[CV] An Image Is Worth 16x16 Words: Transformers for Image Recognition At Scale(ViT) review
[Paper review]


🎈 본 리뷰는 ViT 및 리뷰를 참고해 작성했습니다.
Keywords
🎈 Using pure transformer for Image Recognition
🎈 Fewer computational resources to train
Introduction
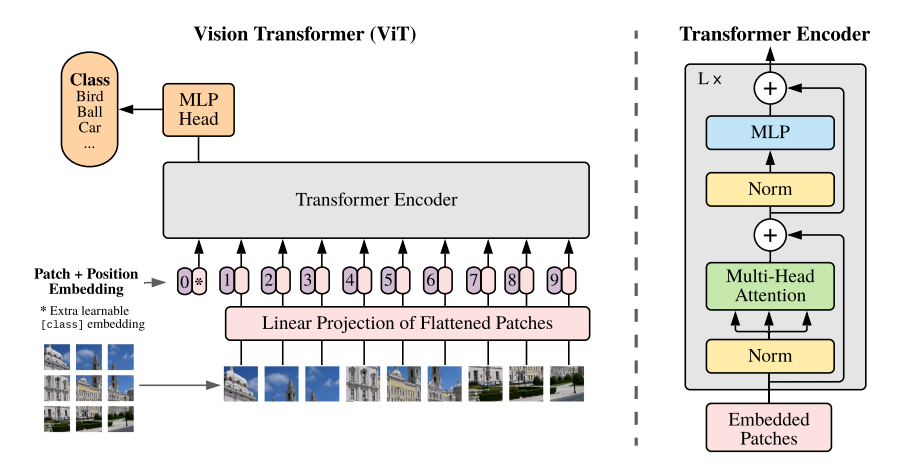
✔ 위는 ViT은 전반적인 아키텍처 구조입니다. 이는 기존의 Transformer나 Bert와 매우 유사한 것을 볼 수 있습니다. 논문의 저자는 기존의 transformer 구조를 최대한 비슷하게 설계해 image classification을 진행했습니다. 그렇기에 기본적인 Transformer나 Bert 구조를 읽어야 이해하기 수월합니다.
✔ ViT는 기존의 CNN보다 inductive bias가 부족하다고 이야기합니다. 그 결과 적은 데이터 셋보다는 많은 데이터 셋에서 좋은 결과를 보여줍니다. 결과적으로는 많은 데이터셋이 있다면 SOTA의 결과를 보여주며, 적은 파라미터 수로 좋은 결과를 보여줍니다.
✅ Inductive bias
- Inductive bias는 training에서 보지 못한 데이터에 대헤서도 적절한 귀납적 추론이 가능하도록 하기 위해 모델이 가지고 있는 가정들의 집합을 의미합니다.
✔ 논문에서는 Transformer가 상대적으로 CNN보다 Inductive bias이 부족하다고 이야기합니다. 기존의 CNN에서는 translation equivariance와 locality라는 가정이 존재하지만, Transformer에서는 이를 가정 할 수 없습니다. 그 결과 충분하지 못한 data에서는 좋은 결과를 얻지 못합니다(ex. ImageNet)
Method
✔ ViT의 모델 디자인은 기존의 Transformer와 가능한 한 유사하게 구성했다고 합니다.
Vision Transformer(ViT)
✔ ViT는 기본적인 이미지를 Patch로 분할해 진행됩니다. 본 논문에서는 각 patch를 (16x16), (14x14) 사이즈를 사용하고 있으며, 이는 이미지의 resolution과는 관계없이 일정합니다. 또한 기존의 Transformer 구조와 다른 점은 Norm을 먼저 수행한다는 점입니다.

✔ 기존의 Transformer의 경우엔 1D sequence of token이 필요했다면, ViT는 이미지(2D)를 다루기 때문에 위와 같이 Reshape를 필요로합니다. 에 대해 구조로 reshape를 진행합니다. 여기서 는 원본 이미지의 높이와 너비이며, 는 채널의 수, 는 각각의 이미지 patch의 크기이며, (=패치의 수) 입니다.
✔ Transformer에서 D 사이즈의 상수 벡터를 사용함으로, patches들을 flatten해 D dimenstion으로 매핑합니다. 위의 projection 결과를 patch embedding이라고 이야기 합니다.

✔ 또한 Bert와 유사하게 시작지점에 학습가능한 임베딩 [class] token을 추가합니다(). 각 class 토큰은 impage representation을 Transformer encoder에서 output으로 나타냅니다.
✔ classification head는 pre-training과 fine-tuning시에 에 attached 되며, 이는 MLP로 구성되어있고, pre-training시에는 하나의 hidden-layer로, fine-tuning시에는 sigle linear layer로 구성되어 있습니다.
✔ 또한 추가적으로 patch embedding에 position embedding한 값으 더합니다. position embedding는 기존의 학습가능한 1D position embedding을 진행했는데, 이는 2D로 진행했으때보다 성능이 좋았기 때문입니다.
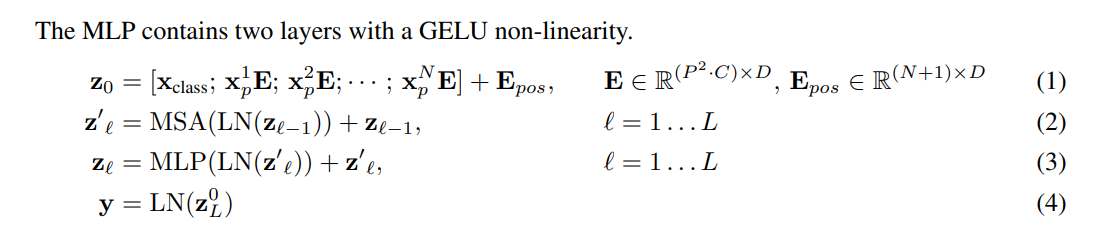
✔ 위는 ViT의 전체적인 구조를 위의 수식을 통해 확인 할 수 있습니다. MSA는 기존 transformer에 multiheaded self-attention을 의미하며, LN은 Layernorm을 의미합니다.
Inductive bias
✔ 앞서 Inductive bias에 정의에 대해 간단히 언급했습니다. ViT에서는 CNN보다 적은 inductive bias가 존재합니다. self-attention layers에서는 global하기에, 오직 MLP에서만 local, translationally equivariant이 존재합니다.
Hybrid Architecture
✔ ViT에서는 raw한 image patch가 아닌, CNN을 통해 추출된 feature map을 input으로 사용한 하이브리드 모델을 실험했습니다. 각각의 patch들은 1x1로 input으로 들어가게 됩니다.
Fine-Tuning And Higher Resolution
✔ 전형적으로, ViT는 큰 데이터 셋을 pre-trained 한 후 fine-tune downstream tasks를 진행합니다. fine-tune시 pre-traine prediction head는 제거한 후 로 이루어진 zero-initialized 피드포워드 레이어를 추가합니다. 추가로 K는 downstream class의 수를 의미합니다.
✔ 일반적으로 생각하면 이미지의 resolution에 따라서 patch 사이즈를 다르게 하는게 아니라, patch 사이즈를 고정을 합니다. patch의 사이즈를 고정하면 sequence lengths를 달라지게 됩니다. 그렇다면 임의의 sequence lengths를 지정해준다면 포지션 임베딩의 의미가 사라지게 됩니다. 결과적으로 2D interpolation를 사용해 대체할 수 있다고 합니다.
Experiments
Setup
✔ Datasets은 아래의 데이터들을 사용했습니다.
- ImageNet with 1k classes
- ImageNet-21k with 21k classes and 14M images
- JFT with 18k classes and 303M high-resolution images
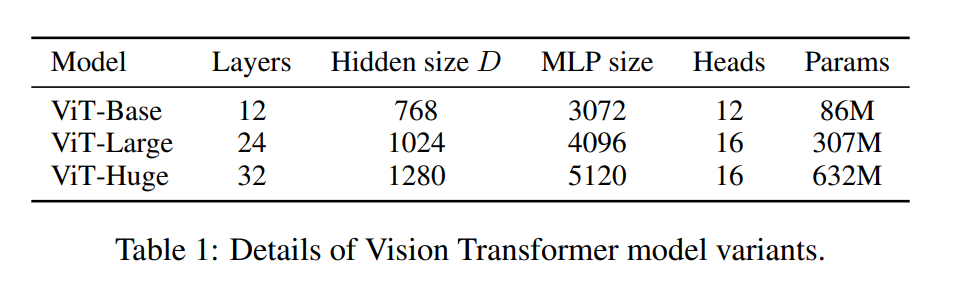
✔ Model variants는 위에 표와 같이 Base, Large, Huge로 구분하며, ViT-L/16이라고 하면 Large모델에 16x16 input patch size라는 의미입니다. 또한 patch 사이즈가 작을 수록 computation cost는 증가할 것입니다.
✔ Training & Fine-tuning 모든 모델의 training시 Adam optimization(을 사용했습니다. 4096개의 batch size를 가지며, high weight decay는 0.1로 서설정합니다. Fine-tuning시에서는 SGD with momentum을 사용하며, 512의 배치 사이즈를 사용합니다.
Comparison to State of the art
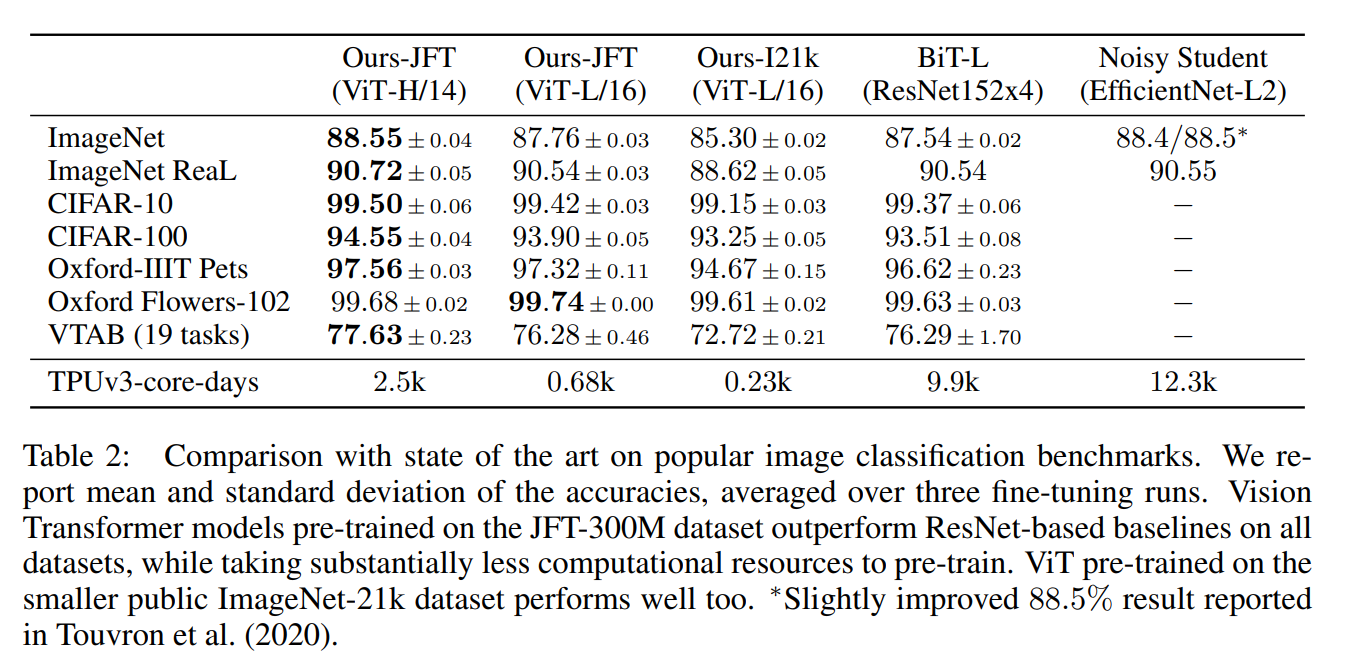
✔ 기존의 SOTA 모델과의 비교입니다. ViT가 SOTA의 성능을 보여주면서, 훨신 더 적은 computational resources가 필요한 것을 확인할 수 있습니다.
Pre-Training Data Requirments
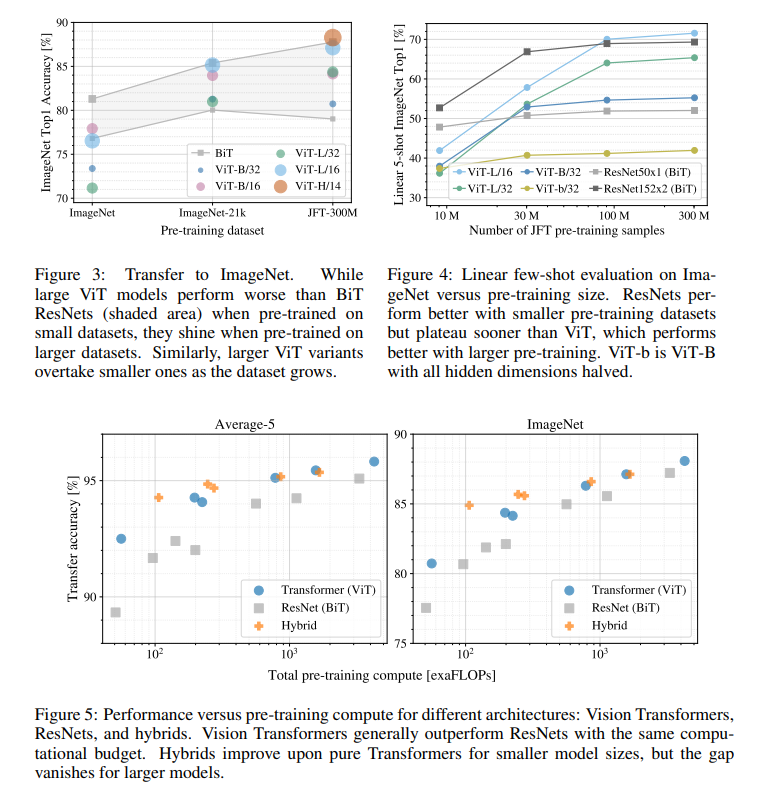
✔ 위의 그래프에서 데이터 크기에 따른 성능을 확인할 수 있습니다. 데이터셋의 크기가 작을떄는 기존의 SOTA 모델의 성능이 더 좋은 것을 확인할 수 있습니다만, 데이터셋의 크기가 커지면 ViT의 성능이 더 좋음을 확인할 수 있습니다.
✔ 이는 앞서 말씀드렸던 inductive bias와 연관지어 생각한다면, 데이터셋의 크기가 많으면 inductive bias가 크게 중요하지 않는다는 것을 의미할 수도 있다고 생각합니다.
Inspecting Vision Transformer
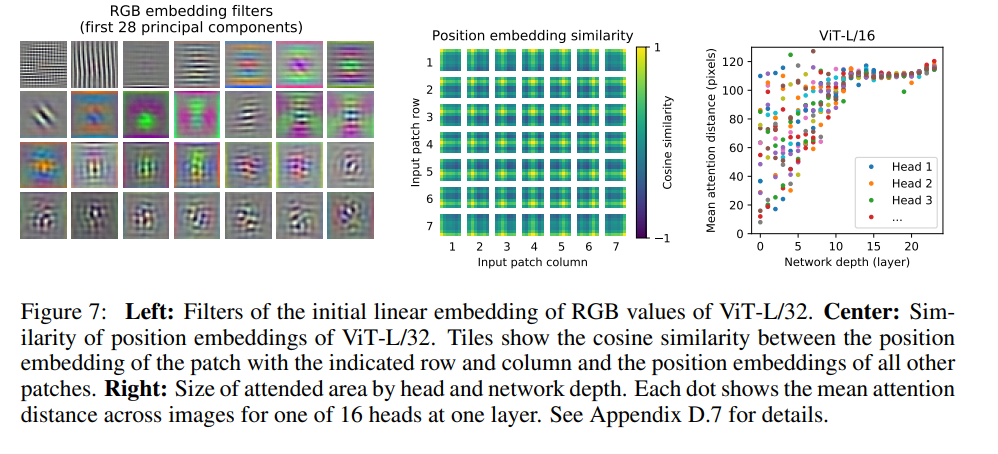
✔ Figure 7의 Left는 학습된 임베딩 필터의 구성요소를 보여줍니다. 구성 요소는 각 patch내에서 미세한 구조를 저차원적으로 표현하기 위한 그럴듯한 기본 기능과 유사한 것을 볼 수 있습니다.
✔ Figure 7의 center는 모델의 position 임베딩의 유사성으로 이미지 내의 거리를 나타내고 있습니다. 더 가까운 patch는 더 유사한 position 임베딩을 갖는 경향이 있습니다.
✔ Figure 7의 right는 "attention weights"를 기반으로 정보가 통합된 이미지 공간의 평균 거리를 계산한 거리를 보여줍니다. 여기서 의미하는 "attention weights"는 CNN의 receptive field size와 유사한 것을 알 수 있습니다.
✅ 지금까지 전반적인 ViT 네트워크에 대해 알아봤습니다. ViT 모델 구조는 사실 상 transformer와 bert를 알고 있다면, 이해하기 어렵지 않은 구조라고 생각됩니다. 논문에서도 역시 transformer 가능한 한 비슷하게 구성했다고 언급하고 있습니다. 위에 작성된 실험 결과외에도 다양한 실험 결과들이 논문에서 제시되어 있습니다. 자세한 내용은 논문에서 확인해주시면 됩니다.
Reference
