
👨🏫 본 리뷰는 cs231n-2017 강의를 바탕으로 진행했습니다.
📌 이번 시간에는 강의 제목과 같이 Loss Functions, Optimization 방법에 대해 소개합니다.
What is Loss Functions and Optimization?
📌 Loss Function은 train data score에 대한 불만족을 정량화한 것입니다. 간단하게 원래 정답과 예측한 정답의 차이를 수치화 시킨것입니다.
📌 Optimization이란 효과적으로 Loss Function을 최소화시키는 방법입니다. 즉, 오류를 최소화 한다고 생각하면 됩니다.
Loss Function
📌 loss function은 현재 사용하는 classifier가 얼마나 좋은 classifier인지 말해줍니다. loss라는 이름과 같이 loss를 최소하는 것이 우리의 목표이지만, train loss가 아닌 test loss를 최소하는 것을 목적으로 진행해야합니다.

** 위의 사진은 loss fuction의 간단한 예시입니다.(=image, =label, =에 대한 loss, =데이터의 수)
Multiclass SVM loss

📌 위의 고양이, 자동차, 개구리 아래의 숫자는 "" score 이고, 오른쪽의 red box가 SVM loss의 수식입니다. 저희 이제부터 이 수식에 대해 뜯어보고 이해 할 예정입니다.
📌 하나씩 접근해보겠습니다. 을 의미합니다. 즉 를 의미합니다. 는 정답이 아닌 값들입니다. 즉, 고양이의 열에서 본다면 car, frog의 결과 값입니다. 는 정답인 class의 예측결과입니다. 즉, 고양이의 열에서 본다면 고양이로 예측한 결과 값입니다. 위의 것 바탕으로 수식을 해석하면 간단합니다. 정답인 class의 예측 결과 값이 정답이 아닌 결과 값 + 1 보다 크다면 0이고 그렇지 않으면 정답인 class의 예측 결과 값이 정답이 아닌 결과 값 + 1 차이를 loss로 합니다.

📌 위의 그래프가 SVM loss의 그래프입니다. 경첩과 비슷하다고 해 "Hinge loss"라고도 말합니다. SVM loss는 값이 커지면 커질수록 좋지 않은 모델이라고 할 수 있습니다. 반대로 loss 값 0에 가까워 진다면 좋은 모델이라고도 할 수 있습니다. (단, test loss에 대해서)
📌 이해를 돕기 위해 위의 예제의 SVM loss를 구해보겠습니다. 고양이가 정답인 열의 loss를 구해보겠습니다. 의 결과를 얻을 수 있습니다. 이와 같은 형식으로 각각의 loss를 구하고 더해서 평균을 구하면 의 결과가 나옵니다. 예제를 하나씩 따라하시면 금방 이해하실 수 있을겁니다. 이제 몇 가지 질문을 통해 SVM loss의 특징에 대해 알아보겠습니다.

Q: What happens to loss if car scores change a bit?
📌 A: car score이 조금 변해도 loss는 그대로일 겁니다. car score와 다른 score의 점수 차가 크기에 변함 없을 겁니다.
Q: What is the min/max possible loss?
📌 A: min = 0, max =
Q: At initialization W is small so all . What is the loss?
📌 A: Class Num - 1
Q: What if the sum was over all classes(including j = y_i)
📌 A: Loss + 1
Q: What if we user mean instead of sum?
📌 A: 값이 scale되는 것뿐 의미는 달라지지 않습니다.
Q: What if we used ?
📌 A: 일반적으로 "squaerd Hinge loss"라고 부르고, 위의 방법은 만약 매우 안좋은 결과를 제곱하면 더 많이 안좋아질 겁니다. 즉, 안좋은 쪽을 더 많이 신경쓰게 될겁니다.
Regularization
 📌 기본적인 모델 학습은 train data로 이뤄집니다. 우리는 loss를 줄일려고 노력할 것이고, loss를 최소화 한다면 좋은 모델이라고 할 수 있을까요? 아닙니다. 우리의 목적은 test data loss의 최소화 입니다. 즉, 학습되지 않는 데이터의 loss를 최소화 해야합니다. 위의 train data를 최소화하면 위의 파란색 선과 같이 모든 원의 점을 정확히 예측하는 그래프가 그려질겁니다. 파란색 선의 그래프는 train data는 정확하게 예측하겠지만, test data는 정확하게 예측하지 못합니다. 우리는 일반적으로 이런 상황을 "Overfitting"이라고 이야기합니다.(초로색 네모가 test data입니다.)
📌 기본적인 모델 학습은 train data로 이뤄집니다. 우리는 loss를 줄일려고 노력할 것이고, loss를 최소화 한다면 좋은 모델이라고 할 수 있을까요? 아닙니다. 우리의 목적은 test data loss의 최소화 입니다. 즉, 학습되지 않는 데이터의 loss를 최소화 해야합니다. 위의 train data를 최소화하면 위의 파란색 선과 같이 모든 원의 점을 정확히 예측하는 그래프가 그려질겁니다. 파란색 선의 그래프는 train data는 정확하게 예측하겠지만, test data는 정확하게 예측하지 못합니다. 우리는 일반적으로 이런 상황을 "Overfitting"이라고 이야기합니다.(초로색 네모가 test data입니다.)
📌 우리의 모델은 Overfitting 되었습니다. 우리는 우리의 모델을 조금 더 일반적인 모델로 만들어야합니다. 위의 녹색의 선 그래프처럼 만들어야합니다. 그럴때 사용하는 것이 "Regularization" 입니다. "Regularization"의 수식은 위의 입니다. "Regularization"의 역활은 모델의 복잡함을 제한합니다. 조금 더 구체적으로 모델이 training dataset에 완벽하게 fit 하지 못하도록 제한하는 것 입니다.

📌 위의 사진에서 볼 수 있듯이 "Regularization"에는 다양한 방법들이 있습니다. 오늘은 L2, L1 "Regularization"을 살펴볼 예정입니다. L2는 와 같이 제곱의 형태로 나타내며, L1은 절대 값의 형태를 나타냅니다. L2의 경우 모든 w의 요소가 골고루 영향을 미치게 하고 싶을 때 사용합니다. L1의 경우 sparse한 solution을 다룹니다. L1이 "좋지 않다"라고 느끼고 측정하는 것은 "0"이 아닌 요소들의 숫자입니다. L2의 경우에는 w의 요소가 전체적으로 퍼저있을 때 "덜 복잡하다"라고 느낍니다.
Softmax Classifier(Multinomial Logistic Regression)
📌 SVM loss의 경우 score의 의미를 다루지 않습니다. 정답 클래스의 값이 정답의 클래스의 값보다 일정 수준 높으면 loss는 0입니다. Softmax fucntion의 장점은 확률 분포를 알 수 있습니다.

📌 우리는 확률 값을 원하기 때문에, 지수함수의 형태로 나타냅니다. 형태는 단조 증가 함수이자 최대화가 간편하기에 치환한 것입니다. 또한 우리는 loss 즉, 손실을 찾고있기에 음수를 곱해줍니다. 아래 사진에서 예시를 볼 수 있습니다.
 📌 위의 사진을 보면 처음에는 지수 함수의 형태로 다음에는 표준화를 진행합니다. 그리고 고양이에 해당되는 값의 loss값을 찾습니다.
📌 위의 사진을 보면 처음에는 지수 함수의 형태로 다음에는 표준화를 진행합니다. 그리고 고양이에 해당되는 값의 loss값을 찾습니다.
Q: What is the min/max possible loss_i?
📌 A: max = 0, min =
Q: At initialization W is small so all . What is the loss?
📌 A:
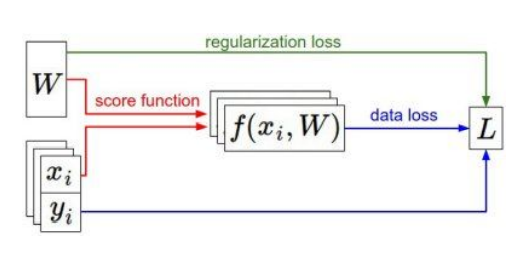
Optimization
📌 우리는 어떻게 가장 좋은 W를 찾을 수 있을까요??? 바로 이 Optimization을 통해 찾을 수 있습니다.
Gradient Descent
 📌 Gradient Descent을 사용해 W(가중치)를 최적화 할 수 있습니다. Gradient는 기울기를 말하는 것이며, Descent는 내려간다는 의미를 가지고 있습니다.
📌 Gradient Descent을 사용해 W(가중치)를 최적화 할 수 있습니다. Gradient는 기울기를 말하는 것이며, Descent는 내려간다는 의미를 가지고 있습니다.
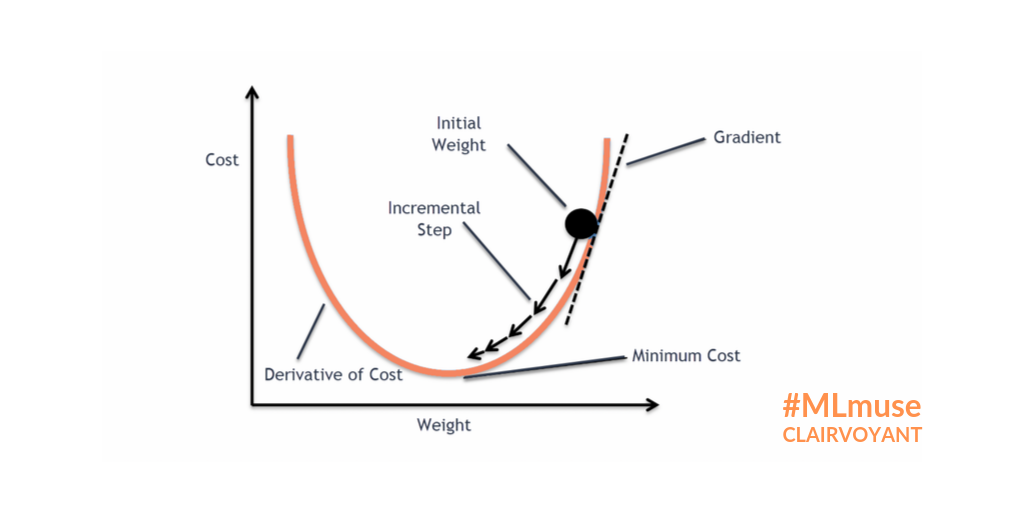
📌 Gradient Descent는 미분을 사용해 계산하는 방식입니다. 우리는 벡터 형태의 가중치를 가지고 있기에 각각의 편미분을 사용합니다. 우리는 미분값과 learning rate(학습률)을 사용해 최종적으로 위의 그래프에서 Minimun cost가 되는지점까지 학습합니다. learning rate(학습률)은 하이퍼파라미터로서 사용자가 직접 정해줘야하는 파라미터입니다. learning rate(학습률)은 학습에 많은 영향을 주기에 신중하게 선택해야합니다.
Stochastic Gradient Descent
 📌 Stochastic Gradient Descent이란 직역하면 확률적 경사하강법이라고 말할 수 있습니다. 말 그래도 모든 데이터를 사용하기엔 너무 비효율적이기에, 확률적으로 mini-batch라는 것을 사용해 학습하는 것입니다. 한 번 학습에 mini-batch만큼의 학습을 하며, 일반적으로 32/64/125..로 설정합니다.
📌 Stochastic Gradient Descent이란 직역하면 확률적 경사하강법이라고 말할 수 있습니다. 말 그래도 모든 데이터를 사용하기엔 너무 비효율적이기에, 확률적으로 mini-batch라는 것을 사용해 학습하는 것입니다. 한 번 학습에 mini-batch만큼의 학습을 하며, 일반적으로 32/64/125..로 설정합니다.
