12/12~12/15 딥러닝 3주차
12/12
⭐이번주 진행 주제 : 텍스트 분석과 자연어처리를 할 예정입니다.
- 이번주 목요일에는 보강이 있습니다. 다음주 수요일에도 보강이 있습니다.
- CNN은 주로 이미지에 주로 사용이되고 물론 텍스트에도 사용을 합니다. 하지만 이미지에서 더 나은 성능을 보여줍니다.
- 텍스트 분석을 할 때 머신러닝(Bag Of Words, TF-IDF), 딥러닝(RNN) 순서로 사용할 예정입니다.
텍스트 분류, 텍스트로 주식의 가격을 예측하는 회귀 모델을 만든다든지 할 때는 주로 RNN이 CNN 보다 더 나은 성능을 내는 편입니다. RNN은 주로 순서가 있는 데이터에 사용합니다. 예를 들어 시계열데이터, 자연어도 말의 앞뒤에 순서가 있기 때문에 시계열, 자연어 등에 사용됩니다. - 자연어처리 실습 이후에는 RNN 으로 시계열 데이터를 다뤄볼 예정입니다.
⭐1004 실습
Q. 이미지 데이터를 읽어오면 다차원 형태의 구조로 되어있는데 np.array 형태로 되어있음에도 왜 다시 np.array 로 만들어주었을까?
A. 리스트 안에는 np.array 로 되어있더라도 여러 장의 이미지를 하나로 만들 때 파이썬 리스트에 작성해 주었음 -> 이미지 여러 장을 하나의 변수에 넣어주었을 때 해당 변수의 데이터 타입은 파이썬 리스트 구조.
train_test_split에 사용하기 위해 넘파이 형태로 변경해 줌.
Q. 정답값을 균일하게 나누기 위해 사용된 train_test_split의 옵션은?
A. stratify=y
✅compile 파라미터
- 옵티마이저(Optimizer) - 데이터와 손실 함수를 바탕으로 모델의 업데이트 방법을 결정.
- 지표(Metrics) - 훈련 단계와 테스트 단계를 모니터링하기 위해 사용. 다음 예에서는 올바르게 분류된 이미지의 비율인 정확도를 사용합.
- 손실 함수(Loss function) - 훈련 하는 동안 모델의 오차 측정. 모델의 학습이 올바른 방향으로 향하도록 이 함수를 최소화해야 함. 최적의 가중치를 찾도록 해야함
회귀 : MSE, MAE
분류 :
바이너리(예측할 값의 종류가 둘 중 하나) :
binary_crossentropy
멀티클래스(예측할 값의 종류가 2개 이상) :
categorical_crossentropy(one-hot형태의 클래스 예: [0, 1, 0, 0]) -> 1004 파일은 one hot 형태이기 때문에 이걸 사용
sparse_categorical_crossentropy(정답값이 0, 1, 2, 3, 4 와 같은 형태일 때)
✅fit
- validation_split을 사용하지 않고 위에서 따로 validation_data를 나눠서 사용한 이유는 class를 statify로 충화표집을 해주지 않으면 균일하게 학습이 되지 않는다.
- 멀티클래스일때 데이터를 따로 균일하게 나눠서 학습시키지 않으면 성능이 낮게 나올 때가 많음
history = model.fit(x_train, y_train, validation_data=(x_valid, y_valid),
epochs=20, callbacks=[earlystop])df_hist[['loss', 'val_loss']].plot()
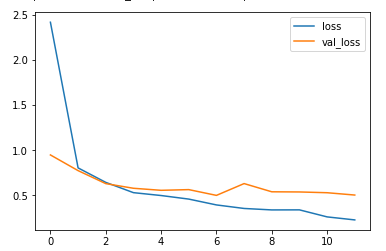
-> 줄어들고 있긴 하지만 점점 격차가 벌어지는 것을 보아 오버피팅이 되고 있다
-> 하지만 개선해볼 여지가 있음
❓❓HOW❓❓
❗ 레이어 수를 늘리자❗
Q. accuracy와 val_accuracy 혹은 loss와 val_loss가 대략 어느정도 차이나면 오버피팅이라 판단할까?
A. 시각화를 해보는게 좀 더 직관적으로 볼 수 있는데 더 이상 val_loss 값이 감소하지 않는데, loss 값은 줄어든다면 오버피팅 되었다고 판단하는게 나아보이며, 딱 수치가 얼마가 차이가 나면 오버피팅이다 이렇게 공식으로 얘기는 잘 하지 않는 편이다!!
-> val_loss 값이 나아지지 않는데 loss 값만 나아진다면 확실하게 오버피팅
✅predict
- softmax로 출력했기 때문에 합이 1이 되는 값으로 출력이 된다
- 0번째 테스트 이미지에 대한 분류 확류임 -> 여기서 클래스를 어떻게 찾을까?
=> np.argmax 사용(가장 큰 값의 인덱스를 변환)
y_pred[0]
`y_pred[0].sum()' -> 1.0
✅예측값과 실제값 비교
- TF로 예측한 값을 csv 파일과 비교
-
y_test = test["labels"]```
y_predict[:5](y_test == y_predict).mean()
-> 0.7666666666666667(성능이 낮은편)
✅테스트 이미지 시각화
-
주의할 점 : test 의 인코딩 값 순서와 train, valid 에서 사용한 순서가 맞는지 확인이 필요.
-
예를 들어 train 의 0 은 cloudy 인데 test 는 rain 이 아닌지 확인해볼 필요가 있음.
-
목적 : 전체 테스트 이미지 시각화 => 어떤게 맞았는지 틀렸는지
-
서브플롯으로 30개 이미지를 한번에 시각화를 하려면 row, col 을 구해서 해당 위치에 이미지를 넣어주어야 함.
-
이미지를 여러 개 시각화 했을 때 알아서 위치에 들어가지 않기 때문에 어떤 위치.
-
이미지의 주소를 지정해 준다고 생각하면 된다.
-
정답이 있는 test.csv 파일을 읽으면 파일이름과 정답이 있다.
-
test.csv 순서대로 이미지를 가져와서 일단 먼저 시각화 하고 예측값과 비교해서 맞았는지 틀렸는지를 보기
class_name = lb.classes_
fig, axes = plt.subplots(nrows=6, ncols=5, figsize=(20, 20))
for i, tcsv in test.iterrows():
col = i % 5
row = i // 5
Image_id = tcsv["Image_id"]
img_label = tcsv["labels"]
img = plt.imread(f"{root_dir}/alien_test/{Image_id}")
color = "red"
if img_label == y_predict[i]:
color = "blue"
axes[row, col].imshow(img)
axes[row, col].set_title(
f"test: {class_name[img_label]}, predict : {class_name[y_predict[i]]}", color=color)-> 틀린 것은 빨간색으로 표시
✅정리
CNN
1) MNIST, FMNIST, cifar10, 말라리아 혈액도말 이미지, 날씨이미지 를 통해 이미지 분류 실습을 알아보았다.
2) CNN Explainer 를 통해 Conv, Pooling 과정을 이미지로 이해해 봤다.
3) 왜 완전밀집연결층을 첫 레이어 부터 사용하지 않고 합성곱 연산을 했을까?
-> 합성곱을 하면 3D => 2D 로 변경
-> 완전밀집연결층은 flatten해서 이미지를 입력해주는데 그러면 주변 이미지를 학습하지 못 하는 문제가 생기기 때문에 합성곱 연산은 array로 입력하고 출력층에서 flatten해서 결과를 출력
💥 완전밀집연결층은 flatten해서 이미지를 입력해주는데 그러면 주변 이미지를 학습하지 못 하는 문제가 생긴다
💥 합성곱, 풀링 연산으로 특징을 학습하고 출력층에서 flatten해서 완전연결밀집층에 주입해 주고 결과를 출력
4) 기존에 사용했던 DNN 에서 배웠던 개념을 확장해서 합성곱 이후 완전연결밀집층을 구성하는 형태로 진행해 봤다.
5) 이미지 전처리 도구는 matplotlib.pyplot 의 imread 를 통해 array 로 읽어올 수도 있고, PIL, OpenCV를 사용할 수도 있다.
6) 이미지 증강 기법 등을 통해 이미지를 변환해서 사용할 수도 있다.
⭐자연어 처리
Q. 머신러닝에서 텍스트로 된 카테고리 범주 값을 어떻게 처리 했을까
A. 인코딩 처리(원핫, ordinary)
- 자연어 처리로 할 수 있는 일
-> 음성 인식, 내용 요약, 번역, 사용자의 감성 분석, 텍스트 분류 작업, 질의 응답 시스템, 챗봇 등
Q. 텍스트는 영어로 학습한 내용을 한국어로 예측하면 성능이 어떻게 될까?
A. 정확도가 굉장히 떨어짐
- 데이터 정체 및 전처리
(텍스트 처리에서)
-기계가 텍스트를 이해할 수 있도록 텍스트를 정제하여 신호와 소음을 구분
-이상치로 인한 과대적합 방지
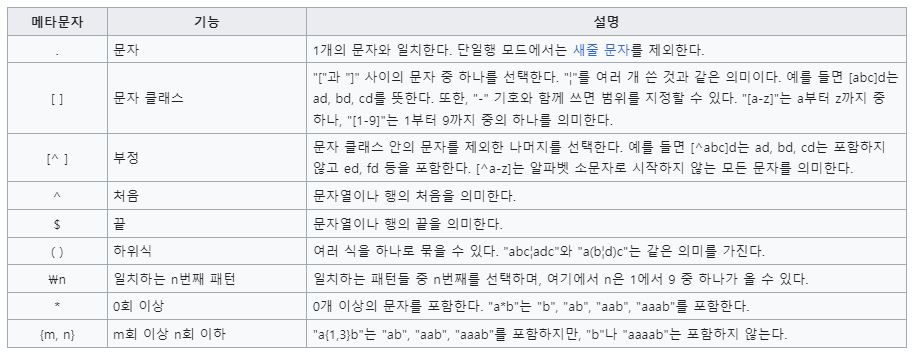
Q. 정규표현식 [0-9] 는 무엇을 의미?
A. 모든 숫자
Q. 정규표현식 [^0-9] 는 무엇을 의미?
A. 모든 숫자를 제외한 것
=> 정규표현식(regular Expression): 문자, 숫자를 제외한 특수문자를 제외할 때 주로 사용. 특정 패턴으로 텍스트 전처리 시에도 사용. 정규표현식은 그 자체로 프로그래밍 언어
✅토큰화
: 텍스트 조각을 토큰이라고 하는 더 작은 단위로 분리
: 패턴을 찾는데 매우 유용하며 형태소 분석 및 표제어를 위한 기본 단계로 간주
: 특정 문자(예. 띄어쓰기, 공백)으로 텍스트 데이터를 나눠주는 것
⭐1101 실습
- 목표: BagOfWords,TF-IDF => 단어를 숫자로 인코딩 하는 방법 알아보기
Q. 했다. 했어요. 했습니다. 했나요? 하다 => 하다로 통일해서 변형해 주면 어떤 효과가 있을까?
A. 데이터를 전처리 해줌 ( 머신러닝에서 데이터를 binning 해주는 것과 비슷한 효과를 냄)
-> 비슷한 의미의 단어를 하나로 전처리해서 나중에 벡터화(인코딩을) 했을 때 데이터의 용량을 줄이고 모델에게 힌트도 줄 수 있다.
✅빈도 기반 워드 임베딩
- 원핫인코딩: 텍스트 데이터, 범주형 데이터 -> 수치형 데이터로 변경
: 머신러닝이나 딥러닝은 수치로된 데이터만 이해하므로 벡터에서 해당되는 하나의 데이터만 1로 변경하고 나머지는 0ㅇ으로 채움
✅back of words(BOW)
- 가장 간단하지만 효과적이라 널리 쓰임
- 장, 문단, 문장, 서식과 같은 입력 텍스트의 구조를 제외하고 각 단어가 이 말뭉치에 얼마나 많이 나타나는지만 헤아림
- 구조와 상관없이 단어의 출현횟수만 셈
- 단어의 순서를 완전히 무시하기에 맥락을 파악하지 않음
ex)
it's bad, not good at all.
it's good, not bad at all.
-> 두 문장의 순서가 달라 의미가 반대이지만 동일하게 반환됨
✅countvectorizer
: 사이킷런에서 제공하는 BOW를 만드는 방법
: 텍스트 문서 모음을 토큰 수의 행렬로 변환
: 문서 목록에서 각 문서의 feature(문장의 특징) 노출수를 가중치로 설정
- 매개 변수
🔷 analyzer : 단어, 문자 단위의 벡터화 방법 정의
🔷 ngram_range : BOW 단위 수 (1, 3) 이라면 1개~3개까지 토큰을 묶어서 벡터화
🔷 max_df : 어휘를 작성할 때 문서 빈도가 주어진 임계값보다 높은 용어(말뭉치 관련 불용어)는 제외 (기본값=1.0)
🔷 max_df = 0.90 : 문서의 90% 이상에 나타나는 단어 제외
🔷 max_df = 10 : 10개 이상의 문서에 나타나는 단어 제외
🔷 min_df : 어휘를 작성할 때 문서 빈도가 주어진 임계값보다 낮은 용어는 제외합니다. 컷오프라고도 합니다.(기본값=1.0)
🔷 min_df = 0.01 : 문서의 1% 미만으로 나타나는 단어 제외
🔷 min_df = 10 : 문서에 10개 미만으로 나타나는 단어 제외
🔷 stop_words : 불용어 정의
from sklearn.feature_extraction.text import CountVectorizer
cvect = CountVectorizer()
dtm = cvect.fit_transform(corpus) -> fit하고 transform 해주기
vocab = cvect.get_feature_names_out()
->단어 사전 보기
cvect.vocabulary_
-> 단어사전 {'단어':인덱스번호}로 보기
df_dtm = pd.DataFrame(dtm.toarray(), columns=vocab)
df_dtmdf_dtm값:
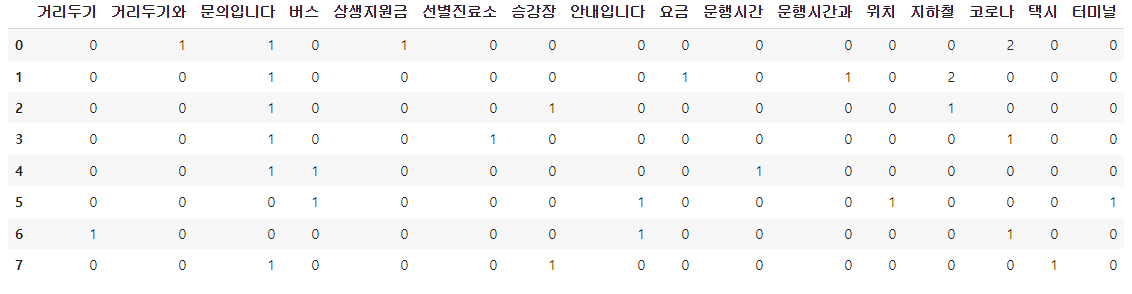
corpus값:

df_dtm 빈도수 값:

✅N-gram 언어 모델
: 모든 단어를 고려하지 않고 일부 단어만 고려
: n-gram에서 n은 단어의 수를 의미

ex) (1, 1) 이라면 1개의 토큰을 (2, 3)이라면 2~3개의 토큰을 사용
: 기본값 = (1, 1)
=> 맥락을 고려하기 위해 사용!!
cvect = CountVectorizer(ngram_range=(1,2))
dtm = cvect.fit_transform(corpus)
cvect.vocabulary_
vocab = cvect.get_feature_names_out()
df_dtm = pd.DataFrame(dtm.toarray(), columns=vocab)
df_dtmdf_dtm 빈도수 값:

- 모델을 받아 변환을 하고 문서 용어 행렬을 반환하는 함수를 만들어 재사용
def display_transform_dtm(cvect, corpus):
"""
모델을 받아 변환을 하고 문서 용어 행렬을 반환하는 함수
"""
dtm = cvect.fit_transform(corpus)
df_dtm = pd.DataFrame(dtm.toarray(), columns=cvect.get_feature_names_out())
return df_dtm.style.background_gradient()display_transform_dtm(cvect, corpus)cvect = CountVectorizer(ngram_range=(2,3)) display_transform_dtm(cvect, corpus)
✅min_df
: 기본값 = 1
: 지정된 임계깞보다 엄격하게 낮은 용어를 무시
ex) min_df=0.66은 용어가 어휘의 일부로 간주되려면 문서의 66%에 나타나야 함
: 어휘 크기를 제한하는데 사용
ex) 0.1이거나 0.2로 설정하면 10% 나 20%보다 많이 나타나는 용어만 학습
-> 너무 희귀한 단어 제거하는 효과
✅max_df
: 기본값 = 1
: max_df=int : 빈도수를 의미
: max_df=float : 비율을 의미
ex) 코로나 관련 기사를 분석하면 90%에 '코로나'라는 용어가 등장할 수 있는데, 이 경우 max_df=0.89 로 비율을 설정하여 너무 빈번하게 등장하는 단어를 제외할 수 있음
-> 너무 많이 등장하는 불용어를 제외하는 효과
✅max_features
: 기본값 = None
: 백터라이저가 학습할 어휘의 양을 제한
: corpus 중 빈도수가 가장 높은 순으로 해당 갯수만큼 추출
-> 단어를 너무 많이 사용해서 dtm 가 너무 커지는 것을 방지하기 위해 최대 단어를 제한
✅불용어
:문장에 자주 등장하지만 "우리, 그, 그리고, 그래서" 등 관사, 전치사, 조사, 접속사 등의 단어로 문장 내에서 큰 의미를 갖지 않는 단어
stop_words=["코로나", "문의입니다", '버스']
cvect = CountVectorizer(stop_words = stop_words)
display_transform_dtm(cvect, corpus)-> 불용어를 제외하고 학습
✅analyzer
: 기본값='word'
: 종류: word, char, char_wb
: 기능을 단어 n-그램으로 만들지 문자 n-그램으로 만들어야 하는지 여부
-> 옵션 'char_wb'는 단어 경계 내부의 텍스트에서만 문자 n-gram을 생성하고 단어 가장자리의 n-gram은 공백으로 채워진다
(char_wb: 단어 안에서만 n_gram을 사용,
char = 단어 밖에서도 n_gram을 사용)
: 띄어쓰기가 제대로 되어 있지 않은 문자 등에 사용
⭐TF-IDF
: 특정한 단어가 자주 등장한다고 문서에서 중요하다고 단정할 수는 없다!
-> 한 단어가 문서 집합 전체에서 얼마나 공통적으로 나타나는지를 구하는 방법
-> 상대적으로 전체 문서에서 얼마나 등장하는지 가중치 부여
✅TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
tfidfvect = TfidfVectorizer()
dtm = tfidfvect.fit_transform(corpus)
display_transform_dtm(tfidfvect, corpus)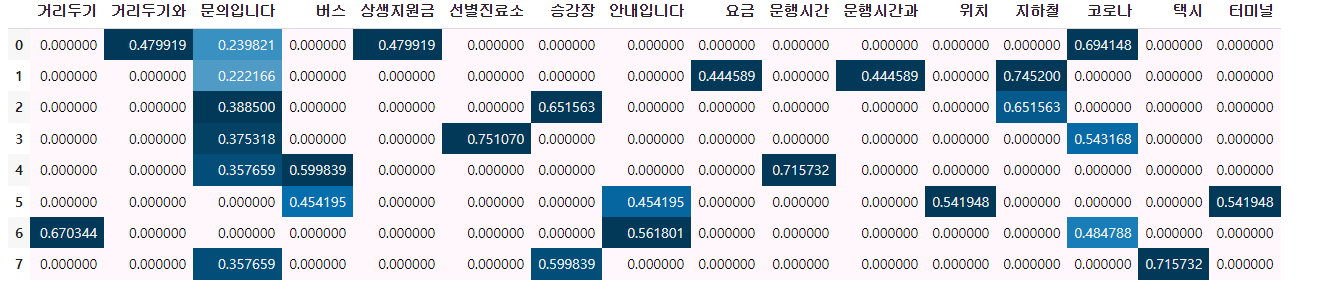
-> 운행시간은 1번 밖에 안나오지만 높은 가중치를 보임
💥 TF-IDF 전체 문서에서는 자주 등장하지 않지만 특정 문서에서 자주 등장한다면 가중치 값이 높게 나오게 된다. 모든 문서에 자주 등장하는 값은 가중치가 낮게 나오게 된다.
12/13
✒ 이미지를 다룰 때는 돈을 쓰지 않고 모델을 내 컴퓨터에서 돌리기 위해 이미지 사이즈, 레이어 개수 등을 조정
-> 텍스트 데이터에서 내 컴퓨터가 힘들어 한다면 여러 방법을 사용할 수 있는데 가장 간단한 방법이 max_features 를 작게 조정하는 것
-> 비지도학습의 차원축소를 사용하게 되면 데이터를 압축해서 사용할 수도 있지만 차원축소 과정에서도 메모리 오류가 발생할 수도 있는데 max_features 를 내 컴퓨터가 계산할 사이즈로 적당하게 조정해 주면 로컬 PC로도 어느정도 돌려볼 수 있다
(조금 더 조정한다면 min_df, max_df, stop_words 등을 조정해볼 수 있음)
⭐TfidfVectorizer
: 각 단어의 가중치를 부여한 비율
: 자주 등장하더라도 중요한 단어가 아닐 수 있고 중요한 단어일 수도 있음
: 주어진 말뭉치에서 매우 자주 발생하고 따라서 훈련 말뭉치의 작은 부분에서 발생하는 특징보다 경험적으로 덜 유용한 토큰의 영향을 축소하는 것
: 파라미터 = norm='l2'
, smooth_idf, sublinear, use_idf
💥 TF-IDF값이 낮으면 중요도가 낮은 것이고 TF-IDF 값이 크면 중요도가 큰 것
✅idf
: '원자'라는 낱말은 일반적인 문서들 사이에서는 잘 나오지 않기 때문에 IDF 값이 높아지고 문서의 핵심어가 될 수 있지만, 원자에 대한 문서를 모아놓은 문서군의 경우 이 낱말은 상투어가 되어 각 문서들을 세분화하여 구분할 수 있는 다른 낱말들이 높은 가중치를 얻게 된다
- 코드
idf = tfidfvect.idf_
vocab = tfidfvect.get_feature_names_out()
idf_dict = dict(zip(vocab, idf)) -> idf값을 딕셔너리 형태로 만들기
⭐1102 실습(분류 모델)
레이블링 하는 법
- 코로나가 들어가면 보건, 안 들어가면 교통
df.loc[df['문서'].str.contains('코로나'), '분류'] = '보건'
df.loc[~df['문서'].str.contains('코로나'), '분류'] = '교통'✅문제와 정답/ 데이터셋 나누기
X = df_dtm
y = df['분류']
1번 방법
python
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)2번 방법
X_train = X.smaple(frac=0.8, random_state=42)
y_train = y[X_train.index]
X_test = X.drop(X_train.index)
y_test = y[X_test.index]-> 균형있게 나누기가 쉽지 않음
3번 방법
split_count = int(X.shape[0] * 0.8)
X_train = X[:split_count]
y_train = y[:split_count]
X_test = X.drop(X_train.index)
y_test = y[X_test.index]💥 데이터가 균형있게 나뉘어졌는지 확인해야 함
⭐1103 실습(eda)
파생 변수 만들기
-
df["len"] = df['title'].map(lambda x:len(x))-> 문장 길이 세기 -
df["word_count"] = df['title'].map(lambda x:len(x.split()))
-> 공백 기준 단어 수 -
df["unique_word_count"] = df['title'].map(lambda x:len(set(x.split())))
-> 중복 제외 단어 수
✅문자 전처리
- 숫자 제거
re.sub('[0-9]', '', '12월 13일 눈이 내립니다.')
-> 결과값: 월 일 눈이 내립니다.
df['title'].map(lambda x: re.sub('[0-9]', '', x))
== df["title"].str.replace('[0-9]', '', regex=True)
- 특수 문자 제거
import string
punct = string.punctuation
df["title"] = df["title"].str.replace('[!\"\$\*]', '', regex=True)-> 특수문자 사용 시 정규표현식에서 메타 문자로 특별한 의미를 갖기에 \를 통해 예외처리를 해야함
-> \는 특수기호의 의미를 살려주기 위한 escape 처리 기호-
대 소문자로 변경
lower(), upper()
df["title"].str.lower() -
한글 영문 공백만 남기고 모두 제거
df["title"].str.replace('[^ㄱ-ㅎㅏ-ㅣ가-힣 a-zA-Z]', '', regex=True)
[^ㄱ-ㅎㅏ-ㅣ가-힣 a-zA-Z]
-> 을 사용하면 한글 공백 영문자만 제거
[^ㄱ-ㅎㅏ-ㅣ가-힣 ]
-> 을 사용하면 한글 공백만 제거
[^ㄱ-ㅎㅏ-ㅣ가-힣]
-> 을 사용하면 한글만 제거
- 공백 여러개를 하나로
re.sub("[\s]+", " ", "공백 전처리")
-> 공백 전처리
re.sub('[ㅎ]+', 'ㅎ', 'ㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎㅎ')
-> ㅎ
re.sub('[ㅋ]+', 'ㅋ', 'ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ')
-> ㅋ
df["title"].str.replace("[\s]+", " ", regex=True)
-> 여러개의 공백을 하나의 공백으로 치환
- 불용어 제거
1번 방법:df["title"].map(lambda x: remove_stopwords(x))
2번 방법: df['title'].map(remove_stopwords)
✅word cloud
- 시각화 하는 기능
def display_word_cloud(data, width=1200, height=500):
word_draw = WordCloud(
font_path=r"/Library/Fonts/NanumBarunGothic.ttf",
-> 폰트 불러오기
width=width, height=height,
stopwords=["합니다", "입니다"],
background_color="white",
random_state=42
)
word_draw.generate(data)
plt.figure(figsize=(15, 7))
plt.imshow(word_draw)
plt.axis("off")
plt.show()- 폰트 경로 코드(코랩)
!apt-get install fonts-nanum -qq > /dev/null
!fc-cache -fv
import matplotlib as mpl
mpl.font_manager._rebuild()
findfont = mpl.font_manager.fontManager.findfont
mpl.font_manager.findfont = findfont
mpl.backends.backend_agg.findfont = findfont- 폰트 경로(윈도우)
r"C:\Windows\Fonts\malgun.ttf"-> 폰트가 있는지 확인
C:\Windows\Fonts\malgun.ttf-> 폰트 설치
from glob import glob font_path=r"C:\Windows\Fonts\*"-> 폰트 지정
✒️ 폰트 속성에 있는 이름 사용하기
-
하나의 기사만 가져오기
display_word_cloud(df.loc[0, 'title'])

-
모든 기사 가져오기
display_word_cloud(' '.join(df['title']))

-
특정 주제 가져오기
display_word_cloud(' '.join(df.loc[df['topic']== '세계', 'title']))
or
display_word_cloud(' '.join(df.loc[df['topic']=='정치', 'title']))
12/14
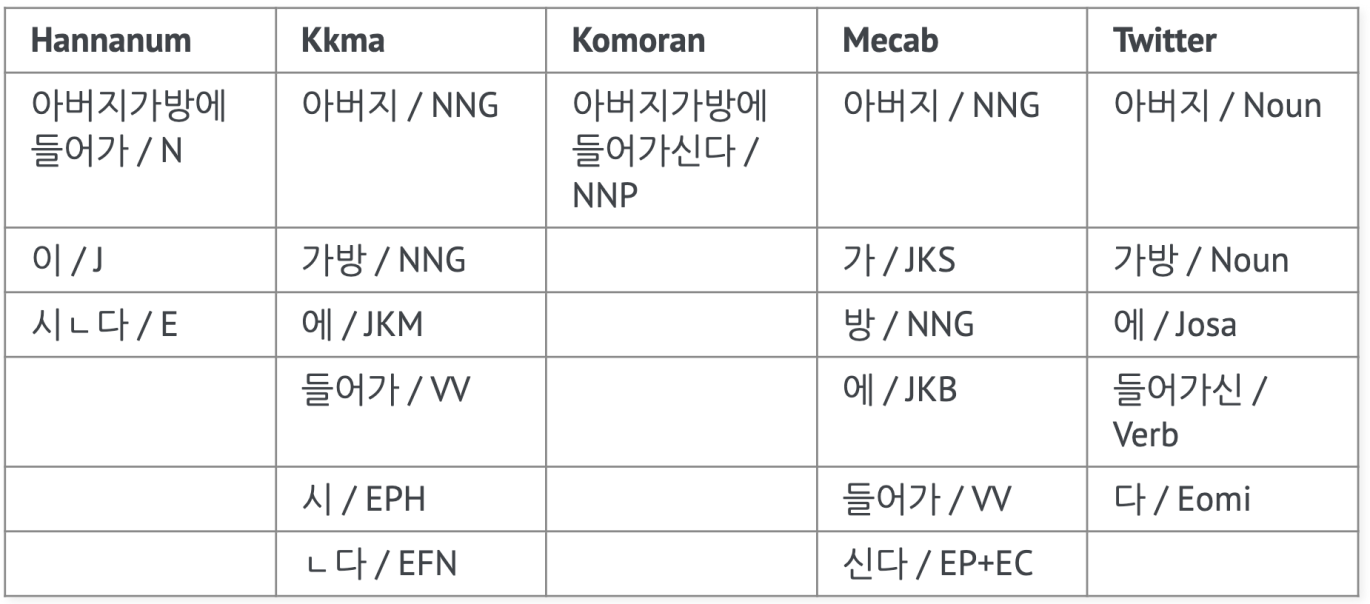
⭐1104 실습(품사 태깅)
목적: KoNLPy로 한국어 형태소 분석기를 사용해 보는 것
- 속도만 봤을 때는 mecab(은전한닢 으로 일본어 형태소 분석기를 한국어에 맞게 제작)이 가장 빨라 보이지만 목적에 따라 선택해서 사용
- 코모란은 자바에서 사용할 수 있도록 만들어진 형태소 분석기
-> 파이썬 환경에서 느리다라고 해서 다른 환경에서도 느린 것은 아님
*pos
- nouns
- morphs
✒ tqdm 오래 걸리는 작업을 진행할 때 진행상태 표시
✅kkma 형태소 사용하기
`
from konlpy.tag import Kkma
kkma=Kkma()`
-
kkma.morphs(u'공부를 하면할수록 모르는게 많다는 것을 알게 됩니다')

-
kkma.nouns(u'공부를 하면할수록 모르는게 많다는 것을 알게 됩니다')
-> ['공부'] -
kkma.pos(u'공부를 하면할수록 모르는게 많다는 것을 알게 됩니다')

✅Pecav(Pure Python 형태소 분석기) 사용하기
-> 퓨어 파이썬이라 설치가 굉장히 깔끔하다
`from pecab import PeCab
pecab = PeCab()`
pecab.pos("저는 삼성디지털프라자에서 지펠냉장고를 샀어요.")

✅Okt 사용하기
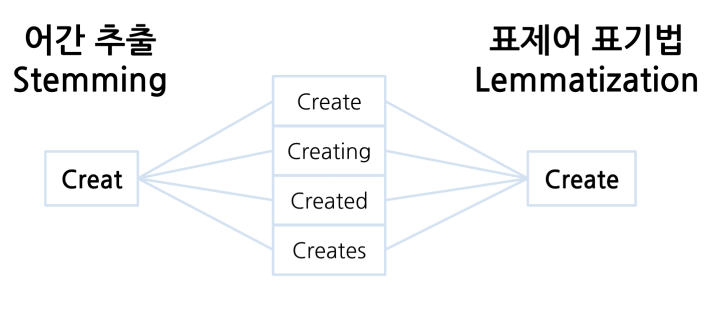
from konlpy.tag import Okt okt = Okt()
- steming 기능을 제공
: 어간 추출

💥 -했다, -했습니다, 했었습니다 등을 사용해도 stem을 사용하면 원형인 하다로 추출된다.
🔷 어간 추출(stemming)와 표제어 표기법(lemmatization)
-
차이점
: 어간 추출은 단어 형식을 의미가 있거나 무의미할 수 있는 줄기로 축소(원형을 잃을 수 있음)
: 표제어 표기법은 단어 형식을 언어학적으로 유효한 의미로 축소(원형을 보존할 수 있음)
-
전체 텍스트에 적용해주기 위한 함수
🔷 수도코드
1) 텍스트를 입력받는다
2) 품사태깅을 합니다. [('문의', 'Noun'), ('하다', 'Verb'), ('?!', 'Punctuation')]
3) 태깅 결과를 받아서 순회
4) 하나씩 순회 했을 때 튜플 형태로 가져 오게 된다 ('을', 'Josa')
5) 튜플에서 1번 인덱스에 있는 품사를 가져온다
6) 해당 품사가 조사, 어미, 구두점이면 제외하고 append 로 인덱스 0번 값만 다시 리스트에 담아준다
7) " ".join() 으로 공백문자로 연결해 주면 다시 문장이 된다
8) 전처리 후 완성된 문장 반환
🔷 코드
def okt_clean(text):
clean_text = []
# 품사 태깅
# 태깅 결과를 받아서 순회
for word in okt.pos(text, norm=True, stem=True):
# 해당 품사가 조사, 어미, 구두점이면 제외하고 append로 인덱스 0번 값만 다시 리스트에 담아주기
if word[1] not in ['Josa', 'Eomi', 'Punctuation']:
clean_text.append(word[0])
#" ".join()으로 공백문자 연결해주면 다시 문장이 된다.
return " ".join(clean_text)
okt_clean('나는 왜 항상 눕고 싶을까?')- 전체에 적용시켜주기
train['title'] = train['title'].progress_map(okt_clean) test['title'] = test['title'].progress_map(okt_clean)
-> 속도를 개선하고자 한다면 멀티스레드를 만들어서 처리하는 방법을 찾아보면 좋다잉
⭐1105 시퀀스 인코딩 실습
- 목표: BOW와 TF-IDF 방식과 시퀀스 방식이 어떤 차이가 있는지 알아보자!!
-> 시퀀스 방식의 인코딩을 시퀀스(순서)를 고려하는 알고리즘(RNN)에서 더 나은 성능을 보인다
-> 머신러닝에서 사용했을 때는 오히려 TF-IDF 가 더 나은 성능을 보이기도 함
🔷 자연어 처리, 시퀀스 방식은 순서가 중요하다
tf.keras.preprocessing.text.Tokenizer(
num_words=None,
filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n',
lower=True,
split=' ',
char_level=False,
oov_token=None,
analyzer=None,
**kwargs
)
- 시퀀스 만드는 법
-> texts_to_sequences를 이용하여 text 문장을 숫자로 이루어진 리스트로 변경
`from tensorflow.keras.preprocessing.text import Tokenizer
vocab_size = 5
tokenizer = Tokenizer(num_words=vocab_size)
tokenizer.fit_on_texts(corpus)
corpus_sequences = tokenizer.texts_to_sequences(corpus)`
-> [[3, 4, 1], [2, 1], [2, 1]]
✒️ 자주 등장하지 않은 것들을 빼고 작성한다(vocab_size를 5로 지정해서 원래는 8개가 있는데 5개까지만 가져왔기 때문에 vocab_size 제한을 풀면 다 나온다)
🔷 BOW는 등장한다, 안한다였다면 시퀀스는 해당 어휘사전을 만들고 해당 어휘의 등장 순서대로 숫자로 변환
- oov_token: 우선순위에 밀려 나오지 않는 단어들을 어떻게 처리할지에 관한 변수
vocab_size = 7
tokenizer = Tokenizer(num_words=vocab_size, oov_token='<oov>')
corpus_sequences = tokenizer.texts_to_sequences(corpus)-> [[4, 5, 6, 1, 2], [1, 1, 3, 2], [1, 1, 3, 2]]
(상생지원금, 인천, 지하철, bus, 버스) 모두 oov_token으로 들어감
✒️ oov안에는 oov아니라 아무 단어나 넣어도 된다
💥 길이가 맞지 않아서 corpus_sequences가 제대로 numpy array로 만들어지지 않음
- 패딩(길이를 맞춰주는 것)
구성: pad_sequences(sequences, maxlen=None, dtype='int32', padding='pre', truncating='pre', value=0.0)
기본값: 0
values: 채울 값을 지정
maxlen: 최대 길이 수 지정
padding='post': 뒤로 채워주기
from tensorflow.keras.preprocessing.text import Tokenizer
vocab_size=12
tokenizer = Tokenizer(num_words=vocab_size, oov_token='<oov>')
tokenizer.fit_on_texts(corpus)
word_to_index = tokenizer.word_index
corpus2_sequences = tokenizer.texts_to_sequences(corpus)
max_length = 13
pads = pad_sequences(corpus_sequences, maxlen=8, padding='post')
print(corpus)
print(word_to_index)
print(pads)
np.array(pads)💥 순서가 중요한 시계열 데이터(주가 데이터 등)는 섞지 않고 순서대나누기도 함
⭐1106 실습
Q. RNN 모델을 만들 예정이며 출력층은 기존에 만들었던 것처럼 만들 예정이다. 행정, 경제, 복지 albel을 one-hot-encoding을 해주는 이유?
A. 분류 모델의 출력층을 softmax로 사용하기 위해서
-> softmax는 각 클래스의 확률값을 반환하며 각각의 클래스의 합계를 구하면 1이 된다.
✒️ 시계열 데이터에서는 순서가 중요하기에 train_Test_split으로 나누지 않지만 1106에서는 순서가 있찌 않기에 사용해도 무방
12/15
⭐RNN(순환 신경망)
: 기존 모델이 전부 은닉층에서 활성화 함수를 지난 값은 오직 출력층 방향으로만 향한다는 한계점이 있었다.(한 방향으로만 향함)
: 시퀀스 데이터를 NN이나 CNN으로 처리하면 성능이 낮음
-> 가중치가 데이터의 처리되는 순서와 상관없이 업데이트 되기 때문에 이전에 본 샘플을 기억할 수 없음
- RNN 특징
: 기존 신경망과 다르게 결과값을 출력층 방향으로도 보내면서 다시 은닉층 노드의 다음 계산의 입려으로 보냄
: 다양한 길이의 입력 시퀀스를 처리할 수 있음
: 텍스트 분류나 기계 번역과 같은 다양한 자연어 처리로 사용됨
: 반복을 하는 노드가 있다고 생각하면 된다.
💥 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내면서 다시 은닉층 노드의 다음 계산의 입력으로 보내는 특징이 있음
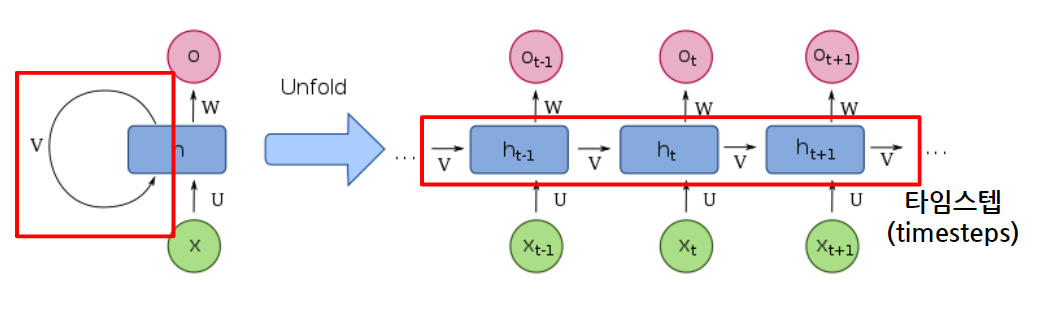
- 타임스텝: 입력 시퀀스의 길이(시점의 수)
- h: 시점, h-1: 이전 스텝의 시점, h+1: 다음 스텝의 시점
🔷 참고자료: https://colah.github.io/posts/2015-08-Understanding-LSTMs/
✅용어
- 셀(cell): RNN의 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할을 하는 노드(RNN의 반복 단위, 개별)
- 메모리셀(memory cell): 이전의 값을 기억하는 일종의 메모리 역할을 수행하는 셀(전체, RNNcell이라고도 함)
- 은닉상태(hidden state): 은닉층의 메모리 셀에서 나온 값이 출력층 방향 또는 다음시점의 메모리 셀에게 보내는 상태
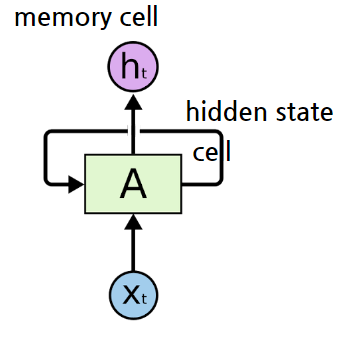
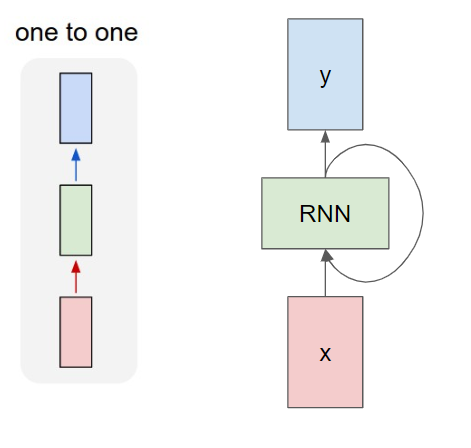
💥 RNN은 은닉층이 깊지 않음
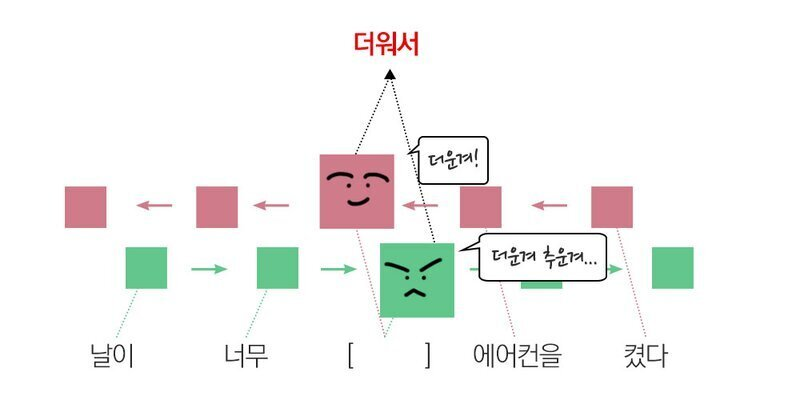
🔷 BPTT를 사용해서 학습(시간 흐름에 따른 작업을 하기에 타임스텝의 역방향으로 역전파를 통해 가중치 비율을 조정하여 감소를 진행함)
-> 순차 RNN 학습 방향에는 한계가 있기 때문에 양방향의 학습을 통해서 해결하는 기법
✅단어 임베딩
:유사한 단어가 유사한 인코딩을 갖는 효율적이고 조밀한 표현을 사용하는 방법을 제공
-> 인코딩을 직접 지정할 필요가 없다!
-> 큰 데이터 세트로 작업할 때 8차원(작은 데이터 세트의 경우), 최대 1024차원의 단어 임베딩을 보는 것이 일반적
🔷 더 높은 차원의 임베딩은 단어간의 세분화된 관계를 캡처할 수 있지만 학습하는데 더 많은 데이터가 필요
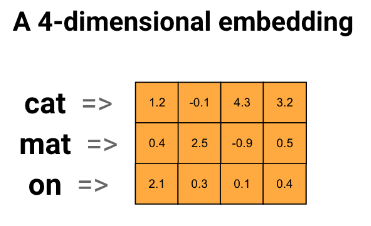
🔷 부동 소수점 값의 4차원 벡터
✅분류 모델 만들기
embedding_dim=16
model = Sequential([
vectorize_layer,
Embedding(vocab_size, embedding_dim, name="embedding"),
GlobalAveragePooling1D(),
Dense(16, activation='relu'),
Dense(1)
])- TextVectorization 레이어: 문자열을 어휘 인덱스로 변환
-> TextVectorization 레이어로 초기화하고 text_ds 에서 adapt 을 호출하여 해당 어휘를 구축 - Embedding 레이어: 정수로 인코딩된 어휘를 받고 각 단어 인덱스에 대한 임베딩 벡터를 찾는다
- GlobalAveragePooling1D 계층: 시퀀스 차원을 평균화하여 각 예제에 대해 고정 길이 출력 벡터를 반환
Q. Dense(1)일때 출략 값이 어떤 형태로 나올까?
A. 0~1 사이의 확률값
✅레이어 만들기
model = Sequential()
# 입력층-임베딩 층
model.add(Embedding(vocab_size, embedding_dim, name='embedding', input_length = max_length)) -> embedding 층 만들기
model.add(SimpleRNN(units=64, return_sequences=True))
-> return sequences: 시퀀스 반환 여부
model.add(SimpleRNN(units=32))
model.add(Dense(units=16))
# 출력층
model.add(Dense(units = n_class, activation='softmax'))
model.summary()✒️ return_sequence는 기본값이 False
-> 다음 시퀀스가 있다면 True로 지정
💥 stratify의 유무차이가 validation_split 사용의 성능을 구분 해줌
=> train_test_split으로 나누면 더 좋은 성능을 낸다(균형있게 validation data를 나눌 수 있음)
✒️ 주로 오류가 발생하는 곳
: input-shape, compile 오타
: RNN에서 레이어 설정을 잘 못 했을 때
-> 등으로 발생하며 fit을 할 때 오류메세지를 확인해야 함
✒️ GPU가 있는지 없는지 확인하는 코드
gpu_info = !nvidia-smi
gpu_info = '\n'.join(gpu_info)
if gpu_info.find('failed') >= 0:
print('Not connected to a GPU')
else:
print(gpu_info)⭐LSTM(장단기 메모리)
: RNN의 기울기 소실 문제를 해결하기 위해
-> 입력의 길이가 길어져도 이전 정보를 더 오래 기억하는 학습 방법의 필요성
: 이전 정보와 새로운 정보를 계산해서 activation 함수로 내보낸다
-> 이전 값과 새로운 값을 입력을 받아 시그모이드 연산을 한다
-> ex) 시그모이드로 0.1이 들어갔다면 이전 정보의 10%만 사용하고 0.9가 들어갔다면 90%를 사용한다.
💥 과거 데이터를 얼마나 기억할지는 sigmoid로 결정
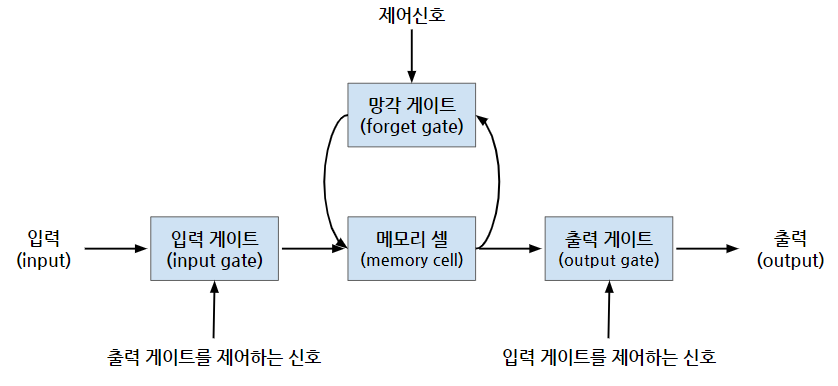
-> 코드는 RNN에서 레이어 생성할 때 이름만 바꿔주면 됌!
🔷 장점: 각각의 메모리 컨트롤이 가능하고 결과값이 컨트롤이 가능
🔷 단점: 메모리가 덮어씌워 질 가능성이 있고 연산속도가 느림
⭐GRU
: 한국인이 개발함!
: LSTM을 변형시킨 알고리즘으로 기울기 소실 문제 해결
: LSTM은 초기의 가중치가 지속적으로 업데이트 되었지만 GRUs는 update Gate와 Reset Gate를 추가하여 과거의 정보를 어떻게 반영할 것인지 결정(GRU는 게이트 2개, LSTM은 3개)
: update gate: 과거의 상태를 반영하는 gate
: reset gate: 현 시점 정보와 과거 시점 정보의 반영 여부를 결정
🔷 장점: 연산속도가 빠르고 LSTM처럼 덮어씌워질 가능성이 없음
🔷 단점: 메모리와 결과값 컨트롤이 불가

💥정리
🎈 텍스트 데이터 벡터화 하는 방법 : bow, tfidf
- 토큰화(str.split()화 해준것) : 하나씩 작게 분리해주는 것
-> 원핫 형태로 만들어줄 수 있음(희소한 백터를 만들게 됨)
-> bow 형태(순서는 고려X)로 만들어줄 수 있음
(min_df, max_df, analyzer, stopwords, n_gram) - TF-IDF 가중치 활용
(너무 자주 등장하는 단어는 가중치 ▼, 특정 문서에서만 자주 등장하는 단어는 가중치 ▲) - RNN: 순서가 있는 데이터를 예측할 때 주로 사용
-> 시퀀스 방식의 인코딩 사용 - Embedding: 여러 각도에서 단어와 단어 사이의 거리를 보고 가까운 거리에 있는 단어는 유사한 단어, 거리가 먼 단어는 의미가 먼 단어
(의미를 더 잘 보존한다는 장점이 있음)
🎈 텍스트 데이터 전처리 방법
: 계산을 효율적으로 하기 위해!
- 정규표현식
-> 텍스트 정규화 - 불용어
-> 나, 너, 그것, 이것, 저것 등과 같이 자주 등장하지만 큰 의미를 갖지 않는 단어 제거 - 형태소 분석
-> 의미가 없는 조사, 구두점, 어미 등을 제거 - 어간 추출(stemming), 표제어 표기법(lemmatization)
-> 표제어 표기법은 원형 보존, 어간 추출은 원형을 보존하지 않음
🎈 RNN(순서가 있는 데이터에 활용)
: time-step을 갖는 데이터에 주로 사용
-> 자연어(챗봇, 음성데이터 등), 시계열 데이터(주가 데이터 등), 심전도 데이터
- RNN
-> 내부 순환 구조가 있음 - LSTM
- GRU
⭐1107 실습 -> 시계열 데이터

Q. 위와 같이 정규화를 하면 어떻게 변환이 될까?
A. Standard Scaler: 평균을 0 표준편차를 1로 만들어준다.
