✅선형회귀
- 특징
- 다른 모델들에 비해 간단한 작동 원리
- 학습 속도가 매우 빠름
- 조정해줄 파라미터가 적다
- 이상치에 영향을 크게 받음
- 데이터가 수치형 변수로만 이뤄졌을 경우, 데이터의 경향성이 뚜렷할 경우 사용하기 좋음
- 선형회귀를 보완한 모델
- Ridge
- Lasso
- ElasticNet
✅결정트리
- 특지
- 만들어진 모델에 대해 시각화 가능
- 시각화 덕분에 비전문가도 이해하기 쉬움
- 데이터의 스케일에 구애X
- 데이터 내 변수의 종류가 달라도 잘 작동
- 학습용 데이터에 과대적합되는 단점이 있음
⭐앙상블
: 여러 머신러닝 모델을 연결하여 더 강력한 모델을 만드는 기법
- 랜덤포레스트
- 그래디언트 부스팅
✅배깅
: boostrap aggregating - 주어진 훈련데이터에서 중복을 허용하여 원 데이터셋과 같은 크기의 데이터 셋을 만드는 과정
- 배깅을 통한 랜덤 포레스트 훈련 과정
- 부트스트랩 방법을 통해 T개의 훈련 데이터셋 생성
- T개의 기초 분류기(트리)들을 훈련
- 기초 분류기들을 하나의 분류기(랜덤포레스트)로 결합 - 평균 or 과반수 투표 방식
-편향은 그대로 유지, 분산은 감소
-서로 다른 데이터셋들에 대해 훈련시킴으로써 트리들을 비상관화 시켜주는 과정
🎈랜덤 포레스트
- 특징
- 성능이 뒤어나고 매개변수 튜닝을 많이 필요로 하지 않음
- 결정트리와 달리 시각화가 불가능하고 비전문가가 이해하기 어려울 수 있음
- 데이터의 크기가 커지면 다소 시간이 걸릴 수 있음
- 랜덤성이 있기 때문에 random_state 변수를 지정하지 않으면 매번 결과가 달라질 수 있음
- 차원이 높고 희소한 데이터는 잘 작동하지 않을 수 있음
🎈엑스트라 트리 모델
- 특징
- 분기 지점을 랜덤으로 선택하기 때문에 랜덤 포레스트보다 속도가 더 빠름
- 1과 동일한 이유로 랜덤 포레스트보다 더 많은 특성 고려
- 랜덤 포레스트와 동일한 원리를 이용하기 때문에 많은 특징을 공유
- 랜덤 포레스트와 비교해 성능이 미세하게 우위에 있음
✅부스팅
: 여러 얕은 트리를 연결하며 편향과 분산을 줄여 강력한 트리를 생성하는 기법
: 이전 트리에서 틀렸던 부분에 가중치를 주며 지속적으로 학습
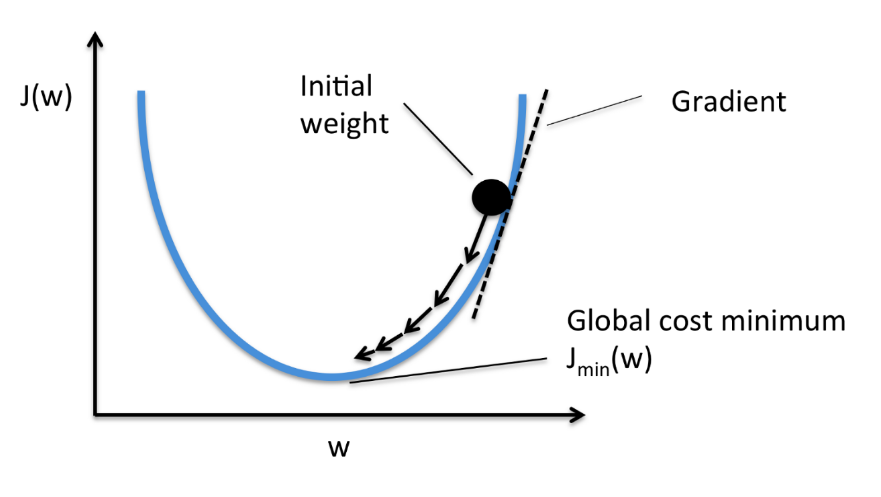
-> 기울기가 가장 적어지는 부분 - 미분하면 기울기를 구할 수 잇음
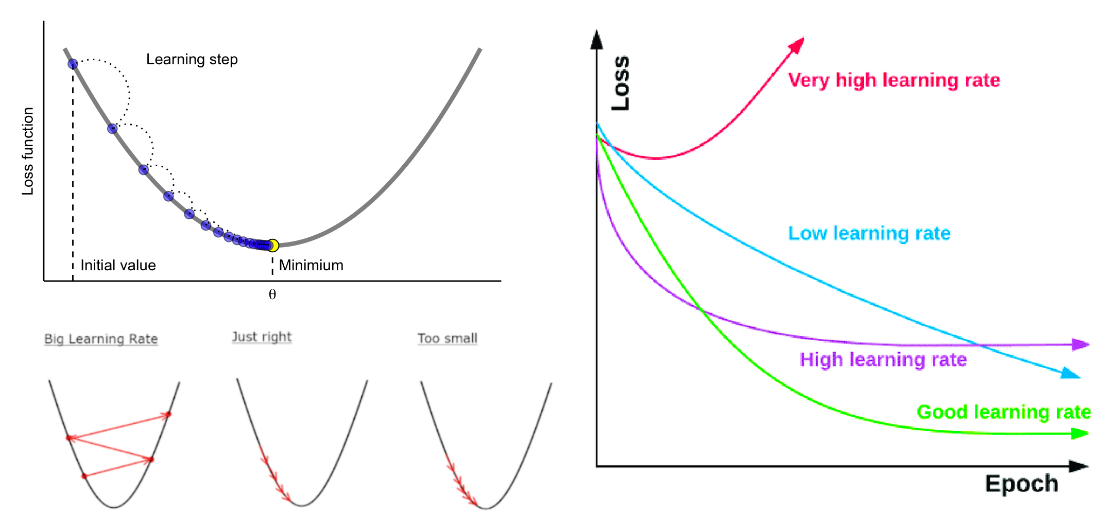
-> 빠르게 학습하고 싶으면 큰 learning rate로, 천천히 하고 싶으면 too small로
✒️배깅 => 오버피팅
부스팅 => 개별 트리의 성능이 중요할 때
주로 사용
🎈GMB(Gradient Boosting Machine)
: 회귀 or 분류 분석을 수행할 수 있는 예측모형
: 머신러닝 알고리즘 중에서도 가장 예측 성능이 높다고 알려짐
- 특징
- 랜덤 포레스트와 달리 무작위성이 없음
- 매개변수를 잘 조정해야 하고 훈련시간이 김
- 데이터의 스케일에 구애받지 않음
- 고차원의 희소한 데이터에 잘 동작하지 않음
-> 차원축소 기법을 통해 해결하기도 함
🎈XGBoost
: 모든 가능한 트리를 나열하여 최적 트리를 찾는 것은 불가능하기에 2차 근사식을 바탕으로 한 손실함수를 토대로 매 iteration마다 하나의 leaf로부터 가지를 늘려나가는 것이 효율적
- 특징
- 병렬처리로 GBM 대비 빠른 수행시간
- 과적합 규제
- 조기 종료 기능
- 다양한 하이퍼 파라미터 종류
- GBM 치고 빠르지만 그래도 학습시간이 느림
- 하이퍼파리미터 수가 많아지면 시간이 더욱 오래 걸림
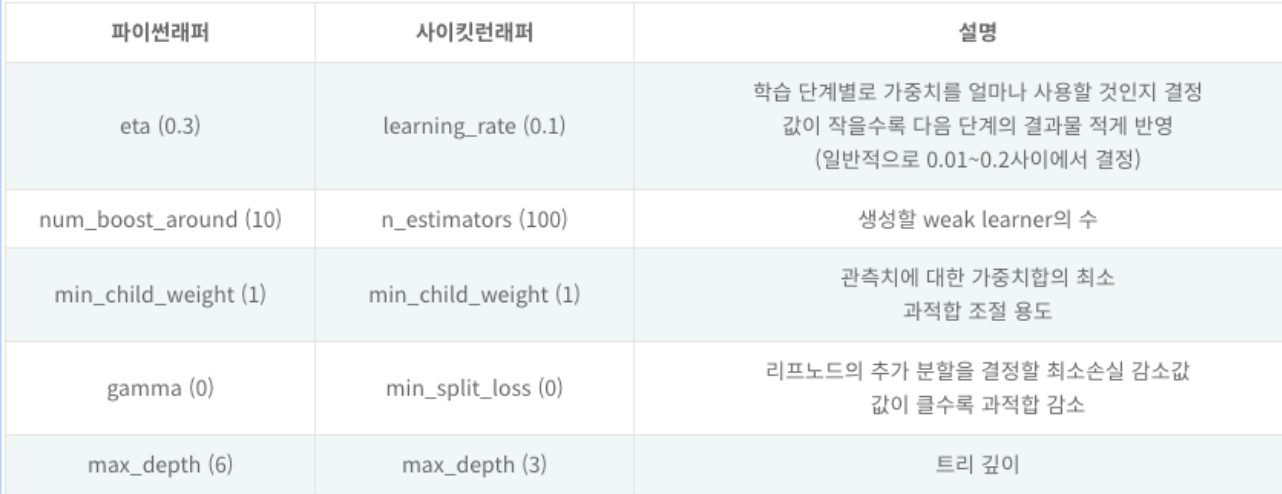
-> XGBoost의 하이퍼 파라미터
🔷 기존의 트리 모델에 없었던 파라미터 중, 중요한 역할을 할 것으로 보여지는 파라미터는 어떤 것일까?
: learning_rate
-> learning rate가 높을 수록 과적합되기 쉽고 너무 낮으면 학습이 오래 걸림
🔷 n_estimators를 높여야 과적합 됨
-> n_estimator == 순차적으로 생성되기 때문에 학습횟수를 의미
-> 과대적합 == 과적합 == 오버피티
(굳이 학습하지 않아야 할것도 학습해서 일반화하기 어려운 것)
✒️ learning_rate를 줄인다면 가중치 갱신의 변동폭이 감소해서, 여러 학습기들의 결정 경계(decision boundary) 차이가 줄어듬.
✒️ n_estimators 를 늘린다면 생성하는 약한 모델(weak learner)가 늘어나게 되고, 약한 모델이 많아진만큼 결정 경계(decision boundary)가 많아지면서 모델이 복잡해짐.
✒️ 즉, 부스팅알고리즘에서 n_estimators와 learning_rate는 trade-off 관계.
n_estimators(또는 learning_rate)를 늘리고, learning_rate(또는 n_estimators)을 줄인다면 서로 효과가 상쇄
🎈lightGBM
: microsoft에서 개발한 머신러닝을 위해 무료 오픈 소스 분산 그래디언트 부스팅 프레임워크
- 특징
- 더 빠른 훈련 속도와 더 높은 효율성
- 적은 메모리 사용량
- 더 나은 정확도
- 병렬, 분산 및 GPU 학습 지원
- 대규모 데이터를 처리
- 오버피팅에 민감하고 작은 데이터에 대해 과적합되기 쉬움
❓ 부스팅 모델은 왜 오버피팅에 민감?
❗ 이전 트리(이전 학습)가 다음 트리에 영향을 주기 때문에
✅0803 실습
- 설치 이슈가 있어서 colab으로 사용
- 왜 설치 이슈?
-> 버전 호환성 문제, 접착제 언어이기 때문에 다른 언어에 대한 의존성 문제
아나콘다로 설치했다면 conda로 설치하는 것이 가장 깔끔함
pip로 설치하면 설치 이슈가 발생할 수 있음
🎈인코딩
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(handle_unknown='ignore')
train_ohe = ohe.fit_transform(train.drop(columns='y'))
test_ohe = ohe.transform(test)# hold-out- validation을 위해 train 값으로 나누기
X = train_ohe
y = train['y']
X.shape, y.shape❓배깅 모델은 시각화가 어려워 3rd party 도구를 따로 설치해야 시각화 가능. 그것도 개별 트리를 시각화 하는 것은 어려움. 그런데 부스팅 모델은 왜 시각화가 가능할까??
❗ 배깅 모델은 병렬적으로 트리를 여러개 생성하지만 부스팅은 순차적으로 생성하기에 시각화가 가능함
✒️ cv에 kfold 를 지정해주면 그냥 cv=숫자를 지정할 때와 어떤 차이가 있게 사용할 수 있을까
-> 셔플기능 사용여부를 결정할 수 있고 랜덤여부를 결정할 수 있음
✒️ demand => 수요예측
✒️ pd.read_json 함수를 이용하면 json을 dataframe으로 변환
🎈ligtgbm
✒️ 가끔 성능이 낮은 장비에서 n_jobs를 -1로 사용하면 노트북이 dead kernel이 되는 현상이 있음
-> 성능이 낮은 장비이거나 다른 작업이 많이 진행되고 있다면 n_jobs를 1로 설정하면 좀 나아짐
- 코드 정리
import lightgbm as lgbm
model_lgbm = lgbm.LGBMRegressor(random_state = 42, n_jobs=-1)
model_lgbm
model_lgbm.fit(X_train, y_train)
lgbm.plot_importance(model_lgbm)
lgbm.plot_tree(model_lgbm, figsize=(20, 20), tree_index=0,
show_info=['split_gain', 'internal_value', 'internal_count', 'leaf_count'])
# valid score
score_lgbm = model_lgbm.score(X_valid, y_valid)
# predict
y_pred_lgbm = model_lgbm.predict(X_test)
# submit
submission['y'] = y_pred_lgbm
submission.head()
file_name = f'{base_path}/sub_lgbm_{score_lgbm}.csv'
submission.to_csv(file_name)
pd.read_csv(file_name)🔷 category 타입으로 되어있으면 lightGBM, catboost에서 인코딩 없이 사용할 수 있음
🎈 데이터를 전처리 하지 않고 category 형태로 넣어주면 알아서 학습
🎈 category 형태로 되어있으면 인코딩 과정이 필요 없음
`from sklearn.model_selection import cross_val_score
cv_score_lgbmr = cross_val_score(model_lgbmr, train.drop(columns='y'), train['y'], cv=3)
# fit & predict
y_pred_lgbmr = model_lgbmr.fit(train.drop(columns='y'), train['y']).predict(test)`
-> lgmb의 장점(성능은 um...)
✒️ _ : 변수 이름 or 함수이름에 주로 사용
✅불균형 데이터
-
현실 시계에서의 불균형 데이터 예시
ex) 암환자 여부, 생산과정 양불 여부 -
confusion matrix

🔷 FP(False Positive, Negative Positive) - 1종 오류
-> 실제는 임신이 아닌데(0), 임신(1)로 예측
스팸메일이 아닌데 스팸메일로 예측
무고한 피고인에게 유죄를 선고
🔷 FN(False Negative, Positive Negative) - 2종 오류
-> 실제는 임신인데(1), 임신이 아닌 것(0)으로 예측
암인데 암이 아닌 것으로 예측
화재가 났는데 화재가 아니라고 예측
✒️ confusion matrix 가 책마다 블로그마다 위키마다 사이트마다 순서 가 다 다름. 어떤 기준으로 봐야 할까?
-> 사이킷런 기준으로 보는게 그나마 더 혼란스러움
🔷 예측값이 1인 것을 기준으로 하는 계산 => Precision
🔷 실제값이 1인것을 기준으로 하는 계산 => Recall
🔷 Precision을 사용할 때: 무고한 피고인에게 유죄 선고
🔷 Recall을 사용할 때: 양불(불량이 아닌데 불량이라고 했다하더라도 다시 불량인지 체크하면 됨), 암환자
