- 데이터베이스(DB, DataBase)는 일정한 규칙, 혹은 규약을 통해 구조화되어 저장되 는 데이터의 모음
- 해당 데이터베이스를 제어, 관리하는 통합 시스템 -> DBMS (DataBase Management System)
- 데이터베이스 안에 있는 데이터들은 특정 DBMS마다 정의된 쿼리 언어(query language)를 통해 삽입, 삭제, 수정, 조회 등을 수행할 수 있음
- 데이터베이스는 실시간 접근과 동시 공유가 가능합니다.
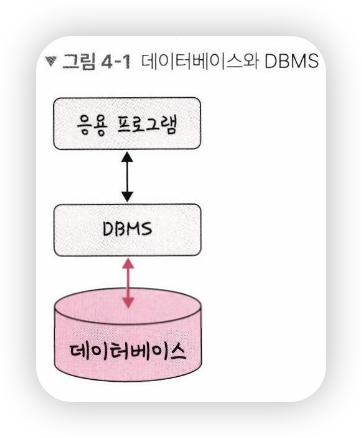
- 그림처럼 데이터베이스 위에 DBMS가 있고 그 위에 응용 프로그램이 있으며, 이러 한 구조를 기반으로 데이터를 주고받음
-> 예를 들어, MySQL이라는 DBMS가 있고 그 위에 응용 프로그램에 속하는 Node.js나 php에서 해당 데이터베이스 안에 있는 데이터를 끄집어내 해당 데이터 관련 로직을 구축할 수 있는 것
엔터티
- 사람, 장소, 물건, 사건, 개념 등 여러 개의 속성을 지닌 명사를 의미
- 예를 들어, 회원이라는 엔터티가 있을 때, 회원은 이름, 아이디. 주소, 전화번호의 속성을 갖음
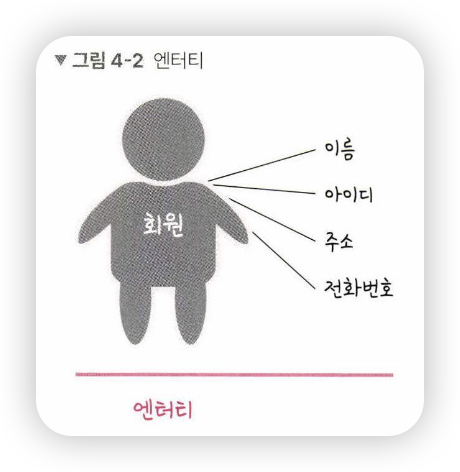
- 서비스의 요구 사항에 맞춰 속성이 정해짐
-> 예를 들어, 주소라는 속성이 서비스의 요구 사항과 무관한 속성이라면, 주소라는 속성은 사라지게 됨
약한 엔터티와 강한 엔터티
- 엔터티는 약한 엔터티와 강한 엔터티로 나뉩니다.
- 예를 들어 A가 혼자서는 존재하지 못하고 B의 존재 여부에 따라 종속적이라면, A는 약한 엔터티이고 B는 강한 엔터티가 됨
- 예를 들어, 방은 건물 안에만 존재하기 때문에 방은 약한 엔터티라고 할 수 있고 건물은 강 한 엔터티라고 할 수 있음
릴레이션
- 데이터베이스에서 정보를 구분하여 저장하는 기본 단위
- 엔터티에 관한 데이터를 데이터베이스는 릴레이션 하나에 담아서 관리
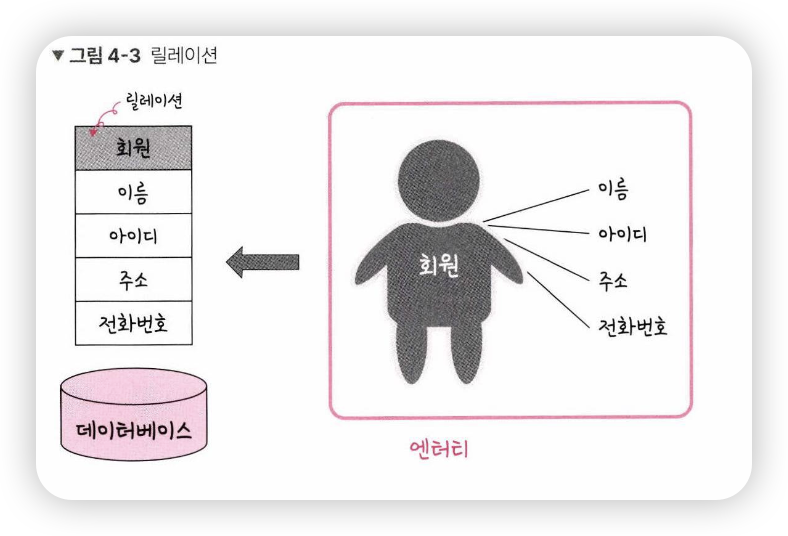
- 그림처럼 회원이라는 엔터티가 데이터베이스에서 관리될 때, 릴레이션으로 변화된 것을 볼 수 있음
- 릴레이션은 관계형 데이터이스에서는 '테이블', NosQL 데이터베이스에서는 컬렉션'
테이블과 컬렉션
- 데이터베이스의 종류 : '관계형 데이터베이스'와 'NoSQL 데이터베이스'
- 대표적인 관계형 데이터베이스 - MySQL, 대표적인 NoSOL 데이터베이스 - MongoDB를 예로,
- MySOL의 구조는 레코드-테이블-데이터베이스
- NoSQL 데이터베이스의 구조는 도큐먼트-컬렉션-데이터베이스
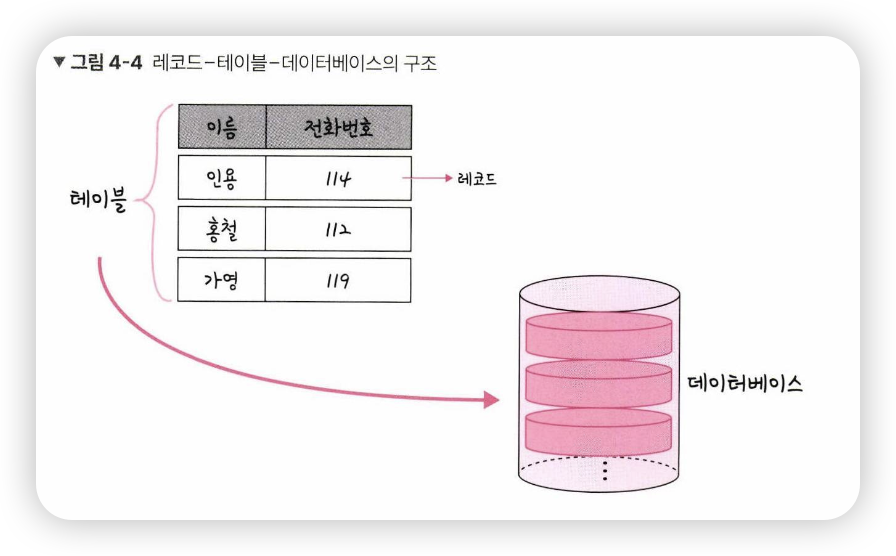
- 그림처럼 레코드가 쌓여서 테이블이 되고, 테이블이 쌓여서 데이터베이스가 됨
속성
- 릴레이션에서 관리하는 구체적이며 고유한 이름을 갖는 정보
- ex) '차'라는 엔터티의 속성엔 '차 넘버, 바퀴 수, 차 색깔, 차종' 등
-> 이 중에서 서비스의 요구 사항을 기반으로 관리해야 할 필요가 있는 속성들만 엔터티의 속성이 됨
도메인
- 릴레이션에 포함된 각각의 속성들이 가질 수 있는 값의 집합을
- ex) 성별이라는 속성이 있다면, 이 속성이 가질 수 있는 값은 {남, 여}라는 집합
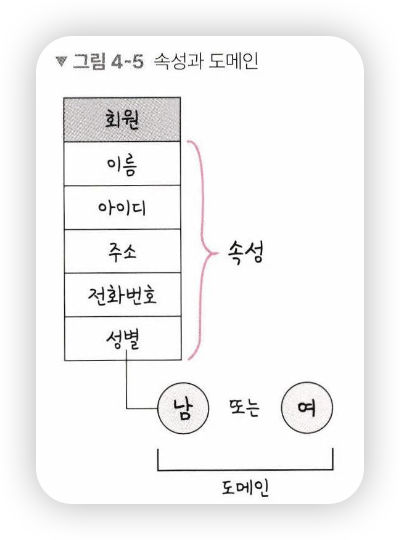
- 그림처럼 '회원'이라는 릴레이션에, '이름, 아이디, 주소, 전화번호, 성별'이라는 속성이, 성별은 {남, 여}라는 도메인을 가지는 것을 알 수 있음
필드와 레코드
- 앞의 것들을 기반으로 데이터베이스에서 필드와 레코드로 구성된 테이블을 만들 수 있음

- '회원'이란 엔터티는 member라는 테이블로
-> 속성인 '이름, 아이디' 등을 가지고 있으며
-> name, ID, addres 등의 필드를 가짐
-> 이 테이블에 쌓이는 행 단위의 데이터를 레코드라고 함 (튜플이라고도 함)
테이블 생성 예
- '책'이라는 엔터티를 정의하고 이를 기반으로 테이블을 생성
- '속성' - 이름, 저자의 아이디, 출판년도, 장르, 생성 일시, 업데이트가 있다고 가정
- 이 엔터티를 데이터베이스에 넣어 테이블로 만들려면, 이 속성에 맞는 타입을 정의해야 함
(타입은 데이터베이스마다 조금씩 차이가 있는데, MySOL을 기준으로 설명)
타입 설정
- 책의 아이디: INT
- 책의 제목: VARCHAR(255)
- 책의 저자 아이디: INT
- 책의 출판년도:VARCHAR(255)
- 책의 장르: VARCHAR(255)
- 생성 일시: DATETIME
- 업데이트 일시: DATETIME
테이블 생성

- 보통 한글을 속성 이름으로 쓰지는 않음
-> tide, author_id 등으로 영어 이름에 매핑해서 쓰며, 속성과 타입들이 들어간 것을 볼 수 있음
MySOL로 구현
CREATE TABLE book (
id INT NOT NULL AUTO_INCREMENT,
title VARCHAR (255),
author_id INT,
publishing_year VARCHAR(255),
genre VARCHAR (255), c
reated_at DATETIME,
updated at DATETIME,
PRIMARY KEY (id)
);필드 타입
- 필드는 타입을 갖음 -> ex) 이름은 문자열이고 전화번호는 숫자
- 타입들은 DBMS마다 다름 (여기선 MYSQL 기준)
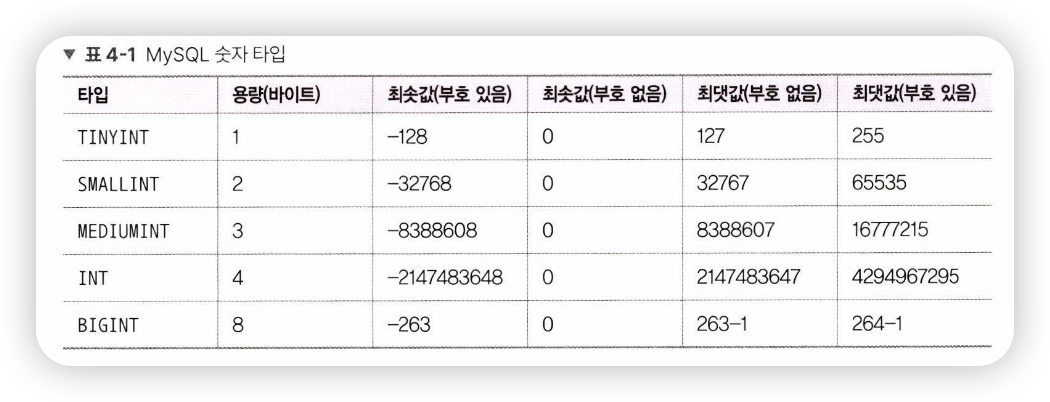
숫자 타입
- 숫자 타입으로는 TINYINT, SMALLINT, MEDIUMINT, INT. BIGINT 등이 있음
날짜 타입
- 날짜 타입으로는 DATE, DATETIME, TIMESTAMP 등이 있음
DATE
- 날짜 부분은 있지만 시간 부분은 없는 값에 사용됩
- 지원되는 범위는 1000-01-01 ~ 9999-12-31
- 3바이트의 용량
DATETIME
- 날짜 및 시간 부분을 모두 포함하는 값에 사용됩
- 지원되는 범위는 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
- 8바이트의 용량
TIMESTAMP
- 날짜 및 시간 부분을 모두 포함하는 값에 사용
- 지원되는 범위는 1970-01-01 00:00:01 ~ 2038-01-19 03:14:07
- 4바이트의 용량
문자 타입
문자 타입으로는 CHAR, VARCHAR, TEXT, BLOB, ENUM, SET이 있음
CHAR와 VARCHAR
- 둘 다, 그 안에 수를 입력해서 몇 자까지 입력할지 정함 -> CHAR(30)이라면 최대 30글자
- CHAR은 테이블을 생성할 때, 선언한 길이로 고정
-> 길이는 0에서 255 사이의 값을 가짐
-> 레코드를 저장할 때 무조건 선언한 길이 값으로 고정해서 저장 - VARCHAR은 가변 길이 문자열
-> 길이는 0 ~ 65,535 사이의 값으로 지정 가능
-> 입력된 데이터에 따라, 용량을 가변시켜 저장
-> ex) 10글자의 이메일을 저장할 경우, VARCHAR(10000)으로 선언했어도, 10글자에 해당하는 바이트 + 길이기록용 1바이트로 저장
👉🏻 그렇기 때문에 지정된 형태에 따라 저장된 CHAR의 경우 검색에 유리하며,
검색을 별로 하지 않고 유동적인 길이를 가진 데이터는 VARCHAR로 저장하는 것이 좋음
TEXT와 BLOB
- 큰 데이터를 저장할 때 쓰는 타입들
- TEXT는 큰 문자열 저장에 쓰며 주로 게시판의 본문을 저장할 때 씀
- BLOB은 이미지, 동영상 등 큰 데이터 저장에 씀
-> 그러나, 보통은 아마존의 이미지 호스팅 서비스인 S3를 이용하는 등 서버에 파일을 올리고 파일에 관한 경로를 VARCHAR로 저장
ENUM과 SET
- 문자열을 열거한 타입들
- ENUM은 ENUM(x-small, small, medium, 1arge, x-large) 형태로 쓰임
-> 이 중에서 하나만 선택하는 단일 선택만 가능
-> ENUM 리스트에 없는 잘못된 값을 삽입하면 빈 문자열이 대신 삽입
-> ENUM을 이용하면, x-small 등이 0, 1 등으로 매핑되어, 메모리를 적게 사용하는 이점
-> 최대 65,535개의 요소들을 넣을 수 있습 니다. - SET은 ENUM과 비슷하지만 여러 개의 데이터를 선택 가능
-> 비트 단위의 연산 가능
-> 최대 64개의 요소를 집어넣을 수 있음
👉🏻 ENUM이나 SET을 쓸 경우 공간적으로 이점을 볼 수 있지만,
애플리케이션의 수정에 따라 데이터베이스의 ENUM이나 SET에서 정의한 목록을 수정해야 한다는 단점
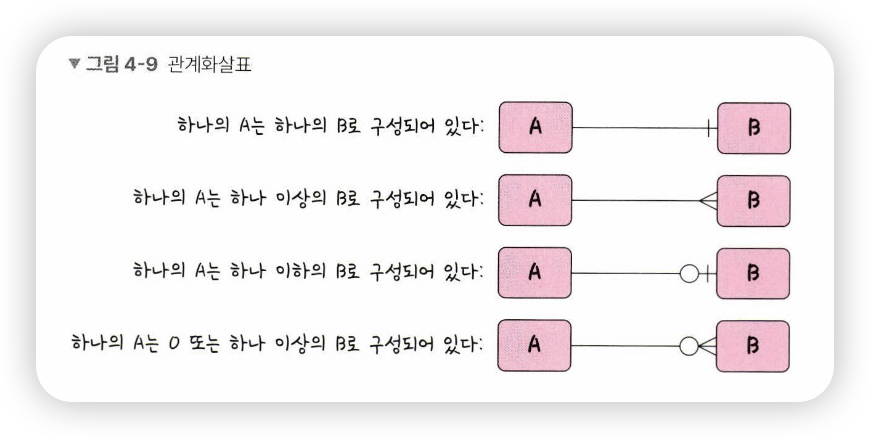
관계
- 데이터베이스에 테이블은 하나만 있는 것이 아님
-> 여러 개의 테이블이 있고 이러한 테이블은 서로의 관계가 정의되어 있음
-> 이러한 관계를 관계화살표로 나타냄
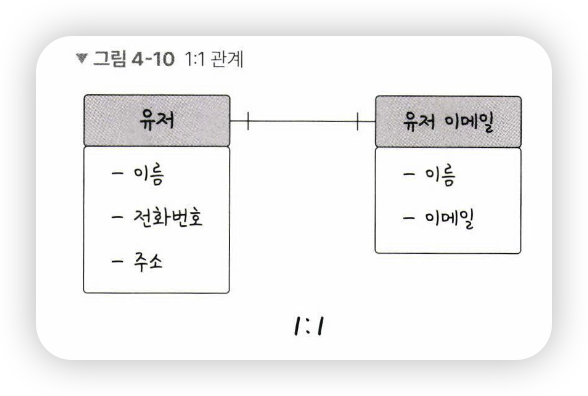
1:1 관계
-
ex) 유저당 유저 이메일은 한 개씩이므로, 1:1 관계
-
1:1 관계는 테이블을 두 개의 테이블로 나눠, 테이블의 구조를 더 이해하기 쉽게 함
1:N 관계
- ex) 쇼핑몰을 운영한다고 가정
-> 한 유저당 여러 개의 상품을 장바구니에 넣을 수 있음
-> 1:N 관계 (한 개체가 다른 많은 개체를 포함하는 관계)
-> 하나도 넣지 않는 0개의 경우도 있으니, 0도 포함되는 화살표를 통해 표현해야 함
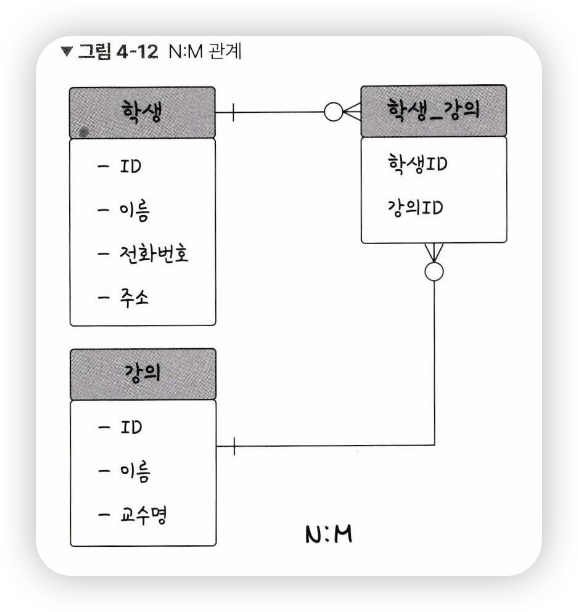
N:M 관계
-
ex) 학생과 강의의 관계를 정의하면
-> 학생도 강의를 많이 들을 수 있고, 강의도 여러 명의 학생을 포함할 수 있음
-> N:M
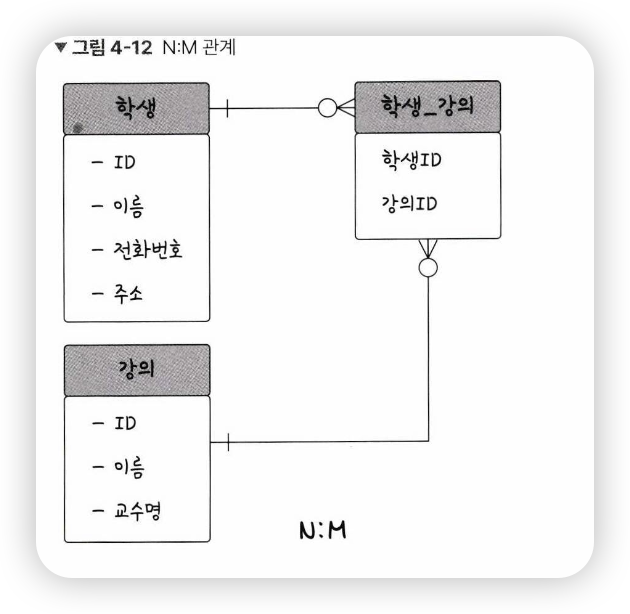
-
그림의 중간에 학생_강의라는 테이블이 끼어 있음
-> N:M은 테이블 두 개를 직접적으로 연결해서 구축하지는 않고, 1:N. 1:M이라는 관계를 갖는 테이블 두 개로 나눠서 설정
키
- 테이블 간의 관계를 조금 더 명확하게 하고, 테이블 자체의 인덱스를 위해 설정된 장치
- 기본키, 외래키, 후보키, 슈퍼키, 대체키가 있음
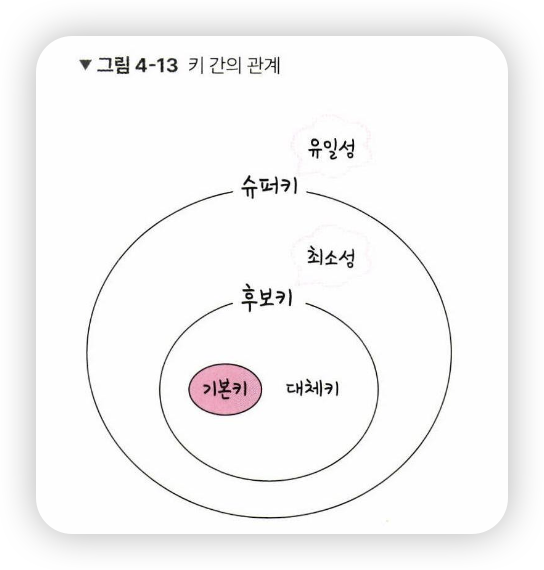
- 슈퍼키는 유일성이 있고, 그 안에 포함된 후보 키는 최소성까지 갖춘 키
- 유일성 : 중복되는 값은 없음
- 최소성 : 필드를 조합하지 않고, 최소 필드만 써서 키를 형성할 수 있는 것
- 후보키 중에서 기본키로 선택되지 못한 키는 대체키가 됨
기본키
- Primary Key 줄여서 PK 또는 프라이머리키라고 많이 부름
- 유일성과 최소성을 만족하는 키

- 테이블의 데이터 중 고유하게 존재하는 속성
- 기본키에 해당하는 데이터는 앞의 그림의 1D처럼 중복되어서는 안됨
-> PDT-0002가 중복되기 때문에, ID라는 필드는 기본키가 되지 말아야 함
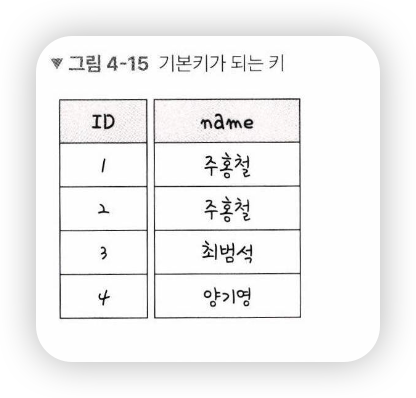
-
그림에서 ID는 기본키로 설정 가능
-> {ID. name} 이라는 복합기를 기본키로 설정할 수 있지만, 그렇게 되면 최소성을 만족하지 않음 -
기본키는 자연키 또는 인조키 중에 골라 설정
자연키
- ex) 유저 테이블을 만든다고 가정하면 주민등록번호, 이름, 성별 등의 속성이 있dma
-> 이름, 성별 등은 중복된 값이 들어올 수 있으므로, 부적절하고 남는 것은 주민등록번호 - 이런식으로 중복된 값들을 제외하며 중복되지 않는 것을, '자연스레' 뽑다가 나오는 키를 자연키라고 함
- 자연키는 언젠가는 변하는 속성을 가집니다.
인조키
- ex) 유저 테이블을 만든다고 했을 때, 회원 테이블을 생성한다고 가정하면 주민등록 번호, 이름, 성별 등의 속성이 있음
-> 여기에 인위적으로 유저 아이디를 부여
-> 이를 통해 고유 식별자가 생겨남 (오라클은 sequence, MySOL은 auto increment 등 으로 설정) - 이렇게 인위적으로 생성한 키를 인조키라고 함
- 자연키와는 대조적으로 변하지 않음 -> 따라서 보통 기본키는 인조키로 설정
외래키
-
FK라고도 함
-
다른 테이블의 기본키를 그대로 참조하는 값으로, 개체와의 관계를 식별하는 데 사용
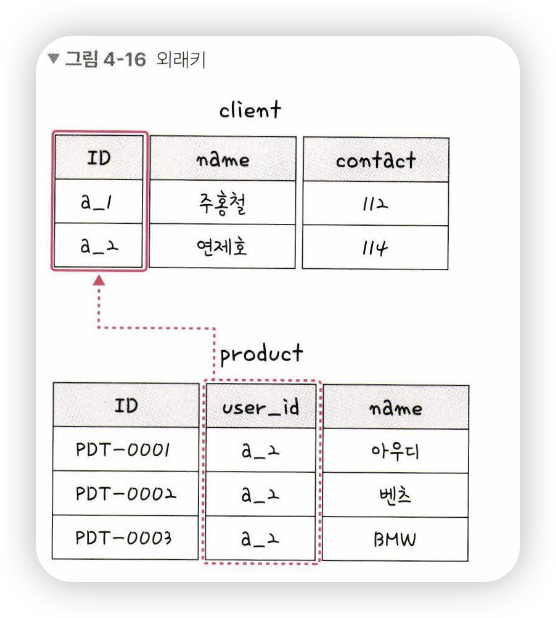
-
외래키는 중복 가능
-
그림을 보면, client라는 테이블의 기본키인 ID가, product라는 테이블의 user_id라는 외래키로 설정될 수 있음을 보여줌
-
또한, user_id 는 a_2라는 값이 중복되는 것을 볼 수 있음
후보키
- 기본키가 될 수 있는 후보들
- 유일성과 최소성을 동시에 만족하는 키
대체키
- 후보키가 두 개 이상일 경우 어느 하나를 기본키로 지정하고 남은 후보키들
슈퍼키
- 각 레코드를 유일하게 식별할 수 있는 유일성을 갖춘 키
