✅Scikit-learn(사이킷런)
- python을 대표하는 머신러닝 라이브러리
- 데이터 분석을 위한 간단하고 효율적인 도구
- 오픈소스, 상업적으로 사용 가능
- 주요 기능 6가지
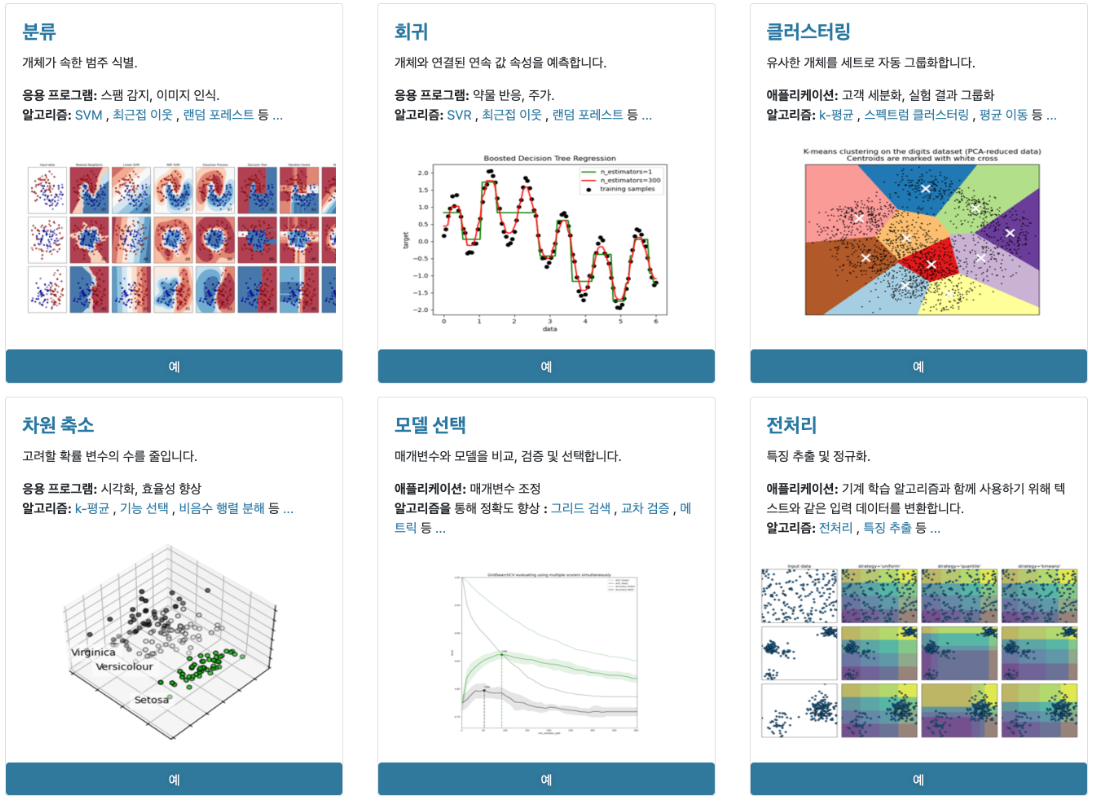 <출처: Scikit-learn 공식 문서>
<출처: Scikit-learn 공식 문서>- classification (분류): 범주화, 카테고리를 나누는 것
ex) 범주화된 데이터
합격/불합격 여부
암 양성/음성
와인의 등급
현역 VS 공익
스팸 메일 여부
소고기 등급 - regression (회귀):
- 수치형 데이터를 예측
- 가설에 미치는 다양한 수치형 변수들과의 인과성 분석
ex) 수치화된 데이터
시험점수
공부시간
기온
판매량
집값
자동차 속도
나이
키 - clustering (군집화): 비슷한 범주들을 모아주는 것
- dimensionality reduction (차원 축소):
- 고차원 데이터를 차원을 축소해서 한눈에 볼수 있게 해줌
- parameter의 개수 줄여줌 --> 속도 개선 - model selection (모델 선택): 학습이 잘 된 최적의 모델을 고름
- preprocessing (전처리): 정규화, 표준화, 특정 데이터 추출, scale 값 통일
- classification (분류): 범주화, 카테고리를 나누는 것
| 범주형 | 수치형 | |
|---|---|---|
| 지도학습 | 분류 | 회귀 |
| 비지도학습 | 군집화 | 차원축소 |
지도학습
✅분류
⭐<지도학습>
fit : 주어진 기출문제와 정답으로 공부를 하는 과정
predict : 기출문제와 정답으로 공부한 것을 바탕으로 실전 문제를 풀어봄(예측)
evaluate : 제대로 문제를 풀었는지 채점(모델 평가)
*대문자 X와 소문자 y로 쓰는 건 관례(X는 2차원 y는 1차원)
gini == 지니계수: 분류가 잘 되었다라고 평가하기 위해서는 분류된 결과가 불순도가 낮아야함 그 불순도가 높은지 낮은지 의미하는 것이 지니계수
y_test = 정답값(실제값)
y_predict = 예측값
y_yest와 y_predict가 같으면 같을수록 decision tree를 통해 학습시킨 모델의 성능이 더 좋다고 할 수 있음(완벽하게 예측했다는 뜻)
피처의 중요도: 예측에 영향을 많이 미쳤다는 것
학습.예측 데이터의 비율: 비율은 상관없지만 학습 데이터의 비율을 높게 해야 함. 통상적으로는 8:2로 나눔
*수치형 변수를 범주형 변수로 만드는 이유?: 머신러닝 알고리즘에 힌트를 줄수도 있고 오버피팅을 방지할 수도 있음
✅ Decision Tree
Decision Tree : 결정 트리 학습법
- 최근 가장 인기 있는 알고리즘
- CART 알고리즘
(랜덤포레스트, 부스트트리, 회전포레스트) - 결과를 해석하고 이해하기 쉬움
- 자료를 가공할 필요X
- 수치, 범주 자료 모두 적용 가능
- 화이트박스 모델(결과에 대한 설명을 쉽게 설명 가능 -> 인공신경망은 어렵기 때문에 블랙박스 모델)
- 안정적
- 대규모의 데이터 셋에서도 잘 동작
*트리를 많이 나누면 과대적합이 발생할 수 있음!
✅ 분류모델 함수
- from sklearn.tree import DecisionTreeClassifier
- DecisionTreeClassifier()
- 주요 파라미터
- criterion: 가지의 분할의 품질을 측정하는 기능
- max_depth: 트리의 최대 깊이
- min_samples_split:내부 노드를 분할하는 데 필요한 최소 샘플 수
- min_samples_leaf: 리프 노드에 있어야 하는 최소 샘플 수
- max_leaf_nodes: 리프 노드 숫자의 제한치
- random_state: 추정기의 무작위성을 제어, 실행했을 때 같은 결과
- 주요 파라미터
✅ 용어정리
1. 과대적합(overfitting)
-너무 많이 공부해서 쓸모없는 부분까지 학습을 다 한 경우
-모의고사에서는 100점을 맞지만 실전에서는 다른 경우
2. 지니불순도
-얼마나 섞여있나
-최악은 p=0.5일때
-아무것도 섞여있지 않으면 멈춤 (p=0)
3. 정확도(Accuracy)
-모델이 얼마나 잘 예측했는지 측정
-시험 보고 나서 몇 개 맞았는지 틀렸는지 채점해 보는 과정과 유사
4. 과소적합(underfitting)
-공부를 너무 안함
5. 수치형을 변수형으로 바꾸는 이유
-머신러닝할때 힌트를 줄 수도 있다
-머신러닝할때 오버피팅을 강제할 수 있다
✅회귀
✅ Feature Engineering
이상치제거
- IQR : 사분위 (Qunantile)값의 편차를 이용하는 기법
quantile(0.75) - quantile(0.25)
✅ Bagging
- Bootstrap Aggregating
- 표본의 개수를 샘플링해서 반복해서 뽑는다.
- 100개의 데이터를 중복을 허용하여 임의로 추출한다
- 데이터를 중복을 허용하여 선택함으로써 새로운 트리를 형성한다.
- 다른 훈련 데이터에 훈련된 기초 분류기들을 결합
- 서로 다른 데이터셋에 훈련시켜 트리들을 비상관화시키는 방법
✅ Ensemble ML Approach
- 분류기 성능 개선을 위해 저성능 분류기를 결합한 복합 모델
- 과반수 투표를 수행하는 개별 분류기 투표나 최종 예측 레이블이 반환된다.
- 배깅 → 병렬
- 부스팅 → 순차적
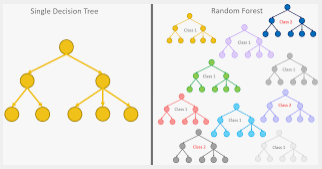
✅RandomForest
- overfitting될 가능성이 높다는 약점을 가지고 있는 Decision Tree를 보완하기 위해 만들어진 모델
- 가지치기를 통해 트리의 최대 높이를 설정해 줄 수 있지만 이로써는 overfitting을 충분히 해결할 수 없기 때문에 만들어진 일반화된 트리를 만드는 방법
Scikit learn RandomForestClassifier (분류)
- from sklearn.ensemble import RandomForestClassifier
- model = RandomForestClassifier(random_state=42)
- 하이퍼 파라미터
- n_estimators=100 (default값) ==> 값을 늘릴수록 시간이 오래걸림, 트리의 수
- max_depth = 트리의 깊이
- min_samples_leaf = 각 트리 임의화를 얼마나 할 것인지 지정
- random_state
- n_jobs => n_estimators 때문에 오래걸리는 시간을 조금이나마 단축시키기 위해 사용, 사용중인 코어를 모를경우를 대비하기 위해 모든 코어 사용 시 -1로 할당
Scikit learn RandomForestRegressor (회귀)
✅Cross Validation (교차검증)
-
교차 검증(cross validation)법 : train set과 test set으로 평가를 하고, 반복적으로 모델을 튜닝하다보면 test set에만 과적합되는 문제를 해결
-
cv : cross validation 개수
-
verbose : 로그를 단계별로 좀더 자세하게 출력할 것인지
k-fold
- 데이터 셋을 k개의 subset으로 나누고 k번의 평가를 실행하는데, 이 때 test set을 중복 없이 바꾸어가면서 평가를 진행
- Accuracy(cross_valid) = Average(Accuracy1,Accuracy2 … , AccuracyK )
- 4개의 fold는 모의고사 , 1개의 fold는 수능인 느낌 .
cross_validation 의 장점
- 모든 데이터 셋을 평가에 활용할 수 있고, 평가에 사용되는 데이터셋의 편향 방지
- 데이터 부족으로 인한 underfitting을 방지
- 평가 결과에 따라 좀 더 일반화된 모델
- 정확도 향상
cross_validation 의 단점
- Iteration 횟수가 많기 때문에 모델 훈련/평가 시간 소요
✅ R^2 결정계수
회귀식의 적합도를 재는 척도
회귀분석에서 종속변수 Y의 데이터 yi에 대하여, yi의 총변동합에 대한 변동합의 비율을 나타낸다
