[Trading Machine Project] Feature Engineering with Time Series Nearest Neighbor
Trading Machine Project
기존 방식
하나의 특성을 기준으로 Nearest Neighbor를 Search 후,
결과 값으로 나온 Nearest Neighbor를 Index 삼고, 기존 Feature의 값을 numpy function을 사용하여 Feature를 생성
Updates
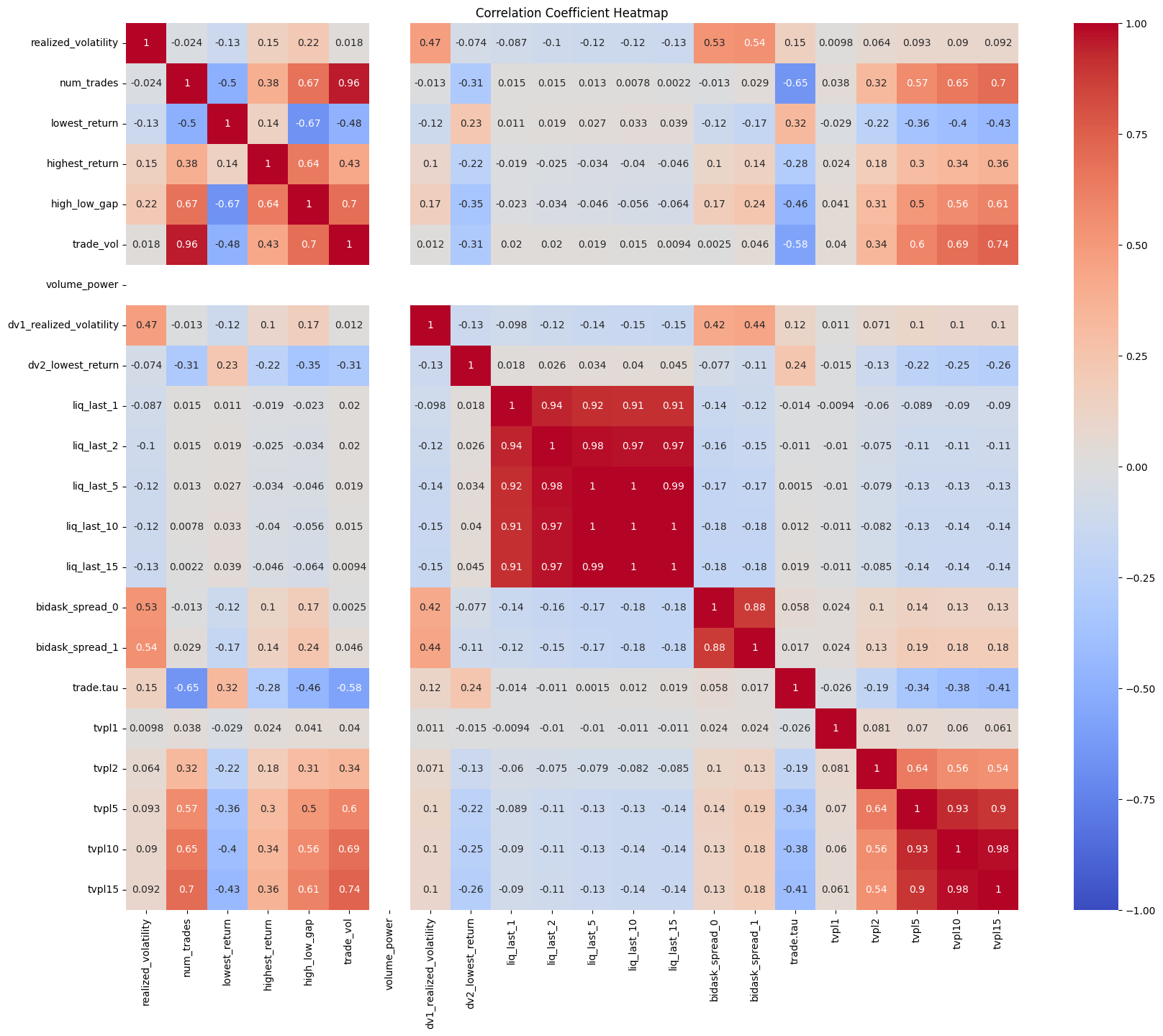
Pearson Correlation Coefficient
주요 특성들을 관찰하고 유사한 특성을 찾고자.
BTC_sum_both_10m.csv의 모든 변수의 상관계수를 계산
두 변수간의 선형성만을 확인하므로 min-max scale 적용
Kendal Tau Rank Correlation Coefficient
정규 분포성을 가지지 않는 특성을 고려해 Kendal Tau Rank 상관계수 또한 계산
ETC..
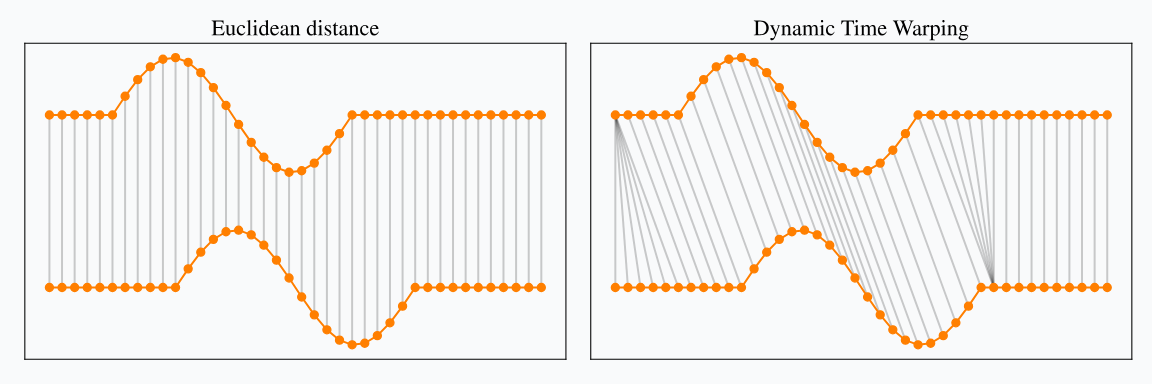
- Dynamic Time Wraping, TLCC 기법으로 두 특성간의 인과성을 찾아보려함
- Time Series Clustering ML로 모든 데이터를 하나의 경우의 수로 생각하는 접근도 시도함
Cointegration Test
공적분 검정을 통해 시계열 특징을 추출하는 방법도 생각해봄
하나의 행의 이전 50개의 값들을 list에 담아 각 Time_Id 별로 대조하며
P-value가 가장 낮은 순으로 Nearest Neighbor를 찾는 로직을 구상했으나 시간 복잡도가 O(N^2) 매우 크므로 최적화 방법 혹은 ML 기법을 사용하는 것이 좋아보임
Performance
-
기존 방식이 단 하나의 특성을 기준으로 Nearest Neighbor를 찾는 방식이었다면, BTC_sum_both_10m와 추가적으로 뽑아낸 다른 모든 특징 모두 고려한 Nearest Neighbor를 생성하였음
-
변수 내용을 pickle 형태로 저장하면 모델을 쉽게 저장해 시간을 절약할 수 있음
-
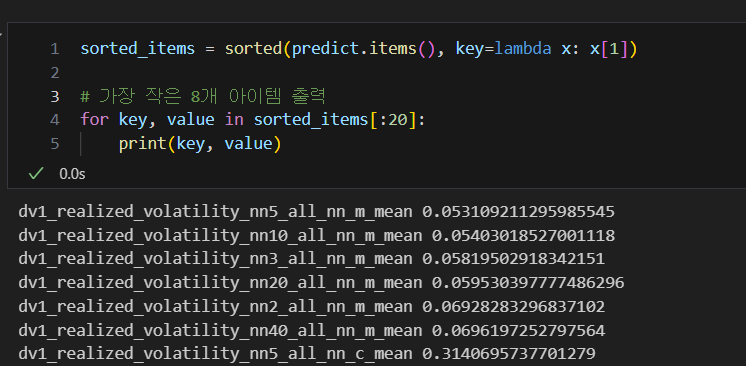
Nearest Neighbor의 dv1_realized_volatility를 Feature로 사용하는 것은 가능하지 않나?? (3등 솔루션 IDEA https://velog.io/@immanuelk1m/Tentative-3rd-Place-Solution-6th-in-Public-life-is-volatile)
위 아이디어를 바로 적용해보았는데 kaggle 대회에서는 0.19의 점수가 가장 좋은 결과를 보여주었고, 이 아이디어를 프로젝트 코드에 적용해보니
가장 작은 0.05 ~ 0.06 대의 더 좋은 점수가 나오는 것을 확인했다.

좋은 글이네요. 공유해주셔서 감사합니다.