[CV] R-CNN(Rich feature hierarchies for accurate object detection and semantic segmentation) review
[Paper review]

R-CNN
1. Abstract & Introduction
✔ 최근 몇년 간 Object detection performance 분야에서는 PASCAL VOC dateset을 기준으로 평가했습니다. 본 논문에서 제시하는 간단하고 확장가능한 알고리즘으로 VOC-2012에서 53.3%(mAP) 결과를 도출했습니다.
✔ <R-CNN에서 제시하는 2가지>
(1). segment objects를 localize 하기 위해 CNN에 bottom-up region proposals(Selective Search)을 적용.
(2). 라벨링이된 학습 데이터가 부족할 때, Superveised pre-training 과 domain-specifif fine-tuning 의 통해 성능 향샹.
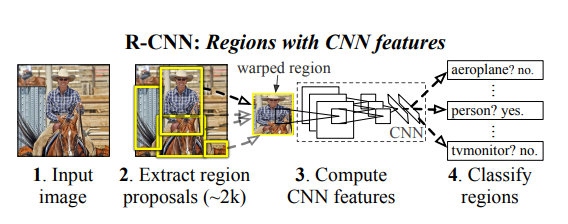
(1). Input 이미지를 받습니다.
(2). 2000개의 bottom-up region proposals을 추출합니다.
(3). 각각의 proposal들의 feature을 CNN을 통해 계산합니다.
(4). class마다 linear SVMs을 사용해 적용해 class를 분류합니다.
✔ 위와 같은 결과를 얻기 위해, 2가지의 problems을 해결해야합니다.
(1). localizing objects with Deep network
: image classification과는 다르게 detection은 localizing object이 필요하다.
- CNN localization problem을 "recognition using regions" 패러다임을 적용해 object detection and semantic segmetaion을 해결할 수 있다. Input image를 2000개의 독립적인 region proposals을 CNN 학습을 통해 고정된 길이의 특징 벡터를 추출한다. 그리고 SVM을 통해 classifes를 진행합니다.
(2). 적은 양의 label 데이터로 high-capacity 모델을 어떻게 학습할 수 있을까?
- 문제해결방안으로는 use unsupervised pre-training, 이후 supervised fine-tuning을 통해 해결할 수 있다. fine-tuning 이후 VOC에서 mAP 54%까지 성취 할 수 있었다.
2. Object detection with R-CNN
✔ 본 object detection system은 3가지 모듈로 이루어져 있습니다.
✔ region proposal을 사용해 독립된 카테고리를 추출합니다. 추출된 자료들은 detector의 candidate이 됩니다.
✔ CNN을 사용해 각 지역에 대한 고정된 길의 feature vector를 추출하는 것 입니다.
✔ linear SVM을 사용해 각 class를 specific 하는 것이다.
2.1 Module design
✔ Region proposals : R-CNN에서는 "selective search" 방식을 사용합니다.
🎈 Selective Search
논문 링크: Selective Search for Object Recognition
- Use the segmented region proposals to generate candidate object locations

✔ Selective Search는 hierachical algorithm으로 물체의 서로다른 크기와 모호한 경계를 해결합니다.
- “Efficient Graph-Based Image Segmentation" 사용해 초기 이미지를 생성합니다. 파랑색 bound-box를 위 사진에서 확인할 수 있습니다.
- 그리디한 알고리즘을 통해 작고 비슷한 region들을 큰 region으로 결합합니다. 즉, 유사도가 높은 영역끼리 합쳐짐을 반복하고, single region이 될 때 까지 반복합니다.
- r(s)와 r(i) 영역이 합쳐진 새로운 영역을 r(t)라 할 때, r(t)의 특징은 모든 픽셀에 다시 접근하여 계산하지 않고 r(s)와 r(i)의 특징값으로 부터 계산합니다. 이런 방법으로 계산하는 시간을 줄일 수 있습니다.
* 자세한 설명은 아래 링크 첨부하겠습니다.
** Selective Search https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=laonple&logNo=220925179894 링크에 자세하게 잘 나와있습니다.
✔ Feature extraction : CNN을 사용해 각각의 4096-차원의 feature vector를 추출했습니다. Features들은 five-conv layers 와 two fc layters를 통해 227 x 227 이미지로 추출되었습니다. Region proposal을 수행하기 위해 우리는 각 region에 대해 CNN에 사용, 호환이 가능하도록 간단한 방법인 warp을 사용합니다. 물론 규격에 맞는 이미지에 bounding box가 들어가면 안됨으로 이미지를 약간 키워 warp를 수행하고 이 때 p=16의 padding 사용합니다.

2.2 Test-time detection
✔ Selective search's fast mode로 2000개의 region propsals 추출 -> Warp -> CNN -> SVM 으로 분류를 진행합니다. 이후 greedy non-maximum suppression을 적용합니다. greedy non-maximum suppression이란 특정 영역이 학습된 임계값보다 큰 선택이된 높은 점수 영역과 겹치는 경우 해당 영역을 거부합니다.
✔ Run-time analysis: 2가지의 특성에서 효율성을 보여줍니다.
(1). 모든 CNN 파라미터는 모든 카테고리를 공유합니다.
(2). CNN을 활용한 feature vectors을 상대적으로 저차원입니다.
추가적으로 오직 feature, SVM weights, non-maximum suppression 사이의 dot products만이 유일한 computation 입니다.
2.3 Training
✔ Supervised pre-training : ILSVRC 2012 classification dataset을 pre-train에 사용했습니다.
✔ Domain-specific fine-tuning : SGD를 이용한 warp된 region proposals만을 사용했습니다. CNN(alexnet)의 마지막 1000-way의 classification을 N+1개로 수정했습니다.(+1은 background 입니다.) 이외 구조는 동일합니다. VOC의 N = 20, ILSVERC 2013의 N = 200으로 지정했고, ground-truth box와 0.5이상의 IoU는 positive, 나머지는 negative로 분류했으며, SGD의 lr= = 0.001로 지정했습니다(1/10의 pre-training rate). SGD iteration에서 uniformly sample 32 positive window and 96 background window로 총 128개의 미니 배치 사이즈를 구성했습니다.
✔ Object category classifiers : 차를 구분하는 binary calssifier를 보면, 명확하게 positive한 이미지를 구분하고, 또한 차와 무관한 배경이미지를 negative로 잘 구분한다. 하지만 부분적으로 차가 보이는 이미지는 클리어하게 구분하지 못하기에, 우리는 validation set의 임계점을 0.3으로 수정했다.
feature들이 추출되고, trainging label을 linear SVM으로 최적했다. 그러나 traing data가 너무 커, 우리는 standard hard negative mining method를 사용했다. hard negative mining은 빠르게 수렴하고, 모든 이미지가 한 번만 통과하면 mAP증가가 멈춥니다. In Appendix B 에서 왜 positive and negative를 구분했는지 , softmax가 아닌 SVM을 선택했는지 등등의 이유가 자세하게 나와있습니다.
- Hard Negative Mining: converges quickly and in pracive mAP stops increasing after only a single pass over all images. A way to balance the positive and negative samples. IoU를 기반으로 negative image를 스코링한 후 Positive 이미지와 balance를 맞춘다.
2.4 Results on PASCAL VOC 2020-12
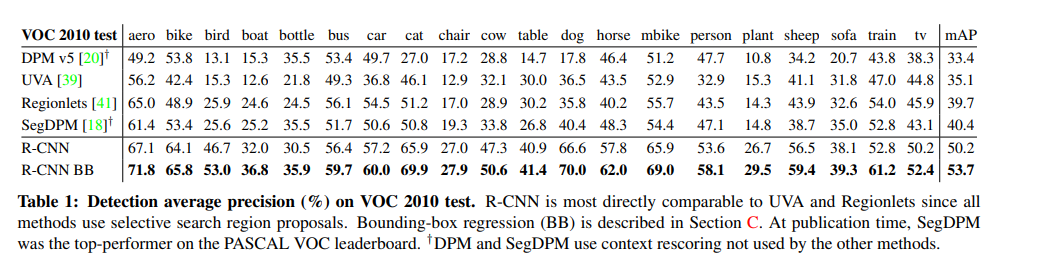
✔ 위 테이블에서 확인해보면, R-CNN과 R-CNN BB에서 가장 높은 mAP를 확인할 수 있습니다. (BB는 Bounding-box regression 입니다.)
2.5 Results on ILSVRC2013 detection
✔ 200-class인 ILSVRC2013 detection dataset을 R-CNN으로 학습했으며, PASCAL VOC와 같은 하이퍼 파라미터와 시스템을 사용했습니다.
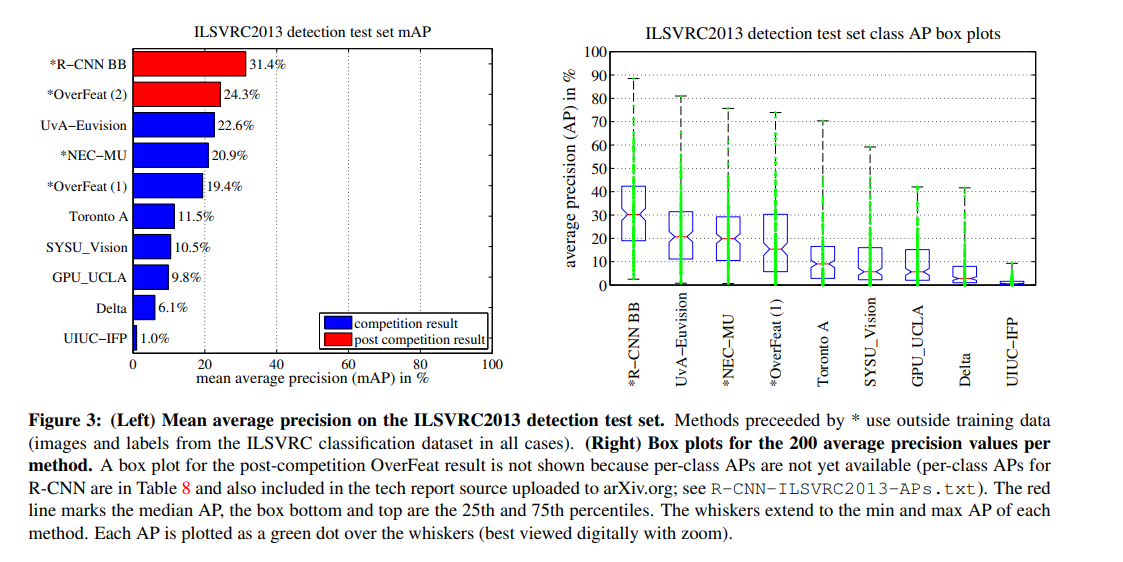
✔ 위 그래프에서 R-CNN BB가 31.4%(mAP)의 test 결과를 확인할 수 있습니다.
3 Visualization, ablation, and modes of error
3.1 Visalizing learned features
✔ first-layer filters의 경우 쉽게 visualized 할 수 있었습니다. 하지만 후속의 layer들의 이미지를 확인하기에는 어려움이 있었습니다. 그래서 간단한 non-parametric 메서드를 사용해 직접적으로 확인할 수 있었습니다.
- 다수의 region proposals의 unit's activations을 계산 -> 정렬 highest to lowest activation으로 -> non-maximum supperssion을 수행 ->display top regions
✔ layer pool5부터 visualize units을 합니다. pool5 feature map은 6 x 6 x 256 = 9216-차원으로 이루어져있습니다. boundary effects를 무시한체 pool5 units은 195 x 195의 수용영역을 가지고 있습니다.

✔ 위의 이미지에서 각각의 row들이 특성을 잘 파악하고 있는 것을 볼 수 있다.
✔ 이를 통해 네트워크는 모양,질감,색 분산 표현들을 결합하여 표현을 배우는 것으로 나타냅니다.
3.2 Ablation studies
✔ Performance layer-by-layer, without fine-tuning:
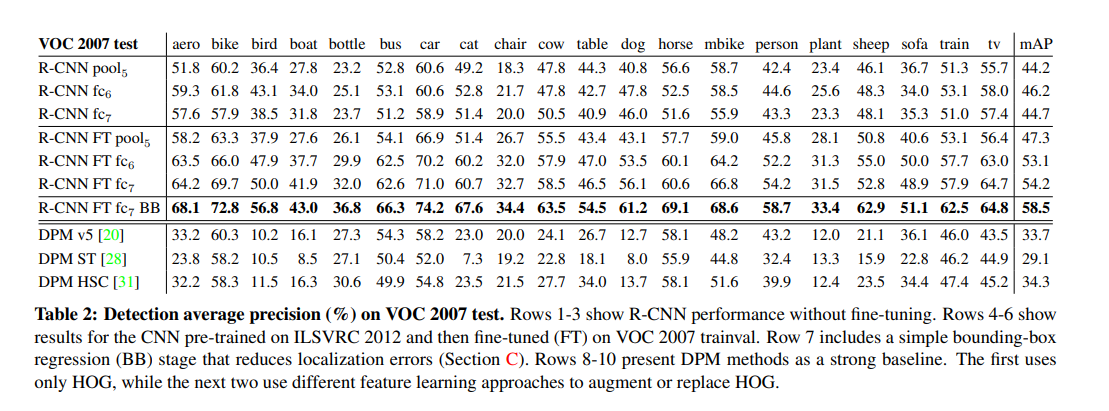
성능에 중요한 layer를 이해하기 위해 fine-tuning 없이 수행 시, fc6 & fc7 또한 비교적 잘 수행되는 것을 볼 수 있습니다. 위의 결과를 보고 conv layer에 중요한 부분이 있다는 사실을 알 수 있었습니다.
✔ Performance layer-by-layer, without fine-tuning: Table 2. 에서 약 8%의 차이를 without fine-tuning과 with fine-tuning 에서 확인 할 수 있습니다.
✔ Comparision to recent feature learning method: 기존의 다른 모델과의 성능 비교를 설명하고 있습니다.. 논문 참고 바랍니다...
3.3 Network architectures
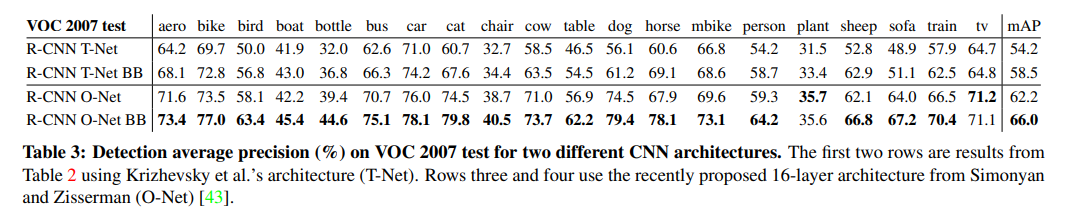
✔ ILSVRC 2014 top performance를 선보인 통칭 VCG를 활용해 새로운 실험을 할 것이다.(VCG = O-net , alexnet = T-net) 위에 표에서 보시다싶이 O-net을 사용한 방법이 66%라는 더 좋은 결과가 나왔습니다. 하지만 약 7배의 더 걸렸습니다.
3.4 Detection error analysis
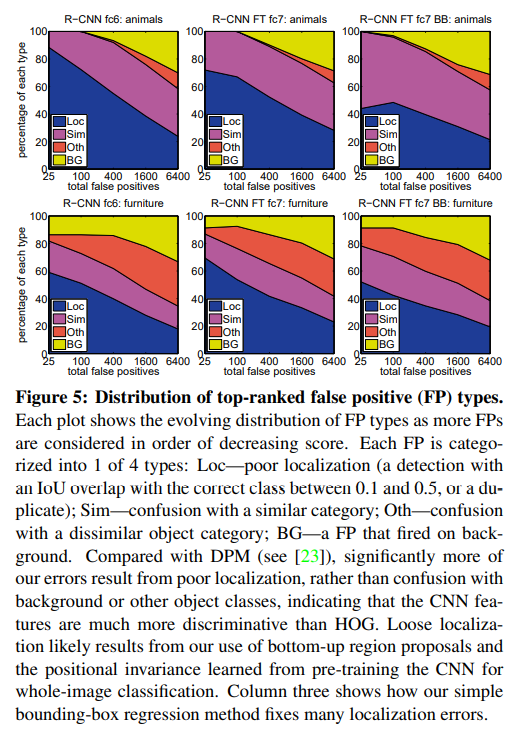
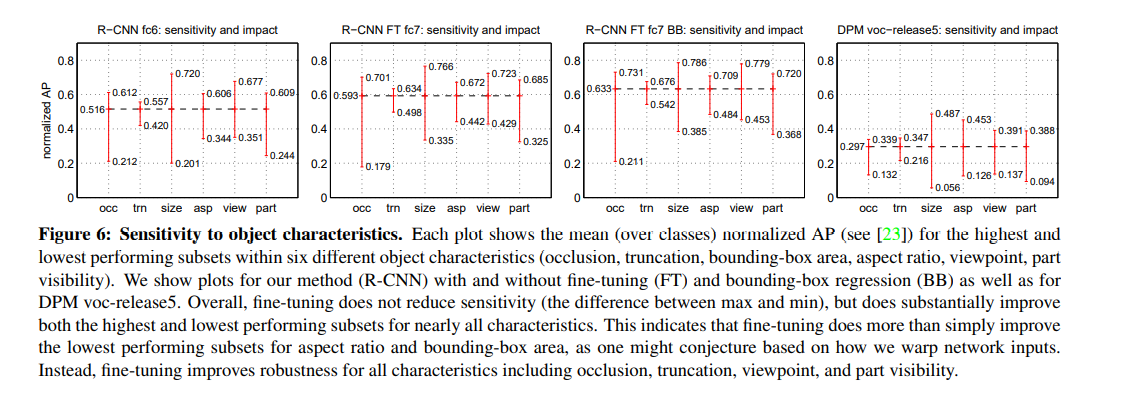
3.5 Bounding-box regression
✔ localization errors 줄이기 위해 simple한 방법을 사용했다. 우리는 pool5 feature들을 train a linear regression model을 사용해 새로운 detection window 를 생성했다. Appendix C.에 자세하게 나와있다.
✔ Appendix C : SVM을 사용해 class-specific detection score을 계산한 후, 새로운 bounding-box를 적용했다. 이 모델은 "DPM"에서 사용된 regression과 비슷하다. 다른점은 위 모델은 DPM과 다르게 CNN을 사용했다는 점이다. 간략하게 각 proposals들의 좌표 및 높이와 넓이, Grounding-truth의 좌표 및 높이와 넓비를 , 특정한 function을 통해 Grounding-truth을 예측치를 측정합니다. 그리고 릿지 회귀를 사용해 파라미터를 계산하고 target값을 측정합니다.
위의 알고리즘은 2가지 중요한점은 (1) regularization은 중요합니다. (2) 아무 proposal들을 선택할 수 없어서 IoU overlap을 최대하는 것으로 선택했고, 임계값은 0.6 입니다.
- 수식에 관련된 부분은 논문 참고 부탁드리겠습니다.
** 4.The ILSVRC2013 detection dataset/ 5.Semantic segmentation 의 경우 위의 R-CNN ILSVR2013 dataset과 segmaetation의 상황에 맞춰 적용하고 테스트한 문단입니다. 각 특징에 따라 조금의 변동이 있지만 기본 골자는 비슷하다고 생각합니다. 자세한 내용은 논문 참고 부탁드리겠습니다.
6. Conclusion
✔ 최근, Object detection 성능은 침채되어 있었습니다. 본 논문은 PASCAL VOC 2012에서 상대적으로 30% 이상의 더 좋은 결과를 도출했습니다. 2가지의 insight를 찾을 수 있습니다.
(1). localize and segment objects에 CNN을 적용했다는 것 입니다.
(2). pre-train network와 fine-tuning으로 부족한 train-data로 높은 성능 향상을 이뤄냈다.
</>
Reference
