
목표
딥러닝계의 Legend 논문(이론) 중 WideResNet와 ResNeXt에 대해 알아보자!
이 내용은 혁펜하임님의 'Legend 13' 강의를 기반으로 작성함.
이 내용은 전 작성 내용과 이어집니다.
WideResNet
WideResNet은 layer가 깊어지는 것에 초점을 두는 것이 아닌 넓어지는 것 (각 레이어의 필터(채널) 수를 증가시키는 것)을 초점으로 두자는 논문이다!
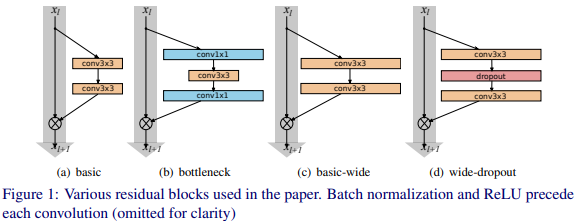
(논문 : https://arxiv.org/pdf/1605.07146v4)
위의 그림을 보면 a, b가 기존이고 c, d가 제안한 구조이다.
a와 c는 단순히 필터 수를 증가시키는 것인데,
b인 병목 구조는 d로 가면서 1 X 1 conv를 사용하는 것 대신 3 X 3 conv 두 번 사이에 dropout을 추가하는 방법을 사용하였다.
d로 발전한 이유는?
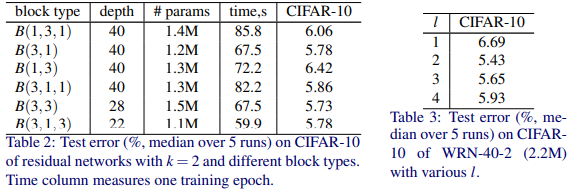 실험을 해보았을 때, B(3, 3)이 제일 효과가 좋았고 (왼쪽 그림)
실험을 해보았을 때, B(3, 3)이 제일 효과가 좋았고 (왼쪽 그림)
3 X 3의 개수를 늘리는 것 (오른쪽 그림)에선 그냥 2개를 사용한 것이 가장 좋은 모습을 보였다.
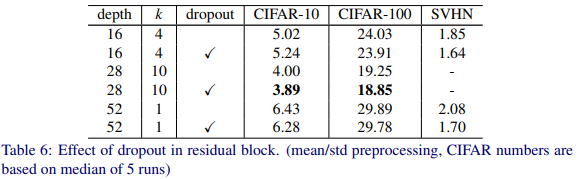 그리고 dropout을 사용한 것도 효율이 좋은 모습을 보였다..!
그리고 dropout을 사용한 것도 효율이 좋은 모습을 보였다..!
WideResNet의 전체 구조
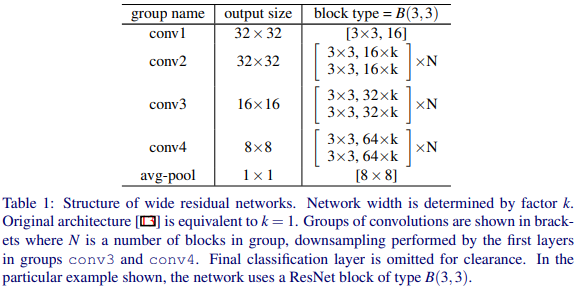 위 그림이 전체 구조인데 설명하면 다음과 같다.
위 그림이 전체 구조인데 설명하면 다음과 같다.
- conv1에선 초기 특징 맵을 생성한다.
- conv2, conv3, conv4에서 필터 수를 16 X k로 두며 Residual Block를 N X 2 X 3개 구성한다.
- 그 이후 GAP - FC를 사용한다.
- conv3, conv4 전에 downsampling(stride = 2)을 따로 진행한다.
그리고 위 구조에서 N과 k에 따라 모델 이름이 정해지는데,
'WRN-40-8'의 경우 N = 6, k = 8이 된다.
뒤의 8이 그대로 k를 나타내고,
40은 N X 2 X 3 + conv1 + fc + 중간중간 downsampling 2개를 계산하여 40이 나온 것이다. 그러므로 N이 6이다.
가장 좋은 WRN 구조
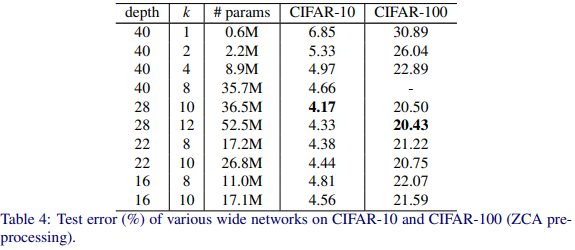 위 그림을 보면 depth = 28에 k = 10인 것이 가장 좋게 나왔다!
위 그림을 보면 depth = 28에 k = 10인 것이 가장 좋게 나왔다!
아쉬운 점
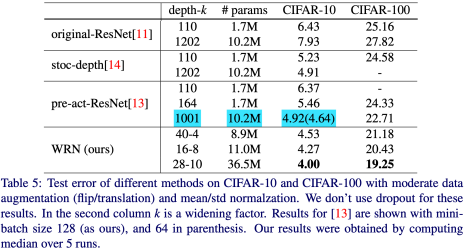 위 그림을 보면 가장 좋았던 모델인 ResNet-1001에 비해 더 좋은 효율을 보인다!
위 그림을 보면 가장 좋았던 모델인 ResNet-1001에 비해 더 좋은 효율을 보인다!
(28-10은 파라미터 수가 훨씬 많기에 그럴 수 있다고 보는데... 16-8의 경우에 파라미터 수가 비슷함에도 더 좋은 효율!!)
하지만, CIFAR가 애초에 32 X 32짜리 data이기에 이정도로 커버가 되지 않을까라는 생각이 든다...
(다른 dataset도 똑같은 결과일까?)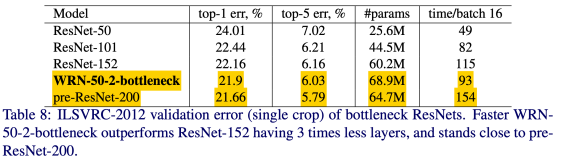 논문에서 적은 layer 수와 계산이 효율적임을 강조하지만 파라미터 수를 줄이는 등의 결과는 보지 않았기에 더 성능이 좋지 않을까라는 생각이다..
논문에서 적은 layer 수와 계산이 효율적임을 강조하지만 파라미터 수를 줄이는 등의 결과는 보지 않았기에 더 성능이 좋지 않을까라는 생각이다..
pre-ResNet-200과 비교하면 파라미터 수가 더 많음에도 에러가 더 큰 모습을 볼 수 있다.
(물론 더 빨라진 모습이다..!)- 병목 구조를 쓰지 않았다. 이에 연산량이 더 많아질 가능성이 커진다. 물론 넓어졌기에 깊이가 줄 수는 있지만 더 넓어진다고 더욱 효율이 좋아지는 것은 아니기에.. 애매한 모습이 보인다고 생각한다.
- dropout을 사용하는 방법은 CIFAR와 SVHN에선 결과가 좋았지만, ImageNet과 같은 나름 공식적인 대회에 대한 결과는 없고, 사실상 dropout이 현재 잘 안 쓰는 방법이다... 단순히 data에 맞춰서 더 나아지는 모습을 보여준 느낌이라 아쉽다.
그래도 WideResNet이 레전드인 이유
- 깊이만 보는 것이 아닌 넓이(필터 수)를 키우는 것에 초점을 맞추어 layer 수를 줄이는 것을 보여주었다!
- layer 수가 적어지기에 계산이 효율적이고 구현의 복잡도가 줄며, 빠른 모습을 보인다!!
(layer는 순서대로 해결되기에 짧을수록 더 빨라진다.)
ResNeXt
(논문 : https://arxiv.org/abs/1611.05431)
ResNeXt는 ResNet에서 발전된 논문으로 아래 그림에서 보이는 BottleNeck의 3 X 3 conv에서 conv를 grouped conv로 바꾸는 아이디어를 접목한 것이 끝인 나름 아이디어가 간단한(?) 발전 논문이다.
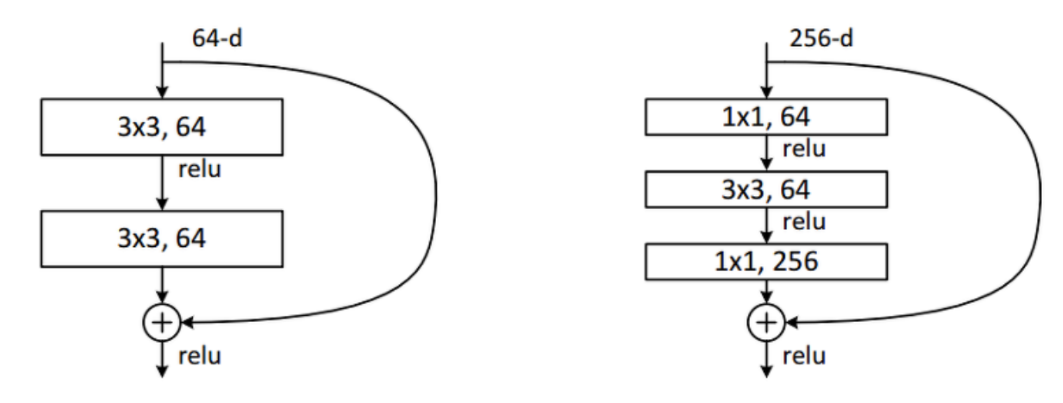 아이디어를 설명하자면 들어오는 채널에 대해 Group의 개수만큼으로 쪼개서 각 그룹 별로 따로 conv를 진행한다는 것이다.
아이디어를 설명하자면 들어오는 채널에 대해 Group의 개수만큼으로 쪼개서 각 그룹 별로 따로 conv를 진행한다는 것이다.
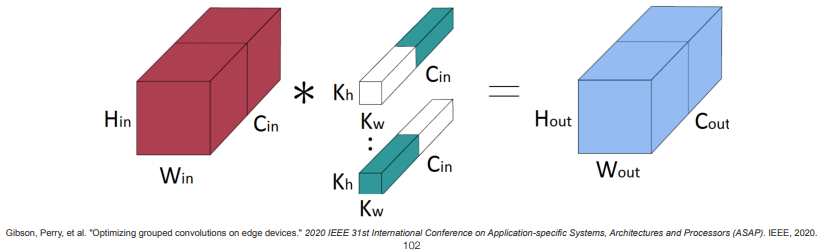 위의 그림은 그룹이 2개일 때 쪼개서 conv하는 것을 나타낸 것이다.
위의 그림은 그룹이 2개일 때 쪼개서 conv하는 것을 나타낸 것이다.
conv 후엔 모든 결과를 concat하는 것으로 이루어진다.
Grouped conv를 하는 이유
예를 들어 입력 채널로 128개가 들어가고 256개의 출력 채널을 만드는 conv가 있다고 가정하자. (conv는 3 X 3)
만약 그룹이 1(groups=1)이면 weight는 256 X 128 X 3 X 3으로 나오게 될 것이다.
nn.Conv2d(128, 256, 3, groups=1)
그룹이 2라면 weight는 절반씩 계산하기에 64개의 입력 채널로 계산한다. 그리고 모든 그룹의 결과를 concat해서 256개의 출력 채널을 만들기에 한 conv당 128개의 출력 채널을 만드는 것과 같다.
nn.Conv2d(128, 256, 3, groups=2)
그러면 weight는 2 X 128 X 128 / 2 X 3 X 3으로 나오게 되고 이 값은 128 X 128 X 3 X 3으로 그룹이 1인 것보다 2배 더 적은 weight 사용량을 가진다!!
만약 그룹이 32라면 weight는 32 X 8 X 128 / 32 X 3 X 3이기에 기존의 것보다 32배 더 적은 weight를 가지는 것이다.
nn.Conv2d(128, 256, 3, groups=32)
그러므로 Grouped conv를 하면 그룹의 수만큼 weight 즉, 파라미터를 절약할 수 있는 것이다!
그렇다면 파라미터를 절약하면 무엇이 좋을까?
이 줄어든 파라미터 (=비용)만큼 다른 곳에 투자할 수 있게 되는 것이다..!
ResNeXt는 이 절약된 것을 병목 효과가 덜 일어나도록 하는 쪽으로 투자한다!
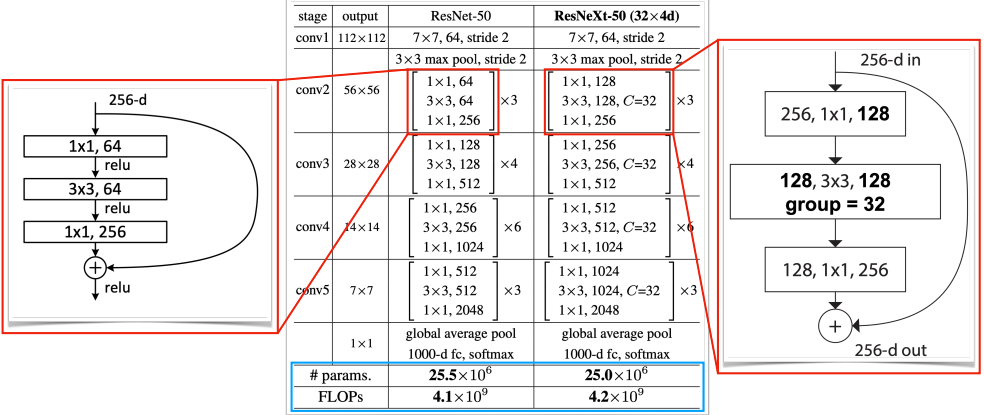
위의 그림을 보면 왼쪽의 Bottleneck 구조를 오른쪽처럼 바꾸어서 병목 효과를 완화한 것을 볼 수 있다.
Cardinality (=그룹 수)를 키운다면?
Cardinality를 키우게 되면 Bottleneck를 완화하는 효과를 가지게 되고, 결과적으로 모델의 성능이 상승하는 것을 볼 수 있었다!! (파라미터 수가 비슷할 때)
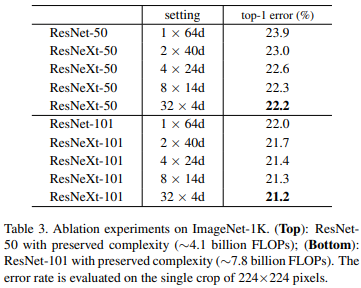 위의 그림에서 보면 setting에서 'Cardinality X 그 때의 채널 수'인 것을 볼 수 있는데, 이 때 그룹을 늘릴수록 더 좋아지는 것을 볼 수 있다.
위의 그림에서 보면 setting에서 'Cardinality X 그 때의 채널 수'인 것을 볼 수 있는데, 이 때 그룹을 늘릴수록 더 좋아지는 것을 볼 수 있다.
파라미터를 2배 키워본다면?
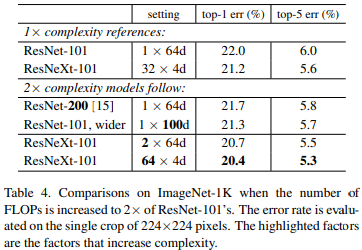 위의 그림을 보면 파라미터를 2배 키우고 어디에 투자를 하였을 때 제일 성능이 좋아지는가를 본 것인데, 역시나 Cardinality에 투자하는 것이 제일 성능이 좋아지는 것을 볼 수 있었다!!
위의 그림을 보면 파라미터를 2배 키우고 어디에 투자를 하였을 때 제일 성능이 좋아지는가를 본 것인데, 역시나 Cardinality에 투자하는 것이 제일 성능이 좋아지는 것을 볼 수 있었다!!
ResNeXt가 레전드인 이유
ResNeXt가 레전드인 이유를 보자면 다음과 같다!
- grouped conv는 AlexNet에서 살짝 언급이 됐던 기술인데, 이를 활용하여 모델이 더 좋아지도록 만들었다!
- goruped conv를 통한 파라미터 절약을 병목 효과를 완화하는데 사용하였다!
- 모델의 성능을 향상시키는 데에 깊이나 넓이을 보는 것이 아니라 그룹 수라는 새로운 성능 향상 수단을 제공한 논문이다!
