
👨🏫 본 리뷰는 cs231n-2017 강의를 바탕으로 진행했습니다.
Overview
-
One time setup
- activation functions
- preprocessing
- weight initialization
- regularization
- gradient checking
-
Trainging dynamics
- babysitting the learning process
- paprameter updates
- hyperparameter optimization
-
Evaluation
- model ensembles
Activation Functions
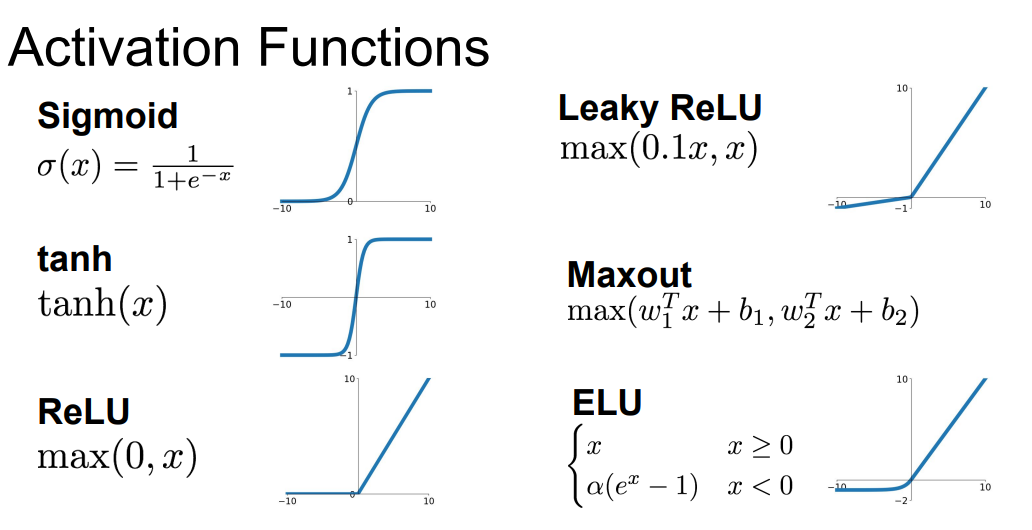
📌 지금까지 많은 Activation functions을 봤었습니다. 오늘은 각각의 Activation functions의 역활과 정의에 대해서 살펴보겠습니다.

📌 시그모이드 함수를 보면, 위의 그래프처럼 0~1사이의 값을 가집니다. 시그모이드 함수에는 몇 가지 문제가 존재합니다.
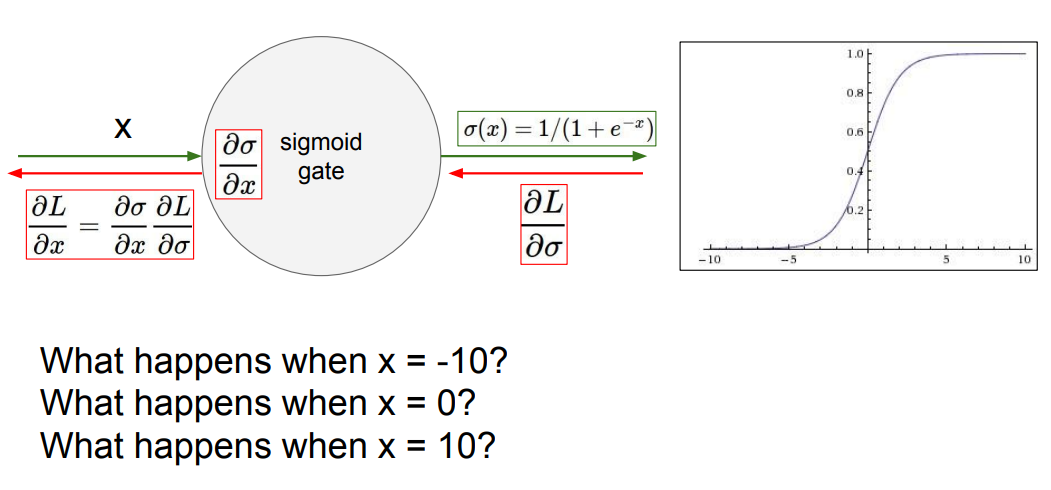
📌 문제점 1. 뉴런이 포화되면 gradinet를 죽일겁니다.
📌 만약 X가 -10, 0, 10이면 어떻게 될까요? -10이면 0에 가깝게 수렴할 것입니다. 또한 chain rule로 인해 gradient들이 0에 가깝게 됩니다. 즉 gradient가 죽게 됩니다. 10일떄도 동일한 현상이 일어납니다. 0일때는 위의 그레프에서 확인할 수 있듰이, 0.5의 값을 가지며 아무 이상 없을 겁니다.

📌 문제점 2. 시그모이드 함수의 결과가 zero-center가 아니라는 것입니다.
📌 시그모이드 함수는 zero-center가 아니기 때문에 항상 양수이거나 음수일 것입니다. 그렇다면 위의 빨간선처럼 gradinet가 특정 방향으로만 움직이기 때문에 효율적이지 못합니다. 즉, 파란선처럼 움직일 수 없다는 것이죠.
📌 문제점 3. exp()연산이 비싸다는 점입니다.

📌 두번째 activation function으로 tanh(x) 함수입니다. 이는 시그모이드 함수와 다르게 -1 ~ 1사이의 값을 가집니다. 이는 즉 tanh는 zero-center하다는 것입니다.
📌 하지만 역시나 그래프를 보시면 포화상태에서 gradient가 죽는 것을 볼 수 있습니다.
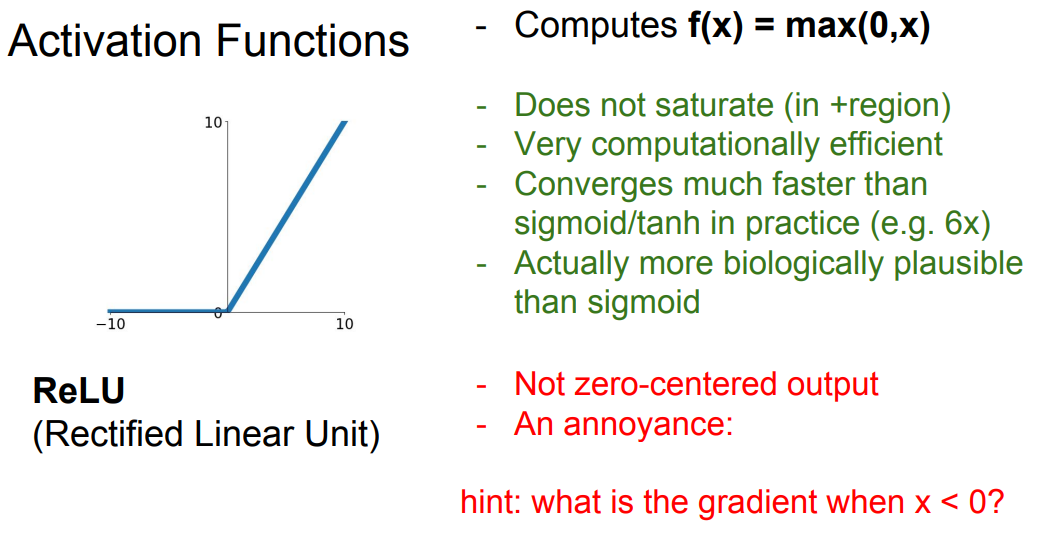
📌 위의 문제들을 해결한 방법론으로 ReLU 함수가 있습니다. ReLU 함수는 두 선형함수의 합이라고 생각할 수 있습니다. ReLU는 양수인 지역에서는 포화가 되지 않습니다. ReLU는 비싸지 않습니다. 또한 다른 함수들보다 수렴이 빠르게 됩니다.
📌 하지만 ReLU 역시 0이하의 값들은 전부 0으로 수렴합니다. 즉, 절반의 gradient는 죽습니다. 또한 역시나 zero-center의 결과를 나타내지 않습니다.
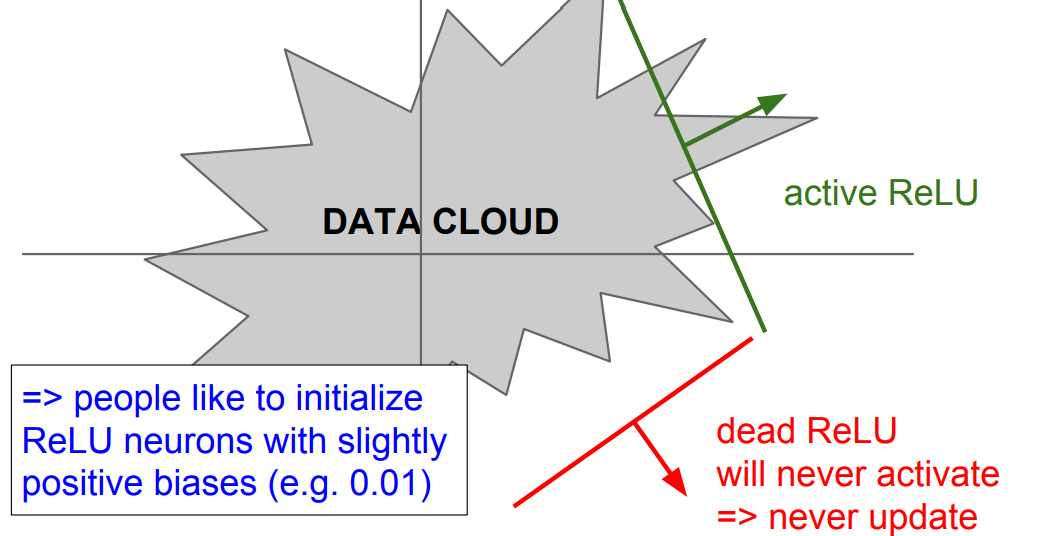
📌 위의 training set(DATA CLOUD)의 초평면에서 보면 ReLU 함수는 빨간색의 방향으로는 활성화 할 수 없습니다.

📌 이를 보완하기 위한 다양한 ReLU 패밀리들이 나오게 됩니다. 먼저 Leaky ReLU는 위의 그래프와 같이 죽지 않습니다. 또한 Parametric Rectifier의 경우 계수를 파라미터처럼 컨트롤 할 수 있습니다.

📌 ELU는 ReLU와 Leaky ReLU의 사이라고 쉽게 이야기할 수 있습니다. ELU는 기존의 dying ReLU 현상을 방지하며, 또한 거의 zero-center에 가깝게 존재합니다. 한 마디로 ReLU의 장점만 모아놓은 함수입니다. 하지만 유일한 단점으로 exp()연산을 수행해야한다는 점입니다.

📌 Maxout은 ReLU와 Leaky ReLU를 일반화 한것이라고 생각할 수 있습니다. 죽지않고 포화하지 않습니다. 하지만 위의 식을 보면 파라미터를 두번 사용하기 때문에 연산량이 많이 늘어납니다.

👨🏫 결론적으로 Activation Fucntion은 ReLU 함수를 사용하면 됩니다.
Data Preprocessing
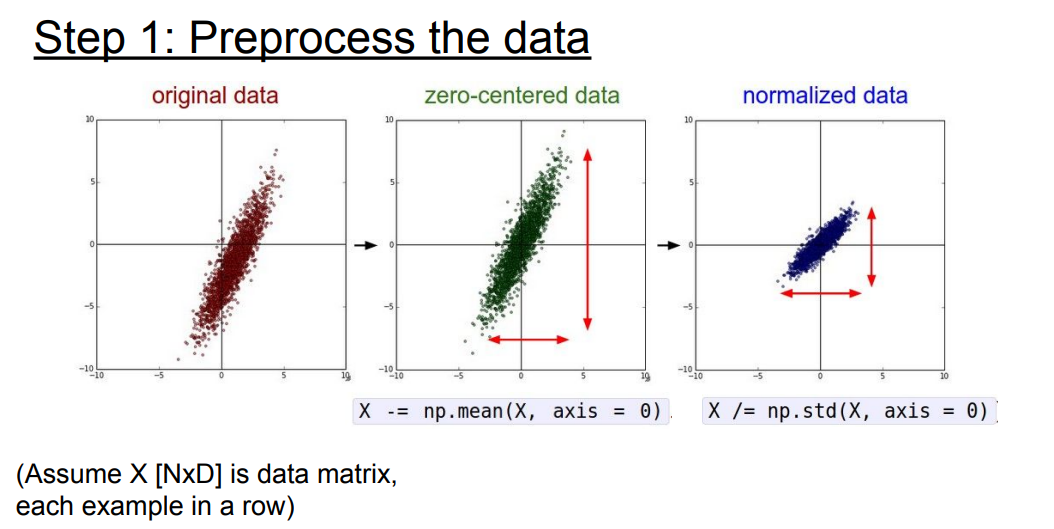
📌 이미지의 관한 전처리는 일반적으로 zero-centered만 수행한다고 합니다. 따른 표준화, PCA, 화이트닝 등이 존재하지만 일반적으로 CNN 계열은 zero-centered만 수행합니다.

📌 이미지의 경우 기본적으로 범위가 정해져 있기 때문에 zero-centered만 수행한다는 것같습니다.
Weight Initialization
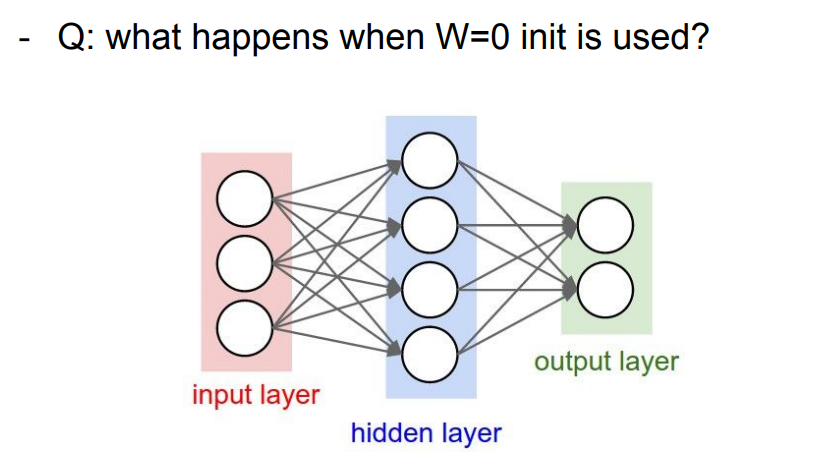
📌 만약 W=0이면 어떻게 될까요? 모든 뉴런의 값이 전부 똑같을 것입니다. 즉, 우리는 Weight를 적당한 방법으로 초기화 시켜줘야합니다.

📌 먼저 ~ Gaussian(0, 0.01) * 0.01로 초기화 시켜줍니다.
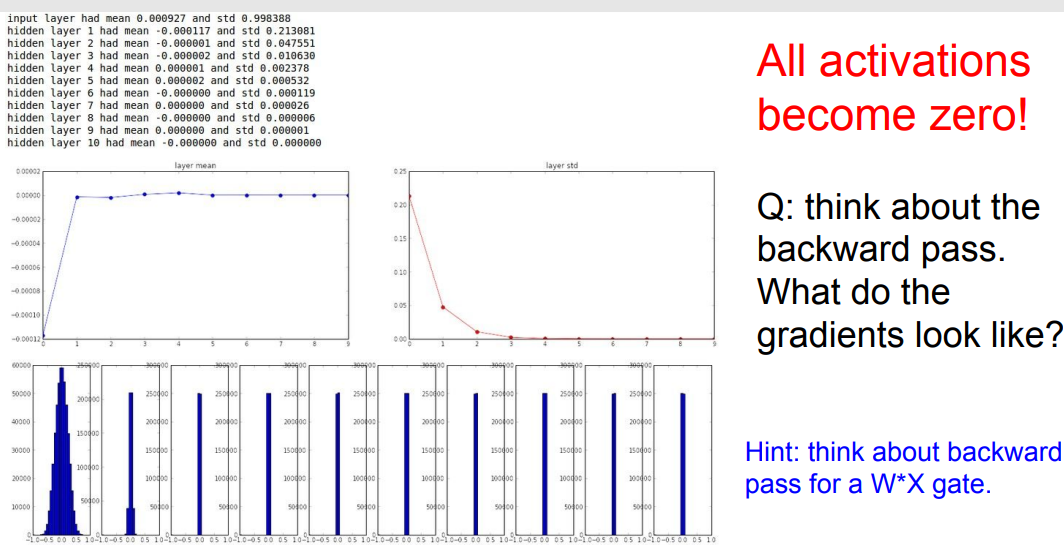
📌 작은 수로 초기화 했습니다. 결과적으로 위의 그래프를 보면 activation이 0으로 수렴하는 것을 볼 수 있습니다. smell networks에서는 괜찮을 수 있어도 깊어지면 질수록 0으로 수렴할 것입니다.
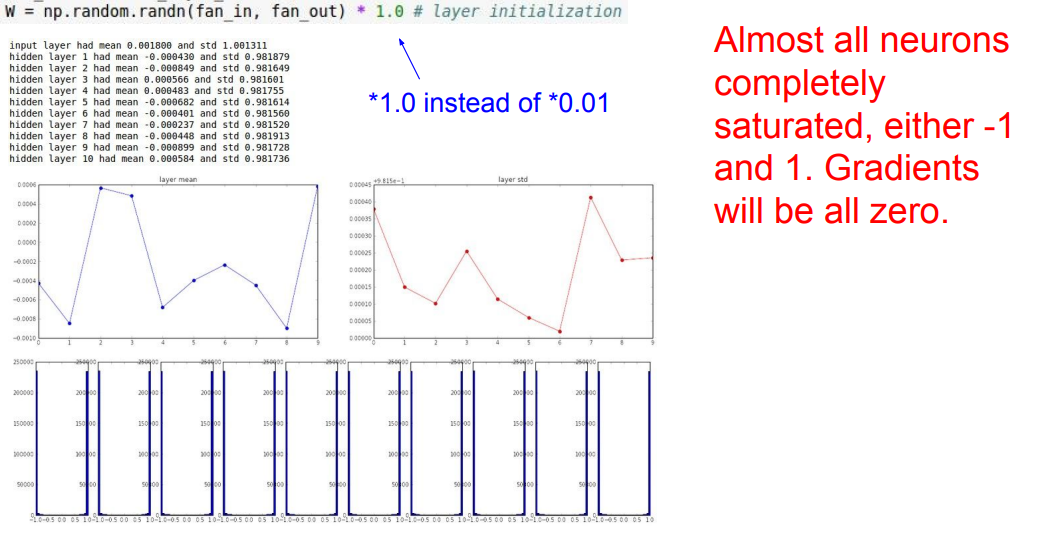
📌 위의 그래프처럼 1.0을 대신 곱해주면, 위의 그래프와 같이 1, -1로 포화되는 것을 볼 수 있고, gradient는 결국 0이 될 것입니다.
📌 위의 결과를 보고 이야기 할 수 있는 건, 결국 Weight 초기화 또한 고민해봐야할 문제이라는 것입니다. 하지만 누군가 미리 좋은 솔루션을 제공해줍니다.
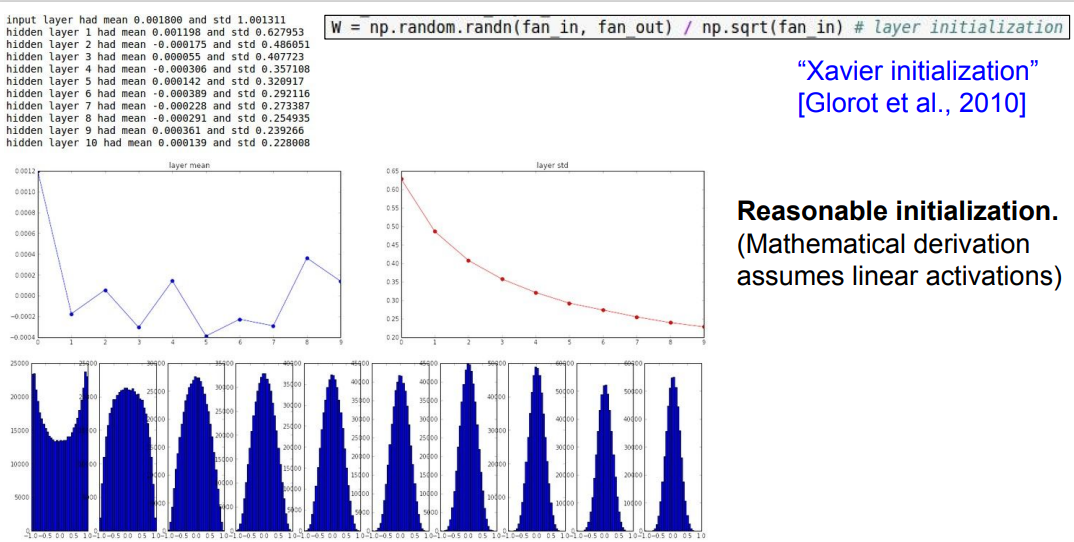
📌 "Xavier" 초기화 방법입니다. 위의 식을 보시면 가우시안 분포에 입력의 수를 나눠주는 것을 볼 수 있습니다. 즉, 입출력의 분산을 막아줍니다. 조금 더 직관적으로 Input의 수가 작으면 더 작은 값으로 나누고 조금 더 큰 값을 얻습니다. 작은 입력의 수가 가중치와 곱해지기 때문에, 가중치가 더 커야만 출력의 분산만큼 큰 값을 얻을 수 있습니다.
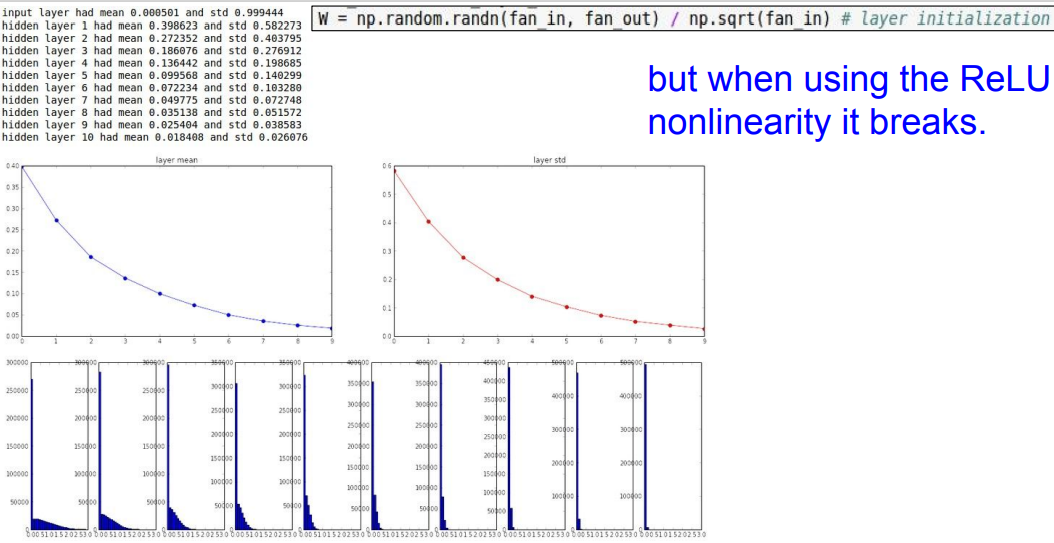
📌 하지만 ReLU 함수를 사용할 때에는 출력의 절반이 죽기 때문에, 분포가 0으로 수렴하는 것을 볼 수 있습니다.
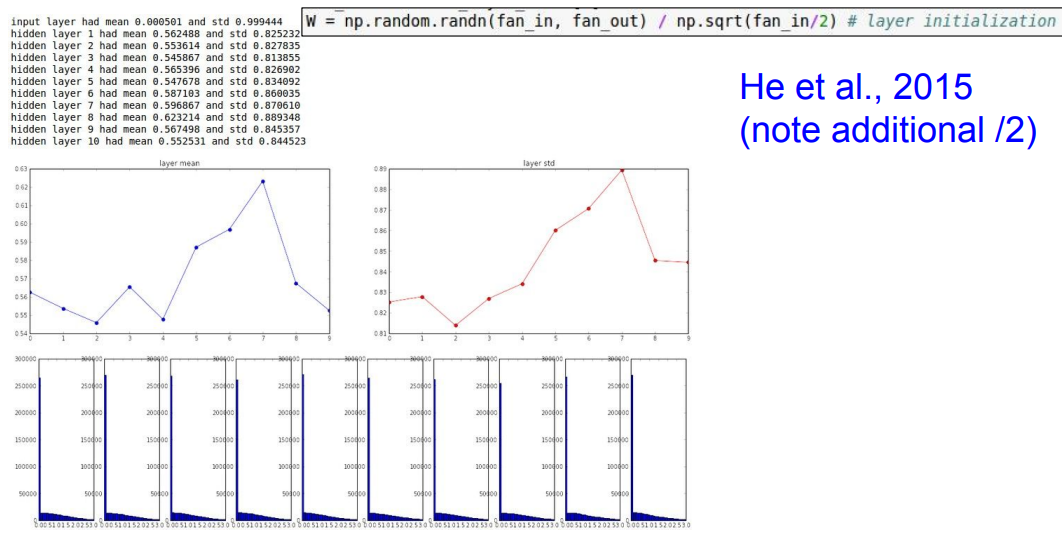
📌 위의 대한 해결책으로 입력의 수를 절반으로 나눠줌으로써 해결해줍니다.
Batch Normalization

📌 Batch Normalization(BN)은 각각의 차원읜 unit gaussain으로 바꿔줍니다.

📌 위의 그림 처럼 각 feature마다 평균을 구해 Normalize를 진행합니다.
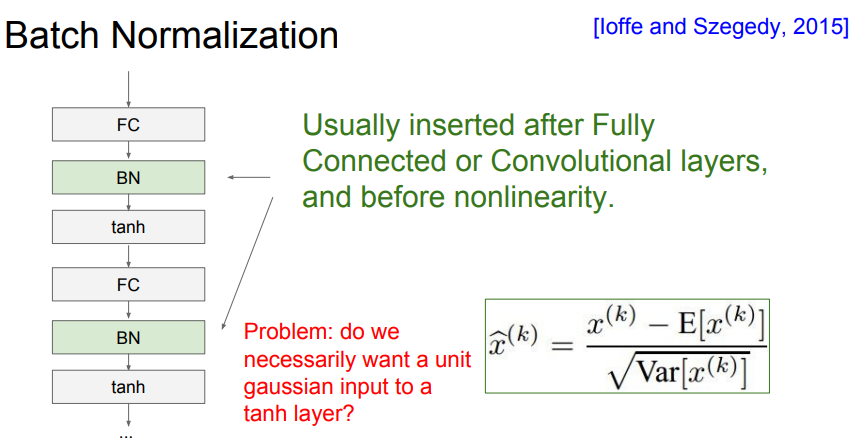
📌 BN은 위의 같이 FC layer나 Conv layer 이후에 사용됩니다.(activation function 전에) 또한 Conv layer의 경우에는 각각의 activation map마다 평균과 분산을 구합니다.
📌 하지만 위의 방법은 모든 포화(saturation)을 방지한다. 하지만 우리의 목적은 모든 포화(saturation)막는 것 보다는 컨트롤하고 싶다.
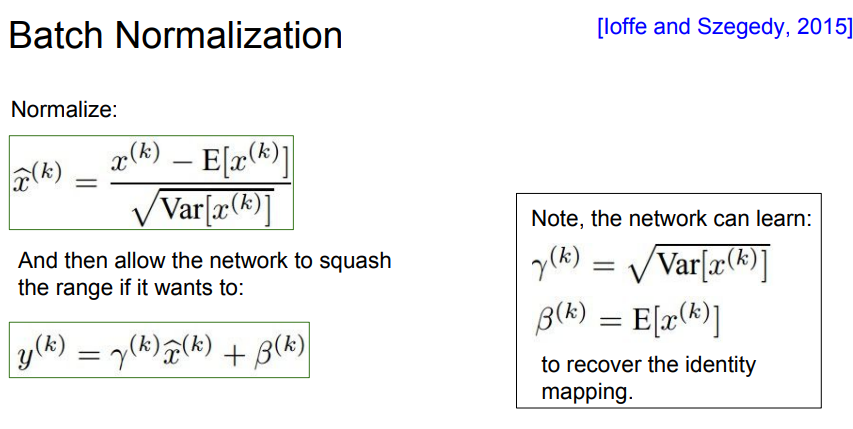
📌 그래서 (scale)과 (shift)를 사용해 컨트롤 할 수 있습니다. 극단적으로 위의 예시와 같이 (scale)과 (shift)를 위와 같이 적용하면 identity mapping이 됩니다.

📌 전체적으로 학습 진행 과정을 보여주고 있습니다. 또한 테스트시 학습을 진행하지 않고 train시 학습했던 파라미터의 평균과 분산을 사용한다.
Babysitting the Learning Process
- Step 1: Preprocess the data
- Step 2: Choose the architecture
Step 1: Preprocess the data
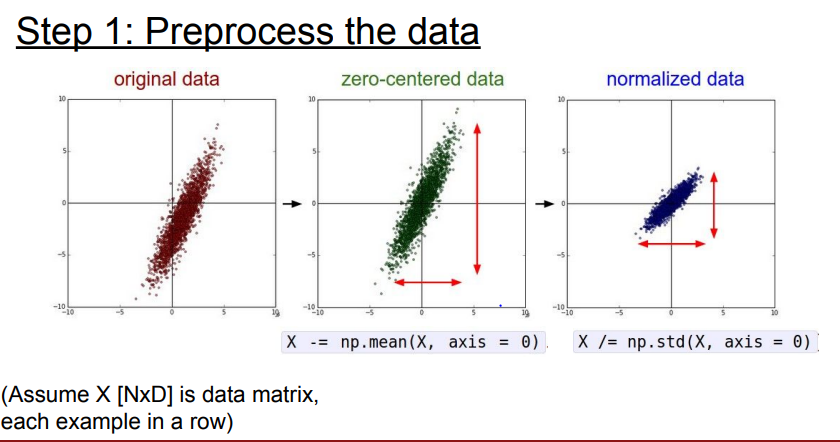
📌 데이터 전처리는 위에서 언급했듯이 간단하게 zero-centered만 진행합니다.
Step 2: Choost the architecture
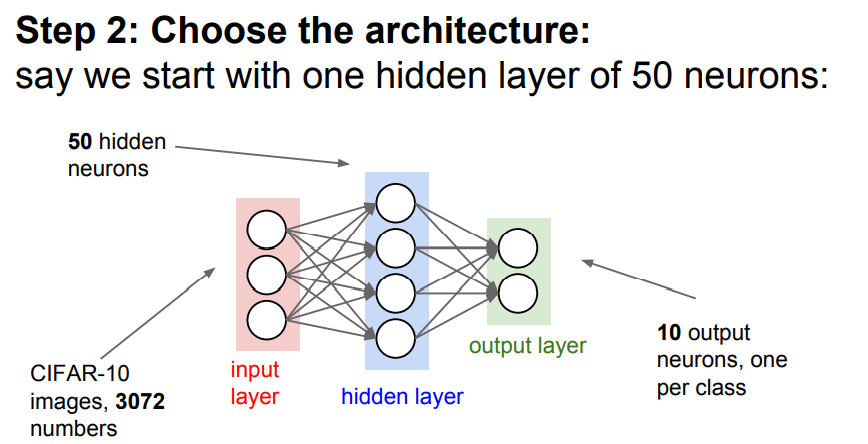
📌 CIFAR-10 3072 images들을 Input으로 50개의 hidden neurons과 10개의 ouptut class 로 구성되어 있습니다.
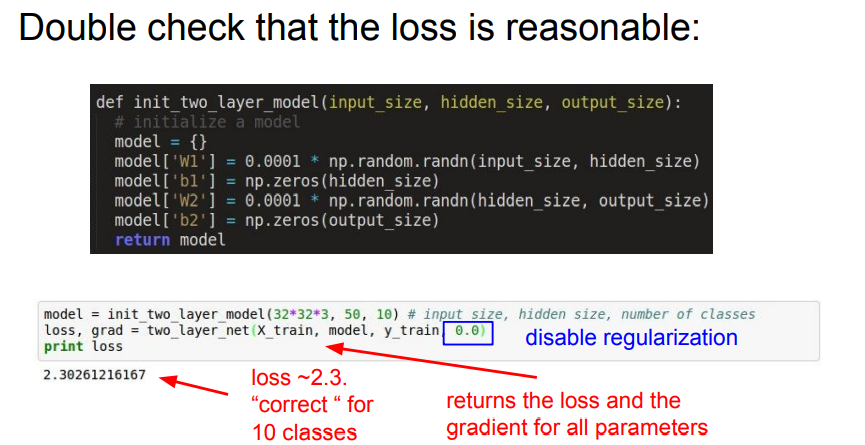
📌 먼저 어떤 Loss를 사용할 것인지 생각합니다. 위의 예시에서는 가중치가 매우 작은 수로 이뤄져 있는 것을 볼 수 있습니다. 즉, 가중치가 작을때 Softmax classifier의 Loss는 negative log likelihood를 사용해야합니다. 위의 식에서는 정규화는 적용하지 않고 계산했을때 2.3026.. 라는 적당한 loss가 나옵니다.
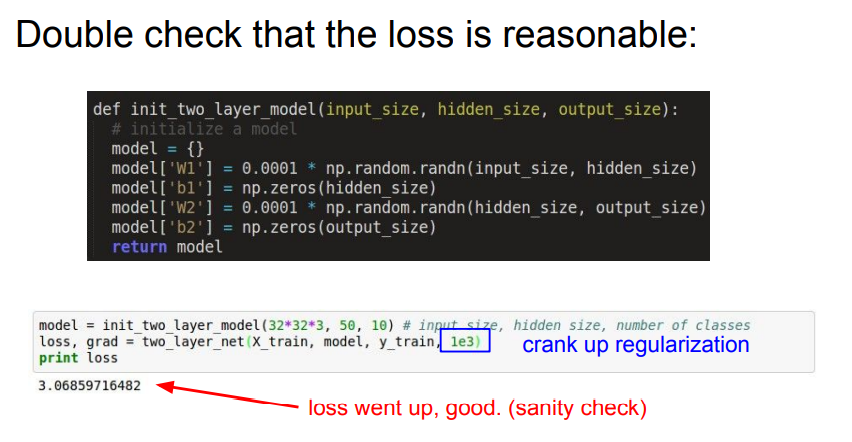
📌 이후 1e3의 정규화 계수를 추가해 진행했을 때, 3.06.. 좀 더 높은 loss를 확인할 수 있습니다.

📌 또한 모델을 테스트할 시에는 매우 일부의 데이터셋을 가지고 실험합니다. 즉, 구성한대로 잘 동작하는지 확인하는 작업입니다. 위의 코드에서는 20개의 CIFAR-10 데이터와 정규화는 사용하지 않고, vanilla SGD를 사용합니다. 적은 수의 예시에서는 overfit 되는것이 당연하고, 그렇게 되어야 정상입니다.
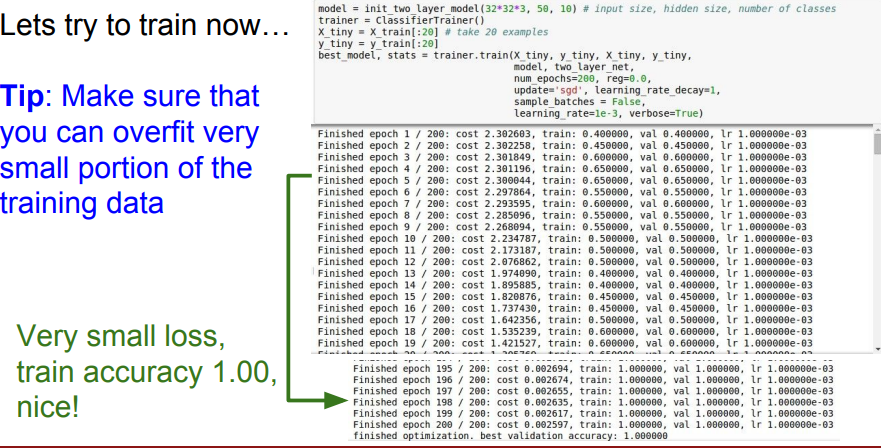
📌 위에 사진과 같이 잘 fitting 되는 것을 볼 수 있습니다.
📌 이제는 loss를 줄이는 약간의 정규화와 learning rate 찾을 겁니다. 특히나 learning rate의 경우에는 매우 중요한 하이퍼파라미터 입니다. 너무 작으면 학습이 잘 일어나지 않을 겁니다. 또한 너무 크면 발산하거나 수렴하지 못하기에 적당한 값으로 학습해야합니다. 일반적으로 [1e-3 ... 1e-5]라고 말할 수 있지만, 분명한건 구성한 모델에 따라 상이할 것입니다.

Hyperparameter Optimization

📌 Hyperparameter Optimization 중 역시 가장 대표적인 cross-validation을 사용합니다. 첫 스테이지에서는 few epochs과 대략적인 파라미터로 찾으며, 두번째 스테이지에서는 첫 스테이지의 실험을 바탕으로 구체적인 파라미터를 찾습니다. 또한 일반적으로 cost가 3배이상 뛴다면 발산하다고 생각할 수 있습니다.
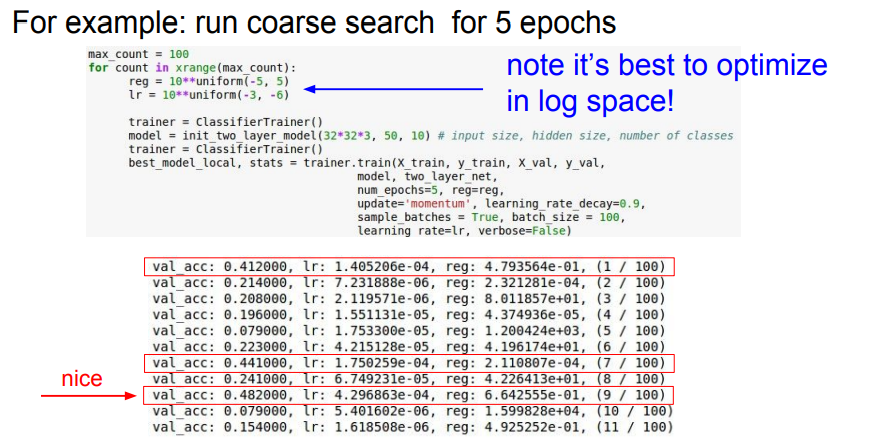
📌 일반적으로 lr이나 reg는 지수부분을 컨트롤합니다. 위의 결과에서 가장 좋은 결과를 찾을 수 있습니다.
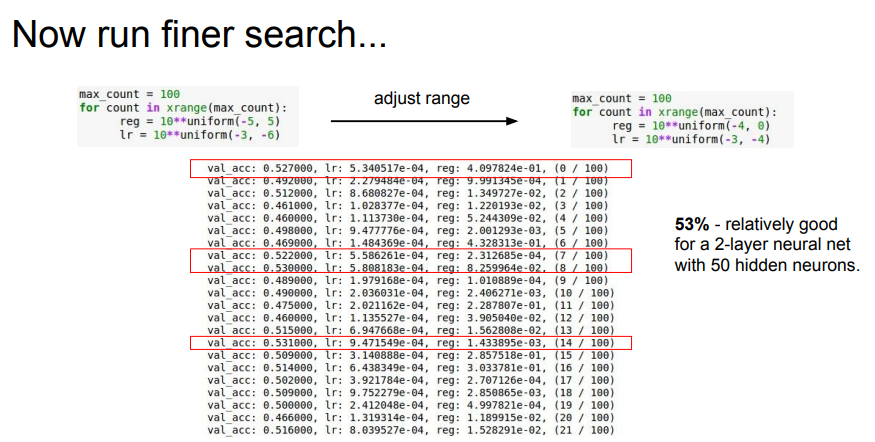
📌 결과를 바탕으로 구체적인 범위를 찾아 다시 테스트합니다.
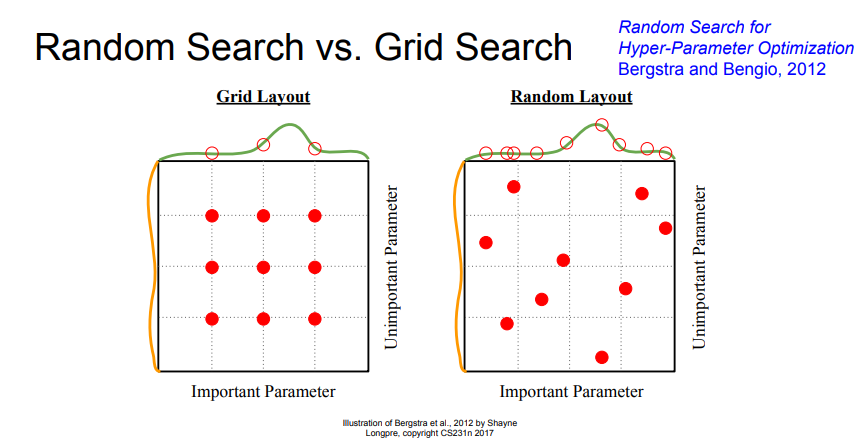
📌 하아퍼 파라미터를 찾는 방법 중에는 위와 같이 Grid search 또는 Random search 방법을 사용할 수 있습니다. 위에서 볼 수 있듯이 Grid search는 그리드하게 선택하기에 최적점을 찾지 못할 가능성이 있지만, Random search는 특정 범위에서 랜덤으로 찾기 때문에 최적점을 찾을 가능성이 더 높습니다.

📌 이외에도 다양한 하이퍼 파라미터들이 존재하지만 나중에 더 학습한다고 합니다.

📌 결과적으로 최적의 하이퍼파라미터를 찾기 위해선 위와 같이 많은 시도를 해봐야한다고 합니다.
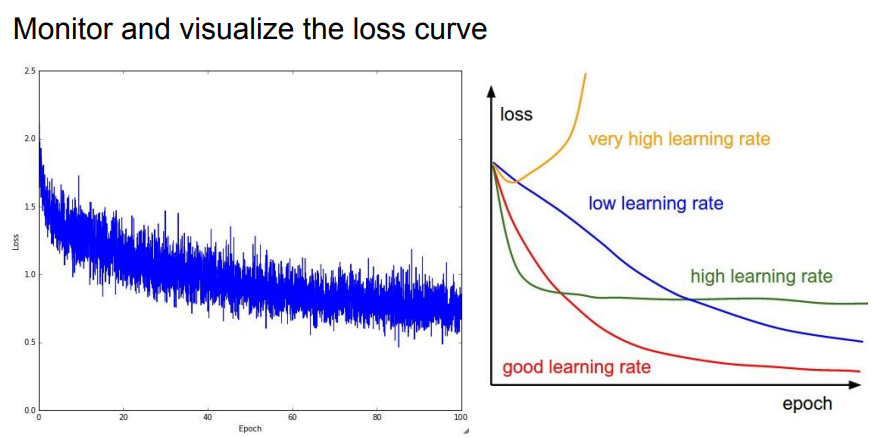
📌 첫번째 그래프에서는 learning rate에 따른 loss의 분포를 확인 할 수 있습니다. 우리는 결과적으로 빨간색선과 같은 learning rate을 찾을려고 노력해야합니다.
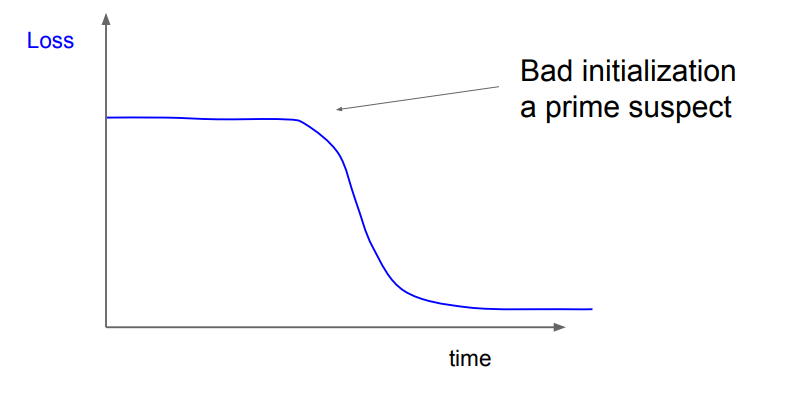
📌 두번째 그래프와 같은 그래프가 나온다면 초기화 값이 생각해봐야합니다. 초반에 학습이 잘 안된다고 이야기 할 수 있습니다.
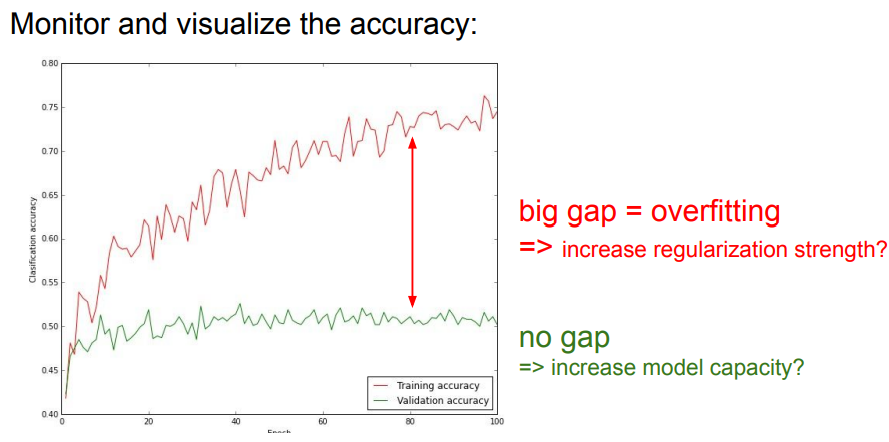
📌 마지막으로 train accurracy 와 Validation accurracy를 비교할 때는 두 그래프의 gap을 확인해 파라미터를 수정할 수 있습니다.

