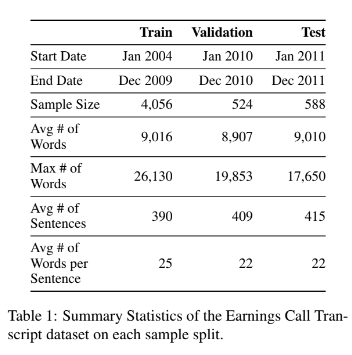
3.1 Data
MSCI 지수에 있는 기업을 기준
2004년 1월부터 2011년 12월까지의 기간
FactSet Document Distributor로부터 수집
FactSet Fundamentals와 Consensus Estimates에서
Reported Earnings per Share (EPS) 및 Analyst Consensus Estimates of EPS 수집
시가 총액이 10억 달러 이상이며 일일 평균 거래량이 5,000만 달러 이상인 모든 기업을 대상
look-ahead bias 피하기 위해, Train, Validation, Test를 Time으로 분할
3.2 Supervised Learing Task
?? 실적 발표 이후 컨퍼런스 콜 -> 그 다음 실적 예측??
-
Input data : Raw Conference Call Transcripts
-
LT는 컴퓨팅 및 메모리 제약으로 인해 12,000 단어(∼20,000 BERT 토큰)
-
표본의 대부분의 대본이 그 길이보다 짧음
-
Earnings Surprises 정도는 SUE로 계산
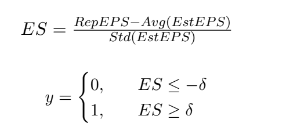
-
실제 EPS와 애널리스트의 EPS 추정치 사이의 차이를 분석가 예측의 표준 편차의 역수 나눔
-
consensus를 earning call 이후 1개월 유효한 애널리스트 예측의 평균으로 측정
-
Conference Call와 Earning 실적 발표 간에 약 3개월의 시간 간격이 있음
-
δ(델타) 값이 -0.10 ~ 0.10 사이의 값을 가지는 경우, sample size의 균형을 맞추기 위해 해당 transcripts 제거
-
1/4은 positive surprise, 1/4은 earning miss, 2/4 ??
-
추가로 positive와 negative를 50/50 비율로 맞추어 줌 (Down-sampling)
-
binary cross-entropy를 Loss function으로 사용
-
earnings surprise 값은 연속적인 값을 가지고 있지만, 시장 참여자는 earnings surprise 인지 아닌지를 더 중요하게 생각하는 경향이 있음
-
또한 시장 참여자는 중요한 이벤트인지에 따라서 earing call에 반응한다. (earing call이 크게 안 중요하다고 판단하면 가격변화에 크게 의미가 없다는 의미??)
4 Methods
4.1 Approach
- 모델을 처음부터 설계하려면 비용이 크므로, pre-train-model을 사용
4.2 Bag-of-Words
- BoW + TF-IDF + Logistic + Gradient Boosted Decision Trees
- dictionary-based model (LM) + Logistic classifier
- BERT-Sent(IMDB 영화 리뷰)
- FinBERT(analyst research reports)
"""
we provide a simple au-
toregressive time-series baseline AR(1) that fits a
logistic classifier on the continuous value of the
firm’s previous earnings surprise. In general, the
autocorrelation beyond the most recent quarter is
much lower. While the resulting performance is
far below that of the best long-document models
we provided, it is important to note that the signal
contained in the text is likely largely distinct from
and complementary to the information contained
in the lagged surprise variables.
"""
4.3 Short Context Models
- FinBERT 512개의 Token을 지원
- Fisrt / Last / Random 방식 혹은
- mean & max pooling 같은 Segment embedding
큰 문장을 Segment embedding을 어떻게 할 것인가
4.4 Hierarchical Transformers
-
document를 중복이 되지 않는 선에서 chunking 하여 greedy 하게 이어 붙임
-
의미있는 최대 segment 길이는 L이고 32,64,128로 hyperparameter, tune
-
Segment Encoder로 토큰 최적화 후, Document Encoder로 전체 내용 파악
-
레이어 수를 {2, 3, 4}로 조정하고 각 레이어의 attention 헤드 수를 6으로 설정??
4.5 Efficient Transformers
-
BigBird가 가장 효율적인 Transformer 모델이기에 선택
-
긴 문서 분류 및 질문-답변 작업에서 좋은 성능을 보임
-
BigBird는 재무 도메인에 사전 학습된 버전이 없기 때문에, RoBERTa-base 체크포인트를 사용
-
financial language 추가 학습
-
FLSE (forward-looking statements)와 positive/negative sentiment words (LMSE LM dictionary 기반) 추출하여 텍스트 길이가 75%와 67% 감소, but 효과적이지는 x
4.6 Implementation Details
- 모든 모델을 10 epochs 학습
- hihest validation accuracy check point로 선택
5. Result
5.1 Comparison
-
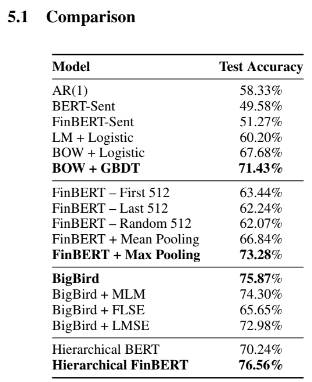
BERT-Sent와 FinBERT-Sent 랜덤 추측보다 훨씬 나은 성능을 보여주진 못 함
-
bag-of-ngrams와 TF-IDF 가중치가 GBDT와 함께 사용될 때 데이터셋에서 비교적 잘 작동함
-
단어 간 비선형 상호 작용을 통해 상당한 신호를 포착할 수 있음
-
텍스트 길이를 줄이려고 하는 모델은 신호를 희석하고 대화의 가장 중요한 부분을 식별하고 포착할 수 없을 가능성이 높음
-
training set이 작아서 BigBird의 이점을 가지진 못했음
-
end-to-end 방식으로 전체을 동시에 처리할 수 있는 모델이 성능 개선에 필요
-
모델이 텍스트의 전체 의미를 이해하고 FLSE과 긍정적/부정적 단어를 잘 식별할 수 있기 때문
5.2 Document Length
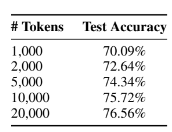
- 잘림 길이가 길수록 모델의 성능이 저하
- 모델이 더 긴 문서를 처리할 수 있는 능력을 지원할 필요성
5.3 Training Efficiency
- 계층적 모델은 BigBird와 Longformer에 비해 약 50%의 속도 향상을 보입니다. 이는 계층적 모델이 긴 문서를 처리하는 데 더 효율적임

6 Model Interpretability and Analysis
- Hierarchical FinBERT was the best performing model
