10/31~11/2 머신러닝 2주차
10/31
⭐회귀모델 성능지표
✅MAE(평균절대오차)
오차값의 describe 값 중 mean 값
mae = abs(y_train - y_predict).mean()
-> 음수 값을 정확히 하기 위해 오차에 절대값을 적용해주어야 함 (abs)
✅MAPE
(실제값 - 예측값/ 실제값)의 절대값에 대한 평균
실제값에 대비해서 오차값의 비율
mape = abs(y_train - y_predict)/y_train.mean()
-> MAPE 값은 작을수록 잘 예측한 것.
✒️r2 score = 사용했던 측정 공식 중에 1에 가까울 수록 좋은 모델이고, 0에 가까울수록 잘못 예측한 측정 공식
✅MSE(Mean Squared Error)
실제값 - 예측값의 차이의 제곱의 평균
-> 오차에 제곱을 하는 이유:
절대값을 씌워주는 것과 마찬가지로 부호 무시 가능
mse = ((y_train - y_predict)**2).mean() mse
✒️pow()도 제곱이랑 같은 역할
✅RMSE(root mean squared error)
mae에 루트 씌우기
np.sqrt(mse) ((np.square(y_train-y_predict)).mean())**0.5
- 분산은 어떨때 사용?
관측값이 평균과 얼마나 떨어져있는지 알아보기 위해,
기대값으로부터 얼마나 떨어진 곳에 분포하는지 가늠,
관측 값에서 평균을 뺀값 -> 차이값에서 평균이 아닌, 차이값의 제곱의 평균
(mse일 경우 실제값과 예측값의 차이의 제곱의 평균)
-> MSE와 매우 유사
-> rmse = 표준편차와 유사 - 분산과 MSE의 차이: 분산은 관측값에서 평균을 뺀 값 제곱/<SE는 실제값에서 예측값을 뺀 값을 제곱
- 회귀에서 Accuracy를 사용하지 않는 이유: 소수점 끝자리까지 정확하게 예측하는 것은 불가능
🎈MSE, MAE 비교 예시
🔷1)
100억을 110억으로 예측
100억을 105억으로 예측
-> MAE, MSE 모두 2번이 잘 예측
🔷2)
5분 걸린다고 예측했는데 10분 걸림
25분 걸린다고 예측했는데 50분 걸림
-> MAE, MSE 모두 2번이 잘 예측
- mape는 생각보다 많이 쓰지는 않음
=> MSE, MAE 등은 회귀모델이 잘 예측했는지 파악하기 위한 지표
🎈분류 VS 회귀
🔷1. 분류
분류의 경우에는 잘 정답값과 비교해서 많이 맞으면 잘 예측했다라고 말할 수 O -> accuracy
🔷2. 회귀
회귀는 잘 예측했다라고 말하기에는 정답값에 딱 맞출 X
오차가 적을수록 모델이 잘 예측했다 라는 가정을 하고 그 오차를 MAE, MSE, RMSE와 같은 지표들로 검증
- stratify: train set과 test set을 분리할 때 class 비율을 동일하게 하는 것(균등하게 배분)
- class 비율이 동일하게 나뉘었는지 어떻게 확인?? countplot으로 시각화
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(12,2))
sns.countplot(x=y_train, ax=axes[0]).set_title("train")
sns.countplot(x=y_test, ax=axes[1]).set_title("test")⭐cross validation의 기법 두개
✅1. GridSearch CV
: 모델의 하이퍼 파라미터 후보군들을 완전 탐색하여 하이퍼 파라미터를 검색
-> 정해진 구간에서만 값을 탐색
장점: 검증하고 싶은 하이퍼 파라미터의 수치를 지정하면 수치별 조합을 모두 검증하여 최적의 파라미터 검색의 정확도 향상
단점: 후보군의 개수가 많으면 많을수록 기하급수적으로 찾는 시간은 오래 걸리며 후보군들을 정확히 설정 필요
✅2. RandomizedSearchCV
: 정해진 횟수 안에서 정의된 하이퍼 파라미터의 후보군들로부터의 조합을 잰덤하게 샘플링하여 최소의 오차를 갖는 모델의 하이퍼 파라미터를 검색
-> 지정된 구간 외에 최적값이 있을 때 그리드 서치로 찾지 못하는 단점을 보완하여 랜덤한 값들을 지정해 그 중 가장 좋은 성능을 찾아내는 파라미터 찾음
정점: 무작위로 값을 선정하고 그 조합을 검증하므로 빠른 속도로 최적의 파라미터 조합을 검색
단점: 후보군을 신중히 결정해야하며, 랜덤한 조합들 중 최적의 하이퍼 파라미터를 찾는다는 보장X, 횟수를 늘려주면 시간도 비례하게 증가
-> gridsearchCV: 조합의 수 만큼 실행
-> randomizedsearchCV: k-fold 수(n_iter 수)만큼 실행
11/1
⭐titanic 데이터 실습 0502
🎈학습, 예측 데이터셋
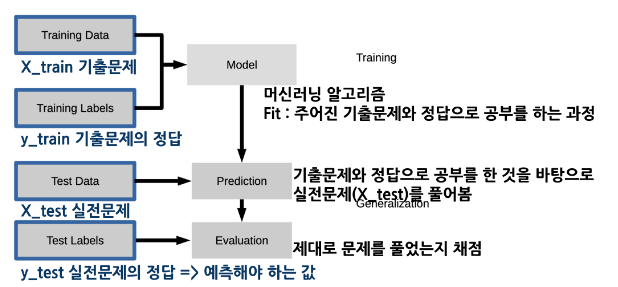
X_train = train[feature_names].fillna(0)
print(X_train.shape)
print("결측치 합계 : ", X_train.isnull().sum().sum())
X_test = test[feature_names].fillna(0)
print(X_test.shape)
print("결측치 합계 : ", X_test.isnull().sum().sum())
🎈지니 불순도
- 지니 불순도는 집합에 이질적인 것이 얼마나 섞였는지를 측정하는 지표이며 CART 알고리즘에서 사용
- 어떤 집합에서 한 항목을 뽑아 무작위로 라벨을 추정할 때 틀릴 확률
- 집합에 있는 항목이 모두 같다면 지니 불순도는 최솟값(0)을 갖게 되며 이 집합은 완전히 순수
🎈로그
로그(log)는 지수 함수의 역함수
어떤 수를 나타내기 위해 고정된 밑을 몇 번 곱하여야 하는지 나타냄
- 복잡한 단위의 계산을 간편하게 계산할 수 있음
- 이진로그 : 밑 2 / 자연로그 : 밑 e / 상용로그 : 밑 10
1. (1,0)을 지남
2. x는 음수를 가지지 않으며, 0보다 큰 값을 가짐
3. x가 1보다 작을 때는 마이너스 무한대로 수렴
ex)
당뇨병 이다 아니다 => 2진분류
생존여부 => 2진 분류
고객센터 문의 7개 => 7개로 분류
쇼핑카테고리 19개 => 19개로 분류
🎈엔트로피
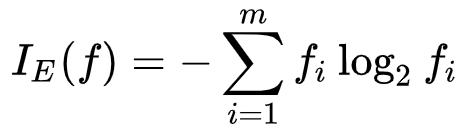
- 확실하게 구분이 될 때, 불확실성이 낮음
- 정보 이론의 엔트로피의 개념에 근거
- 기술적인 관점에서 정보는 발생 가능한 사건이나 메시지의 확률분포의 음의 로그로 정의
- 각 사건의 정보량은 그 기댓값, 또는 평균이 섀넌 엔트로피인 확률변수를 형성
- 최대 엔트로피 : np.log2(클래스 개수)
- 엔트로피 종류 다양 / decision tree에서는 섀넌 엔트로피 사용 -> 이진로그를 사용
- 확률값은 1보다 작기 때문에 공식에 - 붙이기
0/2) * np.log2(1/2))
(2/2) * np.log2(2/2) + (0/2) * np.log2(1/2))
✅ 지니불순도와 엔트로피를 사용하는 목적
: 분류를 했을 때 True, False 로 완전히 나뉘지 않는데 이 때 값이 얼마나 섞여있는지 수치로 확인하기 위해서이고, 0에 가까울 수록 다른 값이 섞여있지 않은 상태
분류의 분할에 대한 품질을 평가하고 싶을 때 사용
✅ 이퍼 파라미터
criterion: 가지의 분할의 품질을 측정하는 기능
max_depth: 트리의 최대 깊이
min_samples_split:내부 노드를 분할하는 데 필요한 최소 샘플 수
min_samples_leaf: 리프 노드에 있어야 하는 최소 샘플 수
max_leaf_nodes: 리프 노드 숫자의 제한치
random_state: 추정기의 무작위성을 제어,실행했을 때 같은 결과가 나오도록 함
✅ 마무리
- 지니 불순도 0.5일 때 가장 값이 많이 섞여있는 상태
- 엔트로피는 np.log2(클래스 개수) 값과 같을 때가 가장 많이 섞여있는 상태
- 지니 불순도나 엔트로피가 0이 되면 트리 분할을 멈춤
- max depth 설정을 하면 지니 계수나 엔트로피가 0이 아닐때 멈춤
11/2
⭐titanic 데이터 실습
- train에만 있는 호칭
set(train["Title"].unique()) - set(test["Title"].unique()) - test에만 있는 호칭
set(test["Title"].unique()) - set(train["Title"].unique())
❓한쪽에만 있는 호칭은 어떻게 정리해야할까? -> 기타로 묶어서 처리
(결측치 처리도 가능하다❗
기타 호칭에 의미 부여를 하고 싶지 않을 때->범주형 데이터의 경우에는 결측치 처리를 하면 원핫인코딩을 했을 때 해당 값이 만들아지지 않음
❗하지만 특이한 값도 고려를 하기 원한다면 예외값이라고 만들어주면 예외값이라는 힌트를 머신러닝 알고리즘에 알려주는 효과가 있음)
=> 빈도수가 작은 값들은 머신러닝이 예측하는데 어려움. 따라서 빈도수가 적은 값에 의미를 살리고 싶으면 '기타'로 묶어줌
- 2개 이하(2개나 1개만 있는 호칭은 etc로 묶기)
title_count = train["Title"].value_counts() title_not_etc = title_count[title_count >2].index title_not_etc
train["TitleEtc"] = train["Title"] train.loc[~train["Title"].isin(title_not_etc), "TitleEtc"] = "Etc"
train["TitleEtc"].value_counts()
=> 앞으로 어떤 값이 들어올지 모르기 때문에 기타의 정의를 빈도수 기준으로 설정함
✒️ 데이터 전처리를 할 때는 train을 기준으로
-> 현실 세계에서 test는 아직 모르기 때문에 train을 기준으로 전처리 해야함
✒️ train에만 등장하는 호칭은 학습을 해도 test에 없기 때문에 예측에 큰 도움이 되지 않음
-
train에만 등장하는 호칭을 피처로 만들어주게되면 피처의 개수가 늘어나는데, 불필요한 피처가 생기기도 하고
-
데이터의 크기도 커지기 때문에 학습 시간도 더 오래 걸림
-
너무 적게 등장하는 값을 피처로 만들었을 때 해당 값에 대한 오버피팅 문제도 있을 수 있음
-
train과 test의 피처 개수가 다르면 오류 발생
-
원핫 인코딩을 할 때 train, test 피처의 개수와 종류가 같은지 확인 필요
-> 예를 들어 train 피처는 수학인데 test 피처는 국어다 라고 하면 피처의 개수가 같더라도 다른 종류 값이기 때문에 제대로 학습할 수 없음.
#피처를 컬럼명으로 만들 때도 제대로 만들어지지 않음
✒️ esc + f: find & 코드 replace
🎈Cabin 파생변수 만들기
- 앞에 알파벳이 들어가는데 알파벳의 이니셜만 따로 파생변수로 만듦
- 없는 값에 의미를 부여하고 싶다면 없는 값은 이니셜 "N"으로 대체
-
train["Cabin_initial"] = train["Cabin"].astype(str).map(lambda x:x[:1].upper().strip()) test["Cabin_initial"] = test["Cabin"].astype(str).map(lambda x:x[:1].upper().strip()) print(train["Cabin_initial"].head(2)) print(test["Cabin_initial"].head(2)) -
train["Cabin_initial"] = train["Cabin"].fillna("N").str[0] train["Cabin_initial"].unique() -
test["Cabin_initial"] = test["Cabin"].str[0] test["Cabin_initial"].fillna("N")
-> T객실은 한개만 있음 ▶️ 요금이 비슷한 객실로 묶어줌
⭐Encoding
🎈One-Hot-Encoding (원핫인코딩)
-
sklearn 을 사용하게 되면 일단 학습을 해서 전처리를 하게 됨(어떤 피처가 있는지를 확인)
-
test에 없는 값이라도 test에 해당 피처를 생성
-
그런데 pandas 의 get_dummies 를 사용하면 각각 전처리를 하기 때문에 다른 값이 있다면 다른 컬럼으로 생성 됨
-
이 부분도 피처가 만들어지고 나서 다른 컬럼은 제외해 주는 방법도 있음
✒️ ordianl-Encoding: S,C,Q를 0,1,2로 만들 수 있음.
🔷 순서가 있는 데이터라면 ordianl-Encoding을 사용하는데 순서가 없는 데이터인데 이 방식을 사용하면 의도치 않은 연산이 될 수 있음
🔷 순서가 없는 데이터라면 One-Hot-Encoding 사용
🔷 pandas를 사용하는 이유는 수치데이터와 범주형 데이터를 함께 넣어주어도 알아서 인코딩을 구분해서 해줌
(수치형 데이터는 그대로 두고 범주형 데이터 대해서만 인코딩 함)
🎈get_dummies 동작방식
수치데이터는 그대로 두고 범주형(object, category) 타입에 대해서만 인코딩
ex) pd.get_dummies(train[["Fare", "Age", "Embarked", "Cabin_initial"]])
⭐결측치
결측치가 있으면 머신러닝 알고리즘 내부에서 연산을 할 수 없기 때문에 오류가 발생
결측치가 있는 피러를 사용하려면 사이킷런에서는 꼭 결측치를 대체해줘야함
✒️현실세계에서 분석하는 데이터 함부로 결측치 채우는 건 꼭 주의
- 머신러닝 알고리즘에서 오류가 발생하지 않게 하기 위해 결측치를 채운것이라 분석할 때도 채운다고 오해하면 안돼~!!!!
train에는 결측치가 없지만 ,test에 결측치가 있어서 새로운 변수를 만들어 채우고자 한다면 train에도 test와 같은 변수를 만들어야함 - int, float, bool은 머신러닝 알고리즘에서 수치데이터로 취급
🎈보간법 interpolate
- 이전 값이나 다음 값으로 채울 수 있는데 이런 방법은 대부분 시계열데이터에서 데이터가 순서대로 있을 때 사용
ex) 일자별 주가 데이터가 있다고 가정할 때 중간에 빠진 날짜에 대한 데이터를 채울 때 사용하거나
ex) 순서가 있는 데이터에서 수집이 누락되었거나 할 때 앞,뒤 값에 영향을 받는 데이터를 채울 때 사용 - 그런데 여기에서는 데이터가 순서대로 있다는 보장은 없지만 이렇게 채울수도 있다는 방법.
- fillna
method : {'backfill', 'bfill', 'pad', 'ffill', None}Method to use for filling holes in reindexed Seriespad / ffill: propagate last valid observation forward to next validbackfill / bfill: use next valid observation to fill gap.
https://pandas.pydata.org/docs/reference/api/pandas.Series.interpolate.html?highlight=interpolatelimit_direction : {{'forward', 'backward', 'both'}}- both 로 지정하면 위 아래 결측치를 모두 채워주고 나머지는 채울 방향을 설정
ex)
train["Age_ffill"] = train["Age"].fillna(method="ffill") train["Age_bfill"] = train["Age"].fillna(method="bfill") train["Age_interpolate"] = train["Age"].interpolate(method='linear', limit_direction='both') train[["Age", "Age_ffill", "Age_bfill", "Age_interpolate"]].tail()
✒️결측치를 대체하는 방법에는 정답이 없다!!!!!!
1. 결측치 행을 그냥 제거하는 방법
2. 결측치를 중앙값으로 대체하는 방법
3. 보간법으로 결측치를 대체하는 방법(보간법도 종류가 다양)
⭐머신러닝 알고리즘
: 랜덤 포레스트를 사용해도 되지만 cross validation을 하게 되면 여러번 학습하기 때문에 빠르게 학습시켜 결과를 보기 위해 DecisionTree를 사용
- cross_validate : Evaluate metric(s) by cross-validation and also record fit/score times. 학습결과에 대한 점수와 시간이 나옵니다. 점수를 보고자 할 때는 편리하지만 지정한 metric에 의해서만 점수가 계산됩니다.
- cross_val_score : Evaluate a score by cross-validation. 점수가 나옵니다.
- cross_val_predict : Generate cross-validated estimates for each input data point. 예측 값이 그대로 나와서 직접 계산해 볼 수 있습니다. 직접 다양한 측정 공식으로 결과값을 비교해 볼 수 있습니다.
- valid_accuracy 만드는 이유: 여러번 모델을 수정하고 제출하다보면 valid 점수와 시제 캐글에 제출한 점수를 비교하기 쉽게 하기 위해 제출 파일 이름에 스코어를 적어주면 좋음
⭐Bagging
: bootstrap aggregating
