David Silver Reinforcement Learning 강의를 참고한 정리글입니다.
AI agent 붐이 휘몰아치는 요즘.. agent하면 또 강화학습..
강화학습의 기초
🟩 강화학습이란..
✏️ 중요한 질문: 강화학습은 뭐가 다른가?!
- 지도적 학습과 다르게 목적 agent가 (reward signal)만 알려줌
- 리워드 = 피드백이라고 하면, 액션을 취했을 때 바로 피드백 x, delay 가능
- 순서가 있음.
- 보통 i.i.d를 가정하는 다른 학습들과 다르다!
- 지도/비지도 학습은 dataset이 정해지지만, 강화학습은 반응을 어떻게 하냐에 따라 받는 data가 계속 달라짐.
💡 예시:
알파고 - 게임에서의 승리가 reward
투자관리 매니징 - sequential한 데이터, 이윤이 reward
🟩 기본 용어 정리
1. Reward
- t 시점의 reward
- 방향이 있는 벡터가 아닌, 스칼라 값!
- agent의 역할은 축척된 reward가 더해졌을 때 maximize하는 것.
💡 강화학습의 Reward Hypothesis
모든 목적은 축척된 reward를 maximize하는 것.
- 즉각적 reward이 아닐수도, 즉 계속 greedy 하게 하면 안되고, 미래 장기적으로 더 큰 reward를 받을 수 있는 걸 선택할 수도 있음.
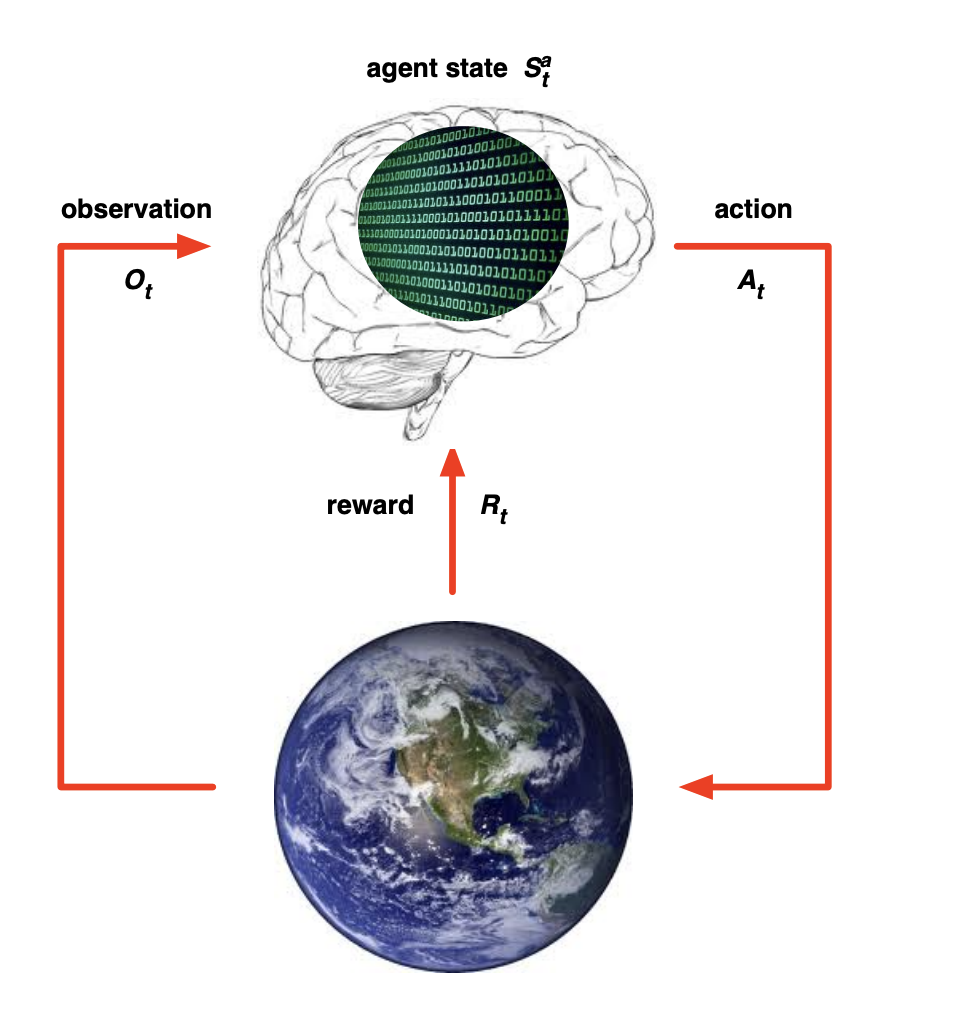
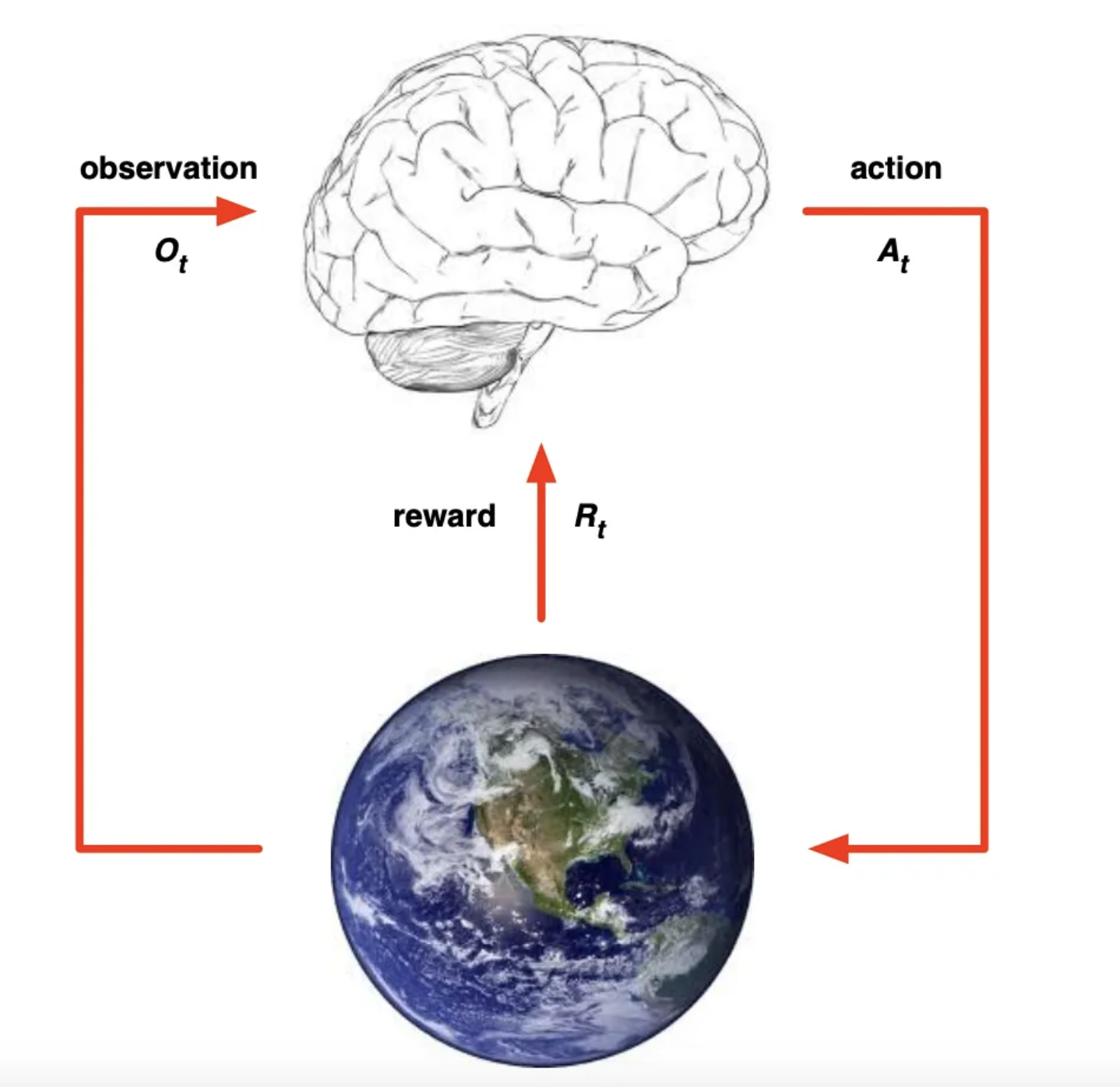
2. Agent / Environment
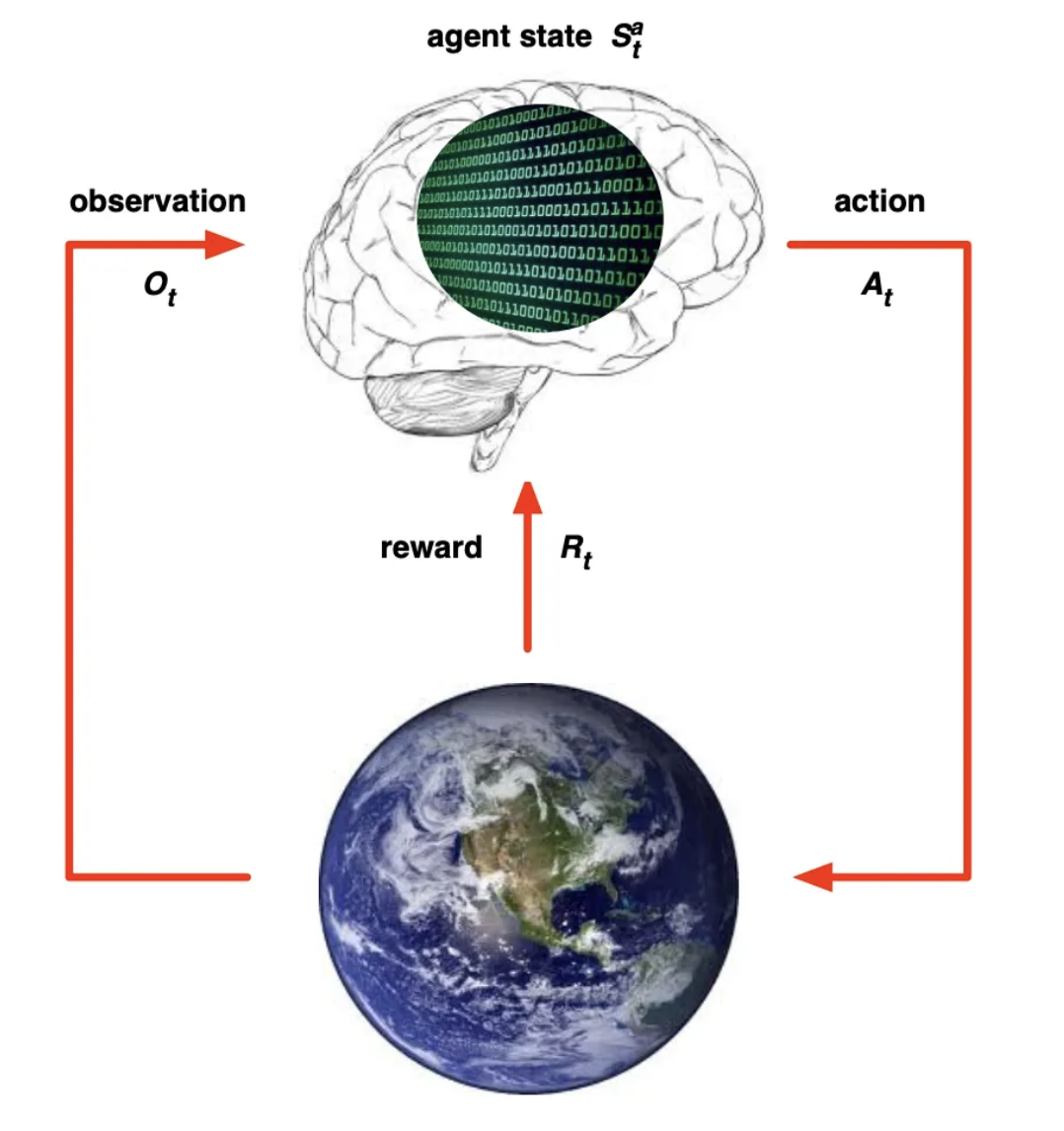
그림을 보면 좀 이해가 빠르다.
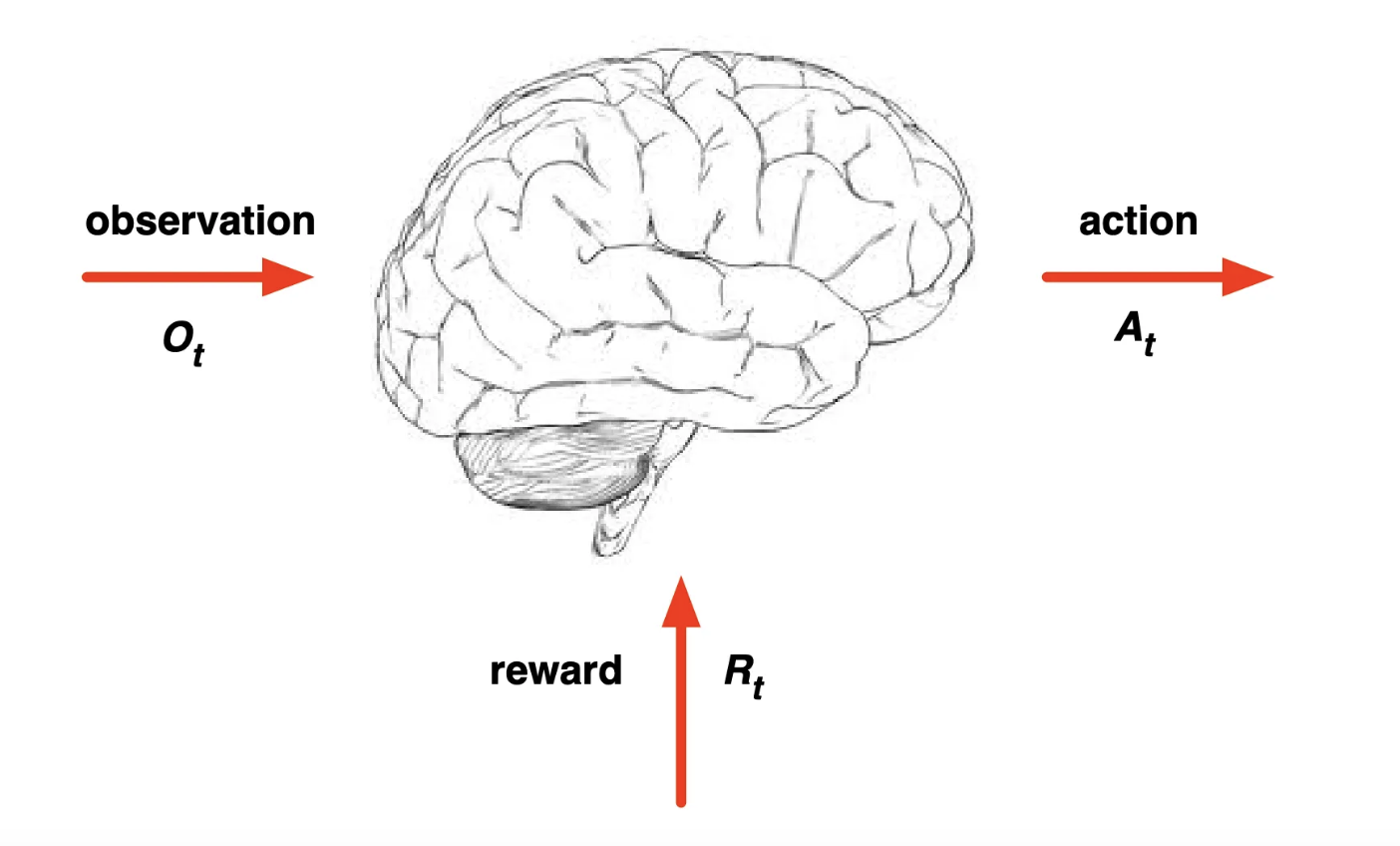
뇌: Agent (액션을 취하는 얘)
지구: 그 밖에 일어나는 환경 (상황, 보상)
이렇게 계속 서로 상호작용을 주고 받으면서 그 때 그 때 agent는 액션을 취하게 됨.
- 매 t시점마다 agent는
- 라는 action을 취함.
- 바뀌는 상황 , 스칼라 값인 Reward 즉 를 받음. (이 두가지를 Environment라고 함)
- 매 t시점마다 environment는
- 라는 action에 따른
- 를 뱉는
→ 상호작용 과정을 거치게 됨
3. History / State
History : t시점까지의 모든 memory (Observation, Action, reward)
에 의해 결정되는 것들
- Agent는 다음 를 결정
- Environment는 를 고름
State : 다음에 뭘 뱉지?를 결정할 때 쓰이는 정보들. 자체일 수도 있고, 변형된 값일 수도 있음!
따라서, State는 History의 함수이다.
💡History 의 값에 따라 변하는 State
여기서 이제 State는 Environment State, Agent State로 나뉨.
- Environment state
- Environment ()를 만들 때 사용한 모든 정보
- Agent에게 모두 보이진 않음.
- 이게 먼소리냐면, 우리가 게임을 할 때 게임하는 내 뇌가 Agent라고 해보자.
- 우리는 게임 내부적인 점수 계산법 ()이 어떤지, 구체적으로 보지 않음.
- 오직 Environment가 내뱉는 것들 중 내 뇌에게 주는 영향만 봄!
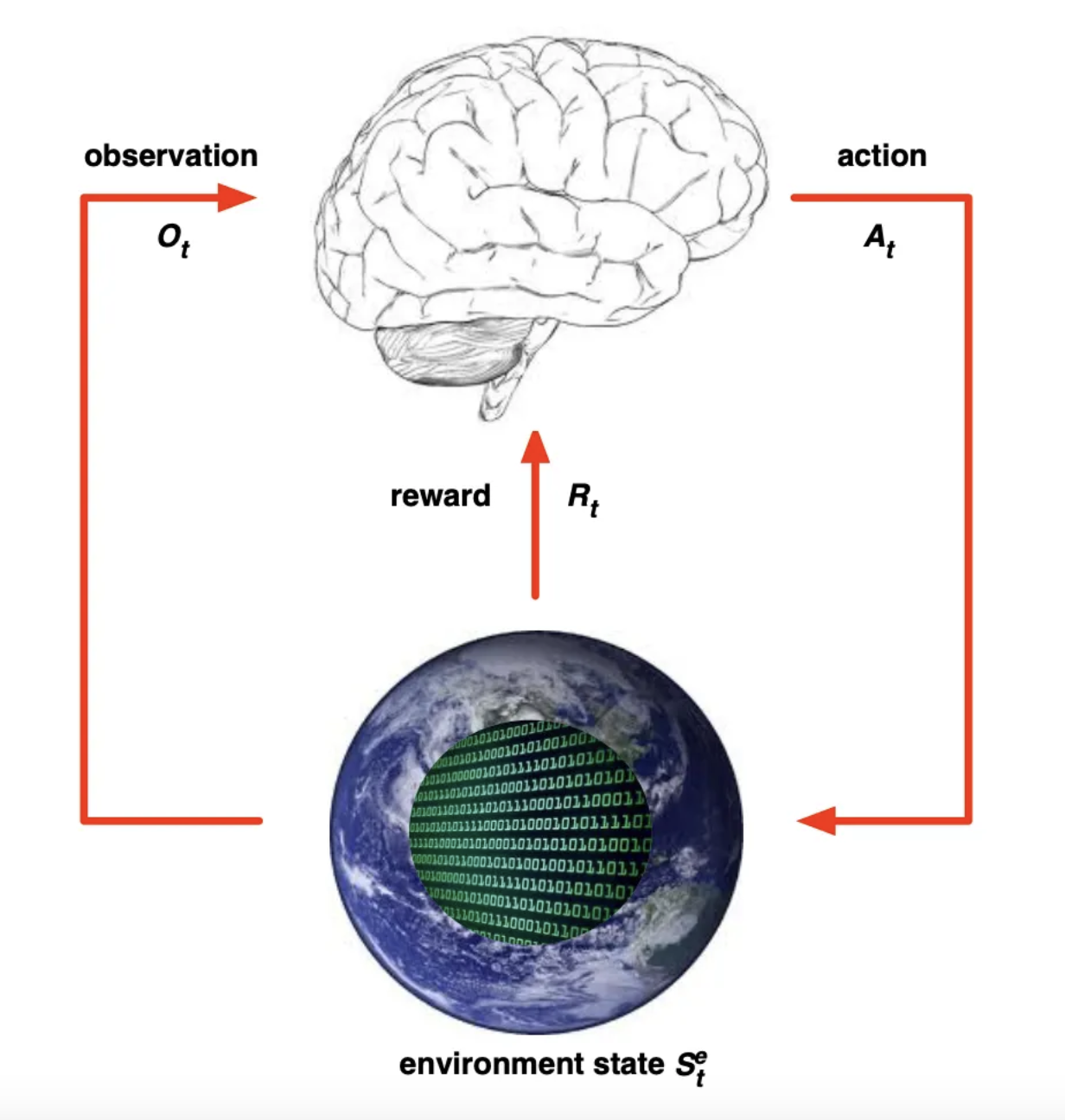
- Agent state
-
Agent가 다음 Action을 할 때 쓰이는 정보들.
-
가공도 가능하고, 그대로 다 볼 수도 잇음.
-
에 따라 달라짐.
-
Markov State
강화학습에서 마코프 상태란,
“현재 상태가 미래를 예측하기에 충분한 정보를 담고 있는 상태”를 의미한다.
즉, 과거의 상태에 의존하지 않아도 된다면 그 상태는
마르코프 상태다.
💡 내가 결정을 할 때 바로 이전 것만 보면 된다는 것.
처음에 이 개념이 너무 헷갈려서 지피티랑 진대를 나눈 결과 (진지한 대화)
제일 이해하기 쉬운 게 수식이다.
- t시점의 State만 주어졌을 때, t+1시점의 State가 될 확률이!
- t시점 전까지의 모든 State가 주어졌을 때, t+1시점의 State가 될 확률과 같다.
→ 즉, 만 있든, ,..,까지 다 있든, 의 Probability는 같을 때, 우리는 그 State가 Marcov하다고 할 수 있다.
하지만 이것도 확 와닿진 않아서 예시를 들어야 됨
헬리콥터를 조종하려고 함.
- 마르코프한 상태 예시
현재 속도,위치,기어,도로 경사등을 상태로 정의하면 다음에 어떤 입력을 줬을 때 어떻게 될지 예측할 수 있슴 → 과거에 몇 초 전 속도가 어땠는지 몰라도 됨.
- 비마르코프한 상태 예시 만약 상태에
현재 위치만 포함시키고,위치,기어,도로 경사는 빼버리면? 그럼 “다음 위치”는 알 수 없슴!!! → 과거 움직임(즉, 위치 정보)이 필요하니까 마르코프 성질이 깨져버림.
4. Fully / Partially Observable
- Fully Observable한 상태
- 모든 state가 같아서 Agent 가 까지 볼 수 있음!
- 그래서 이걸 Markov Decision Process, MDP라고 함.
- Partially Observable한 상태
- 즉 Agent가 를 볼 수 없는 상태
- Partially Observable Markov Decision Process, POMDP라고 함
기초 2에서 이어서…..
