체들을 제외하고는 영향이 존재하였다.
-
여기까지 ZFnet을 통해 시각화한 feature들에 대해 살펴보았다.
-
높은 activation에 대해 해당하는 위치와 filter를 찾아내어 거꾸로 연산해 반대로 input space에 투영시킨 결과들을 보았다고 생각하면 될 것 같다.
-
결과적으로는 낮은 layer에서는 색상, edge 등과 같은 단순한 feature를 학습하였고 높은 layer로 올라갈수록 구체적인 물체의 형상이 학습된다는 사실을 알 수 있었다.
4.1. Architecture Selection
- 이러한 feature 시각화를 통해 모델의 어떤 부분에 문제가 있으며, 어떻게 개선해야할지를 알아볼 수 있다.
- 아래 figure에서 보면 첫번째 layer에서 stride 4로 filtering을 진행한 탓에 feature에 aliasing이 발생함을 확인하였다.
- 따라서 이를 해결하기 위해 ZFNet은 AlexNet의 첫번째 layer의 filter size를 11 x 11에서 7 x 7로 줄이고, stride 역시 2로 줄였다.
- 이를 통해 첫번째와 두번째 레이어의 feature가 더 많은 정보를 가질 수 있게 하여 classification 성능에 개선을 가져올 수 있었다.

4.2. Occlusion Sensitivity

- 앞에서 언급하였다시피, 해당 논문에서는 input image의 특정 부분을 가리면서 classifier가 어떻게 동작하는지를 확인하는 실험 역시 진행하였다.
- 이는 CNN이 어떻게 동작하는지를 조금 더 이해하기 위한 실험인데, 맥락만을 활용하여 classification을 수행하는지, 혹은 정확한 물체의 위치를 찾아내어 classification을 수행하는지를 확인하기 위한 실험이다.
- 해당 figure는 input image의 특정 부분을 가려가며 실험을 진행한 결과이다.
- 먼저 (c)는 해당 input image에 대해 최상단의 convolutional layer에서 가장 강력한 feature map을 deconvnet을 이용해 시각화한 결과이다. 강아지의 얼굴이 가장 강력한 feature로 추출되었음을 확인할 수 있다.
- (b)는 해당 input image의 가린 부분을 옮겨가며 feature map의 활성도를 나타낸 것인데, 강아지의 얼굴 부분을 가렸을 때 activation이 확 떨어지는 모습이다.
- (d)는 input image에서 가린 부분을 옮겨가며 classification이 정답일 확률을 나타낸 것인데, 강아지의 얼굴 부분을 가렸을 때 확률이 가장 떨어짐을 볼 수 있다.
- (e)는 각 부분을 가렸을 때 classification의 예측 결과를 나타낸 것인데 역시 강아지의 얼굴 부분을 가렸을 때에만 다른 class로 예측함을 확인할 수 있다.
- 즉, CNN이 강아지의 얼굴이라는 강력한 feature를 학습하여 이미지에서 해당 feature에 해당하는 부분을 찾아내 classification을 수행한다는 것을 확인할 수 있다.
- 또한, 강아지의 얼굴이 가장 강력한 feature였고, 해당 부분을 가렸을 때 여러 반응이 일어난다는 점에서 feature의 시각화가 제대로 이루어졌음을 확인할 수 있다.
4.3. Correspondece Analysis

- 해당 실험은 CNN 모델이 서로 다른 이미지에서 물체의 특정 부분간의 대응을 어떻게 인식하는지를 알아보기 위한 실험이다.
- 예를 들어 얼굴은 눈과 코의 조합으로 이루어져 있는데, 딥러닝 모델이 이를 계산하는지 아닌지에 대해 알아본다.
- 이를 위해 5개의 서로 다른 강아지 이미지에 동일한 특정 부위(ex : 왼쪽 눈)를 가린 후 featuer vector를 얻어내고, 원래의 feature vector와의 차이를 계산한다.
- 그 후 각 이미지 간 그 차이를 Hamming distance로 계산하여, 그 값이 작다면 왼쪽 눈을 가렸을때 서로 다른 각 이미지들에서 feature가 달라진 방식이 유사하다는 것을 의미한다.
- 실험 결과 5번째 레이어에서 낮은 점수를 기록해, CNN 모델이 특정 물체를 구성하는 부분간의 대응을 계산함을 알 수 있었다.
5. Experiments
5.1. ImageNet 2012
- AlexNet보다 성능이 1.7% 향상되어 14.8%의 error rate를 가졌다.
5.2. Feature Generalization
- ImageNet 데이터로 학습한 feature들을 사용하여 Caltech-101과 Caltech-256 데이터셋에서도 좋은 성능을 얻었다.
- 해당 feature를 일반화하여 다른 dataset에도 사용할 수 있음을 확인하였다.
5.3. Feature Analysis
- ImageNet으로 학습된 레이어의 수를 다르게 하며 caltech dataset에 대해 평가를 진행하였더니, layer의 수가 많을수록 좋은 성능을 내었다.
- network의 hierachy가 깊어질수록 더 강력한 feature를 학습함을 알 수 있다.
6. Conclusion
본 논문에서는 Image Classification을 위한 CNN에 대해 여러 방향에서 탐색해보았다.
먼저, 모델 안에서 일어나는 활동들을 시각화하기 위한 새로운 방법을 고안하였다. 이를 통해 feature가 직관적으로 알아볼 수 있는 객체를 표시한다는 사실을 알게되었으며, layer가 높아질수록 더욱 불변성있고 클래스간 구분이 가능한 특징들을 학습함을 보여준다. 또한, 이러한 시각화를 더 좋은 성능을 얻기 위해 모델을 디버깅하는 수단으로도 활용하여, AlexNet의 성능을 개선하기도 하였다.
또한, 이미지의 일부를 가려보는 실험을 통하여 이미지가 단지 넓은 장면의 상황정보만을 활용하여 classification 되는 것이 아니라, 지역적인 특징에 민감하게 반응한다는 사실을 확인할 수 있었다.
마지막으로, ImageNet에 대해 train된 모델들이 다른 데이터셋에도 잘 일반화하여 사용될 수 있음을 보였다.
