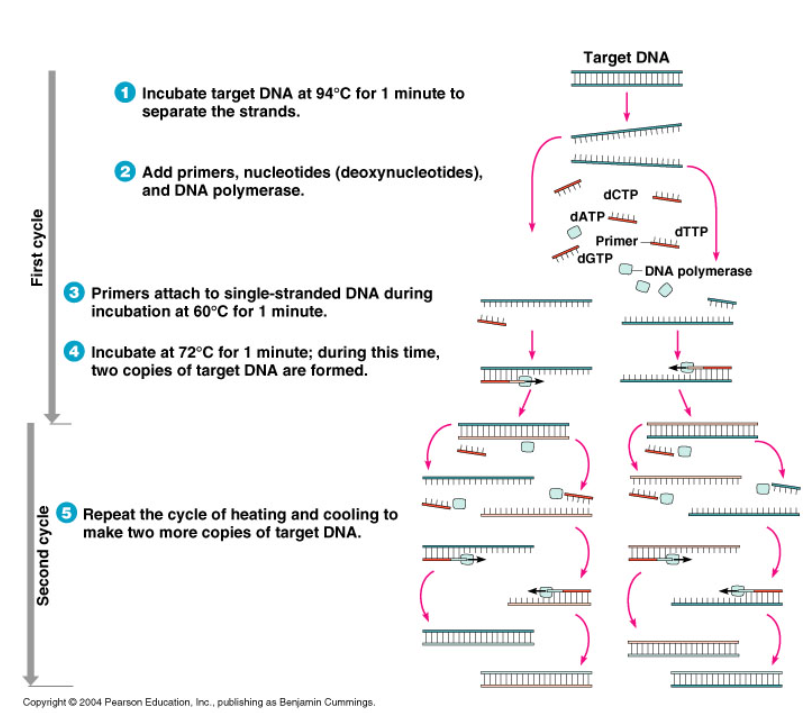
Why Nearest Neighbor
Such as PCR
단일 유전자를 관찰하기 위해 해당 유전자를 증폭시켜 실험하는 PCR과 유사 맥락이고 생각.
Nearest Neighbor의 역할은 하나의 Feature을 여러 개로 증폭시켜 Prediction에 적절한 특성을 찾아내는 과정이라고 생각.
Nearest Neighbor Workflow
TLCC Corr
combined_result_df의 모든 특성간의 켄달타우 Corr을 계산
Nearest Neighbor Structure
ONE FACTOR
combined_result_df의 단일 특성을 반복하며 NN 생성
- canberra (_c)
- minkowski p : 1 멘하탄 Distance (_m_p1)
- minkowski p : 2 유클리드 Distance (_m_p2)
SEVERAL FACTOR
켄달타우 Corr에서 dv1_realized_volatility 값과 가장 높은 상관계수를 가진 5개의 특성 혹은 가장 낮은 상관계수를 가진 5개의 특성 두 Set을 사용
-
canberra (_sev_high_nn_c)
-
minkowski p : 2 (_sev_high_nn_m)
-
canberra (_sev_low_nn_c)
-
minkowski p : 2 (_sev_low_nn_m)
USE ALL FACTOR
combined_result_df의 모든 특성으로 NN 생성
- canberra (_all_nn_c)
- minkowski p : 1 (_all_nn_m_p1)
- minkowski p : 2 (_all_nn_m_p2)
Summary
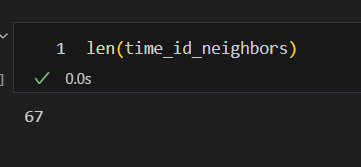
총 67개의 NN 생성
Amplification Feature
아래 단위로 Feature 증폭
'realized_volatility': [np.mean, np.min, np.max, np.std]
'lowest_return': [np.max, np.mean, np.min]
'num_trades': [np.mean]
'trade.tau': [np.mean]
'trade_vol': [np.mean]
'dv1_realized_volatility': [np.mean]
time_id_neigbor_sizes = [2, 4, 8, 16, 32, 64]2^N 개 단위로 NN을 추출하였고
적은 수의 NN을 묶어서 추출한 데이터는 큰 의미가 없음을 확인
Select Feature
Q : 추출한 4000개 정도 되는 Feature 좋은 Feature는 어떤 것일까?
- coin 별로 다르지만 어느 정도 근거가 있는 것도 있음
- 묶는 NN이 적은 것보다 많은 것 대체적으로 좋음
- 적은 양의 데이터로 테스트 한 결과이지만, tvpl, bid-ask spread, liq를 기준으로 묶은 NN은 자체적으로 평가한 Score가 낮았음
Score
Score는 모든 NN의 dv1_realized_volatility 평균 값과 실제 dv1_realized_volatility 값의 RMSPE 계산 값을 기준으로 하였음
- 366개의 dv1_realized_volatility 파생 Feature과 계산
- 많은 데이터 수로 다시 계산해볼 필요가 있음
- Kaggle Competition 1st score : 0.19548
현재 ERROR 발생 해결 중
- NN 개수 67 -> 61 6개의 NN이 에러 발생
- Bin 단위 : 6개
dv1_realized_volatility를 가지고 있는 특성 367
dv1_realized_volatility를 제외하고 특성 366 (61 x 6)
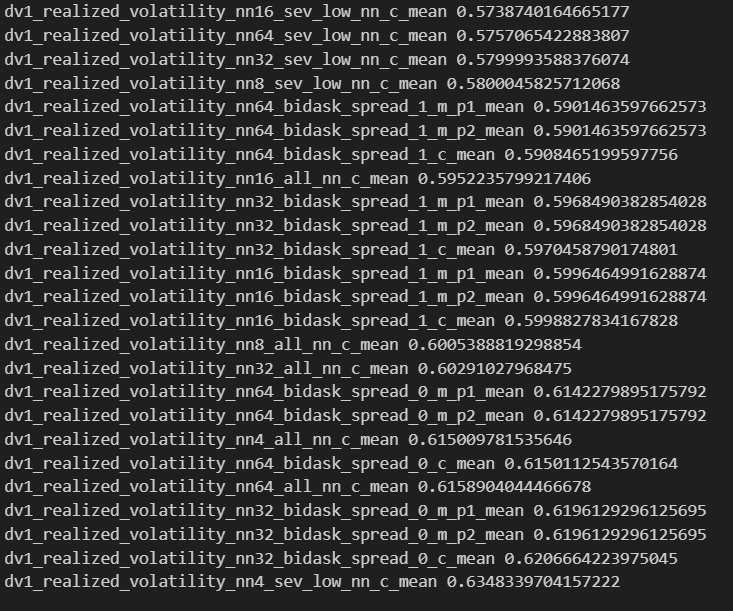
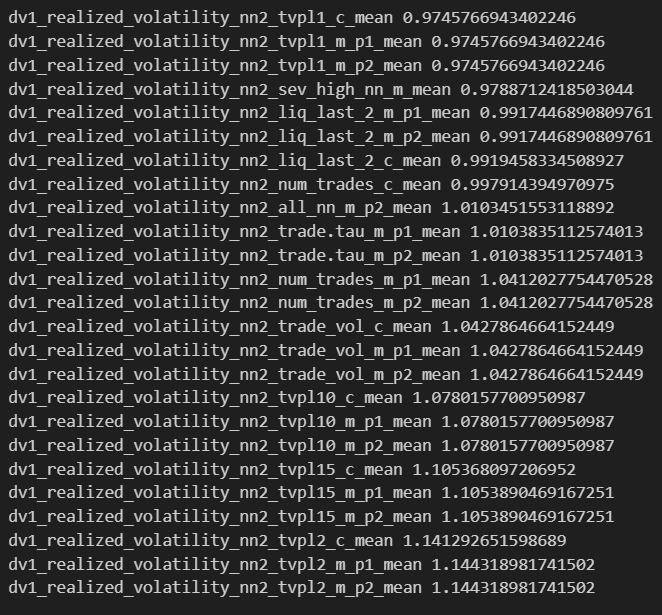
BTC Score
Best 25
Worst 25
ETH Score
Best 25

Worst 25
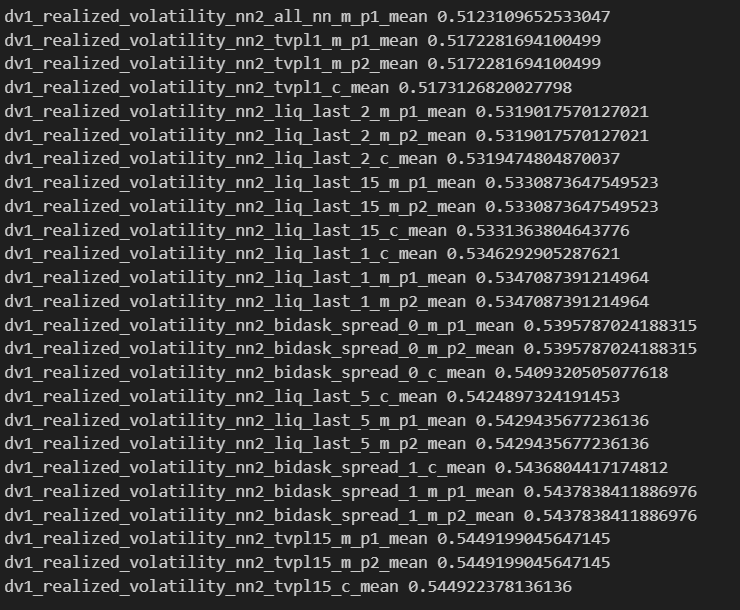
XRP Score
Best 25
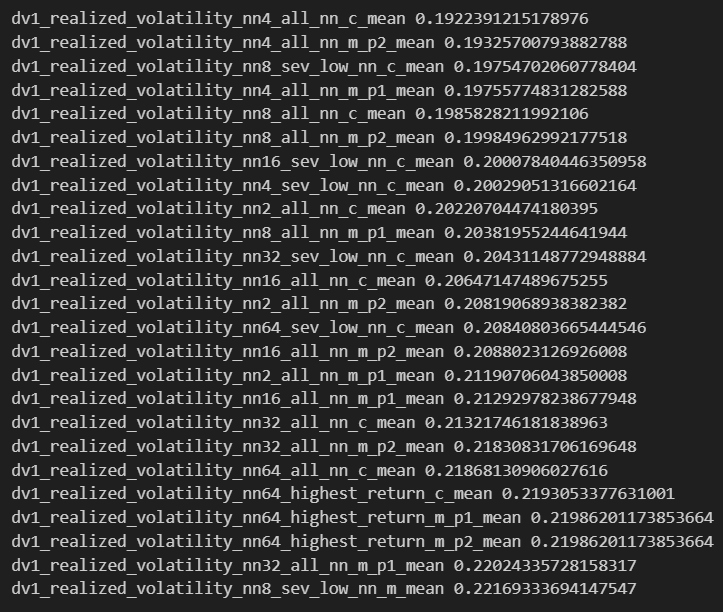
Worst 25

DOGE Score
Best 25
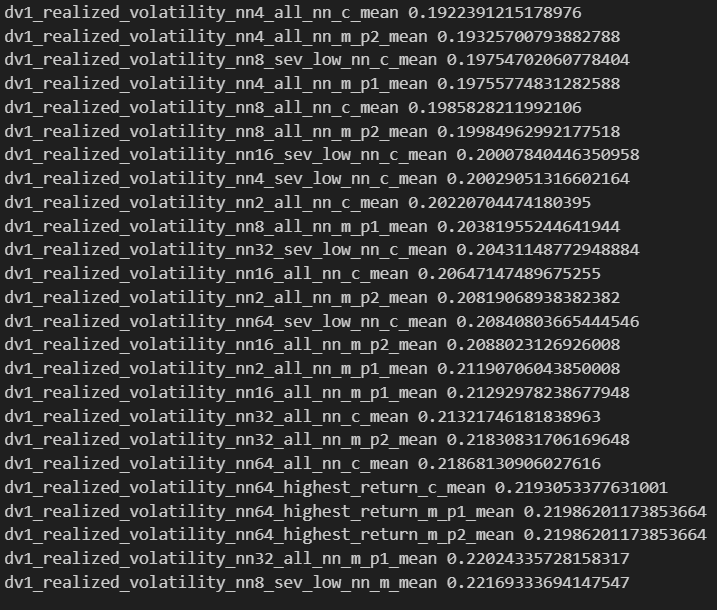
Worst 25
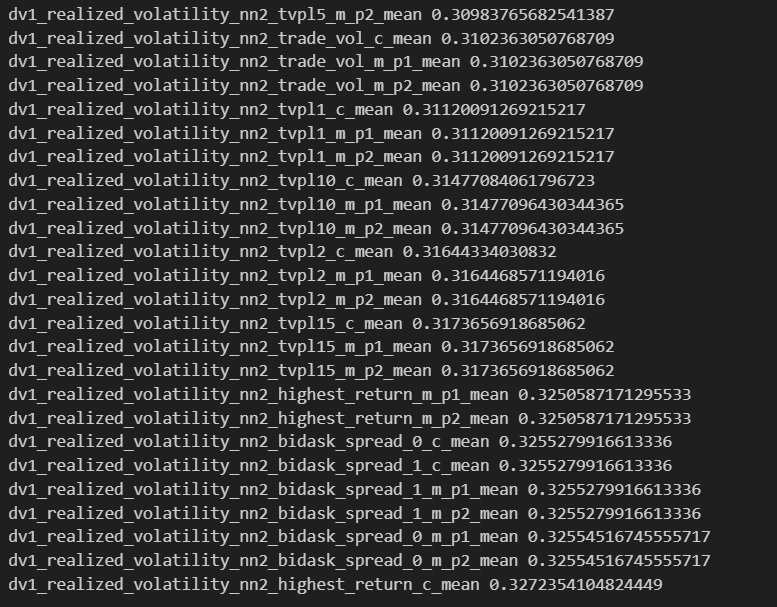
Conclusion
- NN 전에 log scaling 이 필요한 지
- time_id_neigbor_sizes 를 8 ~ 64 단위로 조절 예정
- dv1_realized_volatility를 제외한 다른 파생 변수는 어떻게 Selection 할 지 리서치
- dv1_realized_volatility로 Prediction 값으로도 가능
- Feature Importance 참고 예정
- 기술적 분석 Feature 추가 필요 (ATR, BB, EMA SPREAD...)
