
🎈 본 리뷰는 Faster R-CNN 논문 및 리뷰 등을 참고해 작성했습니다. 참고한 reference는 글 마지막 단에 개시하겠습니다.
 Faster R-CNN의 구조
Faster R-CNN의 구조
Key Words
🎈 RPN
🎈 Anchor box
🎈 Share Features
🎈 time cost-efficient
🎈 Fast R-CNN
🎈 Loss Function
Introduction
✔ 최근 Region-based CNN(R-CNN)은 object detection 분야에서 성공적이었습니다. Fast R-CNN은 R-CNN에서 더 나아가 거의 real-time rate에 가까워지는 성과를 보여줬습니다. (region-proposal의 시간은 제외) 결국 문제는 region-proposal의 문제를 어떻게 해결할 수 있을까?. region-proposal의 가장 큰 문제는 CPU를 사용한다는 것입니다. 그렇다면 해결방안은 간단한거 같습니다. region-proposal을 GPU를 사용해 추출할 수 있다면 해결할 수 있을겁니다.
✔ 본 논문에서 제시된 해결방안은 RPN(Regions Proposal Network)입니다. 본 논문의 가장 핵심이 되는 알고리즘입니다. RPN은 Fast R-CNN와 conv layer을 공유을 함으로써 시간비용을 줄일 수 있었습니다.
✔ Faster R-CNN = RPN + Fast R-CNN 라고 언급합니다. 또한 본 논문에서 제시한 방법론은 object detection의 정확도와 비용 효율적인부분에서 효과적이라고 언급합니다.
Faster R-CNN
- Faster R-CNN의 2가지 구성요소
✔ Deep Fc layer that proposes regions
✔ Fast R-CNN detector that use proposes regions
Region Proposal Networks
** herbwood의 velog RPN에 대해 깔끔하게 설명되어 있는 블로그 입니다. 이해가 안되신다면 추천드립니다.
- Input: Image(any size)
- Output: a set of retangular object proposals, each with an objectness score
- RPN은 Fast R-CNN과 계산을 공유 해야하기에 Fully Connet Layer로 구성되어 있습니다.
Anchors
 ✔ CNN에 모델에서 도출된 feature map의 크기는 고정된 사이즈를 가지고 있습니다. 이 말은 즉 다양한 물체를 인식할 수 없다는 것을 의미합니다. RPN에서는 위의 사진과 같이 서로 다른 3 scales와 3 aspect ratios을 가진 Anchor boxes(=k)를 생성합니다. 위 논문에서는 9개의 Anchor boxes를 사용했다고 합니다. 전형적으로 총 W x H x K개의 Anchor 사이즈를 가집니다. (W x H = feature map의 size)
✔ CNN에 모델에서 도출된 feature map의 크기는 고정된 사이즈를 가지고 있습니다. 이 말은 즉 다양한 물체를 인식할 수 없다는 것을 의미합니다. RPN에서는 위의 사진과 같이 서로 다른 3 scales와 3 aspect ratios을 가진 Anchor boxes(=k)를 생성합니다. 위 논문에서는 9개의 Anchor boxes를 사용했다고 합니다. 전형적으로 총 W x H x K개의 Anchor 사이즈를 가집니다. (W x H = feature map의 size)
✔ Anchor box를 사용함으로써 reg layer에는 4k의 ouput과 cls layer에는 2k의 output이 도출됩니다.
✔ 각 Anchor에 대해 두 가지로 분류합니다.
- Positive: IoU가 0.7보다 크거나, Ground Truth box마다 가장 큰 Anchor 하나.
- Negative: IoU가 0.3보다 작으면 negative로 분류합니다.
- 이 외의 나머지 데이터는 사용하지 않습니다.
RPN Process
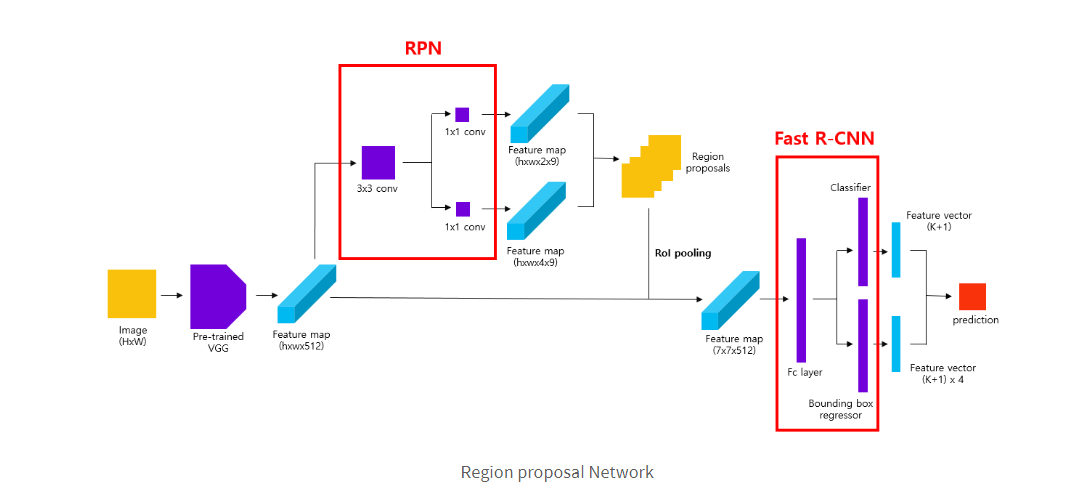
(1). VGG를 통해 학습된 Feature map(hxwx512)를 얻고, 3x3의 conv layer 연산을 진행합니다. 연산 진행 시 Feature map의 크기를 유지시키기 위해 padding을 추가합니다.
(2). 각각의 bbox regression layer와 classification layer의 연산을 위해 1 x 1 conv 연산을 추가합니다. 이때 출력되는 Feature map 커널 수는 classification layer의 경우 2 x 9, bbox regression layer의 경우 4 x 9 가 되도록 설정합니다.
(3). 결과적으로 W x H x K의 region-proposals이 출력됩니다. (W x H = feature map의 size) 이 후 predict된 결과는 Non-maximum Suppression & RoI sampling을 거쳐 Fast R-CNN에 사용됩니다.
Multi-task Loss Function
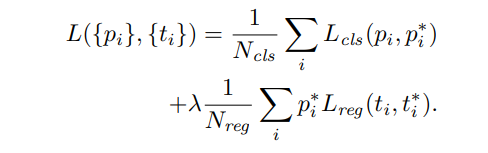
: mini-batch 내의 anchor의 index
: anchor 가 Object에 포함될 예측확률
: anchor가 positive면 1, negative면 0
: 예측 bounding box의 파라미터화된 좌표
: ground truth box의 파라미터화된 좌표
: Classification loss
: Smooth L1 Loss (R( - ))
: mini-batch의 크기
: 정규화된 anchor의 수
: balance parameter
✔ Classification은 object 여부만을 분류하고, bbox-regression은 Ground Truth box 위치를 통해 위치를 예측합니다.(자세한 내용은 Fast R-CNN 논문 참고부탁드립니다.)
Training RPNs
** herbwood의 velog Traing 과정에 대해 깔끔하게 설명되어 있는 블로그 입니다. 이해가 안되신다면 추천드립니다.
✔ RPN은 역전파를 통해 end-to-end 학습이 가능하며, stochastic gradient descent(SGD)를 사용해 학습했습니다.
✔ 랜덤하게 256 anchors sample을 mini-batch로 선정하고 학습합니다. sampling 된 anchors들은 positive와 negative 비율을 1:1로 지정합니다.
✔ 초기 weights ~ Gaussian(0,0.01), momentum = 0.9, weight decay = 0.0005로 설정합니다.
Sharing Features for RPN and Fast R-CNN
✔ RPN과 Fast R-CNN은 독립적으로 이행되기에 합쳐주는 과정이 필요합니다. 아래의 과정으로 수행된다.
4-Step Alternating Training
(1). Image-pre-trained model로 초기화해 RPN을 학습시킵니다.
(2). 학습된 RPN에서 사용된 proposals을 사용해 detection network인 Fast R-CNN을 학습합니다. Fast R-CNN 역시 Image-pre-trained model로 초기화합니다.
(3). RPN training을 학습된 detection network로 초기화합니다. 단, 공유되고 있는 conv layer은 고정시킨 후, 나머지느 고유한 RPN의 layer만 학습시킵니다.
(4). 공유 conv layer은 고정시킨 후 고유한 Fast R-CNN의 layer만 학습시킵니다.
Reference
