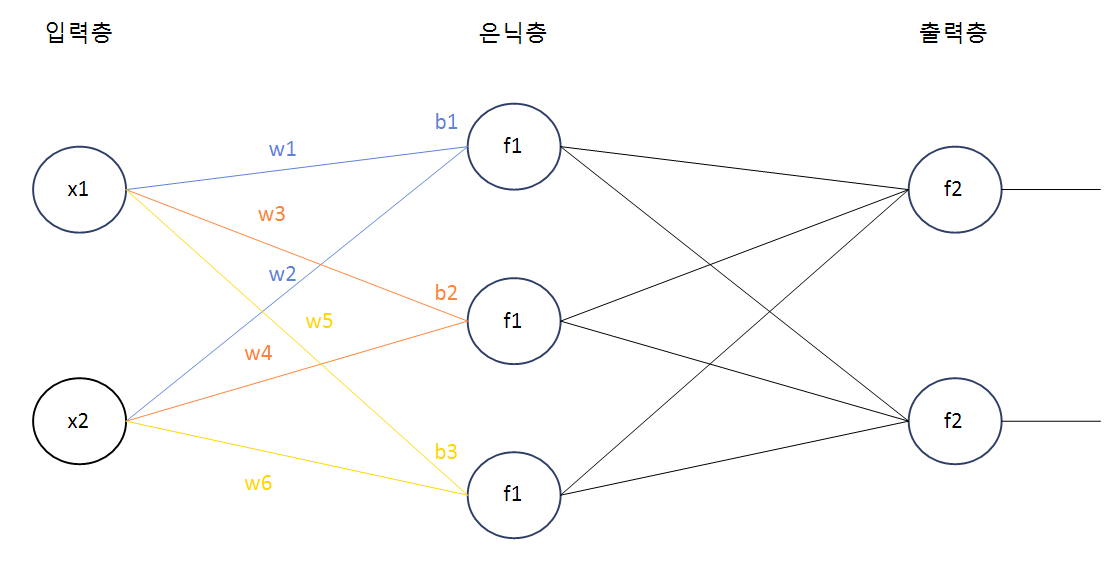
MLP : 다중 퍼셉트론, 입력층과 출력층 사이에 은닉층을 하나 이상 가지고 있는 퍼셉트론.
이를 그림으로 간단히 표현하면 다음과 같다.
위처럼 은닉층이 하나인 경우에 대해 웨이트와 바이어스를 각각 표현하였다.
이 때, f1(activation)에 들어오는 값은 각각 다음과 같다. f1(x1⋅w1+x2⋅w2+b1),f1(x1⋅w3+x2⋅w4+b2),f1(x1⋅w5+x2⋅w6+b3)
근데 이렇게 쓰면 너무 길게 표현해야하므로 이를 벡터와 행렬로 표현하면 다음과 같다! fˉ1([x1x2]⋅[w1w2w3w4w5w6]+[b1b2b3])
이렇게 행렬과 벡터로 표현하였는데, 이를 더 간단하게 하고자 다시 표현하면 다음과 같다.
[x1x2]은 입력층이므로 xˉ로 나타냄.
[w1w2w3w4w5w6]은 첫번째 layer의 웨이트 값이므로 W1으로 표현.
[b1b2b3]은 첫번째 layer의 바이어스 값이므로 bˉ1로 표현.
그러면 fˉ1(xˉW1+bˉ1)으로 간단히 표현 가능하다!!
그리고 이를 출력층까지 표현하면 다음과 같다!!
fˉ2(fˉ1(xˉW1+bˉ1)W2+bˉ2)→fˉ(xˉ) ( MLP에 x를 넣었을 때 나오는 출력값을 의미.)
이것이 곧 출력값이 된다! (여기서 주의할 점은 행렬과 벡터에서 줄였지만 이 나타내는 값들이 몇 by 몇 행렬인지는 알아야 한다!)
결국 MLP는 '행렬' 곱하고 '벡터' 더하고 activation의 반복이라는 것을 알 수 있다!
Non-linear activation이 중요한 이유
위에서 우린 MLP를 행렬과 벡터를 이용해 아주 간결하게 나타내어 보았다.
그렇다면 MLP를 계속 계속 이렇게 은닉층을 이어서 만들어 깊게 깊게 만들면 엄청 복잡한 함수가 만들어 지는 것이라고 유츄할 수 있다..! 과연 그렇게 나올까? →Non-linear activation은 가능하나 linear activation은 그렇지 않다..!
선형 함수(linear activation)은 간단하게 말하자면 '들어가는 대로 나오는 것'이다. (즉, f(x)=x가 성립.)
위의 MLP 설명을 예를 들어 수식으로 나타내면 다음과 같다. xˉ를 사용하면 fˉ(xˉ)=f([x1x2]) 이고, 들어가는 대로 나오기 때문에 [f(x1)f(x2)]가 된다.
그리고 이 값은 즉, [x1x2]로 나오게 된다! 결국, 선형 함수의 경우 f()의 의미가 아예 없어진채로 나온다고 보면 된다.
이를 가지고 위의 예시의 식인 fˉ2(fˉ1(xˉW1+bˉ1)W2+bˉ2)을 f() 을 신경쓰지 않고 전개를 하면 다음이 나온다.
xˉW1W2+bˉ1W2+bˉ2
이제 위의 식을 분석해보자! W1과 W2는 각각 2 X 3, 3 X 2이다. 그러므로 이 둘의 곱은 2 X 2가 나오게 된다. 이 곱을 W라고 정의를 해보자. 무언가 감이 오지 않는가?
전에 우리가 배운 인공신경망 부분에서 웨이트(a)와 바이어스(b)를 구하는 것이 딥러닝의 목표라고 하였고, 이 둘은 머신이 직접 구하는 '파라미터'라고 하였다..!
그런데 a1a2x+b와 ax+b에서 웨이트와 바이어스를 구할 때, 결국 두 식 모두 머신이 웨이트와 바이어스를 구하기에 a1a2이든 a이든 결국 똑같다는 것이다!
(심지어 앞의 경우 머신이 두 개를 구하기에 더 복잡할 수도 있다..)
결국 위의 식의 W1W2는 두 개의 웨이트의 곱이지만 그냥 웨이트(W) 하나 구하는 것이라고 볼 수 있다.
또한, 뒷부분의 bˉ1W2은 1 X 3, 3 X 2여서 1 X 2로 나오고 결국, bˉ1W2+bˉ2도 위의 논리로 보았을 때 그냥 바이어스(b) 하나 구하는 것과 다를 바 없다는 것이다.
결론적으로 말하자면, 선형 함수를 쓰면 fˉ2(fˉ1(xˉW1+bˉ1)W2+bˉ2) = xˉW+b인 것이다!
그리고 선형 함수를 쓴 식 xˉW+b을 그림으로 나타내면 W는 2 X 2, b는 1 X 2 이므로 다음과 같다.
전 그림에선 분명 MLP로 은닉층이 존재하였는데, 위의 그림으로 보니 은식층이 그냥 무시된 것을 확인할 수 있다.
결론을 말하자면 다음과 같다.
linear activation으로는 아무리 깊게 만들어도 hidden layer 없는 FC layer 이하의 표현력만 가진다! → 깊어지는 효과를 전혀 누리지 못하고 그냥 시간 낭비가 된다는 것.
linear activation으로는 입력과 출력 간의 선형적 관계만을 나타낸다. 따라서, Non-linear activation이 중요하다..!
(입력, 출력 간의 비선형적인 관계도 나타낼 수 있고, 깊을수록 복잡한 함수 표현 가능하다.)
물론 머신에서 linear activation을 원하는 경우가 나올 수 있지만, 보통 우리가 쓰는 딥러닝 문제에서는 non-linear activation을 원하는 경우가 대부분이다.
[*] "위에서 hidden layer 없는 FC layer '이하'의 표현력만 가진다."라고 하였는데, 이하가 되는 경우는? 위 그림의 경우는 오히려 그냥 hidden layer 없는 FC layer보다 더 성능이 떨어지는 표현력을 보일 수 있다.
[*] 그렇다면 linear → non-linear → linear → non-linear 이렇게 하면 좀 괜찮지 않을까..?
전혀 아니다. linear의 경우에서 은닉층이 사라진다는 조건은 똑같기 때문에 그냥 non-linear을 두 번 쓰는 것보다 더 표현력이 떨어질 수 있고, 귀찮은 계산만 늘어나게 된다.
Backpropagation (back : 뒤, propagation : 전달)
이제 위처럼 깊은 신경망을 구현하는 방법을 알았으니, 이에 대한 그라디언트를 구하는 방법도 알아야 한다.
그리고 이 방법을 간단히 말하자면 모든 웨이트와 바이어스에 대해 편미분을 진행하여 그라디언트를 만들어주면 된다!
예를 들어 위의 예시였던 그림을 가져오면
이에 대한 웨이트와 바이어스의 개수는 (2 3 + 3) + (3 2 + 2) = 17개가 된다.
그러므로 그라디언트는 17 X 1의 벡터로 나오게 된다..! (전에는 a, b만 있어서 두 개였는데.. 아주 많다..)
이제 웨이트와 바이어스에 대해 하나하나 편미분을 진행해줘야 하는데,
이는 기초 수학에서 배웠던 Chain rule을 이용하면 된다!! (결국 미분이 뒤(back)로 전달(propagation)되므로 backpropagation인 것이다!)
그리고 17개를 하나하나 구하는 것이 귀찮고 복잡하지만, 하나하나 구해보면 규칙성을 발견할 수 있다!
구하기 위해 위의 그림을 다시 조정하면 다음과 같다. 위 그림에 대해 설명하면 다음과 같다.
wa는 해당 layer의 가중치(weight)를 말한다.
da는 해당 layer에서 들어가는 값을 말한다. 예를 들면 d1=w1⋅x1+b1이 된다.
na는 해당 layer에서 나오는 값을 말한다. 예를 들면 n1=f1(d1)이 된다. (n0는 x1을 의미한다.)
ya는 해당 출력값을 말한다. 위에서 보면 y1의 값은 n1과 같다.
그리고 위의 그림에 나오는 신경망의 손실 함수(L)은 MSE를 가지고 정의하여 (y1−y1)2+(y2−y2)2으로 정의하였다.
이제 대표적으로 w1과 w2에 대해서 편미분을 구해 규칙성을 살펴보겠다..!
일단 Chain rule는 뒤에서 연결하여 구하기 때문에 비교적 구하기 쉬운 w2부터 구해보겠다.
∂w2∂L을 뒤에서 뒤로 연결하면 L→n2→d2→w2가 되어 ∂w2∂L=∂n2∂L⋅∂d2∂n2⋅∂w2∂d2가 된다!
이에 대해 하나씩 구해보면 다음과 같다.
∂n2∂L는 (y1−y1)2+(y2−y2)2에서 y1=n2이기에 2(y1−y1)이 나온다.
결국 L→n2→d2→w2가 되어 ∂w2∂L=∂n2∂L⋅∂d2∂n2⋅∂w2∂d2=2(y1−y1)⋅f2′(d2)⋅n1이 나온다!
그 다음으로 w1에 대해 구해보면 다음과 같이 생각할 수 있다.
똑같이 Chain rule로 하니까 ∂w1∂L은 L→n2→d2→n1→d1→w1으로 가서
(w2에 대해 구하는 것이 아니기 때문에 위의 식과 다르게 중간에 w2가 아닌 n1이 들어감.) ∂w2∂L=∂n2∂L⋅∂d2∂n2⋅∂n1∂d2⋅∂d1∂n1⋅∂w1∂d1이 나오겠다고 생각할 수 있다!!
하지만 이는 w1에 대한 답이 될 수 없다. 그 이유는 w1이 바뀌면서 위 신경망의 손실함수에서 위의 경로만 영향을 주면 상관이 없는데, 다른 경로에도 영향을 주기 때문이다! → 결국 편미분을 구하면 그라디언트를 이용해 손실 함수를 업데이트 할텐데 w1이 바뀌었을 때, d1이 바뀌고 이를 통해 n1이 바뀌고 이를 통해 d2가 바뀌고 이를 통해 n2가 바뀌어서 결국 L이 바뀌게 된다. 여기서 우리가 간과한 점은 바로 w1이 바뀔 때, y2의 값도 바뀌어서 이것이 L에 영향을 준다는 것이다!!!
그림으로 보면 다음과 같다. 위는 우리가 w1을 바꾸었을 때, L에 영향을 준다고 생각한 경로이고 위의 결과가 실제 w1이 바뀌었을 때, L에 영향을 주는 경로이다.
그러므로 ∂w2∂L=∂n2∂L⋅∂d2∂n2⋅∂n1∂d2⋅∂d1∂n1⋅∂w1∂d1가 아니라 ∂w2∂L=∂n2∂L⋅∂d2∂n2⋅∂n1∂d2⋅∂d1∂n1⋅∂w1∂d1+⋯가 붙게 된다!!!
위를 통해 편미분을 구할 땐 모든 path를 고려해야 한다는 점을 알 수 있다!
위 사실을 알 수 있지만, 우린 w1과 w2를 구하며 규칙성을 찾을 것이기 때문에 cdots까지 계산하는 것은 생략하겠다...!
∂n2∂L⋅∂d2∂n2⋅∂n1∂d2⋅∂d1∂n1⋅∂w1∂d1 부분만 하나씩 구해보면 다음과 같다.
∂n2∂L은 위에서 구한 것으로 2(y1−y1).
∂d2∂n2도 위에서 구한 것으로 f2′(d2).
∂n1∂d2은 d2=w2⋅n1+⋯인데, 이번엔 n1에 대해 미분해서 w2이다.
∂d1∂n1는 위와 같이 n1=f1(d1)이기에 f1′(d1)이다.
∂w1∂d1은 d1=w1⋅n0+⋯이기에 n0이다!
그러므로 ∂n2∂L⋅∂d2∂n2⋅∂n1∂d2⋅∂d1∂n1⋅∂w1∂d1=2(y1−y1)⋅f2′(d2)⋅w2⋅f1′(d1)⋅n0이 나온다!!
이렇게 w1과 w2를 구하는 방향을 보았다. w1을 보면 ∂w2∂L=∂n2∂L⋅∂d2∂n2⋅∂w2∂d2=2(y1−y1)⋅f2′(d2)⋅n1의 값이 '손실 함수 × 액티베이션(activation) × N값' 인 것이고, ∂n2∂L⋅∂d2∂n2⋅∂n1∂d2⋅∂d1∂n1⋅∂w1∂d1=2(y1−y1)⋅f2′(d2)⋅w2⋅f1′(d1)⋅n0의 값은 '손실 함수 × 액티베이션 × 웨이트 × 액티베이션 × N값' 이 나옴을 알 수 있다.
이에 대해 규칙성이 보이나? w1의 경우 '손 × 액 × 앤' 이고 w2는 '손 × 액 × 웨 × 액 × 앤' 이다!!
결국 파라미터의 편미분 값들은 아래처럼 규칙성을 가짐을 알 수 있다!! (좀 더러워보이긴 하네....)
(손)액웨액웨액웨...액앤 → (손실 함수는 규칙성을 안 따를 수도 있음..!)
그렇다면 layer가 세 개일 때( 은닉층이 2개 ) 가장 입력층에 가까운 웨이트의 값은 '(손)액웨액웨액앤' 으로 나오게 됨을 알 수 있다!
[*] forward propagation : 앞으로 가면서 미분. → 우리가 위 그림에 나오는 모든 변수(d, n)에 대해 그라디언트를 구하면서 일일히 구해갈 수 없다..!
그러므로 training data를 한 번 진행하면서 위의 d와 n값들을 모두 저장해 놓는다! (forward propagation)
그리고 그라디언트를 구할 때 미분 값을 구한다. (backpropagation)
그리고 우리가 아는 GD나 SGD나 Adam 등등...을 써서 업데이트를 해주면 끝!!
[*] 실제로 우리가 깊은 신경망에서 그라디언트를 구할 때 위처럼 일일히 구하지 않고 코드를 통해 쉽게 구하면 된다. 하지만 코드 안에서 어떻게 계산 되는지는 알아야 하기 때문에 배운 것..!
[*] 바이어스도 Chain rule을 이용해 구해보자! →b1과 b2를 구한다면 다음과 같다. b2:L→n2→d2→b2이기에, ∂b2∂L=∂n2∂L⋅∂d2∂n2⋅∂b2∂d2=2(y1−y1)⋅f2′(d2)⋅x 이다.
위에서 x이외의 값은 모두 구했기에 x만 구하면
∂b2∂d2은 w1⋅n1+b2에서 나왔으므로 x는 1이다.
결국 b2는 '손 × 액 × 1' 이 되고, b1도 _손 L→n2→d2→n1→d1→b1이기에 손 × 액 × 웨 × 액 × 1' 임을 알 수 있다. 즉, 바이어스는 앤을 1로 바꾸면 된다!!
행렬 미분을 이용한 backpropagation
우리가 기초 수학 파트에서 행렬 미분하는 것을 배웠고, backpropagation을 행렬을 가지고 미분하면 더 간결하게 나타낼 수 있다!
이번에도 똑같이 위와 같은 예시를 가져오겠다.
그리고 위처럼 구하기 위해 nˉ0,dˉ1,nˉ1,dˉ2,nˉ2를 정의할 것이다. (xˉ는 x 벡터를 의미함.)
nˉ0=xˉ
dˉ1=nˉ0⋅W1+bˉ1 (W1은 wˉ1과 같은 의미.)
nˉ1=fˉ1(dˉ1)
dˉ2=nˉ1⋅W2+bˉ2
nˉ2=fˉ2(dˉ2)
L=(y1−y1)2+(y2−y2)2인데 이는 (nˉ2−yˉ)(nˉ2−yˉ)T와 같다. (nˉ2−yˉ)(nˉ2−yˉ)T를 전개하면 ([y1y2]−[y1y2])⋅([y1y2]−[y1y2])=[y1−y1y2−y2]⋅[y1−y1y2−y2]이므로 이 값은 (y1−y1)2+(y2−y2)2가 나오게 된다.
W1,W2의 경우에는 행렬로 나오는데, dˉa 구하는 과정에서 다른 모든 변수가 벡터이므로 벡터라이징을 해서 Letw1=vec(W1),w2=vec(W2)로 정의하겠다.
이렇게 우리가 그라디언트를 구하기 위한 준비는 끝났다.
일단 L에 대한 w2의 편미분부터 구해보면 다음과 같다. (벡터의 연쇄법칙은 앞으로 앞으로!) ∂w2T∂L=∂w2T∂dˉ2⋅∂dˉ2T∂nˉ2⋅∂nˉ2T∂L가 나온다.
그리고 L에 대한 w1의 편미분은 다음과 같다. (벡터의 연쇄법칙은 앞으로 앞으로!) ∂w1T∂L=∂w2T∂dˉ1⋅∂dˉ1T∂nˉ1⋅∂nˉ1T∂dˉ2⋅∂dˉ2T∂nˉ2⋅∂nˉ2T∂L가 나온다.
여기서 중요한 점은 위 두 미분의 path들은 이미 고려된 값들이라는 것이다!
일단 w2에 대한 미분의 식 ∂w2T∂L=∂w2T∂dˉ2⋅∂dˉ2T∂nˉ2⋅∂nˉ2T∂L을 계산하면 다음과 같다.
∂nˉ2T∂L : dL을 먼저 구하고 여기에 대한 dnˉ2의 뒤에 곱해진 값이 그라디언트 값이 된다! dL : 행렬과 벡터에 대한 미분도 우리가 아는 미분 법칙을 쓸 수 있기 때문에 (nˉ2−yˉ)(nˉ2−yˉ)T를 '앞에꺼 미분 + 뒤에꺼 미분'으로 보면 dnˉ2⋅(nˉ2−yˉ)T+(nˉ2−yˉ)⋅dnˉ2T이 된다.
그리고 이 값은 행벡터 ⋅ 열벡터 + 행벡터 ⋅ 열벡터 이므로 스칼라 값이 나온다. 그렇기 때문에 Transpose해도 같이 똑같으므로 dnˉ2⋅(nˉ2−yˉ)T+((nˉ2−yˉ)⋅dnˉ2T)T이 가능하고, 결국 dL=dnˉ2⋅2(nˉ2−yˉ)T가 된다! 그리고 그라디언트 값은 dnˉ2 뒤의 값 2(nˉ2−yˉ)T이다.
∂dˉ2T∂nˉ2 : 이 값은 풀어서 해석하면 이해하기 쉽다!
이 식은 분자는 가로로 분모는 세로로 벡터가 쌓여있기 때문에 다음과 같다. [∂d21∂n21∂d21∂n22∂d22∂n21∂d22∂n22]
그런데 위 그림에서 보면 d21과 n22은 어느 하나의 값이 바뀌었을 때, 서로에게 영향을 주지 않는다.
(d22와 n21도 마찬가지.)
그러므로 ∂d22∂n21,∂d21∂n22의 값인 해당 그라디언트는 0이 된다.
그리고 ∂d21∂n21와 ∂d22∂n22의 경우 위에서 했던 것처럼 fˉ2′(dˉ2)가 나오게 된다!
위의 결과를 총 정리하면 다음과 같다. [f21′(d21)00f22′(d22)]=diag(fˉ2′(dˉ2)) (diag는 대각 행렬을 의미한다.)
∂w2T∂dˉ2 : 이 값을 구하기 위해선 행렬을 행렬로 미분에서 배웠던 지식을 활용해야 한다. 위처럼 ∂w2T∂dˉ2은 dˉ2=nˉ1⋅W2+bˉ2에서 나오는 값이므로 nˉ1T⊗I가 된다!
이렇게 구한 값들을 모두 곱하면 ∂w2T∂L=(nˉ1T⊗I)⋅diag(fˉ2′(dˉ2))⋅2(nˉ2−yˉ)T가 나온다!
다음으로 w1에 대해 구해보면 다음과 같다. ∂w1T∂L=∂w2T∂dˉ1⋅∂dˉ1T∂nˉ1⋅∂nˉ1T∂dˉ2⋅∂dˉ2T∂nˉ2⋅∂nˉ2T∂L
이를 하나씩 뜯어보겠다.
∂nˉ2T∂L : 위와 똑같이 2(nˉ2−yˉ)T가 나온다.
∂dˉ2T∂nˉ2 : 위와 똑같이 diag(fˉ2′(dˉ2))가 나온다.
∂nˉ1T∂dˉ2 : nˉ1⋅W2+bˉ2에서 d⋅d2=dnˉ1⋅W2가 되고, dnˉ1 뒤에 곱해진 W2가 해당 값이 된다.
∂dˉ1T∂nˉ1 : 위를 응용하면 diag(fˉ1′(dˉ1))가 나온다.
∂w2T∂dˉ1 : 위를 응용하면 nˉ0T⊗I가 나온다.
총 정리하면 ∂w1T∂L=(nˉ0T⊗I)⋅diag(fˉ1′(dˉ1))⋅W2⋅diag(fˉ2′(dˉ2))⋅2(nˉ2−yˉ)T가 나오게 된다!!
이를 통해 규칙을 살펴보면, 순서는 반대로 구하게 되지만 '액웨액웨액웨...액앤!'인 것을 알 수 있다!
이처럼 벡터를 가지고 backpropagation을 하게 되면 스칼라를 할 때 다른 경우의 수를 고려해서 더하는 과정을 생각하지 않아도 모든 path에 대해 나타낼 수 있다! → 그러므로 더 간결하다고 볼 수 있다.
[*] 스칼라를 행렬로 미분하는 backpropagation
우리는 위에서 W1,W2를 vectorize해서 풀었다! 그리고 이것은 사실 굳이 따지자면 야매...? 느낌이 강한데.. 벡터라이징 안하고 행렬 그대로 풀 수는 없을까? →∂w1T∂L가 아니라 ∂W1∂L을 구해보자는 것!
일단, 우리가 위에서 구한 식을 가져오면 다음과 같다.
여기서 (nˉ0T⊗I)을 제외한 나머지 diag(fˉ1′(dˉ1))⋅W2⋅diag(fˉ2′(dˉ2))⋅2(nˉ2−yˉ)T를 vˉT로 치환해보겠다. 그러면 ∂w1T∂L=(nˉ0T⊗I)⋅vˉT가 나오게 될 것이다.
그리고 (nˉ0T⊗I)⋅vˉT을 실제로 전개를 해보겠다. 이 그림을 보았을 때, nˉ0는 x1,x2 이렇게 두 개 나오고, vˉT는 3 X 1의 벡터가 나오게 된다.
그러므로 전개하면 다음과 같게 표현 된다. ⎣⎢⎢⎢⎢⎢⎢⎢⎡x100x2000x100x2000x100x2⎦⎥⎥⎥⎥⎥⎥⎥⎤⋅⎣⎢⎡v1v2v3⎦⎥⎤ (vˉT에 맞춰서 nˉ0⊗I가 확장되어 3 X 6 행렬이 나온다.)
그리고 위를 계산하면 ⎣⎢⎢⎢⎢⎢⎢⎢⎡x1v1x1v2x1v3x2v1x2v2x2v3⎦⎥⎥⎥⎥⎥⎥⎥⎤가 나오고, 이를 shape 맞춰주면 [x1v1x2v1x1v2x2v2x1v3x2v3]가 된다!
결국 ∂W1∂L=[x1v1x2v1x1v2x2v2x1v3x2v3]인 것이다.
여기서 더 나아가 보면, [x1v1x2v1x1v2x2v2x1v3x2v3]=[x1x2]⋅[v1v2v3]이고, 이는 nˉ0Tvˉ가 된다!!
결국 ∂w1T∂L=(nˉ0T⊗I)⋅vˉT에서 vec−1(벡터라이징 풀기)을 하면 ∂W1∂L=nˉ0Tvˉ가 되는 것이다.
여기서 vˉT로 치환한 것을 풀면 최종적으로 다음과 같다.
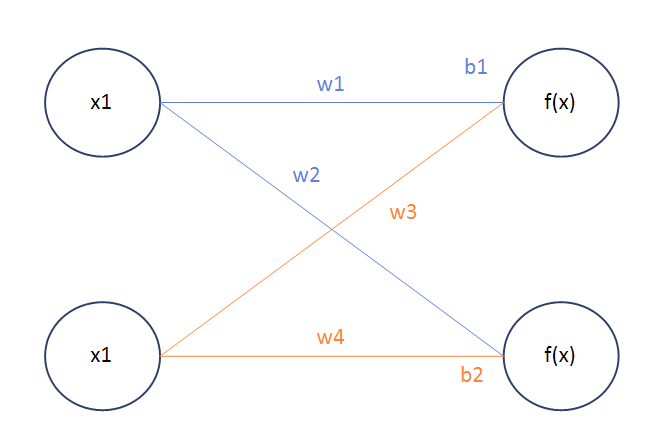 전 그림에선 분명 MLP로 은닉층이 존재하였는데, 위의 그림으로 보니 은식층이 그냥 무시된 것을 확인할 수 있다.
전 그림에선 분명 MLP로 은닉층이 존재하였는데, 위의 그림으로 보니 은식층이 그냥 무시된 것을 확인할 수 있다.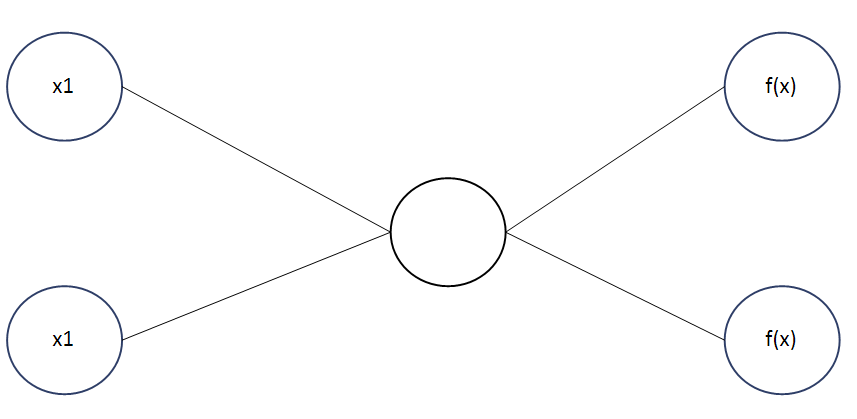 위 그림의 경우는 오히려 그냥 hidden layer 없는 FC layer보다 더 성능이 떨어지는 표현력을 보일 수 있다.
위 그림의 경우는 오히려 그냥 hidden layer 없는 FC layer보다 더 성능이 떨어지는 표현력을 보일 수 있다.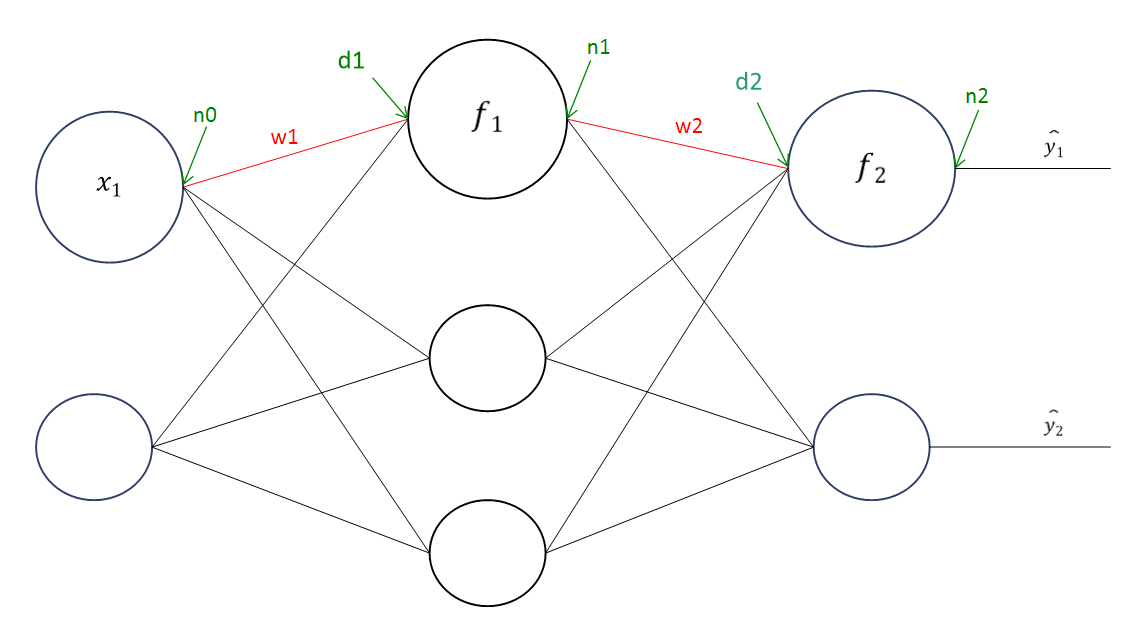 위 그림에 대해 설명하면 다음과 같다.
위 그림에 대해 설명하면 다음과 같다.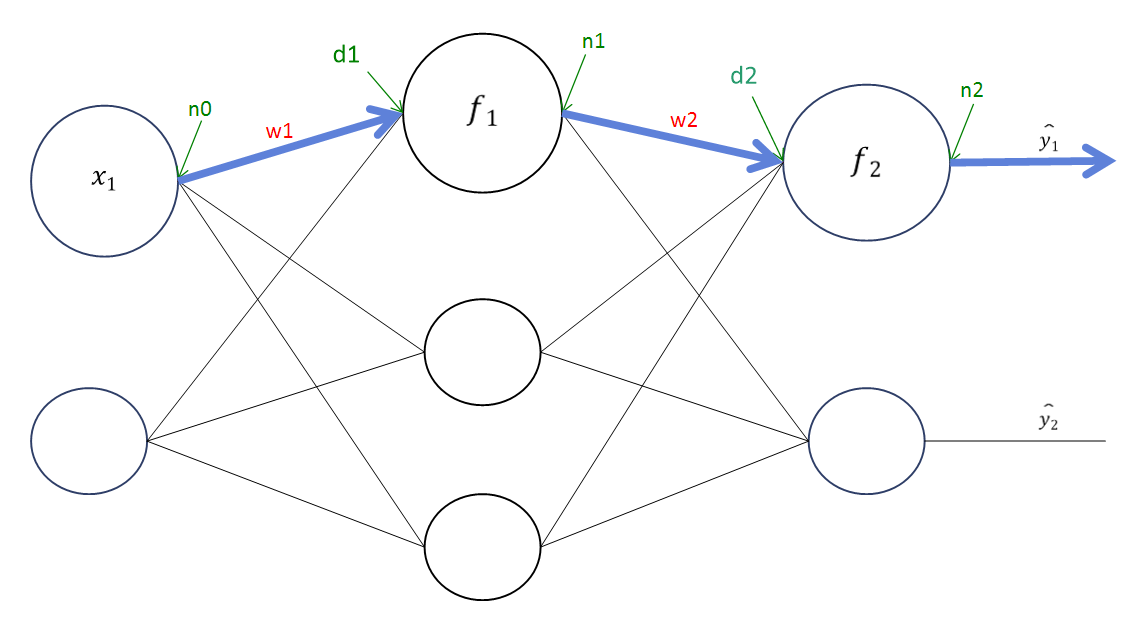 위는 우리가 을 바꾸었을 때, 에 영향을 준다고 생각한 경로이고
위는 우리가 을 바꾸었을 때, 에 영향을 준다고 생각한 경로이고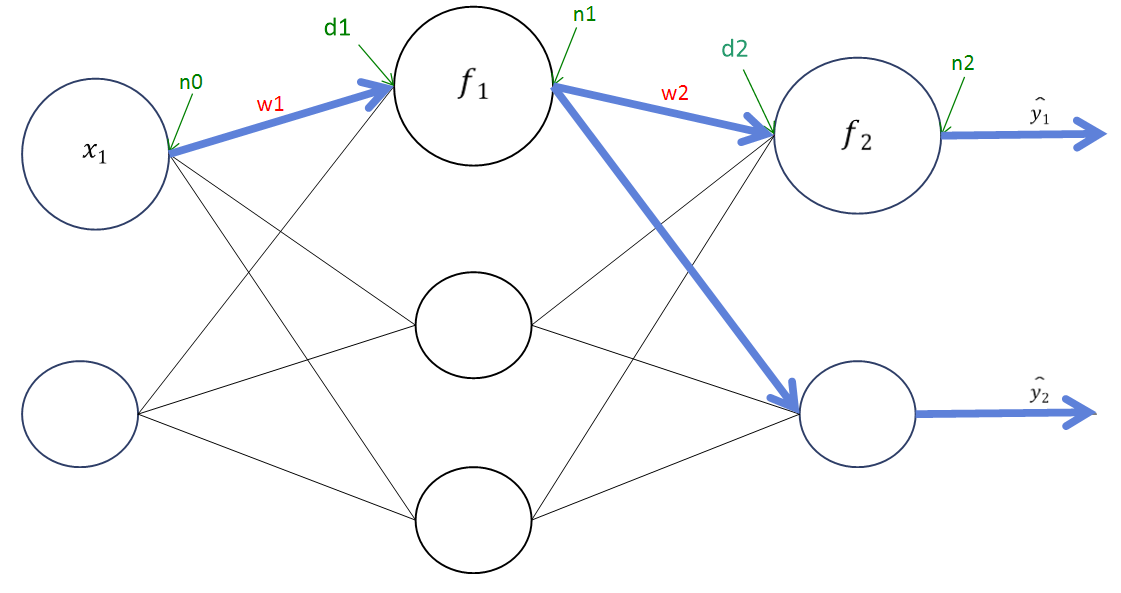 위의 결과가 실제 이 바뀌었을 때, 에 영향을 주는 경로이다.
위의 결과가 실제 이 바뀌었을 때, 에 영향을 주는 경로이다.
 위처럼 은 에서 나오는 값이므로 가 된다!
위처럼 은 에서 나오는 값이므로 가 된다!