⭐Decision Tree
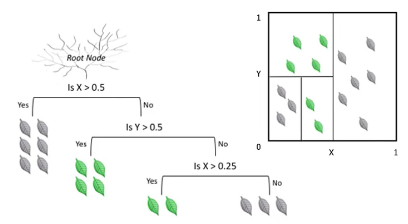
🎈1. 분류와 회귀 작업 및 다중 출력 작업이 가능한 다재다능한 머신러닝 방법론
🎈2. IF-THEN 룰에 기반해 해석이 용이
ex) Sunny일 때 노는 경우 2, 안 노는 경우3
overcast일 때 노는 경우 4, 아닌 경우 0
Rainning일때 나가서 노는 경우 3번, 아닌경우 2번
등등
🎈3. 일반적으로 예측성능이 우수한 랜덤 포레스트 방법론의 기본 구조
🎈4. CART 훈련 알고리즘을 이용해 모델 학습
- 각각의 변수에 대해 한번씩 분할을 함(수직 분할)
-> 수직 분할: 하나의 변수 입장에서 가장 좋은 분할을 반복적으로 진행함
✒️ 해석력을 주는 큰 역할
⭐Decision Tree Classifier
ex) IF-THEN 규칙 예시
- 만일 내일 날씨가 맑고 습도가 70% 이하이면 아이는 밖에 나가서 놀것이다
or
만일 내일 비가 오고 바람이 불면 아이는 밖에 나가 놀지 않을 것이다
💥 데이터 공간상에서는 각 변수를 수직 분할한 것과 동일함
- 새로운 예제
❓ 빨간색 도형과 파란색 도형의 구분
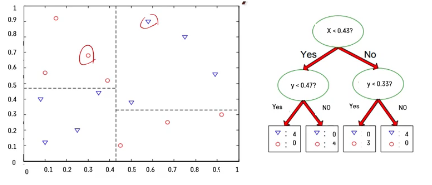
❓ 수직 분할은 어떻게 해야 잘 할 수 있을까?
❗ 데이터 공간의 순도(순수한 정도)가 증가되게끔 영역 구분
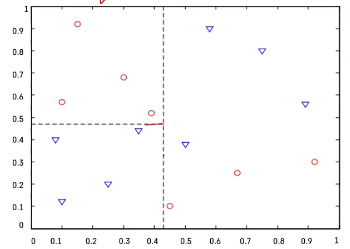
-> 위 아래에 같은 특성이 있는 관측치들만 있음
💥 순도가 높은, 좋은 평가의 경계썬
💥 순도의 증가 == 트레이닝 에러 감소 == minimize loss
❓ 좋은 경계선은 어떻게 찾나?
❗ 후보군을 설정해서 여러가지 경계선 만들기 -> 순도를 높여주는 영역 찾기
🔷 Decision tree는 하나의 변수만 가지고 분할하기 때문에 계산에 드는 Cost가 그리 높지 않고 빠르게 찾아서 학습이 가능함
- 분류 후 활용
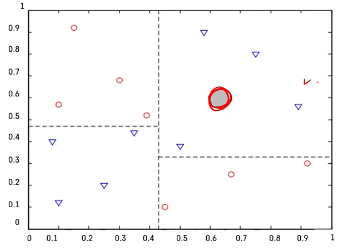
❓ 회색 관측치가 들어왔다! 어떤 클래스로 분류되어야 할까?
-> 100% 파란색 관측치들이 있는 곳에 들어왔기 때문에 파란색 세모일 가능성이 아주아주 크다
❓ 지금처럼 100%가 아니고, 불순도가 섞여있다면??
-> 다수결로 따르자~
✅불순도
: 한 노드에 속하는 샘플들의 클래스 비율을 이용하여 특정 노드가 얼마나 잘 구분이 되었는지 측정

- 노드: 각각의 관측치들이 중간중간 단계마다 거쳐가는 공간
- pi는 i번쩨 노드에 있는 훈련 샘플 중 클래스 k에 속한 샘플의 비율을 의미
🔷 불순도 == Gini Index
✅CART 알고리즘
: Classfication and regresion tree - 불순도를 최소화하도록 최종 노드를 계속 이진 분할하는 방법론
- 왼쪽 오른 쪽의 gini index를 구한 후 최종 가중평균을 내리변 불순도가 나옴
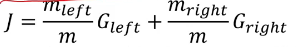
- 이 과정은 최대 깊이가 되거나 불순도를 줄이는 분할을 찾을 수 없을 때 중단됨
✅특징
- 훈련 데이터에 대한 제약 사항이 없기에 과대적합의 문제가 일어나기 쉬움
- 훈련에 제약을 두는 방법인 Regularization으로 과대 적합의 문제를 해결할 수 있음
- 하이퍼 타라미터
-max_depth: 트리의 최대 깊이 제어
-min_samples_split: 분할되기 위해 노드가 가져야하는 최소 샘플 수
-min_samples_leaf: 리프 노드가 가지고 있어야 할 최소 샘플 수
-max_leaf_nodes: 리프 노드의 최대 수
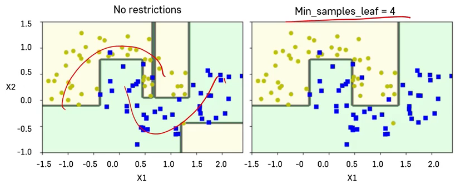
-> regularzation 적용 여부
⭐Decision Tree Regression
- classifier는 다수결을 사용해 다수에 속하는 클래스로 분류/ gini index 사용
- regression은 평균을 이용해 값을 예측/ mse 사용(불순도 대신 연속형 변수를 위한 평가 지표, 오차개념)
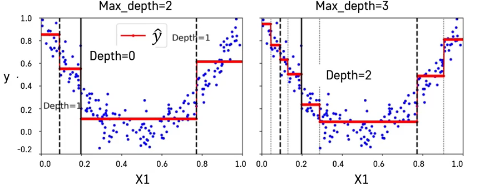
-> 빨강 선이 예측 결과
✒️ classifier와 regression 모두 regularization 적용하는 것이 아주 중용
⭐clustering (군집화)
-비지도 학습의 대표적인 예
-> 비지도 학습: 정해진 답은 없고 스스로 기준을 만들고 분류
-> 예측보다는 데이터에서의 의미를 파악하고 기준을 만드는데 사용
-아무런 정보가 없는 상태에서 데이터를 분류하는 방법
✅ k-means clustering
- 클러스터링에서 가장 일반적으로 사용되는 알고리즘
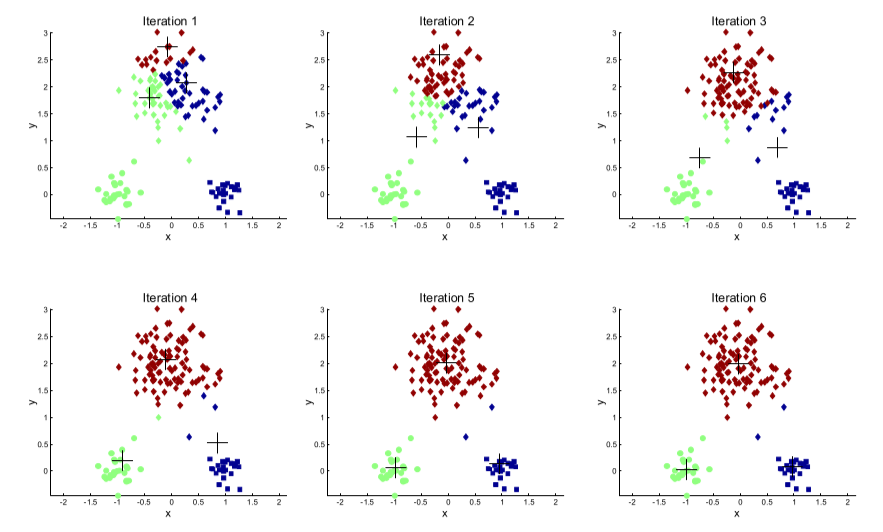
-> 군집 중심점(centroid)이라는 특정한 임의의 지점을 선택해 해당 중심에 가장 가까운 포인트들을 선택하는 군집화 기법이다. K-Means이므로 K개의 centroid를 지정. 이때 가장 가까운 포인트를 선택한다는 점에서 K-Means는 거리 기반 군집화 방법
• 임의로 데이터를 k 개의 그룹으로 나눔
• 각 그룹의 중심점 계산하고, 중심점에서 가까운 레코드를 찾아서 클러스터 업데이트
• 위 과정을 계속 반복해서, 더이상 중심점이 변화하지 않을 때 까지 반복함
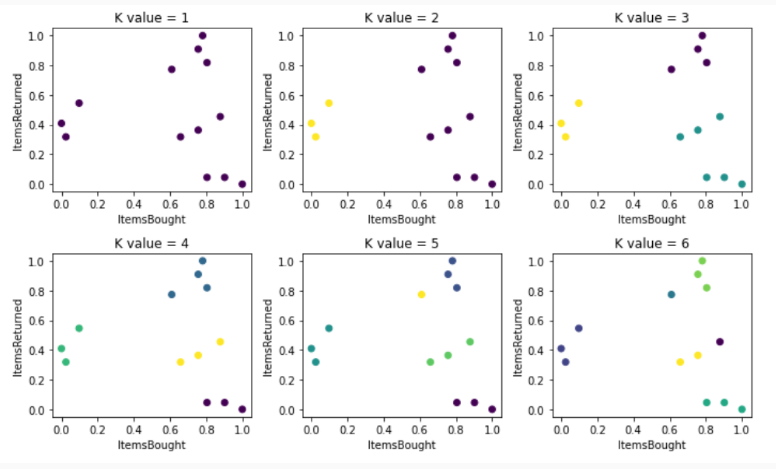
- 코드 예시
# K 값을 늘려가며 반복 테스트
for i in range(1, 7)
# 클러스터 생성
estimator = KMeans(n_clusters = i)
ids = estimator.fit_predict(processed_data[['ItemsBought', 'ItemsReturned']])
# 2행 3열을 가진 서브플롯 추가 (인덱스 = i)
plt.subplot(3, 2, i)
plt.tight_layout()
# 서브플롯의 라벨링
plt.title("K value = {}".format(i))
plt.xlabel('ItemsBought')
plt.ylabel('ItemsReturned')
# 클러스터링 그리기
plt.scatter(processed_data['ItemsBought'], processed_data['ItemsReturned'], c=ids)
plt.show()- 결과값:
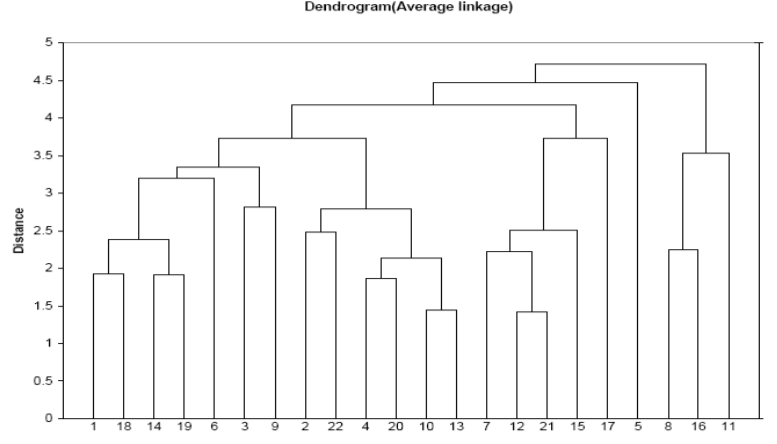
✅ 계층적 클러스터링 (Hierarchical Clustering)
• 미리 클러스터의 수를 지정하지 않음
• 개별 레코드가 하나의 클러스터로 간주하고 시작
• 가장 가까운 두 개의 클러스터를 하나의 클러스터로 결합
• 이러한 step by step 과정을 Dendrogram 으로 표시 가능함
ex) 아래 그림에서 (1,18), (14,19)가 각각 클러스터로 분류되었고, 이 두 클러스터가 상위 단계에서 하나의 클러스터로 결합함
ex)
진돗개, 세퍼드, 요크셔테리어, 푸들, 물소, 젖소
군집화1. 중형견, 소형견, 소
-> 중형견(진돗개, 세퍼드), 소형견(요크셔테리어, 푸들). 소(물소, 젖소)
군집화2. 개, 소
-> 개(진돗개, 세퍼드, 요크셔테리어, 푸들), 소(물소, 젖소)
군집화3. 동물
-> 동물(진돗개, 세퍼드, 요크셔테리어, 푸들, 물소, 젖소)
- 시각화
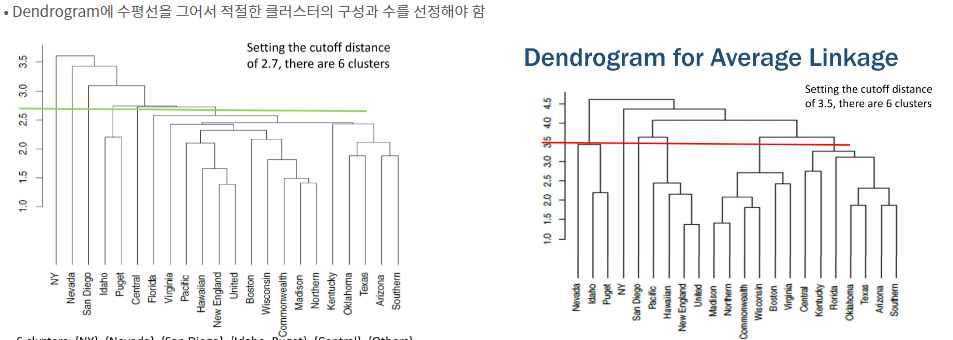
-> 선 위로 올라갈수록 클러스터가 병합됨
❤️출처: K-MOOC 실습으로 배우는 머신러닝
❤️출처: https://yeong-jin-data-blog.tistory.com/entry/%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0%EB%A7%81Clustering-%EA%B0%9C%EC%9A%94
