[CV] ImageNet Classification with Convolutional Neural Networks(AlexNet) review
[Paper review]

😎 오늘은 CNN의 가장 기본중에 기본인 AlexNet 논문리뷰를 진행하겠습니다. 첫 리뷰이기에 많이 부족하지만, AlexNet은 어렵지 않은 논문이었기에 읽을 수 있었다고 생각합니다.
논문 링크: ImageNet Classification with Convolutional Neural Networks
AlexNet
- ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)의 2012년 대회에서 AlexNet이 Top 5 test error 기준 15.4%를 기록해 1등을 기록했습니다.
- 5개의 five convolutional layers 및 max-pooling layer 사용, 3개의 fully-connected layers with a final 1000-way softmax 사용되었다.
- Contributions
- ReLU
- Local Response Normalization
- Ovarlapping pooling
- Data Augmentation/Drop out
Introduction
이 글 처음에는 과거와 현재의 차이에 대해서 말해주고 있다. 과거보다 현재 많고 질 좋은 데이터 셋을 수집할 수 있다고 말하고 있다. 이런 상황에서 CNN은 적은 연결과 매개변수를 통해 이론적으로 좋은 성능 나타낼 수 있다. 하지만 과거에는 값 비싼 비용으로 인해 사용하지 못했다면, 현재는 운이 좋게도 GPU의 발달로 가능하게 되었다. 이 후에는 간단한게 CNN 구조와 어떤 방법으로 과적합을 제어했는지 간략하게 나와있다.
The Dataset
ImageNet 데이터 셋은 약 1500만개의 고해상도 이미지와 약 22,000개의 범주를 가지고 있다. ILSVRC 에서는 ImageNet의 subset을 사용하며 대략 120만개의 training 이미지와 50,000개의 validation 이미지, 150,000개의 testing 이미지로 구성되어있습니다.
이미지의 크기는 256 X 256 고정하였고, resize 방법은 넓이와 높이 중 더 짧은 부분을 256으로 고정시키고, 중앙에서 crop 했다. 각 이미지의 pixel에 traing set의 평균을 빼서 normalize 해주었습니다.
The Architecture
- ReLU
: ReLu는 활성 함수이며 "f(x) = max(0,x)" 함수이다. 위 논문에서 ReLU 방법이 tanh 활성함수보다 약 6배 빠르다고 나와있다.
- Training on Multiple GPUs
: 2개의 GPU를 병렬화 시켜 학습을 진행했습니다. 한 가지 트릭으로 는 layer 2에서 layer 3로 가는 학습 과정에서는 2개의 GPU가 서로 소통할 수 있었습니다.
- Local Response Normalization
:ReLU는 양수값을 받으면 그 값을 그대로 neuron에 전달하기 때문에 너무 큰 값이 전달되어 주변의 낮은 값이 neuron에 전달되는 것을 막을 수 있습니다. 이것을 예방하기 위한 normalization이 LRN 입니다. - Overlapping Pooling
: 일반적으로 pooling layer는 overlap하지 않지만 AlexNet은 overlap을 해주었습니다. kernel size는 3, stride는 2를 이용해서 overlap을 진행했습니다.
✔ 위의 방법의 대한 설명은 생략하겠습니다. 간단하게 이야기하면 위의 방법론들이 test error rate 및 비용을 줄여주는 방법론들입니다.
- Architecture
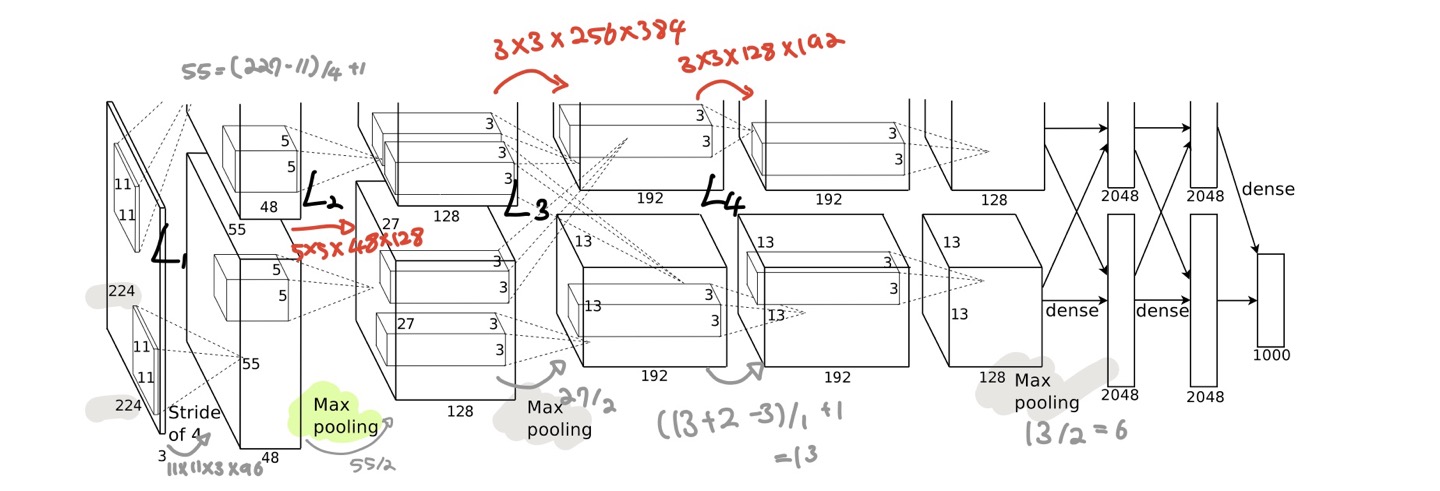
- 위의 아키텍처는 일부가 max-pooling layer가 적용된 5개의 convolutional layer와 3개의 fully-connected layer로 이루어져있습니다.
- [Input layer - Conv1 - MaxPool1 - Norm1 - Conv2 - MaxPool2 - Norm2 - Conv3 - Conv4 - Conv5 - Maxpool3 - FC1- FC2 - Output layer]의 순서로 이루어져 있습니다.
- 아래는 AlexNet 파라미터 수 계산과정입니다. 참고 자료


-
아래 표는 Tensorflow로 요약된 표 입니다.

Reducubg Overfitting
-
위의 네트워크 아키텍쳐는 6천만개의 파라미터가 사용되었습니다. 이미지를 ILSVRC의 1000개 classes로 분류하기 위해서는 상당한 overfitting 없이 수 많은 parameters를 학습 시키는 것은 어렵다고 말합니다.
Data Augmentation
-
간단하게 Data Augmentation은 데이터를 늘리는 것입니다. 2가지 방법으로 Data Augmentation으로 진행했으며, 2가지 방법 모두 little computation으로 수행할 수 있습니다.
-
첫번째 방법으로는 extracting five 224 X 224 patches(the four corner and one center patch) & horizontal reflections 방법으로, 위의 방법으로 기존의 데이터의 약 2048배의 데이터를 수집할 수 있습니다.
-
두번째 방법으로는 PCA를 통해 RGB pixel 값의 변화를 주었습니다. PCA를 수행하여 RGB 각 색상에 대한 eigenvalue를 찾습니다. eigenvalue와 평균 0, 분산 0.1인 가우시안 분포에서 추출한 랜덤 변수를 곱해서 RGB 값에 더해줍니다.

* 위의 방법들로 top-1 에러의 1%를 줄일 수 있었다고 합니다.
Dropout
Test에서 모든 뉴런을 사용했지만, 결과 도출할 때 0.5를 곱해주었다. 처음 두 개의 Fc에서 Dropout을 도출했고, dropout을 통해 overfitting을 피할 수 있었고, 수렴하는데 필요한 반복수는 두 배 증가되었습니다.
Details of learning
Train 모델에는 SGD(stochastic gradient descent) 사용했으며, batch size = 128, momentum = 0.9 and weight decay = 0.0005 를 적용시켰다.

- v = momentum, e = learning rate 이며, weight 초기화는 평균이 0 분산이 0.01인 가우시안 분포를 사용했습니다. bias는 두번째, 네번째, 다섯번째 conv layers 와 Fc layer에서는 1로 나머지는 0으로 계산했습니다.
- learing rate = 0.01로 초기화 했고, 모델 학습 중 총 3번의 감소가 있었습니다.
Results

- 결과적으로 top-5 테스트 셋에서 15.3% 로 competition에서 가장 우수한 성과를 거둘 수 있었습니다.
