11/28
⭐복습
Q. 정확도로 제대로 된 모델의 성능을 측정을 하기 어려운 사례는 어떤게 있을까?
A. 희귀병 검사결과, 불량품 검출(양불 여부), 스팸메일 분류, 은행 대출 사기, 신용카드 사기, 상장폐지종목 여부,
게임 어뷰저, 광고 어뷰저, 그외 어뷰저
=> 이런 사례는 Accuracy로 측정하면 99.99 % 가 나온다면 제대로 측정하기가 어려움
-> 불균형한 데이터일 때 평가를 내리기 어려움
❗ 현실세계는 대부분 불균형한 데이터
Q. 1종 오류의 사례
-> precision을 사용
A. 스팸 메일, 중고차 성능 판별(성능이 좋지 않은 차량은 좋은 차량으로 판매했을 경우 생명과 직결되는 문제), 유무죄 선고(무고한 사람에게 유죄를 선고하면 문제)
Q. 2종 오류의 사례
-> recall을 사용
A. 암인데 암이 아니라고 예측, 지진이 났는데 대피명령이 없는 예측, 자율주행에서 앞에 사람이있는데 사람이라고 인식하지 못할때
- trade off
❗두 마리의 토끼를 다 잡을 수는 없다❗
-> 정밀도와 재현율 둘 다 모두 최대값으로 할 수 없다는 것 (정밀도가 극도로 높게 된다면 재현율은 낮아지고 재현율이 극도로 높다면 정밀도 값은 낮아짐)
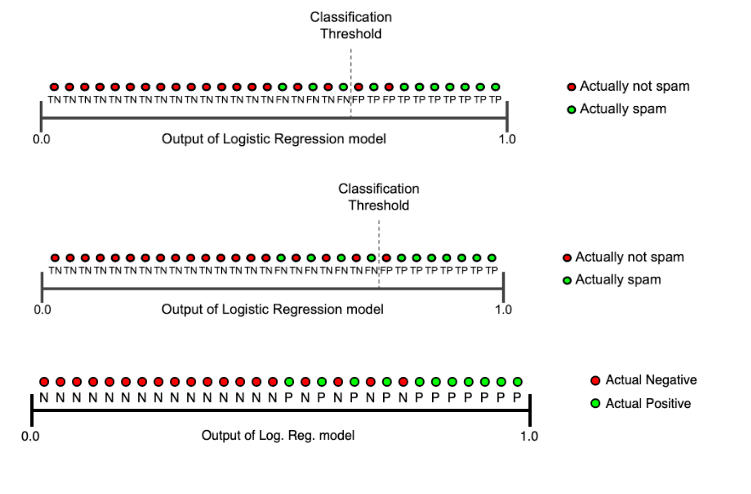
-> 임계값을 직접 정해서 True, False를 결정하게 되는데 보통 0.5 로 하기도 하고 0.3, 0.7 등으로 정하기도 함
-> 기존에는 예측을 할 때 주로 predict 를 사용했지만 predict_proba 를 하게 되면 0,1 등의 클래스 값이 아닌 확률값으로 반환
✒ 임계값 == Threshold
-> 임계값을 낮추게 된다는 것은 그만큼 모델이 Positive라고 예측하는 횟수가 많아진다는 것과 동일한 의미
💥 threshold를 내리면 recall은 올라가고 precision은 내려가게 된다
💥 '공돌이의 수학정리 노트' 정리가 잘 되어있으니 참고!!
https://angeloyeo.github.io/2020/08/05/ROC.html
⭐0804 실습
✒️ zip 은 완전히 다 업로드 되어야 로드가 가능
✒️ csv 는 행기반으로 저장되어 있기 때문에 일부만 업로드 되더라도 불러올 수 있음
🎈 mount 기능 사용하는 법!
(파일 업로드가 느릴 때 구글 드라이브랑 연결하기)
1. 왼쪽 아래에 있는 '<>' 기호인 코드 스니펫 클릭

2. 검색창에 'mount'입력
3. mounting Google~~을 누리고 오른쪽 중간에 있는 삽입 버튼 클릭
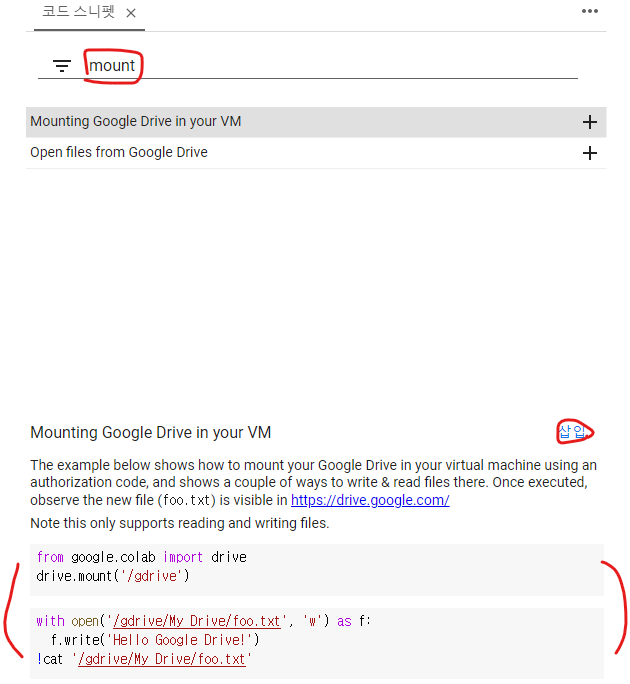
4. 새로운 코드가 생성되면서 실행하면 로그인을 하라는 팝업창이 뜸
5. 두번째 생성된 코드를 실행하여 새로만든 폴더인 'data' 폴더 경로를 확인
6. data 폴더 새로 고침하면 foo.txt가 새로 생성
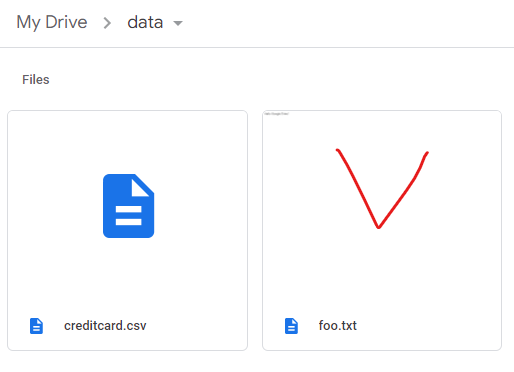
7. pd.read_csv"/gdrive/My Drive/data/creditcard.csv")를 입력하면 원하는 파일을 불러옴
=> 구글 드라이브를 마운트하면 매번 colab에 업로드 하지 않아도 되고 좀 더 빠름
✅predict_proba는 확률 값을 예측
-> 각 클래스마다의 확률을 예측
-> 0,1 일때 각각의 확률을 의미
-> [0.5, 0.5][0.3, 0.7] [0.7, 0.3] 이렇게 나오기도 함
-> 클래스가 여러 개 일 때 이런 확률을 사용해서 예측하기도 함
y_pred_proba = model. predict_proba(X_test)
-
np.argmax는 값이 가장 큰 인덱스를 반환함
import numpy as np np.argmax(y_pred_proba, axis=1) -
predcit로 예측한 결과값과 predict_proba로 예측한 결과값이 똑같다
(y_pred == y_pred_proba_class).mean()
=> 1.0
✅cross tab과 혼동행렬
pd.crosstab(y_test, y_pred)

`from sklearn.metrics import confusion_matrix
cf = confusion_matrix(y_test, y_pred)
sns.heatmap(cf, annot=True, cmap="Blues")`
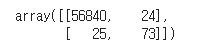
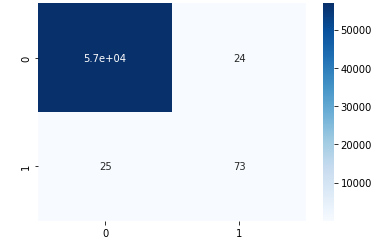
✅classification_Report을 사용한 혼동행렬
cr = classification_report(y_test, y_pred)
print(cr)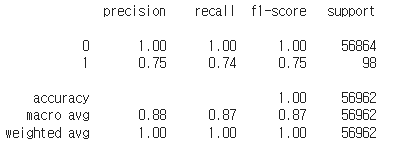
✅f1 score, precision, recall 구하기
from sklearn.metrics import f1_score
f1_score(y_test, y_pred)

# precision_score, recall_score
from sklearn.metrics import precision_score, recall_score
print(precision_score(y_test,y_pred))
print(recall_score(y_test, y_pred))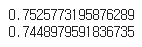
🎈 신용카드 사기에는 recall 측정 지표 사용이 더 적절
🎈 게임에서도 어뷰저가 아닌데 어뷰저로 처리하는 경우가 있음
-> 어뷰저라니 기분 나빠, 게임 접겠다! 라는 고객이 있을 수 있음
-> 그럴 경우는 recall 측정 지표가 더 적합
⭐샘플링
✅샘플링 이유
- 실제로 데이터를 탐색하다 보면 불균형한 데이터가 多
ex) 1년 중 눈이 오는 날과 눈이 오지 않는 날
10년의 기간 중 지진이 나는 날
공장에서 정상 제품과 불량품
암 검진 대상 중 암에 걸린 환자와 걸리지 않은 환자
등등 - 5대 5로 균형 있게 분포되어 있는 분류 문제가 더 드물다
-> 불균형한 데이터 문제를 해결하기 위해 under-sampleing과 over-sampling을 함
💥 두 값의 비율을 맞춰주는 것
✅언더 샘플링 VS 오버 샘플링
under-sampling: 더 값이 많은 쪽에서 일부만 샘플링하여 비율을 맞춰주는 방법
: 구현이 쉽지만 전체 데이터가 줄어 머신러닝 모델 성능이 떨어질 우려있음
over-sampling: 더 값이 적은 쪽에서 값을 늘려 비율을 맞춰준 방법
: 어떻게 없던 값을 만들어야 하는지에 대한 어려움이 있음
✅언더 샘플링
- 1인데이터가 492개이기 때문에 0인 데이터를 랜덤하게 492개 추출하면 언더샘플링이 된다
y.value_counts()
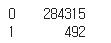
df_1 = df[df['Class']==1]
df_0.shape, df_1.shape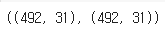
- 각각 만든 샘플링을 하나로 합쳐준다
df_under['Class'].value_counts()
✅오버 샘플링
- SMOTE(Synthetic Minority Over-sampling Technique): 오버 샘플링 기법
-적은 값을 늘릴 때, k-근접 이웃의 값을 이용하여 합성된 새로운 값을 추가
-새로 생성된 값은 좌표평면으로 나타냈을 때, k-근접 이웃의 중간에 위치
-> k값 직접 지정해줘야 함
sm = SMOTE(random_state = 42)
X_resample, y_resample = sm.fit_resample(X,y)
X_resample.shape, y_resample.shape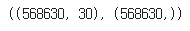
- y의 value_counts VS y_resample의 value_counts


💥 y.resample 값은 x,y모두 같다
✅샘플링 데이터로 f1 score, precision, recall 구하기
f1_score(y_test, y_pred)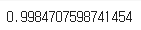
precision_score(y_test, y_pred), recall_score(y_test, y_pred)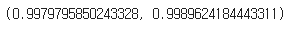
🔷 precision 예측값 기준 => 1종 오류
🔷 recall 실제값 기준 => 2종 오류
💥 SMOTE를 사용한 오버 샘플링 데이터로 모델을 만들어 예측한 결과 비교
-> 샘플링을 사용하지 않고 데이터를 나눠 학습했을 때와 비교해서 f1_score, precision, recall 값이 모두 높아짐
💥 정답 클래스가 불균형하면 학슴을 제대로 하기 어렵기 때문에 오버 샘플링이나 언더 샘플링으로 정답 클래스를 비슷하게 만들어 주면 더 나은 성능을 냄
⭐딥러닝
: 인공지능 스스로 일정 범주의 데이터를 바탕으로 공통된 특징을 도출하고 그 특징으로 예측값 출력 >> 사람같지만 보다 빠른 학습속도, 원하는 빅데이터를 학습 후 활용 가능
✒️ 1950년대 이전부터 신경망 연구가 있었지만 하드웨어의 한계와 데이터 부족의 이류로 활성화되지 못했음
✒️ 이미지, 사운드, 모션 입력만으로도 딥러닝 모델을 만들어주는 편리한 웹사이트!!!
https://teachablemachine.withgoogle.com/
✅순전파(Foward Propagation)
: 인공 신경망에서 입력층에서 출력층 방향으로 예측값의 연산이 진행되는 과정
-> 입력값은 입력층, 은닉층을 지나며 각 층에서의 가중치와 함께 연산되며, 출력층에서 모든 연산을 마친 예측값 도출
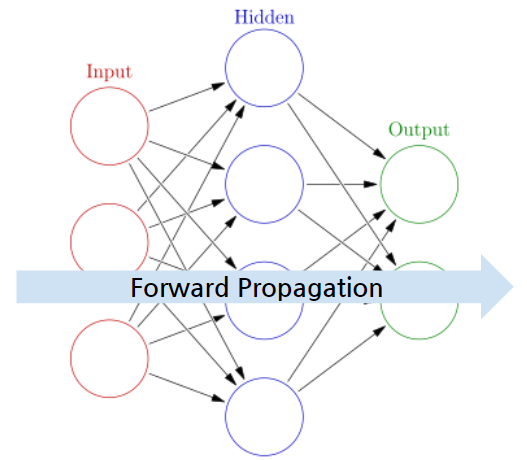
✅역전파
: 순전파와 반대로 출력층에서 입력층 방향으로 계산하면서 가중치를 업데이트
-> 가중치 비율을 조정하여 오차 감소를 진행 >> 다시 순전파 진행으로 오차 감소확인 가능
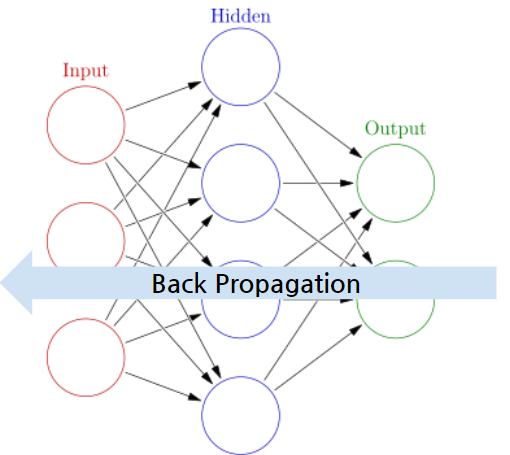
-> 각각의 가중치를 조정하는 방법/ 속도는 느리지만 안정적인 결과를 얻을 수 있음
✅활성화 함수
1. 시그모이드
: S자형 곡선 또는 시그모이드 곡선을 갖는 수학 함수(e. 로지스틱 함수)
- 모델 제작에 필요한 시간을 줄이나 미분 범위가 짧아 정보가 손실되는 단점이 있음
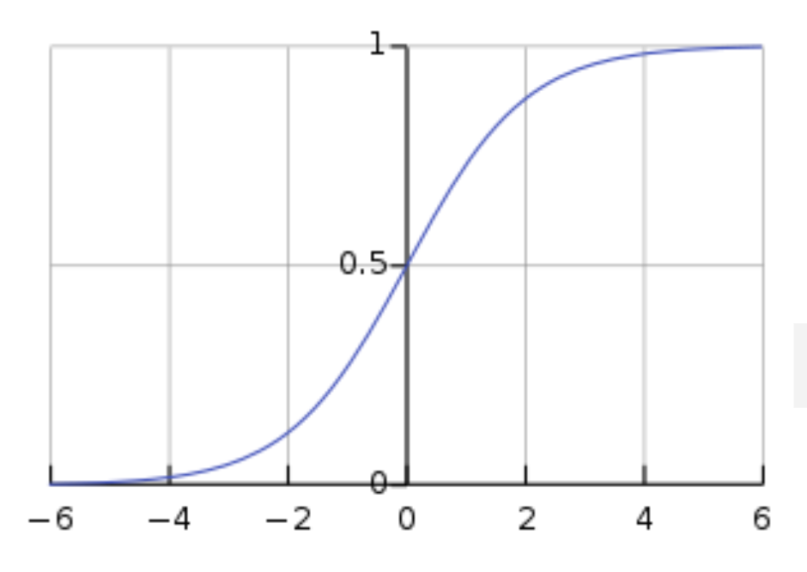
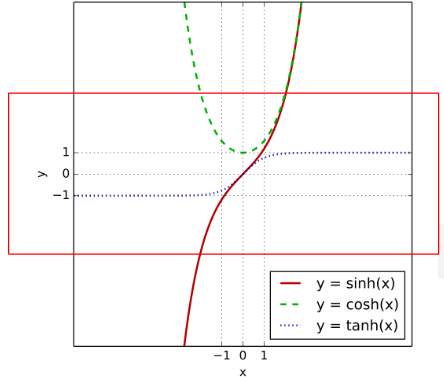
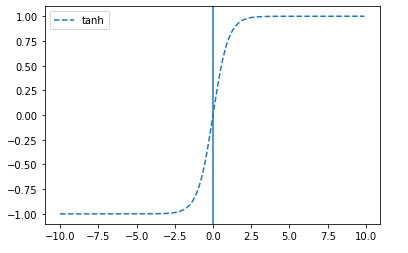
2. tanh-하이퍼 볼릭탄젠트 함수
: sigmoid의 대체로 사용될 수 있음
: 쌍곡선 함수로써 삼각함수와 유사한 성질을 가지고 표준 쌍곡선을 매개 변수로 표시할 때 나오는 함수
- 테이터 중심을 0으로 위치시키는 효과가 있기에 다음층의 학습이 더 쉽게 이루어짐
-> 시그모이드와 비교시, 출력 범위가 더 넓고 경사면이 큰 범위가 더 크기 때문에 더 빠르게 수렴하여 학습 성능이 높아짐 - 미분 범위가 짧아 정보가 손실된다
11/29
⭐영상리뷰
https://www.youtube.com/watch?v=aircAruvnKk
- Deep Learning: 층을 깊게 쌓을 수 있기 때문에 Depp Neural network라 불림
Q. Fully Connected Network 에는 1차원형태로 네트워크에 데이터를 주입해야 하는데 어떻게 비정형 데이터(표형태가 아니라 이미지, 음성, 텍스트 등)를 잘 다룰까
A. 전처리 레이어에서 이미지, 음성, 텍스트 등을 전처리 하는 기능을 따로 제공, 1차원 형태로 네트워크에 데이터를 주입
✒ DNN(Deep Neural Network) => CNN => RNN 순으로 배울 예정!
Q. 왜 28x28 이미지를 입력받을 때 784 로 입력받을까
A. fully connected network에서는 1차원으로만 주입이 가능하기 때문에 네트워크에 데이터를 주입하기 위해
🔷 CNN, RNN 에서는 데이터 전처리를 어떻게 해줄지를 전처리 기능을 제공하고 마지막에는 Fully Connected Network 를 통과하게 된다
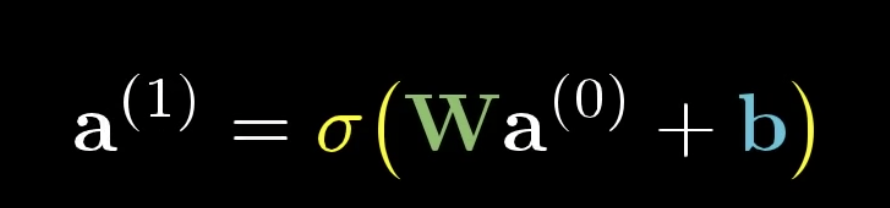
-> w == weight의 약자로 보통 가중치로 번역
-> b == bias의 약자로 보통 편향으로 번역
🔷 가중치는 두번째 레이어가 선택하려는 뉴런의 픽셀 패턴을 알려주며 bias는 뉴런이 활성화되려면 가중치의 합이 얼마나 더 높아야 하는지를 알려준다.
⭐TesnsorFlow
-x를 소문자로 사용
-ndim = 차원의 수
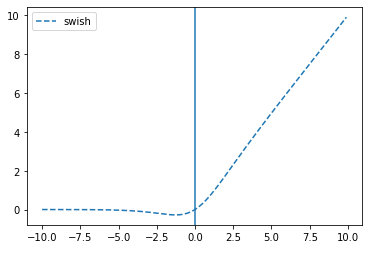
🔷 sigmoid: 활성화 함수로 오늘 실습을 할 예정인데 relu, swish 등 다양한 활성화 함수가 있다
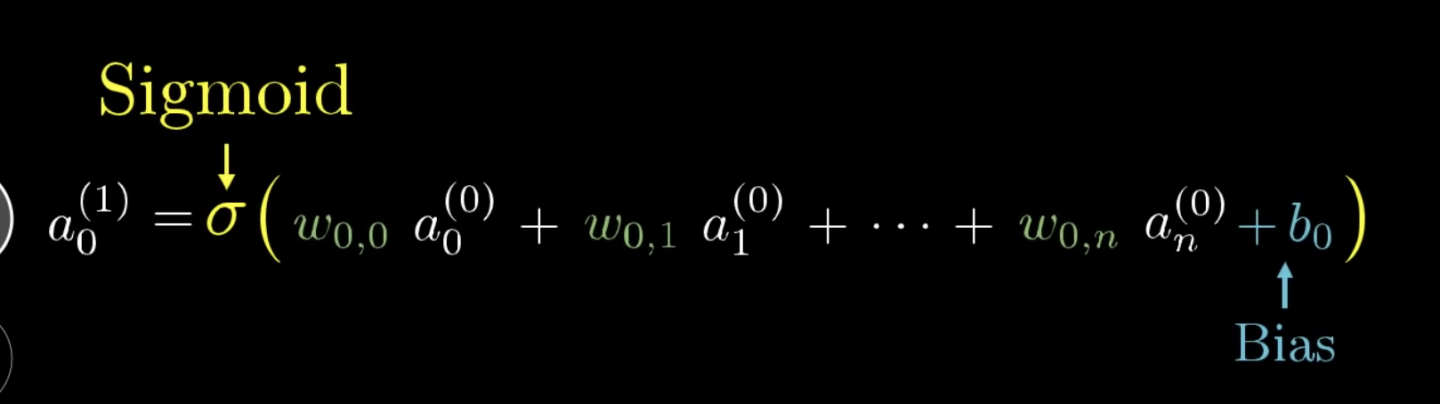
Q. sigmoid의 단점
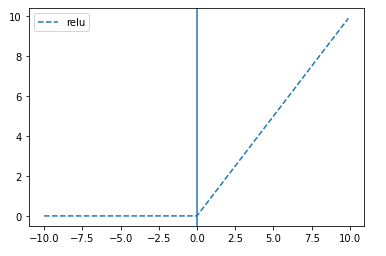
A. 기울기 소실 문제, gradient vanishing
Q. 위 문제를 해결하기 위해 나온 활성화 함수는?
A. ReLu, 리키렐루 함수
Q. dropout 이 무엇일까?
A. 일부 노드를 제거하고 사용하는 것(과대적합 방지하기 위해)
-> 학습속도와는 상관없음
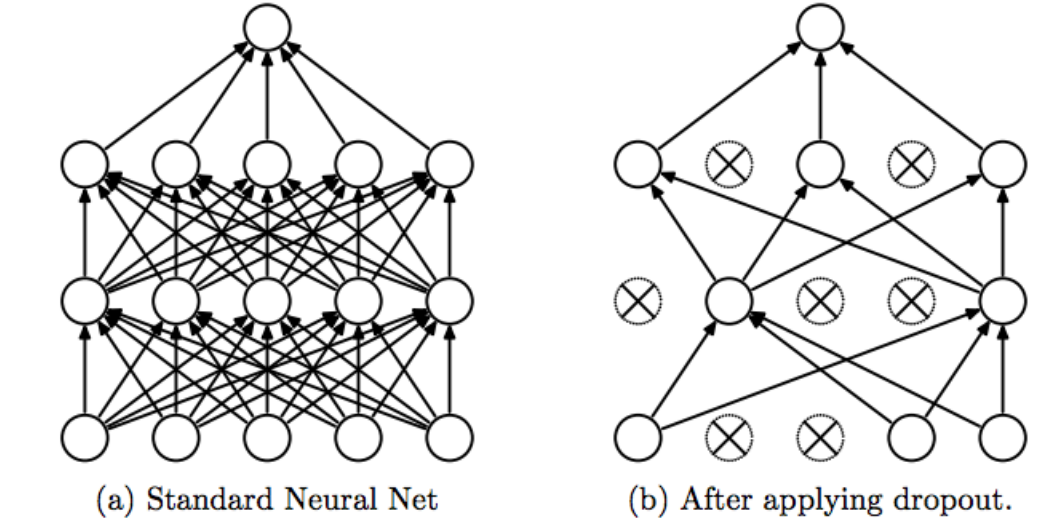
ex)
tf.keras.layers.Dropout(0.2)-> 128개 중에 20퍼센트를 날리겠다
🔷 MNIST 손글씨 이미지 데이터 셋은 왜 만들었을까~~?
-> 우편번호를 읽어내기 위해!
-
MNIST: 손으로 쓴 숫자들로 이루어진 대형 데이터베이스 -> 다양한 화상처리 시스템을 트레이낭하기 위해 일반적으로 사용
-
60,000개의 트레이닝 이미지와 10,000개의 테스트 이미지를 포함
-
트레이닝 세트의 절반과 테스트 세트의 절반은 NIST의 트레이닝 데이터셋에서 취합하였으며, 그 밖의 트레이닝 세트의 절반과 테스트 세트의 절반은 NIST의 테스트 데이터셋으로부터 취합
-
예시 코드
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
idx = 38
display(pd.DataFrame(x_train[idx]).style.background_gradient())
sns.heatmap(x_train[idx], cmap="gray")
plt.title(f"label : {y_train[idx]}")
💥 각 이미지에 어떤 값이 있는지 확인하는 법
🔷 output = activation(dot(input, kernel) + bias)
출력 = 활성화함수(행렬곱(input, kernel) + 편향)
🔷 tf.keras.layers.Dense(units=128, activation='relu')
=> units(노드) 개수, 층(레이어)수는 하이퍼파라미터
⭐딥러닝 학습 과정
-> 출력값고 실제값을 비교하여 그 차이를 최소화하는 가중치와 편향의 조합 찾기
: 가중치는 오차를 최소화하는 방향으로 모델이 스스로 탐색(역전파)
:오차계산은 실제 데이터를 비교하며 손실함수(모델의 정확도 평가시 오차를 구하는 수식)를 최소화하는 값을 탁색하기에 알맞은 손실함수를 선정하는것이 중요
- 알맞은 손실함수를 찾아 최소화하기 위해 고안된 방법은 경사하강법이고 옵티마이저로 경사하강법 원리를 이용
🔷 손실함수
: 머신러닝 혹은 딥러닝 모델의 예측값과 사용자가 원하는 실제값의 오차를 의미
: 손실함수의 함수값이 최소화되도록 하는 가중치(weight)와 편향(bias)를 찾는 것이 목표
🔷 경사하강법
: 손실함수의 현재 위치에서 조금씩 손실이 낮아지는 쪽으로 가중치를 움직이며 최솟값을 찾는 방법
🔷 옵티마이저
: 최적화 방법을 결정해주는 방식
: 경사하강법에 기반을 둠
-> local minima에 빠져 global minima를 찾지 못하는 것을 방지하기 위해 사용
-> 오차가 최소가 되는 지점을 찾기 위해 사용
💥 오차가 최소가 되는 지점을 찾기 위한 optimizer, 기울기, 방향, learning rate를 고려
🔷 loss: 손실율 측정(모델이 학습을 하고 결과값이 나오면 실제값과 얼마나 차이가 있는지 평가하는 손실함수)
-> 븐류에서는 주로 크로스 엔트로피를 사용
🔷 metrics: 평가지표
Q. 분류 결과의 품질을 측정하기 위해 Loss 손실함수로 크로스엔트로피를 사용하는데 공식 앞에 마이너스는 왜 있을까?
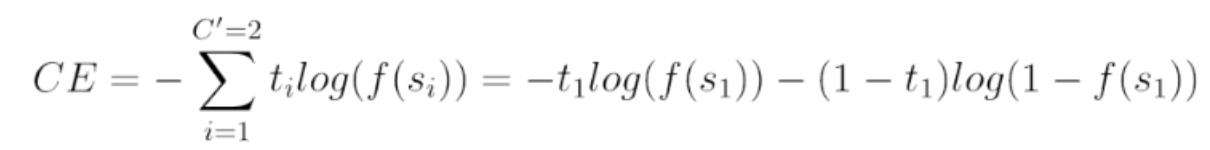
A. 위 값들은 확률값이기 때문에 양수로 만들어줘야 함
✅소프트맥스
- 다중 클래스 분류
- 다중 클래스 분류의 출력층에서 사용
- N개로 반환되면 모든 확률의 합이 1이 됨
[0.1 ,0.05 ,0.7, 0.15] - 가장 큰 값으로 반환되는 값을 해당 클래스로 선택
ex) np.argmax([0.1 ,0.05 ,0.7, 0.15])
-> 0.7에 해당되는 인덱스 순서인 2가 반환
-> 정답 클래스의 종류는 4개
✒️ np.argmax는 가장 큰 값의 인덱스를 반환한다!!
💥 다 더했을 때 1
💥 각 클래스의 확률을 출력
✅학습하고 훈련하기
model.fit(x_train, y_train, epochs=5)
-> 여러번 학습을 하면(여러번 실행하면!) loss가 점점 줄어든다
-> 학습을 하며 weight와 bias 값을 업데이트 하기 때문!


- epoch가 증가할수록 loss가 줄어들고 accuracy가 올라간다
- eopch가 증가할수록 loss가 감소하지 않고 accuracy가 나아지지 않는다면 더 이상 학습하지 않고 중단할 수도 있음
- loss는 cross entropy를 사용하는데 확률값이 얼마나 섞여있나를 본다
- 0에 가까울 수록 다른 확률값이 석여있찌 않는 것
- 이 네트워크의 첫 번째 층인 tf.keras.layers.Flatten은 2차원 배열(28 x 28 픽셀)의 이미지 포맷을 28 * 28 = 784 픽셀의 1차원 배열로 변환합니다. 이 층은 이미지에 있는 픽셀의 행을 펼쳐서 일렬로 늘립니다. 이 층에는 학습되는 가중치가 없고 데이터를 변환하기만 합니다.
픽셀을 펼친 후에는 두 개의 tf.keras.layers.Dense 층이 연속되어 연결됩니다. 이 층을 밀집 연결(densely-connected) 또는 완전 연결(fully-connected) 층이라고 부릅니다. 첫 번째 Dense 층은 128개의 노드(또는 뉴런)를 가집니다. 두 번째 (마지막) 층은 10개의 노드의 소프트맥스(softmax) 층입니다. 이 층은 10개의 확률을 반환하고 반환된 값의 전체 합은 1입니다. 각 노드는 현재 이미지가 10개 클래스 중 하나에 속할 확률을 출력합니다.
🔷 2개라도 기본이 softmax이고 실습할 때는 바이너리 분류를 할 예정이라 sigmoid로 지정할 예정

🔷 텐서플로 VS 파이토치의 차이는 seaborn VS plotnine 처럼 라이브러리 도구의 API 차이
🔷 시각화 할 때도 data, x, y, color(hue) 이런 용어를 알고 있다면 API 가 달라지더라도 비슷하게 사용할 수 있는 것과 유사
🔷 직접 딥러닝 모델을 밑바닥부터 짜서 구현할 수도 있지만, 기능들을 함수나 메서드로 감싸서 코드 여러 줄을 한 두줄의 API 를 호출해서 사용할 수 있게 만들어 놓은 도구
🔷 분류:binary_crossentropy(이진분류)
categorical_crossentropy
(다중분류: one-hot-encoding)
sparse_categorical_crossentropy
(다중분류: ordinal Encoding)
❗❗ 힘들어도 어려워도 겁..먹지 말자..❗❗
❤️1) 다른 모델에 적용한다면 층 구성을 어떻게 할것인가? 입력-은닉-출력층으로 구성된다
2) 예측하고자 하는 값이 분류(이진, 멀티클래스), 회귀인지에 따라 출력층 구성, loss 설정이 달라진다
이건 예제를 몇 개 연습해 보면서 익히는 것을 추천!!
3) 분류, 회귀에 따라 측정 지표 정하기
4) 활성화함수는 relu 를 사용, optimizer 로는 adam 을 사용하면 baseline 정도의 스코어가 나온다
5) fit 을 할 때 epoch 를 통해 여러 번 학습을 진행하는데 이 때, epoch 수가 많을 수록 대체적으로 좋은 성능을 내지만 과대적합(오버피팅)이 될 수도 있다
6) epoch 수가 너무 적다면 과소적합(언더피팅)이 될 수도 있다
⭐0901 실습
✅활성화 함수
- sigmoid
plt.axvline(0)
plt.legend()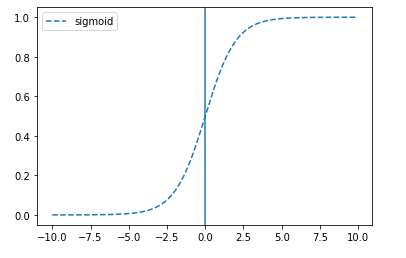
-
tanh
plt.plot(x, tf.keras.activations.tanh(x), linestyle='--', label="tanh")
-
swish
plt.plot(x, tf.keras.activations.swish(x), linestyle='--', label="swish")
-
relu
plt.plot(x, tf.keras.activations.relu(x), linestyle='--', label="relu")
✅층 설정
- 신경망의 기본 구성 요소는 층(layer)
- 층은 주입된 데이터에서 표현을 추출합니다.
대부분 딥러닝은 간단한 층을 연결하여 구성 - tf.keras.layers.Dense와 같은 층들의 가중치(parameter)는 훈련하는 동안 학습
Q. 당뇨병 여부 예측문제에서는 출력층을 어떻게 구성?
A. 시그모이드로 해야함(당뇨병이다/아니다)
-> 다중분류와 이진분류의 차이를 생각
- 공식 문서의 멀티클래스 분류 층 구성을 이진 분류 층 구성으로 변경하는 코드
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])✅레이어 만들기
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(units=128, input_shape=[input_shape]),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1, activation='sigmoid')
])- 입력층: flatten -> dense로 변경한 이유
-> 1차원으로 바꿔줄 필요 없음!(flatten은 2차원을 2차원으로 만들어주려는 것)
✅모델 컴파일
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])🔷 다중 분류일 때: 활성화함수=softmax, 출력층 n개
🔷 이진 분류일 때: 활성화함수=sigmoid, 출력층 1개
11/30
⭐0901 실습 -> 분류
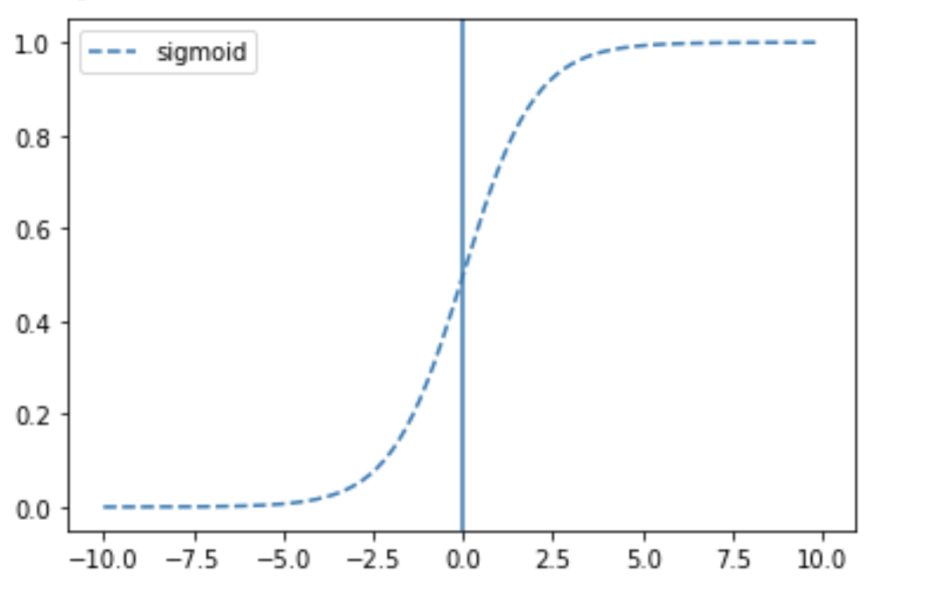
Q. sigmoid 그래프를 2진 분류에 사용한는 법?
A. 특정 임계값(ex 0.5)을 정해서 크고 작다를 통해 True, False 값으로 판단
-> 임계값은 보통 0.5를 사용하지만 다른 값을 사용하기도 함
✅모델 컴파인
- 회귀 : MSE, MAE
- 분류 :
-바이너리(예측할 값의 종류가 둘 중 하나) : binary_crossentropy
-멀티클래스(예측할 값의 종류가 2개 이상) :
categorical crossentropy(one-hot형태의 클래스 예: [0, 1, 0, 0])
sparse categorical crossentropy(정답값이 0, 1, 2, 3, 4 와 같은 형태일 때)
✅예측
- 예측값 시각화
(y_pred.flatten() > 0.5).astype(int)
-> 임계값을 정해서 특정값 이상이면 True, 아니면 False로 변환해서 사용할 예정

Q. 바이너리이면 결과가 2개 나와야 하는게 아닌가?
A. 소프트 맥스라면 2개가 나온다
-> 바이너리로 했기 때문에 예측값이 각 row 당 하나씩 나옴
-> y_pred = model.predict(X_test)로 나오는 값은 확률값(sigmoid) 0~1 사이의 값을 가진다
💥 바이너리를 사용하고 sigmoid를 사용한다면 결과는 1개가 나옴
✅딥러닝 파라미터(IN 레이어 & 학습 코드)
🎈 성능 변경
1) 레이어
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(units=128, input_shape=[input_shape]),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1, activation='sigmoid')
])✒️ 보통 레이어 구성을 2의 제곱으로 사용하지만 꼭 그렇지는 않아도 된다
🎈1. 히든 레이어 추가
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(units=128, input_shape=[input_shape]),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1, activation='sigmoid')
])
-> 히든 레이어 수를 더 늘릴 수 있다.
🎈2. unit 수 변경
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(units=128, input_shape=[input_shape]),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1, activation='sigmoid')
])
-> 128을 2의 제곱으로 변경(꼭 제곱 아니어도 되긴 함)
🎈3. 활성화함수: activation 함수 변경
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(units=128, input_shape=[input_shape]),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1, activation='sigmoid')
])
-> relu, swish, elu, selu 등등
2) 학습
history = model.fit(X_train, y_train, epochs=500, validation_split=0.4,
callbacks=[PrintDot(), early_stop], verbose = 0)🎈1. epochs 수
history = model.fit(X_train, y_train, epochs=500, validation_split=0.4,
callbacks=[PrintDot(), early_stop], verbose = 0)
-> 수를 늘리면 늘릴수록 좋은 결과가 나오지만 너무 늘리면 과대적합 될 수 있음
🎈2. validation_split 비율
history = model.fit(X_train, y_train, epochs=500, validation_split=0.4,
callbacks=[PrintDot(), early_stop], verbose = 0)
🔷 drop-out 코드는 바로 위 layer에만 적용된다
-> 모든 레이어에 적용하고 싶으면 모든 레이어 밑에 drop-out 코드를 작성해줘야한다
✅정리
💥 loss: 손실함수, 회귀는 MSE, MAE, 분류는 바이너리와 멀티클래스에 따라 나누어짐, 훈련에 사용해서 가중치와 편향을 업데이트
💥 metric: 평가지표, 회귀는 MSE, MAE, 분류일 때는 accuracy, 검증에 사용
Q. 분류일 때 사용하는 loss의 종류?
A, crossentropy
- 이진분류 - binarycrossentropy(label 값이 이진분류 되어 있어서)
- 다중분류 : 원핫인코딩 - categorical_crossentropy( label 값이 다중분류, 즉 원핫인코딩 되어 있어서)
- 다중분류 : ordinal - sparse_categorical_crossentropy( label 값이 다중분류, 즉 ordinal Encoding 되어 있어서)
-> loss 값을 보고 label이 어떤 형태인지 알 수 있음
(label 값이 바이너리, 원핫, 오디널 인코딩이 되어있는지 보고 loss값을 지정해야 함)
💥 보통은 정형데이터는 딥러닝보다는 머신러닝이 대체적으로 좋은 성능을 내기도 한다. 물론 딥러닝이 좋은 성능을 낼때도 있다!
💥 중요한 것은 데이터 전처리와 피처엔지니어링이 성능에 더 많은 영향을 준다는 것!!!
💥 garbage in garbage out: 좋은 데이터를 통해 모델을 만드는게 성능에 가장 중요한 역할
⭐TF 회귀 튜토리얼 실습 -> 회귀
Q. 스케일값이 클때는?!
A. 정규화를 하자
-> Min-Max, standard, robust
-> standard, min-max, robust => 스케일만 바꿀 뿐이지 분포는 변하지 않는다
✅horsepower
horsepower = np.array(train_features['Horsepower'])
horsepower_normalizer = layers.Normalization(input_shape=[1,], axis=None)
horsepower_normalizer.adapt(horsepower)- 사이킷런의 전처리 기능이나 직접 계산을 통해 정규화 해주는 방법도 있음
- TF에서도 정규화 하는 기능을 제공
🔷 horsepower_normalizer: horsepower 변수를 가져와서 해당 변수만 정규화 해주는 코드
horsepower_model = tf.keras.Sequential([
horsepower_normalizer,
layers.Dense(units=1)
])- 전처리 레이어를 추가해서 모델을 만들 때 전처리 기능을 같이 넣어줄 수 있음
- 장점: 전처리 방법을 모르더라도 추상화된 기능을 사용해서 쉽게 정규화 해줄 수 있음
- 단점: 추상화된 기능은 소스코드, 문서를 열어보기 전에는 어떤 기능인지 알기 어려움
Q. 레이어 구성에서 출력층의 분류와 회귀의 차이는?
A. 분류는(n, activation='softmax'), (1, activation='sigmoid')
회귀는 항등함수 -> 그대로 출력
- 항등함수: 입력받은 값을 그대로 출력하는 함수
💥 회귀의 출력층은 항상 layers.Dense(units=1)이 형태
Q. 분류와 회귀 실습간의 loss의 차이는?
A. 분류: crossentropy 회귀: mae, mse 등
✅심층 신경망(DNN)을 사용한 회귀
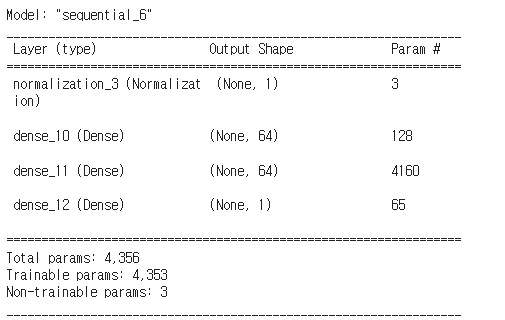
def build_and_compile_model(norm):
model = keras.Sequential([
norm,
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
model.compile(loss='mean_absolute_error',
optimizer=tf.keras.optimizers.Adam(0.001))
return model-> loss='mean_absolute_error': loss값을 보니 회귀 모델이다!!
-
항등함수로 출력
layers.Dense(1)
-> 값 하나로 출력됨
-
선형회귀를 사용했을 때와 loss 값이 어떤 차이가 있나?
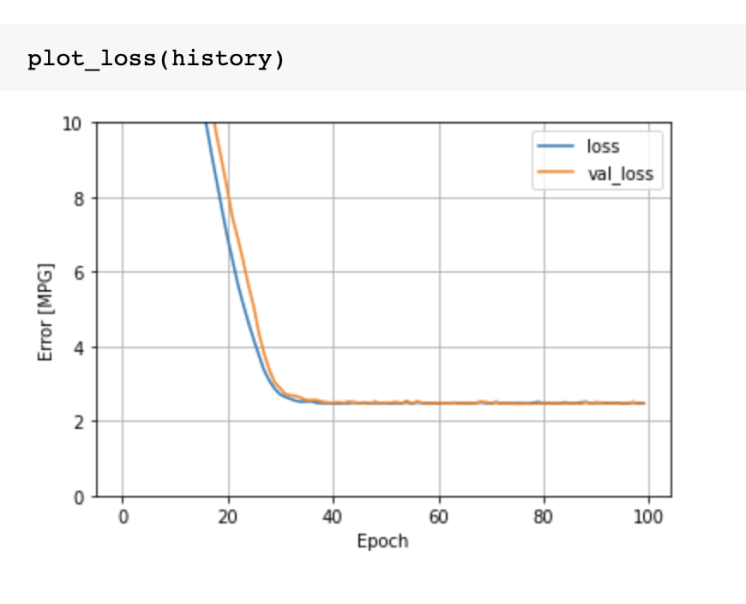
-> 선형회귀를 사용했을때보다 DNN을 사용했을 때 성능이 나아짐을 확인
(loss 값이 작은게 성능이 좋은 것)
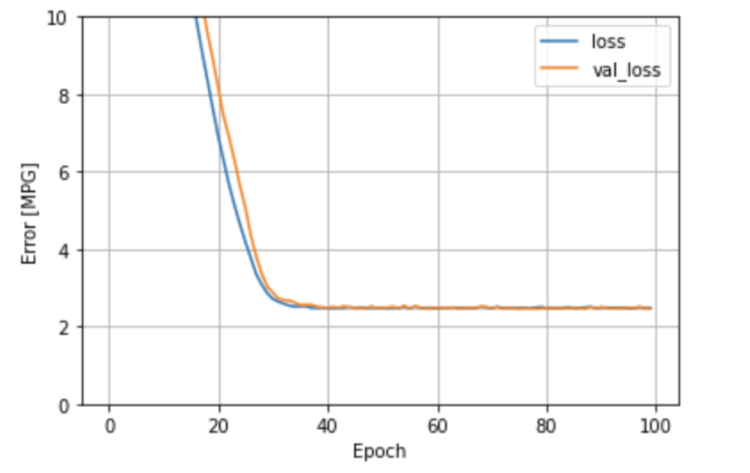
🔷 선형입력 다중회귀
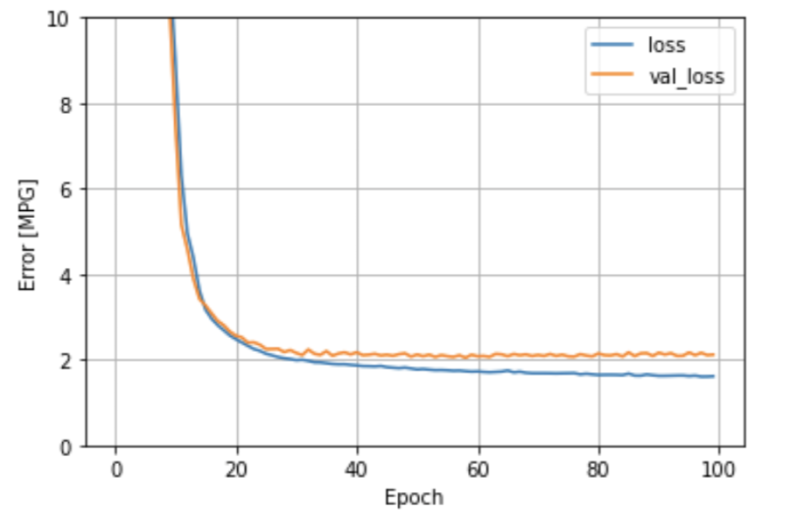
🔷 DNN 다중회귀
-> 이 값은 오차가 작게 나와야 잘 예측한 모델
✅regression 실습에서 보고자 하는 point
1) 정형데이터 입력층 input_shape
2) 정규화 레이어의 사용 => 직접 정규화해도 된다
3) 출력층이 분류와 다르게 구성이 된다는 점
4) loss 설정이 분류, 회귀에 따라 다르다.
5) 입력변수(피처)를 하나만 사용했을 때보다 여러 변수를 사용했을 때 성능이 더 좋아졌다. => 반드시 여러 변수를 사용한다라고 해서 성능이 좋아지지 않을 수도 있지만 너무 적은 변수로는 예측모델을 잘 만들기 어렵다는 점을 알수 있다.
💥 loss는 훈련 손실값, val_loss는 검증 손실값
Q. 어떻게 해야 val 결과가 나올까?
A. validation_split 지정
Q. validation_split은 어디서 지정?
A. model.fit할때
-> model.fit(X_train, y_train, epochs, validation_split)
Q. dnn_model.predict(test_features).flatten() 예측 결과 뒤에 flatten() 이 있는 이유는 무엇일까
A. 2차원 값을 1차원 형태로 만들어주기 위해서(tesnsorflow같은 경우 예측값이 기본으로 2차원으로 나옴)
⭐0902 실습 -> 회귀
✅레이어 구성
-
input shape값을 구하기
input_shape = train.shape[1] -
레이어를 만들기: 분류와 동일하지만 회귀는 출력을 하나로 함!
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(units=128, input_shape = [input_shape]),
tf.keras.layers.Dense(128, activation='selu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1)
])-> 마지막 줄 Dense(1)만 다름!
✅모델 컴파일
- optimizer는 아무거나 골라도 상관없음!
-> 이 중에!!
dir(tf.keras.optimizers)
model.compile(optimizer=optimizer,
loss=['mean_absolute_error'],
metrics=["mae", "mse"])✅모델 학습
early_stop = tf.keras.callbacks.EarlyStopping(monitor='val_loss', patience=10) history = model.fit(X_train, y_train, epochs=1000, verbose=0, callbacks=[early_stop], validation_split = 0.2)
✅정리
🔷1. 딥러닝 모델을 조정하여서 회귀 딥러닝 모델 생성
(분류 모델과 다르게 Dense 출력 유닛 1로 설정, Compile에서 loss, metrics 변경)
🔷2. 자원과 시간을 아끼기 위해서 학습 과정 중 성능이 비슷하면 멈출 수 있도록 EarlyStopping 설정
(tf.keras.callbacks.EarlyStopping)
(tf.keras.callbacks.EarlyStopping -> 성능이 비슷함에도 남은 epochs가 많이 남았다면 시간이 아까우니까~~~)
🔷3. 학습 과정에서 validation_split을 설정하여 검증 데이터셋도 설정
(모델이 과적합인지 과소적합인지 제 성능을 하는지 확인하기 위해서-> model.fit(validation_split=0.2)))
🔷4. 딥러닝 모델을 학습
(model.fit)
🔷5. 학습한 모델의 성능을 history 표를 보면서 측정
(여기서 우리 전에 배웠던 loss, mae, mse 지표를 보면서 모델이 잘 예측했는지 평가하기)
-> 검증모델에서의 지표와 비교를 해보고(val_loss, val_mae, val_mse 등등) 과대적합이 됐는지, 과소적합이 됐는지도 볼 수 있다
❤️ 출처: 오늘코드
❤️ 출처: 멋쟁이 사자처럼 AI school
