
목표
딥러닝계의 Legend 논문(이론) 중 내 생각에 가장 혁신적인 논문 중 하나인 ResNet에 대해 배워보자!
이 내용은 혁펜하임님의 'Legend 13' 강의를 기반으로 작성함.
이 내용은 전 작성 내용과 이어집니다.
Loss Landscape
Loss Landscape는 2017년에 제기된 문제로 BN, ReLU를 사용하여 Vanishing Gradient를 해결할 수 있었는데, 그래도 Layer가 너무 깊으면 학습과 테스트가 안 되는 underfitting 현상이 일어나는 문제가 있었다.
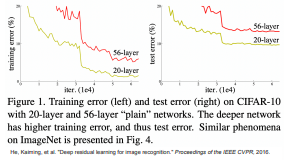 위의 그림을 보면 20층의 layer보다 56층의 layer가 train과 test 둘 다 error가 높은 것을 볼 수 있다..!
위의 그림을 보면 20층의 layer보다 56층의 layer가 train과 test 둘 다 error가 높은 것을 볼 수 있다..!
그래서 왜 이런 문제가 발생하나 봤더니 깊어질수록 Loss 모양이 꼬불꼬불해진다는 Loss sharp 현상이 있었다!
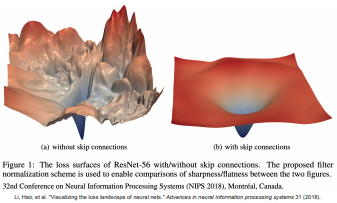 그래서 이를 막고자 ResNet은 skip-connection을 해결 방안으로 내놓았고, 이를 적용한 것이 위 그림의 (b) 그림이다!
그래서 이를 막고자 ResNet은 skip-connection을 해결 방안으로 내놓았고, 이를 적용한 것이 위 그림의 (b) 그림이다!
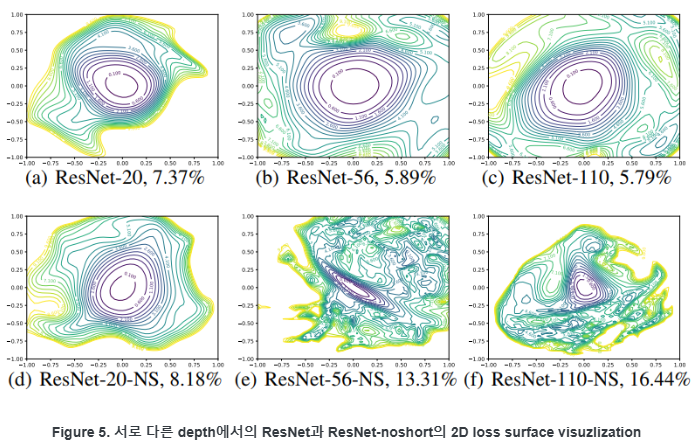 위의 그림도 보자면 NS(no skip-connection)면 layer가 깊을수록 loss 모양이 꼬불꼬불해지고 적용되면 완만해지는 것을 볼 수 있다. 그리고 skip-connection을 적용하였을 때, layer가 깊을수록 높은 정확도를 보였다!
위의 그림도 보자면 NS(no skip-connection)면 layer가 깊을수록 loss 모양이 꼬불꼬불해지고 적용되면 완만해지는 것을 볼 수 있다. 그리고 skip-connection을 적용하였을 때, layer가 깊을수록 높은 정확도를 보였다!
※ loss landscape는 어떻게 그릴까?
로 나온 경우 웨이트, 바이어스로 이루어져있기에 축, 축으로 그리면 Loss를 3D로 볼 수 있었다. 하지만 위의 그림들은 웨이트가 여러 개이기에 축이 웨이트의 개수만큼 나오게 될 것이다.
그렇다면 어떻게 저걸 3D로 표현할 수 있을까?
이는 간단하게 다음과 같이 구할 수 있었다!
에 대해 minimum한 값을 가지는 것을 라고 하였을 때, 이 는 와 같이 웨이트의 길이만큼 있는 벡터로 나타낼 수 있다.
그리고 이 웨이트의 길이와 같게 임의의 분포(여기선 가우시안 분포 을 씀.)를 따르도록 , 로 만든다. 그 다음으로 에 대해 만큼 바꾸어가고, 에 대해 만큼 바꾸어가며 의 변화를 관찰하면 된다!
그러면 라는 값에 대해 와 라는 방향에 대해 와 만큼의 크기만큼 움직이는 그림을 그릴 수 있게 된다. 이를 식으로 표현하면 다음과 같다.
그리고 Figure 1의 그림은 를 -1 ~ 1 사이의 값으로 바꿔가며 plot한 값이 된다.
Figure 5의 그림의 경우에는 좀 더 발전된 방식으로 Landscape를 그리는데, 는 그대로 두고 , 를 scaling한 랜덤 백터를 나타내도록 구성한다.
scaling하는 방법은 아래와 같은데,
첫번째로 일단 Figure 1처럼 , 를 똑같이 세팅하고,
두번째로 를 필터에 대해 다시 정의하여 로 둔다. 여기서 는 이 에서 번째 layer를 의미한다. 그리고 는 이 layer의 번째 filter를 의미한다. 그러면
은 첫번째 layer의 첫번째 filter에 해당하는 weight 모음을 의미한다!
(위를 CNN에 맞게 표현하자면 는 모듈에서 i번째 나오는 conv를 의미하고, 는 개채행열에서 '개'를 의미한다.)
위와 같이 정의되었을 때, 와 또한 filter 안의 weight 모음에 맞는 크기로 , 로 표현한다!!
이 때, 의 크기와 의 크기를 같게 만들어준다.
그러면 에 대해 는 이 나오게 될 것이고, 이에 대해 를 곱하여 준다.
이를 통해 과 의 크기를 같게 만들어준다. (도 동일)
이를 수식으로 표현하자면 다음과 같이 바꿔치기 하는 것이다.
위와 같은 방법을 filter-wise normalization이라고 부르며, 이는 landscape를 그리는 과정에서 filter에 따른 웨이트의 길이가 모두 다르고 큰 값의 필터가 loss에 더 큰 영향을 미치기에 이를 보정하기 위해 정규화를 한다고 생각하면 된다!! 이 방법을 사용하면 Figure 5처럼 더 보기 좋게 나오게 되는 것이다!
ResNet
ResNet은 2015년에 ImageNet 문제를 푸는 대회에서 새롭게 우승을 하게 된 모델이다!
기존 VGGNet에서 'Skip-connection'이라는 혁신적인 아이디어를 바탕으로 만들어진 모델이며 아래의 그림을 보면 사람의 능력을 뛰어넘기 시작한 최초의 모델이기도 하다!!
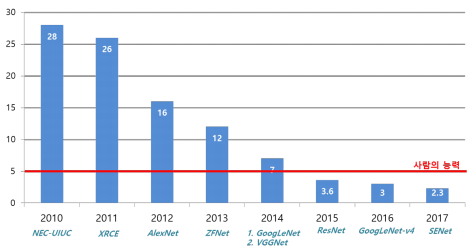
(논문 : https://arxiv.org/abs/1512.03385)
Gradient Vanishing이 아닌 문제
저자인 He는 기존의 BN + ReLU를 사용하여 Gradient Vanishing 문제를 해결을 하였는데, 아직도 모델이 깊어질 때 정답률이 떨어지는 것에 의문을 가졌다. 왜냐하면 이론상 깊어진 것들은 앝은 것들을 포함할 수 있기 때문이다.
예를 들어 Layer가 10인 모델은 Layer가 30인 모델이 해당 Layer들을 가지고 있을 수 있고, 심지어 나머지 20층으로 더 좋은 표현력을 가질 수 있기 때문이다. 즉, 얕은 모델에 그냥 값만 전달하는 identity mapping을 쌓아 얕은 모델의 성능을 그대로 가진 깊은 모델을 가질 수 있기에 깊어질 수록 표현력이 좋아야한다는 것이다. 하지만 위의 그림을 보면 Gradient Vanishing을 어느정도 해결한 두 model 중에 깊은 것이 error이 더 높다..! 이를 통해 이 문제가 Gradient Vanishing 때문이 아니라는 것을 알 수 있었다.
하지만 위의 그림을 보면 Gradient Vanishing을 어느정도 해결한 두 model 중에 깊은 것이 error이 더 높다..! 이를 통해 이 문제가 Gradient Vanishing 때문이 아니라는 것을 알 수 있었다.
하지만 He는 이 문제가 왜 일어나는지 당시에는 알 수 없었다. 다만, shortcut connection (=skip-connection)을 논리적으로 제안하여 이 문제를 해결하는 방안은 내놓았다!!
※ 후에 이 문제는 나중에 loss landscape가 꼬불꼬불한 것이 문제라는 것으로 밝혀지게 되었다!!
skip-connection을 하는 이유
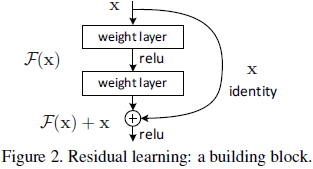 위 그림이 바로 He가 주장한 skip-connection인데, 간단하게 설명하자면 기존 layer를 학습하는데 가 원조인데, 여기서 로 나가게 해주는 것이다.
위 그림이 바로 He가 주장한 skip-connection인데, 간단하게 설명하자면 기존 layer를 학습하는데 가 원조인데, 여기서 로 나가게 해주는 것이다.
보기엔 간단한 방법인데 He가 적용하게 된 이유를 보자면 다음과 같다.
를 가지고 기존 layer의 구성 요소가 변하지 않는 상황에서 만들 수 있는 가장 이상적인 것이 라고 할 때, 라고 가정을 해보자. (이렇게 가정하는 이유는 다음 과정에 나온다.)
이 때, skip-connection이 없는 MLP라면 weight matrix, 즉 의 값이 이기에 이 값이 가 되려면 그냥 값만 전달하는 identity mapping이 되어야 할 것이다!!
그리고 skip-connection이 있는 MLP라면 weight matrix는 이기에 이 값이 가 되려면 이어야 된다!!
그런데 여기서 weight는 Loss를 줄이는 방향, 즉 0으로 초기화하기 때문에 는 일 때 더 만들기 쉬운 것이다!!
그러므로 를 쓴다...!
그렇다면 를 만들고자 할 때, 인게 효율적이라는 것은 알았는데.. 왜 로 만들고 싶은 것일까?
를 만드는 이유
원래 MLP는 이상적인 경우인 가 결괏값 를 향하도록 한다. ()
하지만 이 경우엔 목표가 로 멀기에 학습을 하는데 비효율이 생길 수 있는 것이다. 그러나 로 목표를 로 잡는다면 학습의 목표가 뚜렷하고 효율적으로 움직일 수 있는 것이다.
이는 마치 우리가 ai를 공부를 하는데, 단순히 ai를 마스터하겠다는 목표를 이루는 것보다 논문 하나씩 마스터 해나가겠다는 목표가 더욱 이루기 쉽고 뚜렷하다는 것과 비슷하다!
그리고 여기서 굳이 보다 작은 값으로 목표를 잡는 것이 아니라 가 목표인 이유는 우리가 아주 조금씩 목표를 잡아 가는 것이 쉽기에 값의 변화가 크지 않을 정도 그러므로 입력값과 근사한 를 향해간다는 것이기에 로 잡는 것이다.
결국 skip-connection이 있으면 "특정 layer에서 비중을 높이지 말고 차근차근 조금씩 비슷한 정도로 바꿔나가라"는 것을 MLP에게 알려주는 것이다!
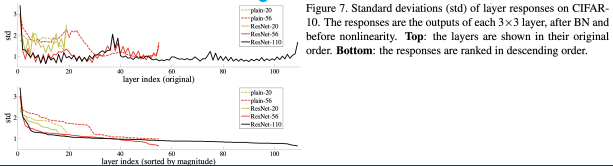
실제로 논문에선 층이 깊을수록 std가 더 작다는 실험 결과도 제시하였다! 그리고 이는 layer마다 편차가 크지 않은 것이 더 좋은 성능을 낸다는 것을 의미한다!
Residual Learning
우리가 학습하고자 하는 는 결국 에서 나왔기에 가 0에 가까워지도록 학습한다. 그리고 이는 결괏값과 입력값의 차이만 학습하기에 Residual Learning가 된다.
추가로 BN을 쓰는 경우엔 아래의 그림과 같이
conv BN ReLU conv BN + ReLU의 방식으로 진행되었다!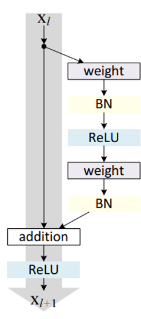
ResNet의 구조
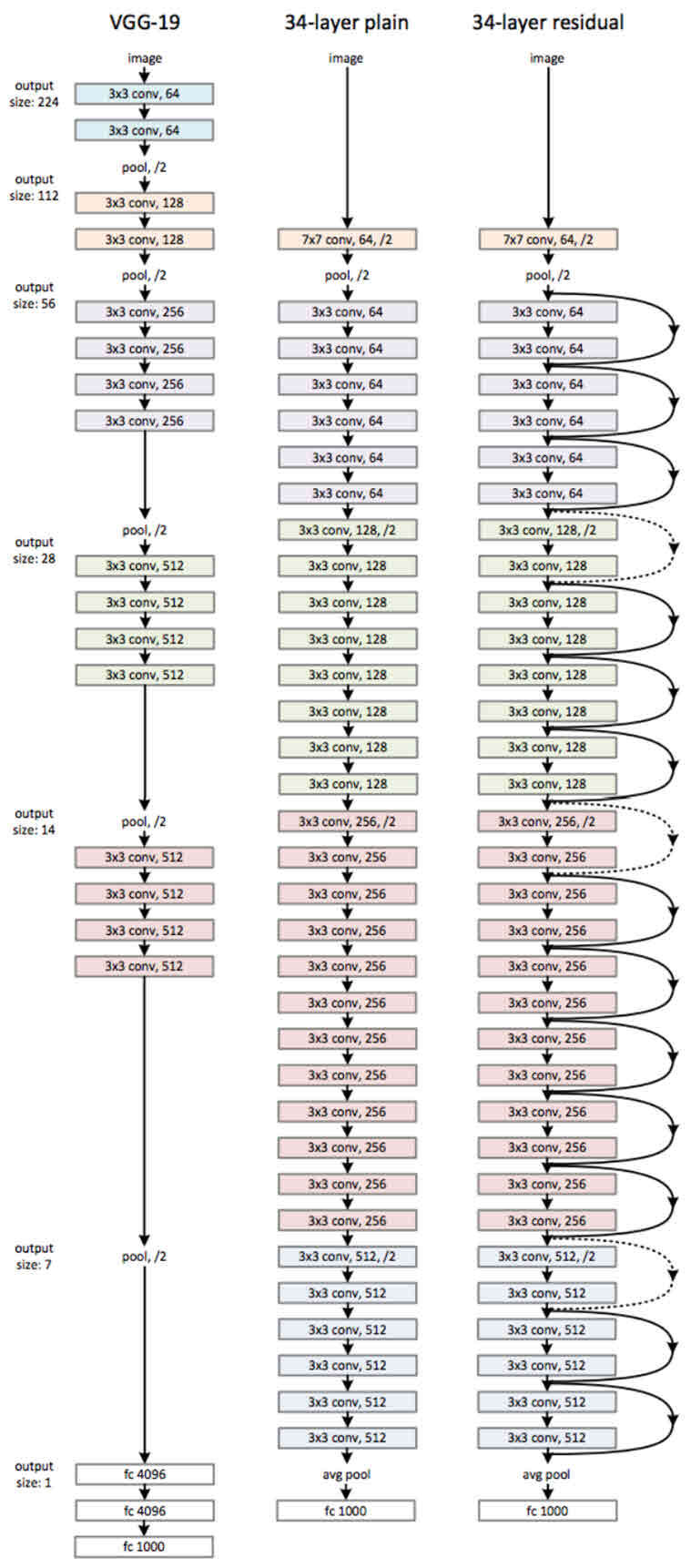 ResNet은 VGGNet과 비슷한 구조를 띄는데, 차별점이 있다면 다음과 같다.
ResNet은 VGGNet과 비슷한 구조를 띄는데, 차별점이 있다면 다음과 같다.
- 맨처음과 맨끝 pooling 말고는 쓰지 않는다. 다만, 사이즈는 줄여야 좋기에 stride=2로 줄인다!
- 점선은 1 X 1 conv이고 사이즈를 줄이는 과정에서 채널 수가 바뀌기에 이를 맞춰주기 위해 쓰인다!
- 마지막에 GAP FC로 마무리 한다는 특징이 있다.
Bottleneck 구조
위 그림의 ResNet은 3 X 3 conv만을 사용하여 깊게깊게 만드는데, 이렇게 할 때 너무 층이 깊어지면 파라미터 수가 많아져서 학습이 힘들다.
그래서 50층 이상의 깊은 ResNet에서는 1 X 1 conv로 채널 수를 줄이고 3 X 3 conv를 통과시킨 다음 1 X 1 conv로 채널 수를 키우는 병목 구조를 사용한다.
실제로 이렇게 하면 아래 그림의 원래 구조보다 25% 정도 파라미터 수를 덜 가지는 효과를 가진다. 또한 다시 3 X 3 conv로 공간 정보를 볼 수 있게 하므로 실제 정보적인 측면에서도 크게 효율이 떨어지지도 않는다!
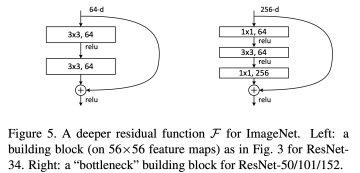
Layer의 깊이에 따른 구조 차이
결과적으로 50층 이상에선 위의 병목 구조를 사용하였다!
또한 채널 수를 맞추기 위해 쓰는 1 X 1 conv인 점선 연결은 각 conv3_x, conv4_x, conv5_x의 첫번째에 사이즈가 줄어듦에 따라 feature map 간의 weight sum을 하도록 만들기 위해 사용해준다! 그리고 50-layer부터는 conv2_x의 첫번째도 채널 수 조절을 위해 사용하였다..!
추가로 아래 그림에선 1 X 1 conv에서 stride=2로 사이즈를 down sample를 하였는데, 후에 v1.5에선 병목 구조의 3 X 3에 stride=2로 주는 것을 택하였다!
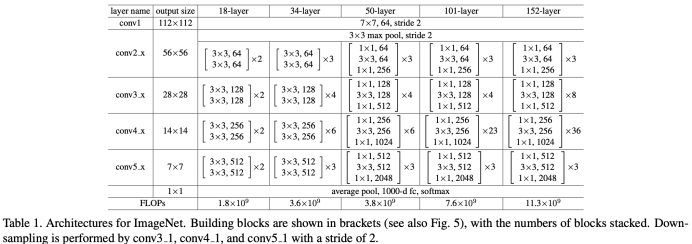
그리고 아래의 그림을 보면 깊이가 계속해서 깊어져도 더 더 좋은 성능을 보여주는 것을 볼 수 있다!!
ResNet을 교차로 진행하지 않는 이유는 무엇일까?
ResNet은 skip-connection을 하나씩 진행을 하는데, 아래 그림처럼 교차로 진행하지 않는 이유는 무엇일까?!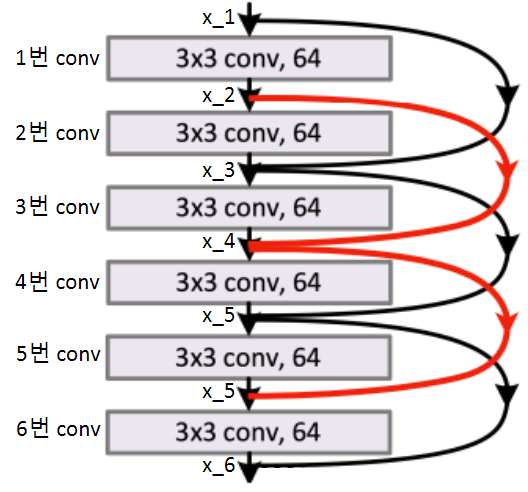 그 이유는 이렇게 하는 것이 모델에게 너무 복잡한 문제이기 때문이다.
그 이유는 이렇게 하는 것이 모델에게 너무 복잡한 문제이기 때문이다.
위의 그림에서 3번 conv의 관점에서 원래는 2번 conv와 , 사이의 잔차만 보면 됐는데, 갑자기 와 사이의 잔차에 1번 conv까지 봐야되는 상황이 되기에 너무 복잡해지는 문제인 것이다.
ResNet이 레전드인 이유
- skip-connection을 사용하여 계속해서 깊게 만드는 것을 성공하였다!!
- ResNet 6개 모델을 앙상블하여 1등에 성공하였다!!
ResNet의 해석 논문
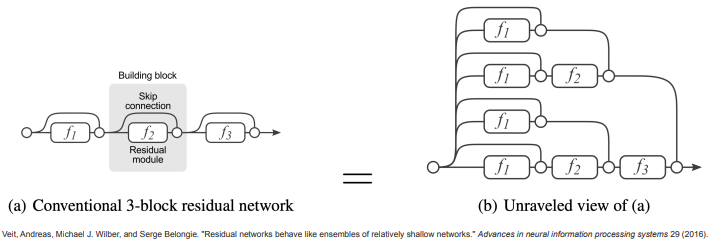
(논문 : https://arxiv.org/pdf/1605.06431)
위 그림은 ResNet에 대해 해석한 논문인데, 이 논문에선 Residual Block이 '앙상블'을 한 효과를 낸다고 설명하였다.
실제로 skip을 하는 경우, skip을 안 하는 경우를 가지고 path를 보면 로 PATH가 나온다. 그리고 이들의 결과를 앙상블하였기에 앙상블 모델처럼 볼 수 있다고 한다.
ResNet의 발전 논문
기존의 것은 ReLU가 끝에 있기에 gradient가 사라질 위험이 존재한다! (ReLU는 음수면 다 걸러버리기 때문에...)
그래서 카이밍 허는 아래 그림처럼 act를 Residual 쪽으로 넣어서 이를 해결하였다!
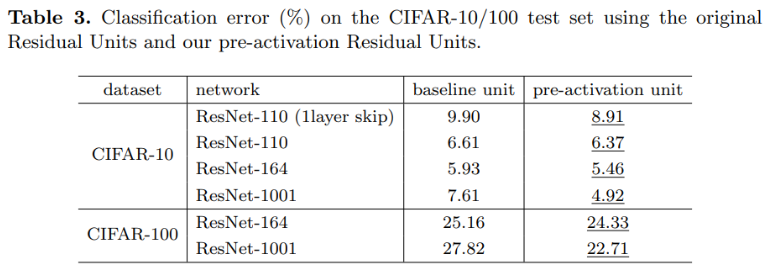
(이는 post-activation에서 pre-activation으로 바꾼 것으로 볼 수 있다!)
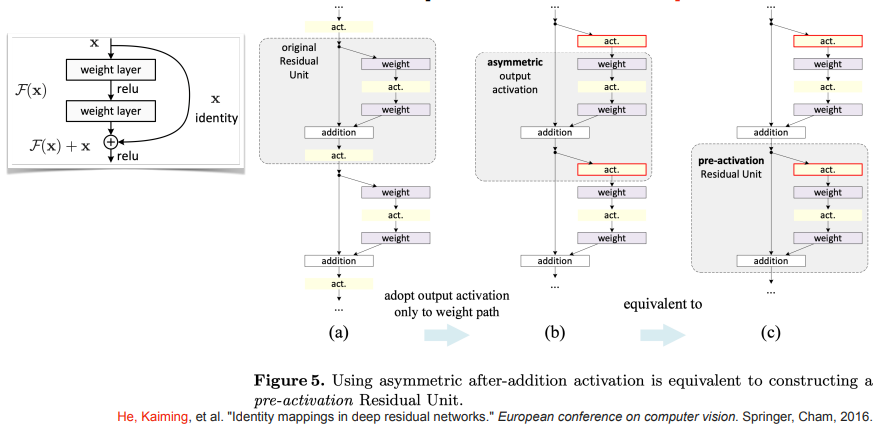
그리고 여러가지를 시도해보았는데, BN까지 빼는 것이 가장 효과가 좋았다고 한다.
 위의 그림처럼 모든 것을 full pre-activation으로 두었을 때, 기존에 shortcut이 conv - BN이었는데, BN - ReLU를 residual 쪽으로 빼놨기에 shortcut이 conv만 하면 되도록 단순화되는 효과가 있다!
위의 그림처럼 모든 것을 full pre-activation으로 두었을 때, 기존에 shortcut이 conv - BN이었는데, BN - ReLU를 residual 쪽으로 빼놨기에 shortcut이 conv만 하면 되도록 단순화되는 효과가 있다!
