목표
인공신경망에 대해 step by step으로 배워보자!
이 내용은 혁펜하임님의 'AI DEEP DIVE'를 바탕으로 구성함.
AI VS ML VS DL
AI vs ML vs DL
AI : 인간의 지능을 모방하는 것
ML : 이를 데이터를 이용하면 ML!
DL : 이를 DNN(딥 뉴럴 네트워크)를 이용하면 DL!
보통 AI 안에 ML이 있고 그 안에 DL이 있다.
AI에만 속하는 것은 규칙 기반 알고리즘이 있다.
(내가 데이터를 공부해서 규칙을 찾고, 이를 대입해 푸는 것.)
DL에는 결정 트리, 선형 회귀, 퍼셉트론 ,SVM(Support Vector Machine)가 있다.
(머신 러닝은 데이터를 주고 규칙을 찾게 하고, 이를 가지고 문제를 풀게 한다.)
DL에는 CNN, RNN, GAN이 있다.
(딥러닝은 아주 기이이이이이이이픈 인공 신경망으로 학습하는 것을 의미한다!)
CNN, RNN, GAN
이들은 용도에 따라서 유형이 달라진다.
CNN : Convolutional Neural Network라고 하며, 주로 이미지 인식 및 패턴 인식에 쓴다.
입력값으로 사진(RGB에 대한 행렬)을 주면 이를 보고 출력값으로 1 or 0을 준다.
*앞으로 2x3x5x5 같은 경우 '개채행열'이라고 부르겠다! 이는 2개, 3채(색깔), 5행, 5열을 의미한다.
RNN : Recurrent Neural Network라고 하며, 주로 연속적인 데이터(시퀀스 형태의 데이터), 문장, 시계열 데이터에 쓴다.
입력값으로 연속적 데이터를 주면 출력값도 연속적 데이터로 준다.
ex) 번역 : 나는 대웅 -> I am DaeWoong
이를 이진수로 바꾸고 이진수로 출력하는 형태이다.
GAN : Generative Adversarial Network라고 하며, 생성적 적대 신경망을 의미한다.
이는 생성자 G(Generator)와 판별자 D(Discriminator)로 이루어지며, 이 둘이 대립해 경쟁적으로 학습하며 실제와 구분이 어려운 가짜 데이터를 만드는데 사용한다.
D같은 경우에 CNN와 같이 이미지 파일을 주었을 때, 출력값으로 1 or 0을 준다. D는 실제 데이터와 가짜 데이터를 구분하는 역할을 한다.
G는 임의의 데이터를 받아 실제 데이터와 비슷한 가짜 데이터를 만드는 역할이다.
이 둘은 서로 번갈아가며 학습하여 결과적으로 두 신경망이 균형을 찾을 때까지 반복한다.
이를 통해 D는 진짜도 0.5, 가짜도 0.5를 출력하며 구분을 아예 할 수 없을 정도로 학습을 한다.
GAN은 딥페이크, 스타일 변환, 이미지 변환, 그림 그리기, 음악 생성 등 간단한 소스 파일을 주고 이를 발전시키는 영역에 쓰인다.
딥 러닝의 분류 / 지도 학습과 비지도 학습
학습에는 지도 학습, 비지도 학습, 자기지도 학습, 강화 학습이 있다. (이 노트는 지도 학습과 비지도 학습만 정리.)
-
지도 학습
내가 선생님이고 기계를 학습 하는 것 -> 내가 정답을(label)을 알고 있어야 한다!
내가 정답을 많이 가지고 있어야 더 정확해진다.
ex) 회귀 (regression), 분류(classification)
이 수업의 중심 내용이 지도 학습이다! -
비지도 학습
반대로, 정답을 모른다.
ex) 군집화 (K-means, DBSCAN, ...), 차원 축소 (데이터 전처리 : PCA, SVD, ...), GAN (딱 정확히 비지도 학습이라기엔 애매하지만....!)
자기지도 학습
지도 학습의 문제 : 데이터는 많을수록 정교하고 무조건 좋은데, 정답을 표현하는 데이터(정답을 알고 있는 데이터)가 너무 적다. -> 정답 만드는 비용이 상당해서 (이 문제 상황은 준지도 학습과 동일)
자기지도 학습 : 진짜 풀려고 했던 문제 말고 다른 문제를 새롭게 정의해서 먼저 풀어보는 것!
데이터 안에서 self로 정답(label)을 만듦.
(새롭게 정의한 문제에 대한 정답)
(그래서 이름이 자기지도 학습)
자기지도 학습의 과정.
1. pretext task(다른 문제) 학습으로 pre-training(다른 문제에 대한 출력값)
2. downstream task(분류, 본 문제)를 풀기 위해 transfer learning(pre-trained model을 본 문제 상황에 맞게 바꾸어줌.) 함. ->지도학습 과정.
ex) 고양이, 강아지를 구분하는 문제에서 고양이 사진의 픽셀을 나누고 두 픽셀을 골랐을 때, 어떠한 출력값(관계성에 관한)이 나오게 하는 문제로 바꾸는 것.
-> transfer learning로 위의 문제의 출력값을 내는 모델을 고양이 사진을 넣었을 때, 고양이인지 아닌지 판단하는 모델로 약간의 변화를 줌.
강화학습
강아지에게 '손'이라는 훈련을 시키는 것과 비슷하다!
강화학습에는 Agent, Reward, Enviroment, Action이 있다.
각각 대입을 시키면 다음과 같다.
Agent : 강아지
Reward : 간식
Enviroment : 보호자
Action : 손
결국 강화학습은 Agent가 Reward를 maxiumize할 수 있는 방향으로 Enviroment을 상대로 Action을 한다고 할 수 있다.
다른 예시로 오목을 통해 흑돌이 이기도록 강화학습 하는 것이 있다.
그러면 각각 대입은 다음과 같다.
Agent : 흑돌
Reward : 승리
Enviroment : 흰돌
Action : 수
그리고 다음도 대입이 된다.
State : 바둑판 (현재 주어진 상황을 의미.)
Q-function : Q(s_t, a_t)
-> 내가 한 Action에 대한 각각의 평가값. Reward에 향한 방향이면 Reward의 값을 가진다.
Q-learning : Q-function의 값이 높은 방향으로 학습하는 것.
Episode : 내가 한 판수(실행 횟수)
위에 대해 설명하면, 흑돌(Agent)가 이기는 모델을 만들기 위해 흰돌(Enviroment)에 대항해 수(Action)를 놓아 결국 승리(Reward)를 얻고자 한다. 이를 강화학습으로 한 수(Action)마다 바둑판 상황(State)을 보고 가장 이길 확률이 높은 방향(Q-function)으로 가도록 한다. 이러한 학습(Q-learning)을 하는 판수(Episode)를 아주 반복해 최적의 결과를 낸다.
하지만, 이 학습에는 중요한 문제가 빠져있는데, 만약 오목을 하는 와중에 이길 수 있는 상황이 생겼지만, 이를 놓치고 '우연히' 다른 방법으로 돌아돌아 이겼다고 하면..!
-> 강화학습은 이렇게 돌아돌아 이기는 방법에 대해 최적화가 되어 결국 더 쉽게 이기는 방법을 못 찾고 이기는 확률 자체가 낮아지게 될 것이다!
이에 대한 해결법으로 Exploration이 있다.
Exploration은 다른 해결책을 찾도록 탐험시키는 것을 의미한다. 대표적으로 ε-Greedy(입실론 그리디) 방법이 있다.
ε-Greedy : ε(입실론)은 상수를 의미한다. 예를 들어 ε으로 0.1을 대입하면, 0.1의 확률로 다른 길(무작위로 골라)을 찾고, 나머지 0.9의 확률은 Q-function을 따라라! 라는 의미가 된다.
위의 예시에서 ε-Greedy을 사용하면 오목을 하는 와중에 돌아돌아 이기는 방법 외에 쉽게 이길 수 있던 방법도 알게 된다..!
-> 하지만 둘 중 무엇이 더 좋은 것이 모델이 모른다..! 이를 위해 discount factor을 사용한다.
discount factor : Greedy한 길을 찾아갈 때, 한 번 길을 거칠 때마다 해당 길목의 Q-function(Reward를 향하는 값)의 값을 γ(감마)값만큼 곱해준다.
이를 예시에 적용하면 다음과 같다.
γ(감마)값이 0.9라고 했을 때, 돌고 돌아 이기는 방법은 Q-function값을 쉽게 이기는 방법보다 더 많이 가지게 될 것이다. 돌고 돌아 가는 경우에 Q-function을 100번 마주치고, 쉽게 이기는 것은 10번이라고 하면 (0.9)^100 < (0.9)^10 이므로 쉽게 이기는 것이 좋은 방법이라는 것을 알게 될 것이다!!
인공신경망, weight와 bias의 직관적 이해, 인공 신경망은 함수이다!
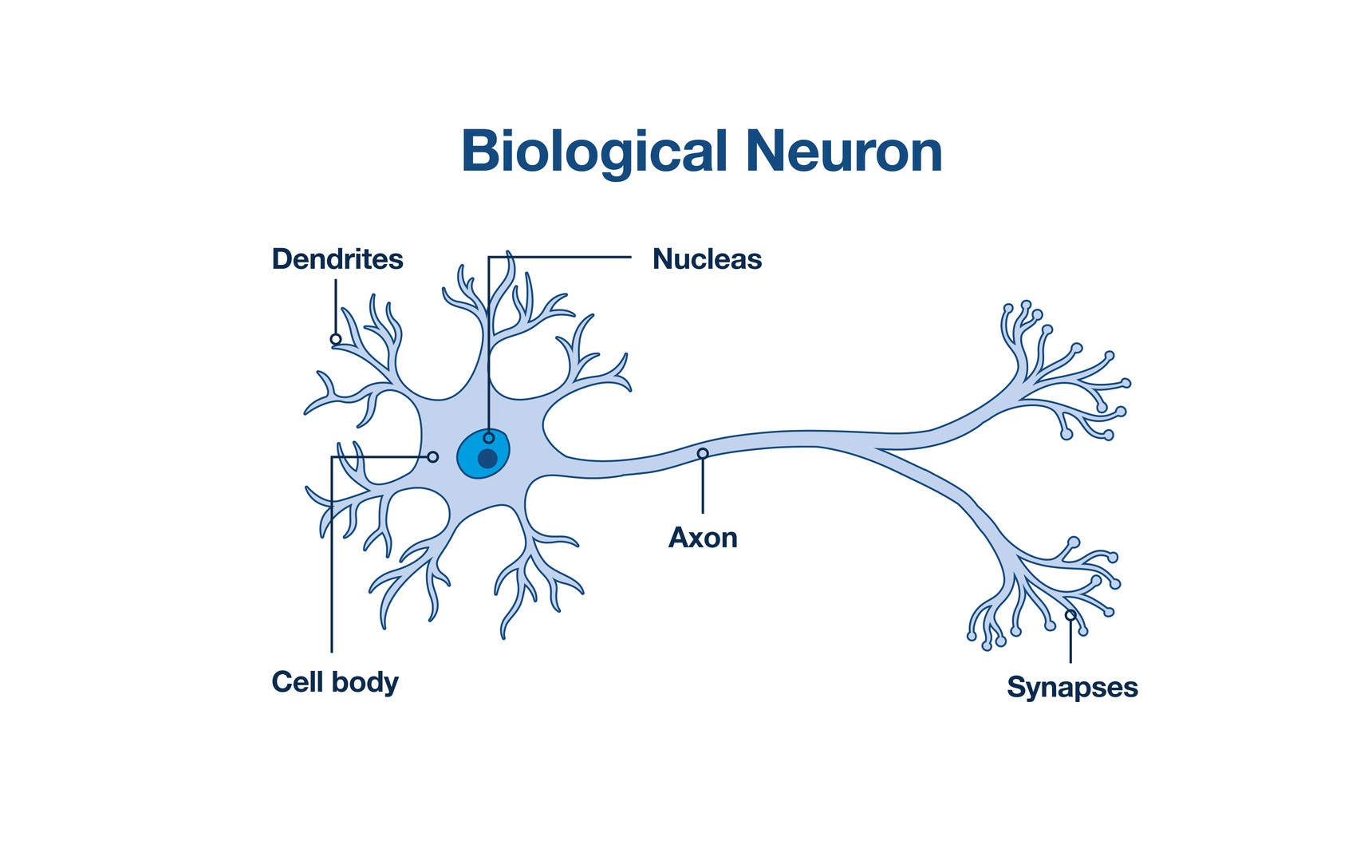
1. 신경
나는 생명과학을 안 배워서 잘 모르지만 신경에 대해 한 줄로 정의하면 다음과 같다.
자극을 전달 받고 / 전달할지 말지 정하고 / 전달하는 역할!
신경망은 위의 역할을 그대로 따른다!!
자극을 전달 받고 -> 노드의 입력값(0 or 1)을 받고 엣지를 통해 전달
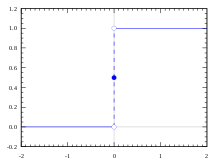
전달할지 말지 정하고 -> 활성화 함수(activation)에 '입력값 x weight + bias' 를 가지고 정해진 조건에 따라 출력값(0 or 1)을 정함.
[*] 여기서 activation은 unit step function을 말하고 있고, 다른 여러가지 활성화 함수도 존재한다!
전달하는 -> 다시 엣지를 통해 출력하는 노드에 출력값(0 or 1)을 전달
여기서 weight는 '중요도'로 입력값에 곱해지고, bias는 '민감도'로 총입력값에 bias를 더해 활성화 함수에 들어가는 값을 정한다!!
즉, 주어진 입력에 대해 원하는 출력이 나오도록 웨이트와 바이어스를 정해주는 것이 중요하다!
근데 AI가 '스스로' 적합한 웨이트와 바이어스를 정한다는게 대박인 점이다!
2. 인공 신경망
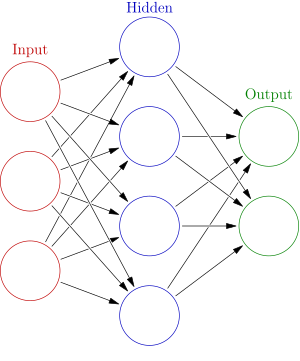
위의 그림처럼 신경들을 여러 차례로 이어주면 그게 바로 신경망!
이 때, 입력값은 가장 왼쪽(입력을 받는 노드)에만 받고 그 이외는 활성화 함수로 이루어져있다.
-> 이는 '웨이트 곱하고 바이어스 더하고 activation 판별하고'의 반복이다!
weight의 개수 : 한 층의 노드들의 곱
bias의 개수 : 총 노드의 합
그리고 위에서 입력값을 받는 곳이 input layer(입력층)
마지막 출력값에 앞 뒤로 엣지가 이어진 것까지 output layor(출력층)이다.
그리고 이 이외의 것들은 hidden layer(은닉층)이다.
깊은 인공 신경망 (DNN)-> 은닉층이 개많음!
그리고 노드끼리 싹 다 연결한 층(한 층의 모든 노드가 연결된 층)은 FC(fully - connected) layer이라 부른다.
그리고 모든 layer가 FC layer인 신경망을 multilayer perceptron (MLP)라고 부른다.
3. 인공 신경망은 ㅎㅅ다!!
위의 답은 '함수'! 인공 신경망도 함수이고, 깊은 인공 신경망은 합성함수가 개많이 이어진 것으로 볼 수 있음!
-> 인공신경망은 '입력과 출력을 연결시켜 주는 연결 고리' 인 것이고,
결국, 주어진 입력에 대해 원하는 출력이 나오도록 하는 함수를 알아내자는 것!
(즉, 웨이트와 바이어스를 알아내는 것이 바로 딥러닝의 목표이다!!)
선형 회귀(지도 학습에 속함.)
선형 회귀 : 입력과 출력 간의 관계(= 함수)를 '선형'으로 놓고 추청하는 것
-> 처음 보는 입력에 대해서도 적절한 출력을 얻기 위함.
ex) 키와 몸무게의 관계(=함수!)를 ax+b로 두고 a, b를 잘 추정해서 처음보는 키에 대해서도 적절한 몸무게를 출력하는 머신을 만들어보자!
위 상황에서 우리가 알아내야 하는 것은 '최적의' 웨이트(a), 바이어스(b)!
이를 '데이터'에 기반하여 알아내야 한다!
그렇다면 최적의 a, b는 어떻게 정하는가?
이는 내가 고른 a, b가 좋은지 나쁜지를 판단 가능해야 한다.
-> loss (=cost)를 최소화하는 a, b가 최적의 a, b!
loss라는 것은 내가 풀고 싶은 문제에 맞게 잘 정의하는 것! (무엇을 줄이면 좋을까?)
ex) 위 예시에서는 머신이 예측한 y값과 실제 데이터의 y값의 차이의 제곱이 loss함수가 될 수 있다!
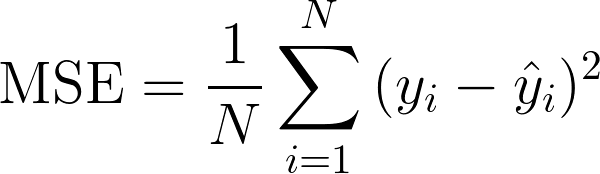
(이 loss 함수를 MSE(Mean Squared Error)라고 부른다.)
[*] 왜 절대값이 아니라 제곱값을 쓸까?
-> 제곱값이 차이에 대해 더 민감하게 반응한다.
Loss를 최소화하는 a, b를 어떻게 찾을까?
-> a, b를 일일히 바꿔가며 생기는 Loss값 변화를 그래프로 그리면, 여기서 최소가 되는 부분의 a, b를 찾을 수 있다.
*그래프의 최솟값이 0은 될 수 없는 이유?
->그래프는 차이의 제곱값인데, 차이가 아예 0이 되는 경우는 실제로 일어나지 않기 때문에 그래프의 최솟값은 무조건 0 이상이라고 생각한다.
그러나, 웨이트와 바이어스 수백 수천개인데 이를 일일히 다 따져가며 언제 봄..? 더 스마트한 방법은 없나?
-> 경사 하강법이 있다!
gradient descent(경사 하강법)
경사 하강법 : 일단 처음 a, b는 아무렇게나 정한 다음, 현재 a, b 위치에서 L을 줄이는 방향으로 나아가자! (현재에 최선을 다하자)
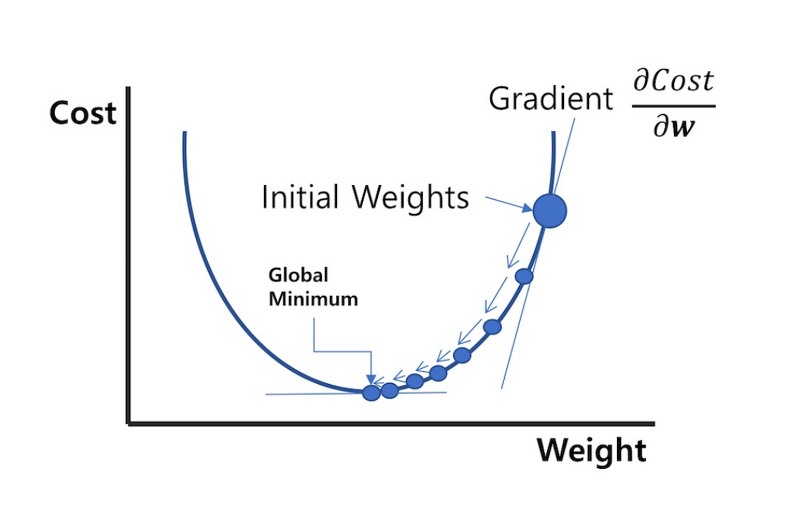
gradient는 항상 가장 가파른 방향(L값을 가장 크게 하는 방향)을 향한다!
그러므로 현재 방향에서 그라디언트를 빼주면 된다!
그렇게 하면 loss의 최솟값(Global Minimum)에 조금 더 가까운 위치로 가게 된다. (이것을 계속 반복!)
(''는 L값을 가장 작게 하는 방향을 향하기 때문에 L의 최솟값 방향을 향한다.
그러므로 현재 방향에서 를 빼주면 다음 최솟값에 가까운 위치가 된다.)
Learning rate (보폭)의 존재 이유?
-> 생각보다 그라디언트가 커서 반복을 계속하면 최솟값쪽으로 수렴되는 것이 아닌, 무의미한 값의 반복이 일어날 수 있기 때문!
ex) 에서 그리고 처럼
양쪽으로 왔다갔다만 할 수 있음!
그러므로 α (보통 1보다 작음. 그래야 수렴하니까..!) 를 그라디언트에 곱해준다!
α 를 상수로 둘 수도 있고, 스케쥴링(반복 횟수에 따라 α 값을 조율해주는 것.)도 가능하다!
Initial weight? (초기 값은 어떻게 정할까?)
-> 너무 멀리 잡으면 한세월 걸리기 때문에 처음을 잘 잡는 것도 중요!
경사 하강법의 단점
1. 너무 신중하게 방향을 선택한다.. (너무 느리게 감) -> 모든 데이터를 다 고려한 방향이기에..!
2. local minimum에 빠질 수 있다.
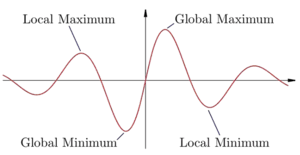
-> local minimum은 함수에서 극솟값(그냥 주변에 비교했을 때 제일 낮은 값)을 나타낸다.
여기서 경사하강법을 진행했을 때, 주변 반경에서 제일 낮은 값으로 가기 때문에 local minimum으로 향하게 된다.
하지만 우리는 global minimum을 찾아야 하기 때문에.. 초기값이 잘못 잡혀있을 경우, 잘못된 길(극솟값의 함정)로 빠질 수 있다.
가중치 초기화 기법 정리
Initial weight를 한 줄로 요약하면!
-> 아무데나 잡는데, 0 근처로 잡아라!
1. LeCun
or
-> w를 다음 유니폼에 따르게 잡던가 다음 정규 분포에 따르게 잡아라!
"그리고 위의 결과에서 둘이 평균은 0, 분산도 똑같다!!"
[*] 유니폼? -> 주사위 확률처럼 일정한 확률의 막대기
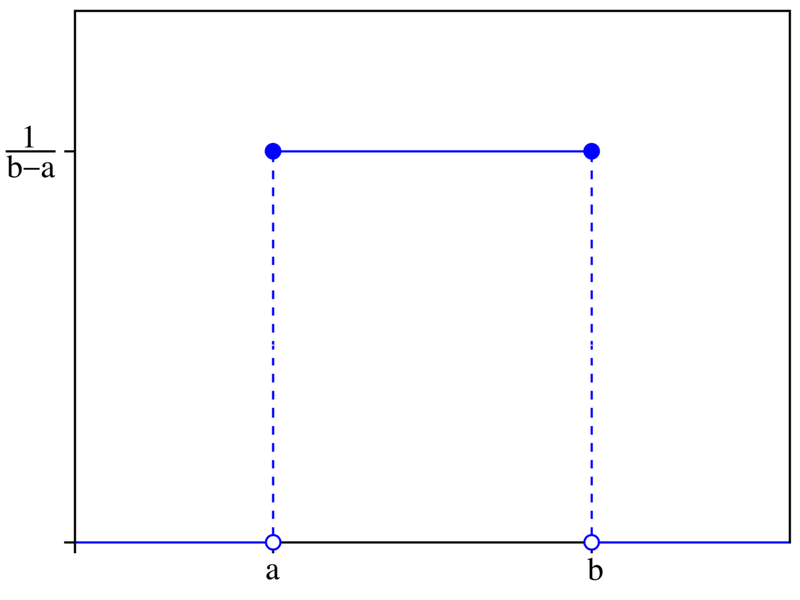
[*] 은? -> 한 layer (입력 노드, 엣지, 출력 노드)에서 입력 노드의 개수를 말한다.
은 출력 노드의 개수를 말함!!
2. Xavier (sigmoid / tanh 사용하는 신경망)
or
-> 이것도 위 둘이 평균, 분산 똑같다.
3. He (ReLU 사용하는 신경망)
or
-> 이것도 위 둘이 평균, 분산 똑같다.
(요즘엔 He ('허'라고 읽음.)를 많이 쓴다고..!)
[Q] w(웨이트, 바이어스 포함)를 걍 0으로 잡거나 1로 잡으면 안됨? 왜 무작위로 함??
(-> 이는 backpropagation 강의를 보고나서 알 수 있음.)
내 예상 -> 0에서 시작하면 이에 대한 그라디언트 값도 0이 나오니 0에 결국 수렴하는 활성화 함수가 존재할 수 있음. 1은 모든 경우에 대해 1로 시작하면 신경망의 네트워크가 한 값으로 편향될 수 있다.
즉, 어떤 한 값으로 초기화 하는 것은 네트워크의 다양성 부족과 네트워크의 대칭성 문제를 가져올 수 있다. (특수한 경우에만 성립하는 것처럼 될 수도 있음.. 그러면 딥러닝 하는 의미가 없지!!)
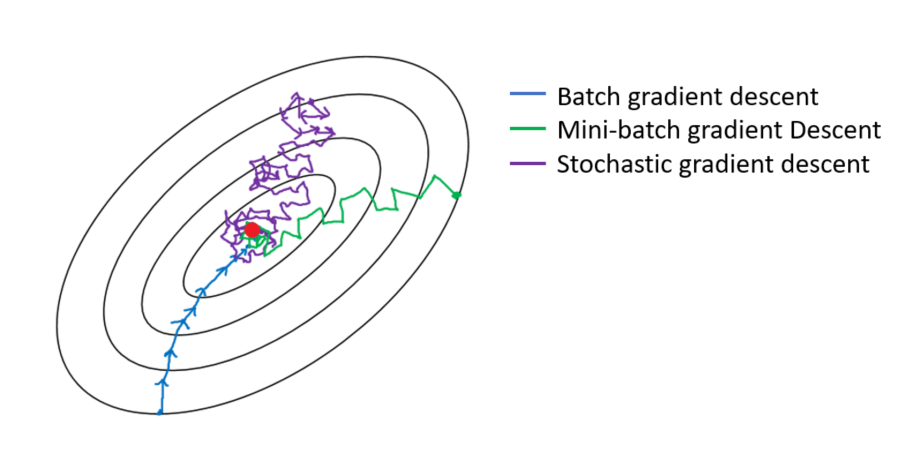
GD(Gradient descent) vs SGD(Stochastic Gradient descent)
SGD : Loss 함수에 있는 데이터 중 하나를 무작위로 뽑아서 이를 그라디언트로 임의로 칭하고 계산을 하는 것!
즉, 하나만 보고 '빠르게' 방향 결정한다.
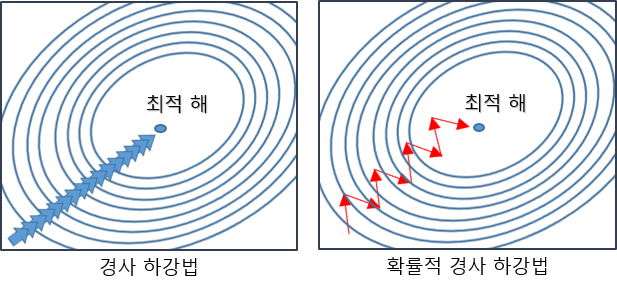
이때, gradient 값은 최솟값을 향하지 않는데, 그 이유는 한 데이터에 대해서만 했기 때문이다!!
-> 비복원추출(이미 뽑았던 데이터는 다시 안 뽑는다!) and 다 뽑히면 다시 데이터 모두 가져와서 그 중 하나 무작위로 뽑는거 반복한다!!
그리고 이는 local minimum 탈출의 기회가 되기도 한다..!
-> 한 데이터에 대해서 보기 때문에 local minimum쪽이 아니라 global minimum 쪽으로 향할 수 있다!! 물론, GD처럼 주어진 상황에서 '무조건' local minimum쪽으로 가는 것이 아니라 그럴 수 있다 정도...? ㅎ
mini-batch SGD
GD는 모두 다 보니까 너무 신중해서 탈이고, SGD는 하나씩만 보니까 너무 성급하게 방향을 결정한다. (불필요한 경박스런(?) 움직임이 넘 많다..!)
-> 그래서 mini-batch가 나왔다!!
이는 mini-batch 사이즈만큼을 선택해서 이를 가지고 그라디언트를 만들어 사용한다.
주의점은 이 mini-batch 사이즈보다 더 적게 데이터의 개수가 남았을 때, 그냥 그 데이터 개수만큼 그라디언트를 만들어 사용한다는 것이다. (왜냐면 소외되는 데이터가 없도록 하기 위해서!)
또, GPU는 병렬 연산을 가능하게 하므로 여러 데이터에 대해서도 빠르다. 그러므로 적당한 사이즈의 batch size를 가지고 GD를 하면 빠르다!
[*] 여기서 batch size는 8k(8000)까지만 키우자..! 왜냐면 batch size가 클수록 에러가 많이 난다.
(성능이 안 좋다...아마 안 좋은 (쓸 데 없는) local minimum으로 빠질 가능성이 커지기 때문이지 않을까...)
다만, 8k까지는 다음 조건을 만족하면 괜찮게 작동한다!
- batch size를 두 배로 하고 싶으면, learning rate도 두 배로 해라!
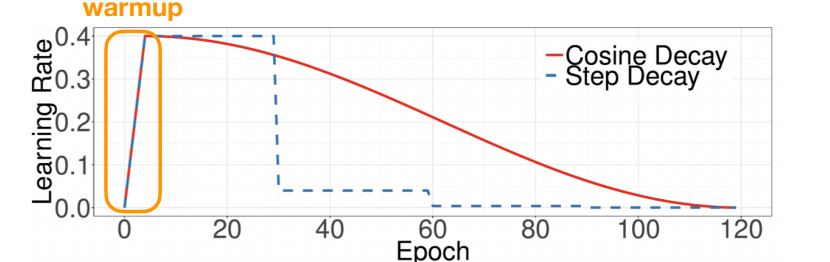
- learning rate에 warmup 단계를 만들어라!
-> learning rate가 상수가 아니라 어떠한 함수일 때, learning rate를 첨부터 크게 하면 안 좋고 내가 원하고자 하는 learning rate까지 조금씩 키워서(warmup) 목표치까지 도달하고, 그 다음에 더 조금씩 조금씩 줄어들어라!
[*] GPU vs CPU
구구단을 하는 것을 예로 들자면, 구구단 문제 1000개 푸는데 GPU는 초딩 1000명을 데리고 각각 구구단을 시키는 것이고(병렬 연산), CPU는 구구단 박사 1명에서 구구단 시키는 것(직렬 연산)..? 이라고 볼 수 있다.
[*] Epoch와 batch size
총 Epoch 수
-> 전체 데이터를 몇 번 반복해서 볼꺼냐를 의미.
batch size -> 몇 개씩 볼꺼냐
learning rate -> (보폭을) 얼만큼 갈거냐
등등..을 'hyperparameter'라고 한다!
=> 이들은 우리가 '직접' 정해줘야 한다.
[*] Parameter vs Hyperparameter
파라미터 (머신이 '스스로' 알아내는 변수)
-> weight, bias (얘도 걍 weight라고도 부름..!), 등등..이 존재
하이퍼파라미터 (내가 '정해줘야' 하는 변수)
-> Initial weight 값, (총) Epoch, batch size, learning rate, model architecture (<- layer 수, node 수, activation 함수 등...)
Moment vs RMSProp
- (mini-batch) SGD vs Momentum
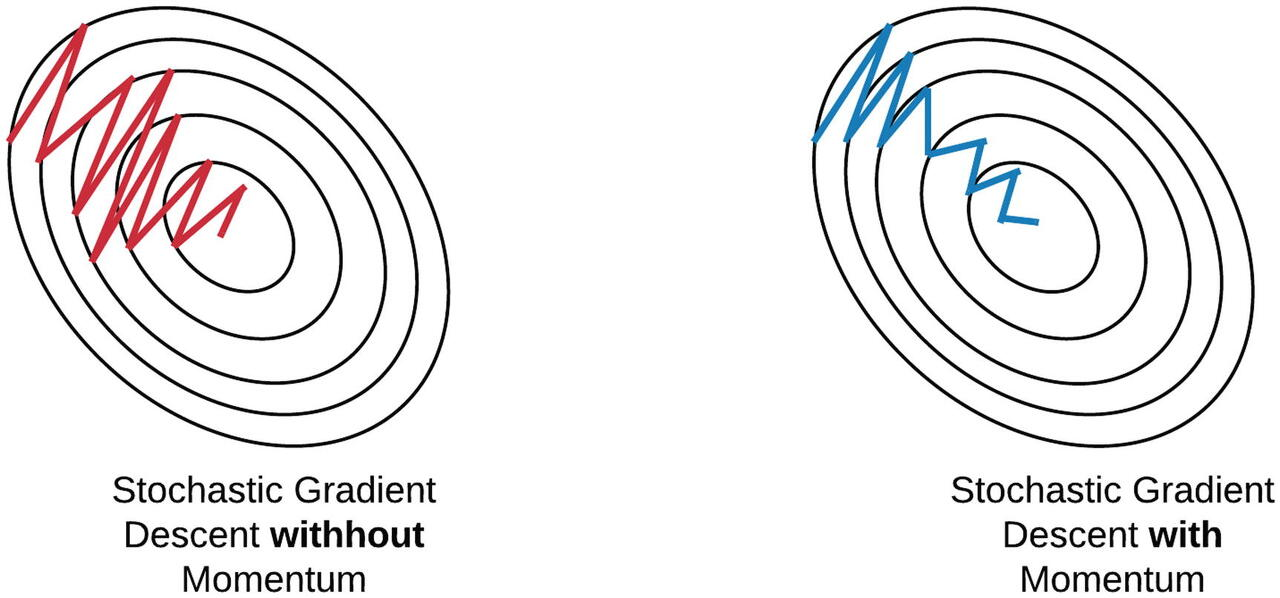
타원형태(산 모양)의 그래프에서 SGD를 구하면 그라디언트가 향하는 방향은 위상(등고선..?)으로 보았을 때의 수직이 되는 방향으로 간다. 그래서 계속 수직 방향으로 가다보면 최솟값에 좀 느리게 도착한다. (이는 타원형의 곡률이 크면 클수록 더 심하다.)
이에 반해, momentum은 그라디언트가 향하는 방향을 가는 것에 '관성'을 더한다. 내가 어디 방향으로 갔다면 그 방향으로 가고자 했던 관성을 남겨두고 다음 방향을 향한다. 그렇게 하면 타원형 같은 경우에 가로세로로 움직이는 반경이 줄어들어 더 빨리 도착할 수 있으며, 앞으로 움직이고자 하는 관성은 더 더해져서 더 빨리 도착하게 된다.
마지막에 최솟값에 다다를 때쯤엔 조금 돌아간다는 아쉬움은 있을 수 있지만 그래도 이러한 상황에서 쓰기 좋다.
-> 한 마디로 정리하면 "그라디언트를 누적함으로써 관성을 가지게 함. like 치타가 사냥할 때, 사냥감이 방향을 바꾸면 치타가 쉽게 방향을 못 바꾸는 것처럼...!
- (mini-batch) SGD vs RMSprop (Root Mean Square Propagation)
먼저 예시를 들어보겠다.
웨이트가 100이고, 바이어스가 0.1인 경우에 그래프는 한쪽 방향으로 아주 편향된 그래프가 나올 것이다. 그리고 이것이 계속 반복되면 너무 한 방향으로 폭주하거나, 위와 같은 경우에 기울기 소실의 문제도 가질 수 있다.
그래서 RMSprop는 위의 파라미터에 크기(지수 이동 평균)을 나누어주어 학습률을 조정한다.
즉, 많이 훑은 축으로는 적게, 적게 훑은 축으로는 많이 탐색을 한다. (평준화를 통해 공평하게 탐색한다.)
또한, RMSprop도 mini-batch SGD처럼 미니 배치 단위로 데이터를 사용해 그라디언트를 사용해주는 것이다.
결국 RMSprop는 Learning rate를 각 파라미터(웨이트, 바이어스 등) 별로 다르게 준 셈이라고 볼 수 있다! (경사 보고 너무 가파른 쪽은 좀 조심조심.. 완만한 쪽은 과감하게!!)
Adam(Adaptive Momentum Estimation)
Adam은 momentum과 RMSprop의 합작이라고 볼 수 있다!
일단 논문 자료를 보면 다음과 같다.

우리는 여기서 'Update parameters' 부분을 유의깊게 보면 된다!
(''는 '='으로 봐도 된다.)를 주의 깊게 보면 우리가 위에서 보았던 GD의 그라디언트의 계산 방식( )과 유사하다.
차이점이 있다면 가 그라디언트()를 나타낸다는 것인데, 하나씩 뜯어서 살펴보면 다음과 같다.
- 로 '방향(exponential moving average : 지수이동평균)'을 의미한다.
위의 momentem에서 봤듯이, 방향은 관성을 가지게 한다! (=치타)
일단, 위에 그림에서 보면 는 그냥 0과 1 사이의 값이고, 는 현 시간대의 그라디언트를 의미한다.
예를 들어 이 라고 한다면,
로 과거의 그라디언트 값을 계산대상으로 하면서 가장 최근의 데이터(그라디언트)를 가장 가중치 있게 한다. 그리고 이 방식이 지수이동평균(exponential moving average)의 방식이다. - 로 '보폭'을 의미한다.
이는 RMSprop에서 봤듯이, 많이 훑은 축으로는 적게, 적게 훑은 축으로는 많이 탐색한다. (가파른 쪽은 조심, 완만한 쪽은 과감!!)
의 경우 위의 와 별반 다르지 않은데, 다만 그라디언트의 제곱(원래 벡터의 제곱은 안 되는데, 이 논문에선 편의상 각 원소들의 제곱을 벡터의 제곱이라고 부른다. 예를 들어 가 있으면 를 여기서 제곱이라고 말한다.)을 누적한다는 의미가 있다. 그리고 에서 가 분모로 들어가면서 작은 값은 크게, 큰 값은 작게 나타나게 된다는 의미를 가진다. - : 이들은 그렇게 중요한 의의는 아니고, 더 디테일하게 값을 계산하기 위해 존재하는 것들이다. 정확히 하자면 각각 와 의 평균이 와 의 평균과 비슷하도록 조정해주는 것을 말한다.
간단히 설명하자면, 위 논문에 따르면 를 0으로 생각했는데, 사실 이전의 값이 존재하겠지만 우리가 이전의 값을 알 수 없으니 0으로 생각하고 계산을 한 것이다. 그리고 이는 초반의 각각의 평균이 0 근처에서 계산된다는 문제가 있었고, 이를 해결하기 위해 조정을 해주는 것이다! - : 입실론은 '작은 양수'를 말하고 실제 계산할 때 보통 로 계산한다. 근데 이러한 작은 값이 무슨 의미가 있냐고 하면...
만약 입실론이 없다면 가 0에 가까운 값으로 갔을 때, 의 값이 갑작스럽게 확 튈 수가 있다는 문제가 있다.
예를 들어 local mininum, global mininum에 가까워질수록 그라디언트 값이 0에 가까워지므로 도 0에 가까워진다. 그랬을 때 값이 확 튈 수도 있는데, 만약 입실론이 있다면 0에 가까워져도 값이 확 튀지 않도록 버팀목이 되어주기에 입실론이 중요한 역할을 한다고 할 수 있다!
결국 Adam은 에서 momentem의 아이디어를, 에서 RMSprop의 아이디어를 쓴 것이라고 보면 된다!!
Training VS Test VS Validation
Training은 처음에 정답들을 보여주면서 훈련하는 것을 의미하고, Test는 새로운 데이터를 보여주며 잘하나 테스트 하는 것이다!
일단, Test 데이터를 학습 때 사용하면 안 된다!
왜냐면 DL의 목적이 '처음 보는 데이터에 대해 얼마나 잘하는지'를 보는 것이기 때문이다!! 즉, Test data에 대해 잘하는 것이 AI의 목표! (실전에 강하도록!)
그런데, 학습 도중에 Test를 해보고 싶다면? 이것이 바로 Validation이다! (모의 test)
( Training의 데이터의 일부를 가지고 Validation의 데이터로 삼는다! )
이 위의 말을 data의 관점으로 보면 다음과 같다.
- Training : 파라미터 학습을 위한 data (모델이 알아서 작성하는 변수)
- Test : 최종적으로 학습된 모델 시험용 data
- Validation : 하이퍼파라미터 선택을 위한 data (내가 직접 지정하는 변수)
백엔드도 그렇고 모든 컴퓨터 분야에서 가장 중요한 것이 '테스트'이다.
DL도 마찬가지로 테스트를 잘해야 좋은 머신이므로 val data를 보고 하이퍼파라미터를 결정한다!
- ex1) val data에 제일 잘할 때 학습을 멈춘다. (총 Epoch 수)
- ex2) val data에 제일 잘하는 모델을 구한다. (model 구조)
우리가 궁극적으로 Test data를 잘 봐야하는 것인데, Training만 주구장창 복잡하게 한다고 마냥 Test data를 잘 보는 것이 아니다. 예를 들어 Test data를 수능이라 하고, Training data를 연습 문제라고 한다면 연습 문제만 주구장창 푼다고 수능에 나오는 모든 문제를 잘 맞추는 것이 아니다. (시간 분배라던지.. 문제들의 중요도 식별이라던지.. 수능 문제 출제 경향이라던지.. 연습 문제로는 한계가 있는 부분이 있다..!)
그래서 우리는 수능을 위해 '모의고사'라는 것을 보고, 이에 해당하는 것이 Validation data인 것이다!!
물론 Val data를 잘한다고 Test data를 잘 보는 것이 보장되지는 않는다..! 하지만 연습 문제만 푸는 것으로는 '연습 문제'만 잘 보게 되는 것이므로 Val data를 잘하는 것이 중요하다고 할 수 있다!!
K-fold Cross Validation
K-fold Cross Validation은 데이터의 수가 너무 적어서 Training data를 가지고 val data로 전환해 쓰기가 곤란할 때, 쓰는 방법이다!
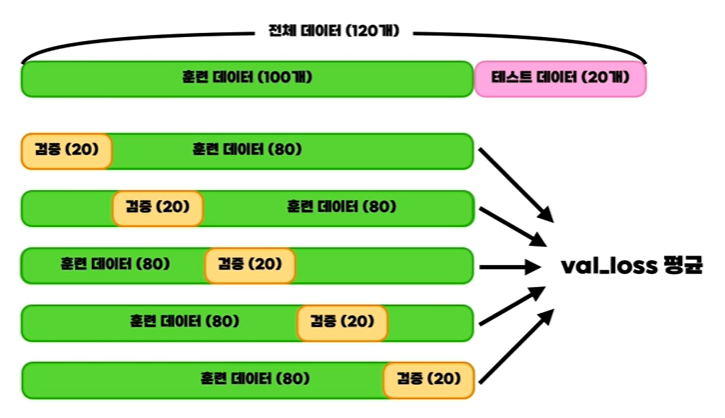
혁펜하임님의 강의 자료에 나온 위의 그림을 보면, 훈련 데이터 100개와 테스트 데이터 20개로 총 120개의 데이터가 있다.
위의 경우는 5-fold로 val data를 한 것인데, 훈련 데이터를 5등분하여 training과 val data를 하고, 나오게 되는 val_loss들의 평균을 내는 것이 K-fold Cross validation이다!
그렇다면 이를 어떻게 활용할 것인가? 하이퍼파라미터의 적절한 셋을 고르는데 활용한다!
val_loss 평균이 가장 작게 나오는 하이퍼파라미터를 적절한 모델의 환경이라고 하는 것이다!
그렇게 한 다음, 선택된 set으로 training data 전체(위에선 100개)를 다시 훈련하거나,
학습했던 5개의 모델 출력 결과를 하나로 합치기도 함. ( ex) majority vote : 다수결 )
정리
- AL(인간의 지능 모방) 안에 ML(데이터를 이용) DL(DNN을 이용)가 있다.
- CNN(이미지 및 패턴 인식), RNN(자연어 처리), GAN(생성적 적대 신경망 <생성자(도둑)와 판별자(경찰)>으로 딥페이크, 음악 생성, 이미지 변환, 그림 그리기 등)
- 지도 학습 : 내가 정답을 알고 훈련시키는 것 / 비지도 학습 : 내가 정답을 모르는 것
- 자기지도 학습 : 진짜 풀려고 했던 문제 말고 다른 문제를 새롭게 정의해서 먼저 풀어보는 것!
- 강화학습 : 어떠한 환경에서 계속 학습을 해 결과들을 비교하며 최적의 최종 결과를 내는 것.
- 인공 신경망 = 함수 : 웨이트와 바이어스를 알아내는 것이 최종 목표.
- 선형 회귀 : (loss 함수를 최소화 하는) 최적의 웨이트와 바이어스를 알아내는 분석 기법
- 경사하강법 : 일단 처음 웨이트, 바이어스는 아무렇게나 정한 다음, 현재 웨이트, 바이어스 위치에서 L을 줄이는 방향으로 나아가자! (현재에 최선을 다하자)
( : learning rate, g : gradiant)- Initial weight (초기 가중치 설정) "0 근처로 잡아라!!"
- SGD : 데이터 중 무작위로 하나를 뽑아 이에 대해 그라디언트를 구해 빠르게 목표로 가는 것.
- mini-batch SGD : 데이터 중에 batch size만큼 무작위로 뽑아 이에 대해 그라디언트를 구해 계산.
- 파라미터(머신이 스스로 알아내는 변수) : weight, bias / 하이퍼파라미터(내가 직접 정해주는 변수) : learning rate, epoch, batch size, model architecture ( layer 수, node 수, activation 함수 등...)
- Momentum : 그라디언트를 누적함으로써 '관성'을 가지게 함.
- RMSprop : 많이 훑은 축은 적게, 적게 훑은 축은 많이 탐색. (평준화를 통해 공평하게 탐색.)
- Adam : momentum과 RMSprop의 합작
- Validation : training data에서 빼와 모의 test하는 것. 이를 통해 하이퍼파라미터 선택.
- K-fold Cross Validation : training data가 적을 때 사용. training data를 k개로 쪼개 한 부분씩 val data로 삼아 모의 test.
이를 통해 가장 val_loss 평균이 낮은 하이퍼파라미터 set을 찾을 수 있음.
