12/19~12/21 마지막 주
12/19
⭐시계열 데이터
- 기존에는 데이터를 나눌 때 섞어서 나누었는데 시계열 데이터에서는 섞어서 나누지 않고 순서를 고려해서 나눈다
- 자연어 텍스트를 시퀀스 인코딩 했던 것처럼 언어도 맥락이 있기 때문에 섞으면 원래 의미를 잃어버릴 수 있다
💥 시계열 데이터에서도 순서가 중요
ex) 지난 일년 간의 데이터를 통해 앞으로 일주일 간의 데이터를 예측한다고 했을 때도 윈도우를 밀어서 앞으로 예측할 일주일 데이터도 일주일치를 한번에 예측하게 하지 않고 그 전날까지의 데이터를 가지고 와서 다음날을 예측
Q. 시계열 데이터로 예측해볼 수 있는 것은?
A. 주가, 부동산 가격, 판매량, 재고량, 매출액, 신선식품 업체의 유통량, 농수산물가격, 동시접속자수, 서비스이용 고객수, 식물의 성장예측, 트래픽량
Q. 회귀와 시계열의 차이점은?
A. 데이터의 순서 고려 여부, 시계열 모델은 회귀 모델로도 예측할 수 있음(하지만 구분은 함!)
Q. bike-sharing-demand 를 실습했을 때 날짜, 시간 데이터가 있었는데 그 데이터로 시계열 방법을 사용하기 보다는 회귀 방법을 사용했다! 시계열을 사용해서 예측해 볼 수도 있기는 데 왜 시계열 방법을 사용하지 않고 회귀 방법을 사용했었을까?
A. bike 데이터를 나누는 기준이 1~19일까지 train, 나머지는 test로 되어있다. 여러 변수를 고려해서 수치데이터를 예측할 때 회귀 모델을 사용한다.
⭐1107 실습 -> 시계열 데이터
- 진행 순서: 데이터 로드 => 데이터셋 나눅 => 정규화(Min-Max) => 윈도우 방식으로 x, y 값 만들기 => 순서를 고려해서 데이터셋 나누기 => 모델 만들고 예측하기
✅정규화
- 마지막에는 y값만 복원해야하므로 편리하게 하기 위해 x, y를 따로 스케일링 해준다
mmsx = MinMaxScaler()
mmsy = MinMaxScaler()
x_mm = mmsx.fit_transform(dfx)
y_mm = mmsy.fit_transform(dfy)-> minmax y를 할때 "Reshape your data either using array.reshape(-1, 1) if "와 같은 오류가 뜸
💥 y값은 종가(Close) 컬럼의 값을 시리즈 형태로 가져왔기 때문에 2차원 형태로 변경할 필요가 있다! -> dfy.to_Frame()로 바꿔줘야 함
🎈 y_mm = mmsy.fit_transform(dfy.to_frame())
len(x_mm), len(y_mm)
-> (734, 734)
🎈 위 값은 변수별로 스케일링을 해준 값으로 윈도우를 고려하지 않은 값이다. (이전 시점의 데이터가 각 행의 들어있지 않고 해당 시점의 스냅샷만 있는 상태)
-> 윈도우를 고려해서 데이터를 만들 예정
✅x,y에 윈도우 사이즈 적용하기
-
window_size 만큼만 슬라이싱
-
10일치 데이터로 다음날 주가를 예측
-
다음 날 종가(i+windows_size)는 포함되지 않도록 X값을 만들고
-
다음 날 종가를 y로 만듦
-> 이 방식을 사용하지 않으면 회귀 방식이랑 똑같기도 하고 성능이 좋지 않게 나옴! -
시작값 지정
for start in range(len(y_mm)- window_size):
print("start : ",start, "stop : ", start+window_size, end=",")
💥 윈도우를 하나씩 이동하면서 데이터를 만들어 줄 예정
- x_data, y_data에 적용하기
for start in range(len(y_mm)- window_size):
stop = start+window_size
print("start : ",start, "stop : ", stop, end=",")
x_data.append(x_mm[start: stop])
y_data.append(y_mm[stop])np.array(x_data).shape, np.array(y_data).shape
-> ((724, 10, 4), (724, 1))
✅train, test 나누기
split_size = int(len(x_data) * 0.8)
X_train = np.array(x_data[:split_size])
y_train = np.array(y_data[:split_size])
X_test = np.array(x_data[split_size:])
y_test = np.array(y_data[split_size:])🎈 x_data[:split_size]은 리스트 형식으로 shape값을 구할 수 없기 때문에 np.array 형태로 바꿔줘야한다
✅모델 만들기
- input shape는 하나의 층에만 넣기
data_size = dfx.shape[1]
model = Sequential()
model.add(LSTM(units=10, activation='tanh', return_sequences=True, input_shape = X_train[0].shape))
model.add(LSTM(units=10, activation='tanh'))
model.add(Dropout(0.05))
model.add(Dense(units=1))
model.summary()-> data_size는 차원 값
✅컴파일
- 시계열 예측은 회귀 모델이기에 loss값과 metrics를 회귀 모델을 만들때와 같게 한다
model.compile(optimizer='adam', loss='mse', metrics = ['mae', 'mse'])
✅예측 결과 시각화
y_pred = model.predict(X_test)
rmse = ((y_test - y_pred)**2).mean()**0.5
pd.DataFrame({'test': y_test.flatten(), 'predict': y_pred.flatten()}).plot()
✅원래 값으로 복원하기
y_predict_inverse = mmsy.inverse_transform(y_pred)
y_predict = y_predict_inverse.flatten()
y_predict[:5]-
예측 원본 정답
-
방법1
y_test_origin = dfy[10:][split_size:]
-
방법2
mmsy.inverse_transform(y_test).flatten()
-> 이 방법도 있지만 정답값은 원래 데이터 프레임에서 추출한 값을 사용하면 날짜 정보가 있기 때문에 방법 1을 사용하는게 더 좋음
⭐비즈니스 데이터 분석과 군집화(비지도 학습)
- 오가닉 트래픽(Organic Traffic): 광고나 소셜미디어, 리퍼럴 사이트와 같은 채널을 통해 사이트로 유도되는 트래픽을 제외하고 검색 엔진을 통해 곧바로 유입되거나 동일한 도메인 안에서 유입되는 트래픽을 의미
✅AARRR
: 시장 진입 단계에 맞는 특정 지표를 기준으로 우리 서비스의 상태를 가늠할 수 있는 효율적 기준
- Acquisition(첫방문) : 어떻게 우리 서비스를 접하고 있는지
- Activation(첫 회원가입) : 사용자가 처음 서비스를 이용할 때 긍정적인 경험을 제공하는지
- retention(재구매) : 이후의 서비스 재사용률은 어떤지
- Referral(친구소개) : 사용자가 자발적 바이럴, 공유를 일으키는지
- Revenue(첫구매) : 최종 목적(매출)로 연결되는지
✅코호트 분석
: 분석 전에 데이터 세트의 데이터를 관련 그룹으로 나누는 일종의 행동 분석
: 정의된 시간 범위 내에서 공통된 특성이나 경험 공유
-> 고객이 겪는 자연적 주기를 고려하지 않고 맹목적으로 모든 고객을 분할하는 대신 고객의 수명 주기 전반에 걸쳐 패턴을 명확하게 볼 수 있음
🔷 유형
-
시간 집단
: 특정 기간 동안 제품이나 서비스에 가입한 고객 -
행동집단
: 과거에 제품을 구매했거나 서비스에 가입한 고객
-> 특정 세그먼트에 대한 맞춤형 서비스 또는 제품을 설계하는데 도움 -
규모집단
: 회사의 제품이나 서비스를 구매하는 다양한 규모의 고객
(자주 오는데 우유 같은 저렴한 물건을 사는 사람도 있고 가끔 오는데 아이패드나 핸드폰을 사는 고객도 있고 다양한 규모 집단이 있다)
✅잔존율 분석(Retention rate analysis)
: 리텐션 분석은 고객이 이탈하는 방법과 이유를 이해하기 위해 사용자 메트릭을 분석하는 과정
-> 유지 및 신규 사용자 확보율을 개선하여 수익성 있는 고객 기반을 유지방법 확보
ex) 처음부터 평생 수강권을 줄 수 있는데 고객 이탈과 수강률을 생각해 30일 수강권을 주고 절반 이상 수료시 평생 수강할 수 있게끔 해주고 다른 강의를 수강할 수 있는 쿠폰을 준다
-> 특정 제품에서 가장 중요시 여기는 지표를 북극성지표라고 부름
✒️ Description 항목을 groupby하지 않은 이유는?
-> Description 항목을 groupby에 사용하면 StockCode가 같은데도 다른 Description이라면 함께 집계되지 않는다. StockCode 기준으로 집계하기 위해 집계 후에 Description을 구해야하므로 groupby를 쓰지 않는다
12/20
⭐1201 실습
- 판매 상위 데이터의 Description 구하기
stock_desc = df.loc[df["StockCode"].isin(stock_sale.index),
["StockCode", "Description"]].drop_duplicates("StockCode").set_index("StockCode")
stock_desc.index.value_counts()
-> drop duplicates를 사용하여 중복된 부분 제거
- 연도와 월 파생변수 만들기
-
df["InvoiceYM"] = df["InvoiceDate"].astype(str).str[:7]
-> 타입을 문자열로 바꾼후 슬라이싱을 해준다 -
df["InvoiceYM"] = df["InvoiceDate"].map(lambda x: str(x)[:7])
-> 임의의 문자 lambda를 사용해서 만들어준다
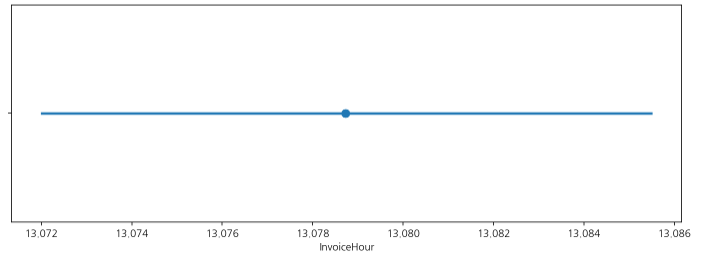
- pointplot을 그릴때는 연산이 꼭 들어가야 함!
🔷 연산이 없는 경우
:sns.pointplot(data=df, x='InvoiceHour')
🔷 연산이 있는 경우
: sns.pointplot(data=df, x='InvoiceHour', y='TotalPrice', estimator=len, errorbar=None)
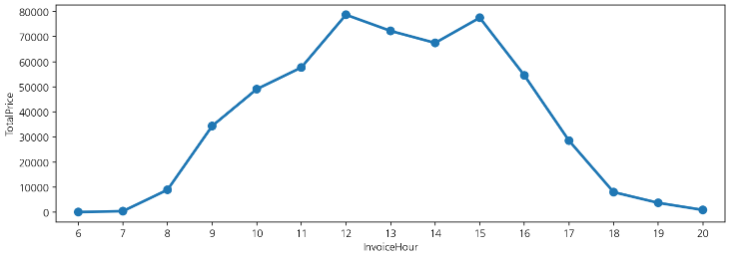
✒️ estimator가 들어가는 시각화에서는 errorbar(이전버전은 ci)를 제외하고 그리는 것을 추천
✒️ y값은 수치데이터를 꼭 지정해줘야함
✒️ 연산은 'count'(len)을 사용하면 개수를 세어 시각화 해준다.
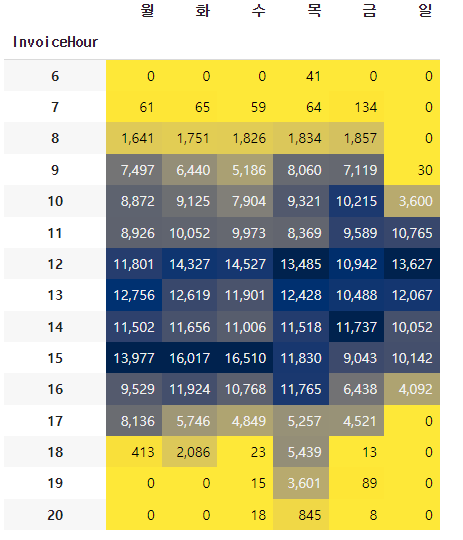
- 시간-요일별 빈도수
🔷 시간별, 요일별 crosstab을 통해 구매 빈도수 구하기
hour_dow = pd.crosstab(index=df['InvoiceHour'], columns = df['InvoiceDow']) hour_dow.columns = day_name
🔷 위 코드를 시각화
hour_dow.style.background_gradient(cmap='cividis_r').format("{:,}")
🔷 다양한 시각화
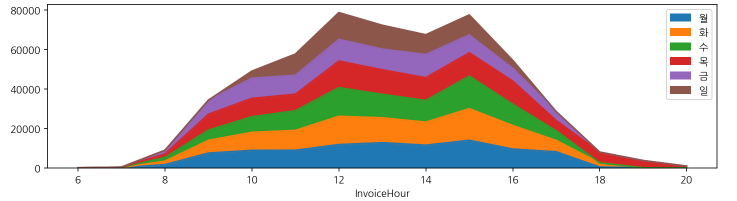
-
시간별 요일별 구매 주문 시각화
hour_dow.plot.area(figsize=(12,3))
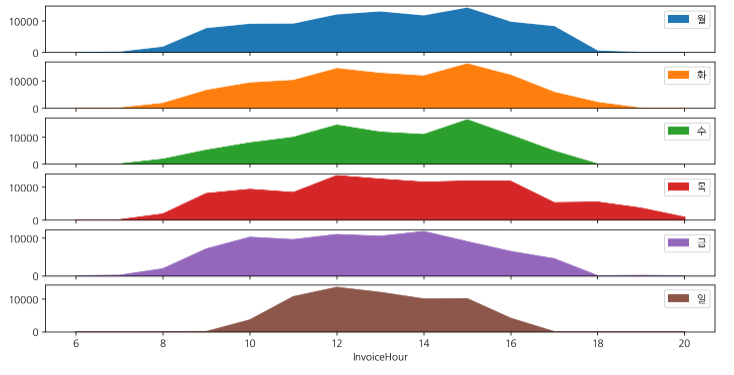
-
시간별 요일별 구매 주문 subplot을 통해 구하기
hour_dow.plot.area(figsize=(12,6), subplots=True);
-
시간별 요일별 구매주문을 heatmap으로 구하기
sns.heatmap(hour_dow, cmap='cividis_r', annot=True, fmt=".0f")
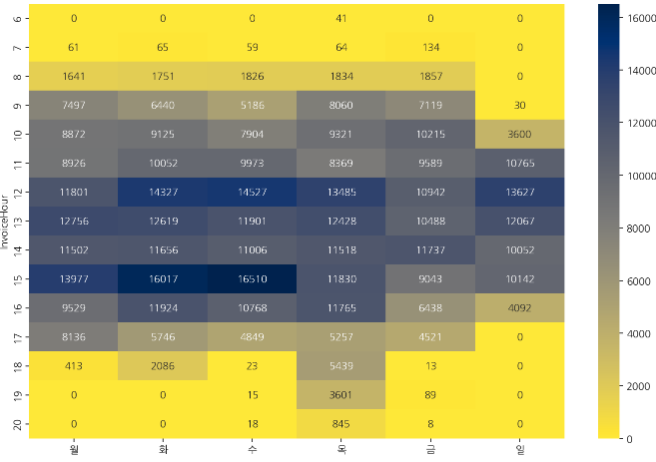
❓ 어떨 때 pandas의 background_gradient를 사용하고 어떨 때 seaborn의 heatmap()을 사용하면 좋을까?
🅰️ pandas 의 background_gradient() => 변수마다 성질이 다를 때, 각 변수별로 스케일값을 표현
seaborn 의 heatmap() => 같은 성질의 변수를 비교할 때, 전체 수치데이터로 스케일값을 표현
✅고객
🔷 ARPU(Average Revenue Per User) :
- 가입한 서비스에 대해 가입자 1명이 특정 기간 동안 지출한 평균 금액
- ARPU = 매출 / 중복을 제외한 순수 활동 사용자 수
🔷 ARPPU(Average Revenue Per Paying User): - 지불 유저 1명 당 한 달에 결제하는 평균 금액을 산정한 수치
🔷 arppu 구하기
arppu = df_valid.groupby('InvoiceYM').agg({'TotalPrice':'sum','CustomerID':'nunique'})
arppu.columns=['sale_sum', 'customer_count']
arppu['ARPPU'] = arppu['sale_sum']/arppu['customer_count']
arppu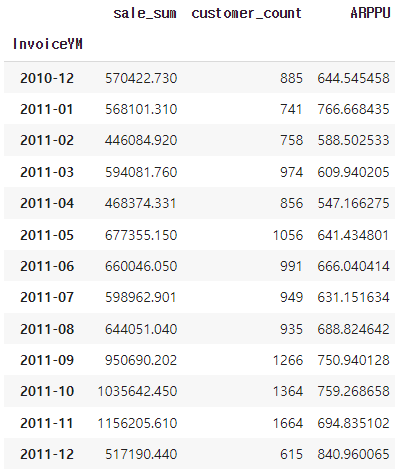
-> CustomerID 를 사용할 때는 count가 아닌 nunique 를 사용
-> 중복이 되지 않게 하기 위해 nunique를 사용
✅MAU
: MAU는 기준을 다르게 정하기도 하는데 로그인 수로 세기도 하고 아래 코드에서는 구매 데이터만 있기 때문에 구매수로 구함
mau = df.groupby(['InvoiceYM']).agg({'CustomerID':'nunique'})
mau.plot.bar(figsize=(12,3), rot=0, title='MAU(Monthly Active User')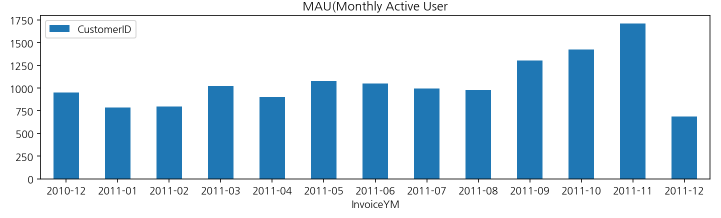
❓ 리텐션이란?
🅰️ 코호트 분석 중에 시간으로 묶어서 분석하는 기법
코호트 기법에서 시간으로 묶어서 분석하는 것이 리텐션이고 리텐션으로는 이탈, 성장 등을 분석할 수 있다
- 이탈 - 지난 달에 구매한 사람이 이번달에도 구매했는가?
- 성장 - 지난 달에 비해 매출액이 늘어났는가?
리텐션을 볼 때는 서비스마다 보는 관점이 다르기도 함
-> 헬스장 전월 대비 회원권 유지 회원 비율, 구독형 서비스(통신사, 정수기, oTT, 클라우드 등) 가입자 유지 비율
❓ 월별 리텐션을 어떻게 구할 수 있을까??
(1개월 후에도 제품 또는 서비스를 여전히 사용하는 사용자 수 는 어떻게 구할까)
🅰️ 해당 고객의 첫 구매월을 찾고 첫 구매월과 해당 구매 시점의 월의 차이를 구한다 그 후 첫 구매한 달로부터 몇 달째 구매인지를 구한다
-
해당 구매월 구하기
df_valid['해당구매월'] = pd.to_datetime(df_valid["InvoiceYM"]) -
최초 구매월 구하는 법
df_valid.groupby('CustomerID')['해당구매월'].transform('min')
-> tranform('min')을 해주면 해당 행에 대한 최솟값을 구해준다

-> 그냥 group by에 min값을 구하면 groupby에 대한 min값이 나옴

-
첫 구매일로부터 몇달째 구매인가?
🔷 연도별 차이와 월별 차이를 구한다
year_diff = df_valid['해당구매월'].dt.year - df_valid['최초구매월'].dt.year month_diff = df_valid['해당구매월'].dt.month - df_valid['최초구매월'].dt.month
🔷 연도차이 12개월 + 월차이 + 1로 부터 첫 구매 후 몇달 후 구매인지 알 수 있도록 cohort index 변수를 생성
`df_valid["CohortIndex"] = (year_diff 12) + month_diff + 1`
🔷 시각화
plt.figure(figsize=(12, 4)) sns.countplot(data=df_valid, x='CohortIndex')

-> 코호트 빈도를 구하니 잔존율을 늘리기 위해 노력해야함이 보인다
-> 마케팅비를 많이 쏟아서 고객을 유치했지만 유지가 잘 되지 않는 것으로 보여진다
✅잔존 빈도 구하기
cohort_count = df_valid.groupby(['최초구매월', 'CohortIndex'])['CustomerID'].nunique().unstack()
sns.heatmap(cohort_count, annot=True, fmt=".0f")
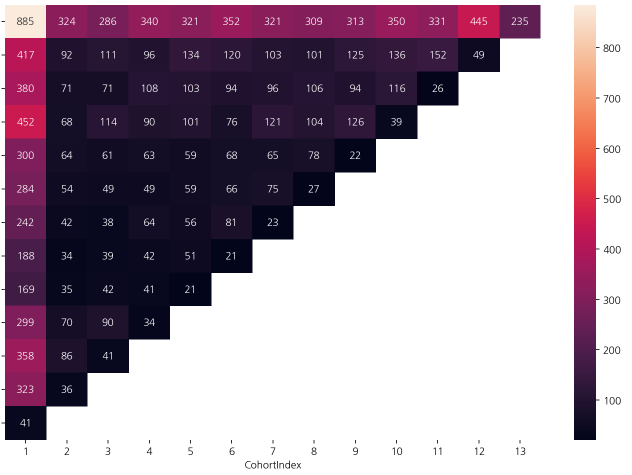
cohort_count.index = cohort_count.index.astype(str)
-> 이 코드를 사용해서 깔끔하게 정리해줄 수 있음
⭐RFM 분석
R(Recency) - 최근에 구매했는지?
F(Frequency) - 얼마나 자주 구매했는지?
M(Monetary) - 얼마나 많은 금액을 구매했는지?
=> 이 기준으로 고객 Segment 를 나누는 것이 RFM 분석
12/21
⭐RFM
: 가치있는 고객을 추출해내어 이를 기준으로 고객을 분류하는 분석 방법
-> 구매 가능성이 높은 고객을 선정하기 위한 데이터 분석방법
- 3가지 지표 또는 차원에 따라 각 고객을 분석
-Recency: 거래의 최근성(고객이 얼마나 최근에 구입했는가?)
🔷 최근구매일(구매일-x.max()).day)
-> 최근일수록 높은 스코어(값이 작을수록 높은 스코어)
-Frequency: 거래빈도(고객이 얼마나 빈번하게 우리 상품을 구입했나?)
🔷 구매빈도수(count)
-> 값이 높을수록 높은 점수를 준다(자주 왔는지를 보기 때문에)
-Monetary: 거래규모(고객이 구입했던 총 금액은 어느정도인가?)
🔷 총 구매금액(sum)
-> 값이 높을수록 높은 점수를 줌(얼마나 많은 금액을 구매했는지 보기 때문에)
💥 가장 중요한 문제는 그룹의 경계를 정의하는 것!
❓ 고객 세분화는 왜 하는 걸까?
🅰️ 구매 행동별로 고객을 묶어 각 고객집단별로 차별화된 마케팅 전략을 수립할 수 있다!
- 파레토 법치: 상위 고객의 20*가 기업 총 매출의 80%를 차지한다
⭐1202 RFM 실습
✒️ 원본 파일은 엑셀이지만 판다스에서 50만행 이상의 엑셀 파일을 불러오면 매우 느리다
-> 파일 사이즈는 엑셀이 더 작지만 csv 파일로 로드하는게 더 빠름
✅RFM 구하기
-
최근 거래 기준일(last_timestamp)을 만들기 위해 timedelta로 날짜 더해주기
last_timestamp = df['InvoiceDate'].max()+dt.timedelta(days=1)
-> 최근 영업일과 같은 마지막으로 거래를 했다면 0으로 될텐데 마지막 거래일자에 거래한 값이 1이 되게 하기 위해서이다
✒️ 리텐션을 구할때도 코호트 인덱스 값을 1로 설정한 것처럼 0부터 시작하지 않고 1부터 시작하도로 1을 더해줌 -
가장 앞에 있는 데이터의 최근 구매일자로부터의 날짜 차이
(last_timestamp - df['InvoiceDate'])[0].days -
가장 최근에 있는 데이터의 최근 구매 일자로부터의 날짜 차이
(last_timestamp - df['InvoiceDate']).iloc[-1].days
🔷 RFM 최종 코드
df.groupby('CustomerID').agg({'InvoiceDate' : lambda x: (last_timestamp - x.max()).days,
'InvoiceNo' : 'count',
'TotalPrice': 'sum'})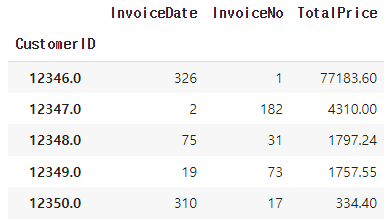
-> 복잡하지만 group by 내부에서도 람다 사용 가능
✅qcut을 통한 RFM 변수 만들기
- 고객의 R, F, M을 1~5점으로 만들어주고 계산을 할 예정
print(range(1,11)) pd.qcut(range(1,11), 5, labels=range(1,6))
-> range(1, 11)
[1, 1, 2, 2, 3, 3, 4, 4, 5, 5]
Categories (5, int64): [1 < 2 < 3 < 4 < 5]
❓ r 값은 값이 작을 수록 5, 4, 3, 2, 1 로 점수를 준다면 어떻게 만들어야 할까??
🅰️ list(range(5,0,-1))
r_labels = list(range(5,0,-1))
f_labels = list(range(1,6))
m_labels = list(range(1,6))
cut_size = 5
# 스케일 값이 차이나지 않게 스케일을 조정해주는 효과가 있다
r_cut = pd.qcut(x=rfm['Recency'], q=cut_size, labels=r_labels)
f_cut = pd.qcut(x=rfm['Frequency'], q=cut_size, labels=f_labels)
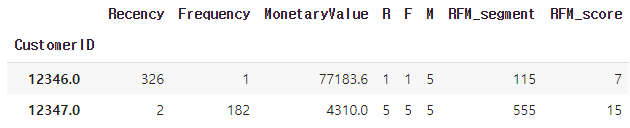
m_cut = pd.qcut(x=rfm['MonetaryValue'], q=cut_size, labels=m_labels)✅RFM 세그멘트 값 구하기
rfm["RFM_segment"] = rfm['R'].astype(str) + rfm['F'].astype(str) + rfm['M'].astype(str)
-> 
✅세그멘트 점수 값
rfm["RFM_score"] = rfm[['R', 'F', 'M']].astype(int).sum(axis=1)
->
- 3D로 표현하기
ax.scatter3D(rfm["R"], rfm["F"], rfm["M"])```
```ax = plt.axes(projection='3d')
ax.scatter3D(rfm["Recency"], rfm["Frequency"], rfm["MonetaryValue"])
🔷 3D 그래프 사이즈 조절하는 법!
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(20,20))
ax = plt.axes(projection='3d')
ax.scatter3D(rfm['R'], rfm['F'], rfm['M'])❓ 지도학습과 비지도 학습의 차이
🅰️ 정답의 유무
⭐군집화 분석
: 대표적인 비지도 학습 방법
: 주어진 데이터들의 특성을 고려해 데이터 집단(Cluster)을 정의하고 데이터 집단의 대표할 수 있는 대표점을 찾는 것으로 데이터 마이닝의 한 방법
-> 비슷한 특성을 가진 데이터들의 집단 = cluster
💥 데이터 줄테니까 너가 알아서 나눠봐!!
-
k-mean 클러스터
입력값
k: 클러스터 수
D: n 개의 데이터 오브젝트를 포함하는 집합
출력값: k 개의 클러스터 -
클러스터의 거리를 계산할 때 같은 클러스터끼리는 가까운 거리에 있어야 하고 다른 클러스터와는 멀리 떨어져 있어야지 잘 군집화가 되었다고 평가할 수 있다
=> Elbow, 실루엣 기법 등을 사용해서 평가한다
✒️ DBSCAN: 이상치는 군집에 포함시키지 않는 기법이라 이상치 탐지에 주로 사용된다
⭐1203 실습
✅로그 변환 후 스케일링 하기
from sklearn.preprocessing import StandardScaler
ss= StandardScaler()
X = ss.fit_transform(rfm_cluster_log)✅KMeans
inertia = []
silhouettes = []
range_n_clusters = range(2, 20)
for i in range_n_clusters:
kmeans = KMeans(n_clusters=i, random_state=42)
kmeans.fit(X)
inertia.append(kmeans.inertia_)
silhouettes.append(silhouette_score(X, kmeans.labels_))-> elbow값을 보기 위해 inertia값을 리스트로 만들고, silhouette_score값도 리스트로 만듦
-> 반복문을 통해 n_clusters를 특정 범위만큼 지정한 이유는 클러스터의 수는 사용자가 지정해야하는 파라미터값이기 때문이다.
-> 어느 값으로 설정해야 잘 군집화가 되었는지를 평가할 때 inertia값을 사용한다.
-> 군집의 중심(centroid)과 데이터 포인트 간의 거리로 측정
-> 차이가 적게 난면 거리가 가까울수록 inertia_값이 작게 나온다.
(작게 나올수록 좋다!)
✅Silhouette Score
: 군집화 평가 방법
: 각 군집 간의 거리가 얼마나 효율적으로 분리돼 있는지 나타냄
- 좋은 군집화가 되기 위한 기준 조건
-> 전체 실루엣 계수의 평균값, 즉 사이킷런의 silhouette_score() 값은 0~1 사이의 값을 가지며, 1에 가까울수록 좋다
-> 전체 실루엣 계수의 평균값과 더불어 개별 군집의 평균값의 편차가 크지 않아야한다
ex) 전체 실루엣 계수의 평균값은 높지만, 특정 군집의 실루엣 계수 평균값만 유난히 높고 다른 군집들의 실루엣 계수 평균값은 낮으면 좋은 군집화 조건이 아님
plt.title('Silhouette Score')
plt.plot(range_n_clusters, silhouettes)
plt.xticks(range_n_clusters)
plt.show()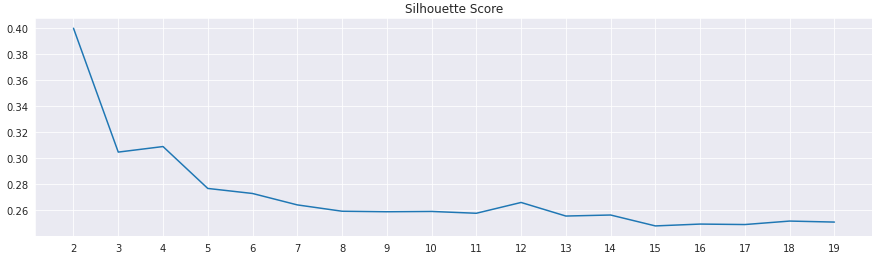
⭐추천시스템
: 정보 필터링(IF) 기술의 일종으로 특정 사용자가 관심을 가질만한 정보를 추천하는것
- 콘텐츠 기반 방식
- 협업 필터링 기반 방식으로 추천 목록 생성
-
소비자층의 프레임이 변화했다!
(파레토 법칙에서 롱테일 법칙에 더 주목하기 시작함 -> 빅데이터를 활용해 80%의 이름 없는 긴꼬리 부분에 대한 마케팅을 강조) -
콘텐트 기반의 추천
: 소비한 콘텐츠를 기준으로 유사한 특성을 가진 콘텐츠를 추천하는 방식
🔷 데이터 습득 -> 컨텐츠 분석(특징 추출, 벡터화) -> 유저 프로필 파악(유사도) -> 유사 아이템 선택
🔷 벡터의 유사도 - 유클리디안 유사도
: 두 점 사이의 거리르 계산할 때 쓰는 방법으로 최단거리(직선거리)를 찾음
: 거리의 값이 가장 작다는 것은 문서 간 거리가 가장 가깝다는 것을 의미
