
목표
딥러닝계의 Legend 논문(이론) 중 EfficientNet에 대해 배워보자!
이 내용은 혁펜하임님의 'Legend 13' 강의를 기반으로 작성함.
이 내용은 전 작성 내용과 이어집니다.
EfficientNet
지금까지 모델의 성능을 키우기 위한 여러가지 시도들이 있었는데,
주로 깊이를 늘리는 것 (ResNet), width를 키우는 것 (WideResNet), 해상도를 키우는 것(MobileNet) 등이 있었다.
EfficientNet은 위의 세 가지 요건을 같이 키우되 효율적으로 키우는 것을 목표로 하는 모델이다!
그렇다면 왜 이 세 가지만 선택했을까?
그 이유로 크게 두 가지를 뽑을 수 있는데,
첫째는 직접적으로 모델 용량에 영향을 주기 때문이다.
세 파라미터 모두 모델의 표현력에 대해 직접적 영향을 주며 계산이 단순하고 명확한 scaling가 가능하다는 특징이 있다.
둘째는 이 세 가지 특징이 상호 보완적 특성을 가지고 있기 때문이다.
예를 들어 해상도가 큰 이미지를 넣을 때, 깊게 하여 receptive field를 키우는 것이 성능을 높이는 방안이 되고, 필터가 많아야 더 세밀한 특징도 잡아내기 때문이다.
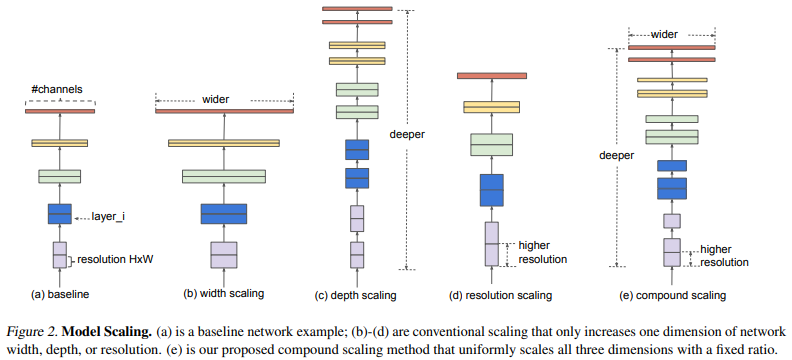 위 그림에서 compound scaling을 보면 세 가지 파라미터에 대해 볼 수 있다.
위 그림에서 compound scaling을 보면 세 가지 파라미터에 대해 볼 수 있다.
depth, width, resolution의 비교
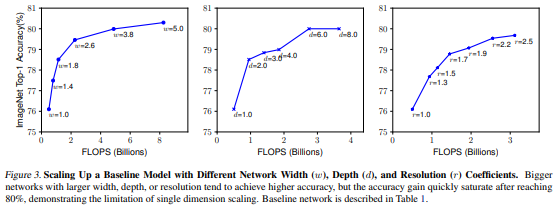 위 그림은 세 특성에 대해 하나만 변화를 주는 것을 나타낸 그림이다.
위 그림은 세 특성에 대해 하나만 변화를 주는 것을 나타낸 그림이다.
차례대로 Width(), Depth(), Resolution()을 의미한다. 여기서 알 수 있는 것은 하나만 키울 시에 saturation이 찾아온다는 한계가 있다는 것이다..!
EfficientNet-B0
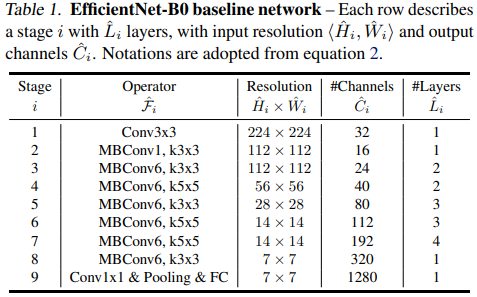 이 논문은 세 특성을 saturation이 찾아오지 않도록 적절히 늘리는 것을 계획한다.
이 논문은 세 특성을 saturation이 찾아오지 않도록 적절히 늘리는 것을 계획한다.
이에 위 그림의 구조를 가지는 EfficientNet-B0에서 NAS 방법을 통해 밸런스를 잡고자 한다!
위 구조를 살펴보자면 다음과 같다.
일단, MBConv6는 Mobile Inverted Bottlenect, expansion ratio =6 이라는 뜻이다. 이 채널은 MobileNet V3의 구조로 SE도 추가한 Bottlenect이다!
그리고 Resolution을 통해 stride=2를 어디서 했는지 볼 수 있고, activation은 전부 SiLU(=Swish)임을 볼 수 있다.
(SE 부분에서만 sigmoid를 사용하였다..!)
그리고 Stochastic Depth 기법을 적용하여 layer를 랜덤하게 스킵하는 방법을 사용하였다.
을 고정하고 의 차이 비교
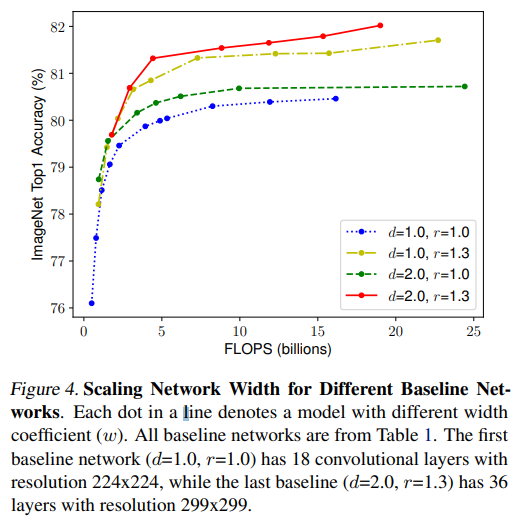 위 그림은 와 을 특정 값으로 고정시킨 상태에서 를 키웠을 때의 그래프이다.
위 그림은 와 을 특정 값으로 고정시킨 상태에서 를 키웠을 때의 그래프이다.
위를 통해 알 수 있는 것은 일단 머든지 키울수록 성능이 좋아진다는 것이다!
그리고 같은 연산량에서 의 밸런스의 차이에 따라 성능이 크게 달라진다는 것이다!
또한, 를 키우는 상황에서 이 크면 클수록 saturation이 더디게 나타난다!
즉, 를 키우는 것은 이 클수록 효과가 더 좋다는 것!
의 밸런스
그렇다면 이 밸런스는 어떻게 맞추면서 키울까?
이 논문에서 채택한 방법은 다음과 같다.
일단, 로 둔 다음, 를 키우는 방법을 사용하였다!
그리고 는 연산량을 기준으로 아래처럼 산정하였다!
- 는 (depth)에 해당하는데, depth를 2배 키우면 연산량은 2배 증가한다!
- 는 (width)에 해당하는데, width를 2배 키우면 입력 채널과 출력 채널 둘 다 2배씩 늘어나기에 연산량은 4배 증가한다!
- 는 (resolution)에 해당하는데, resolution를 2배 키우면 가로 축과 세로 축 둘 다 2배씩 늘어나기에 연산량은 4배 증가한다!
그러므로 를 배만큼 키운다면 연산량은 으로 나오게 되는 것이다!
여기서 만약 라고 가정했을 때,
전체 연산량 = 가 된다.
그리고 라고 가정했기에 연산량은 가 되는 것이다!!
여기서 이면 EfficientNet=B0가 되고, 이면 연산량을 2배 키운 모델로 얻을 수 있는 것이다.
이렇게 다양한 값을 사용하여 논문은 B0 ~ B7까지 다양하게 제안하였다..!
(자세히 들어가보면 구현이 조금은 다르기는 하다..ㅎ)
여기까지 했을 때, 를 정한 상태에서 를 고르는 방법은 다음과 같았다!
일단 로 두고 accuracy를 가장 크게 한 를 선정하였다!
그리고 이 값을 선정하는 방법은 쌩 노가다로 그리드 서치를 하여 찾아내었다...ㅋ
그 결과, 가 선택되었고, 를 에서부터 키워가면서 scale up 시켜주었다!!
B0 ~ B7 전체 성능 표
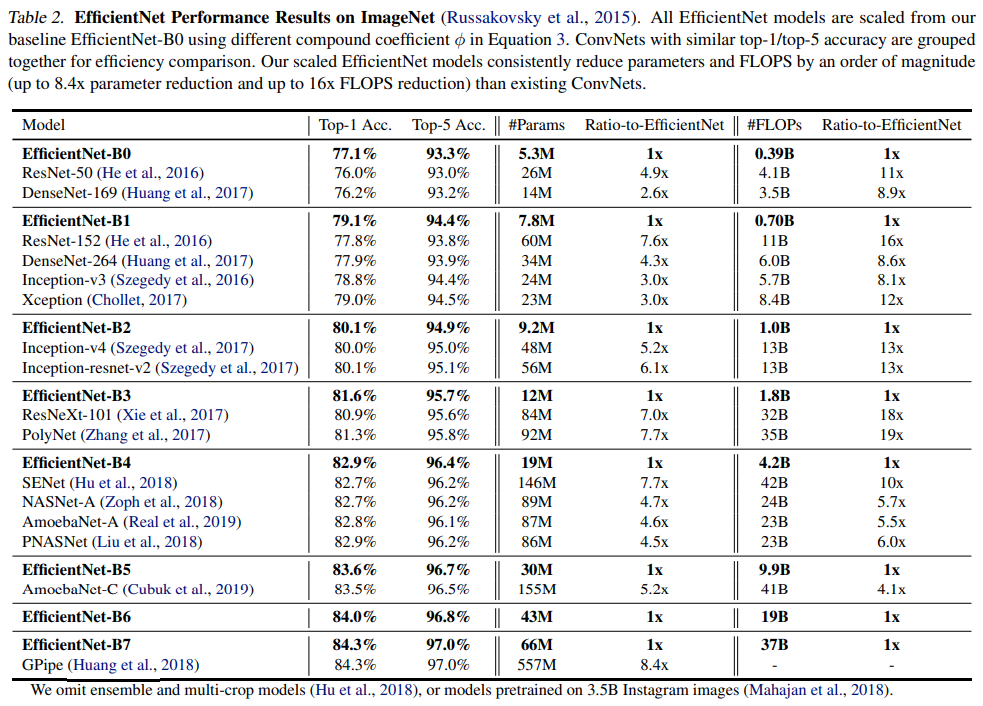 전체 성능표는 다음과 같이 나왔으며, 비슷한 accuracy에 엄청나게 가벼운 파라미터와 연산량의 효율을 보여주었다..!!!
전체 성능표는 다음과 같이 나왔으며, 비슷한 accuracy에 엄청나게 가벼운 파라미터와 연산량의 효율을 보여주었다..!!!
CAM (Class Activation Map) 분석
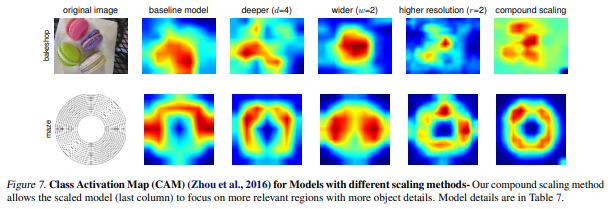 위 그림은 CAM으로 마지막 conv layer의 feature map을 기반으로 중요도 히트맵을 생성한 것이다.
위 그림은 CAM으로 마지막 conv layer의 feature map을 기반으로 중요도 히트맵을 생성한 것이다.
그림을 보면 확실히 compound scaling가 그림의 정확한 포인트를 보고 분류를 하는 것을 볼 수 있다!!
성능 비교
- compound scaling VS 하나만 키우기
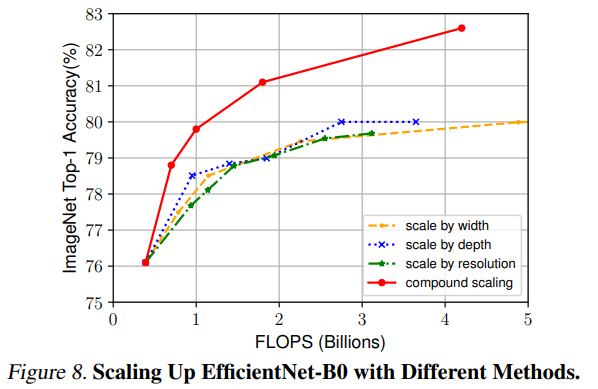 확실히 compound scaling가 성능이 좋았음을 확인할 수 있다!
확실히 compound scaling가 성능이 좋았음을 확인할 수 있다! - 다른 모델과 비교
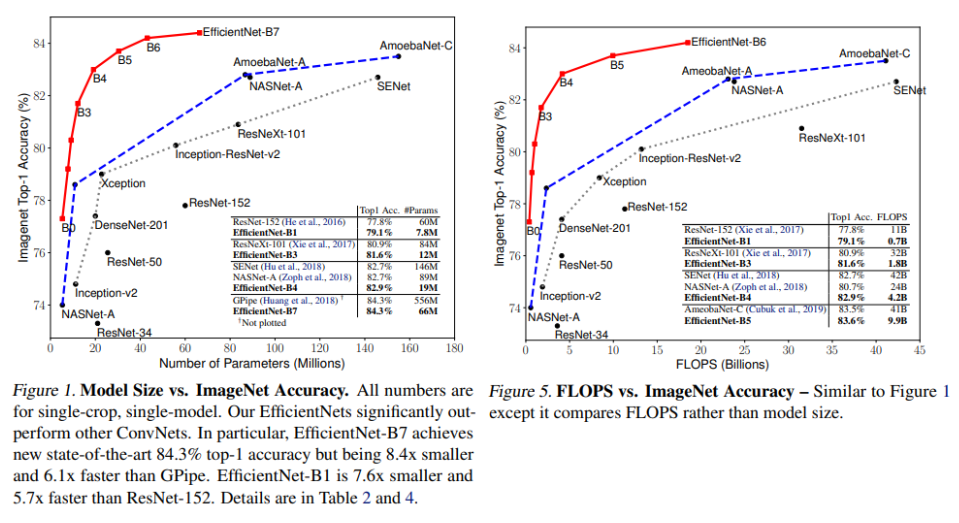 확실하게 타 모델에 비해 적은 파라미터와 연산량으로 큰 accuracy를 달성한 것을 볼 수 있다!!
확실하게 타 모델에 비해 적은 파라미터와 연산량으로 큰 accuracy를 달성한 것을 볼 수 있다!!
EfficientNet이 레전드인 이유
- 높은 Accuracy를 유지하면서 적은 파라미터 & 연산량을 가지기 위해 Depth, Width, Resolution를 효율적으로 키우는 방법을 고안하였다!
- Depth, Width, Resolution를 효율적으로 키우기 위한 (= 밸런스를 맞춰 키우기 위한) 효과적인 방법을 고안하였다!
- 타 모델과 비슷하거나 높은 정확도에 압도적으로 낮은 파라미터 & 연산량을 보여주었다!!
