Data and Methodology
2.1 Data sources
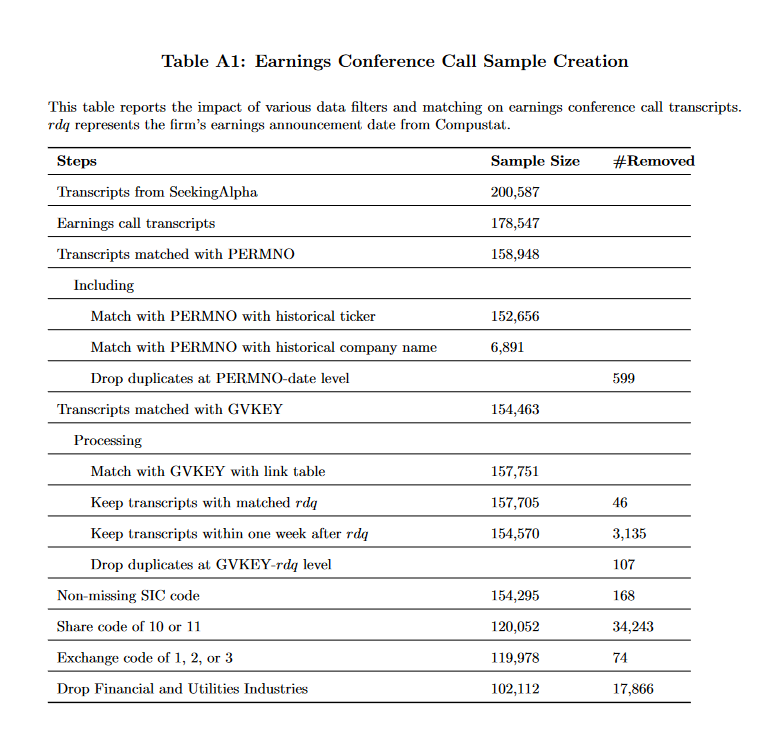
- 2007 ~ 2021.7까지의 178,547개 earnings conference call transcripts 수집
- CRSP and Compustat에 있는 ticker으로 선별
- 기업 이름, event 이름, 날짜와 매치해서 154,463개의 transcripts로 선별
선별 기준 table
2.2 Constructing the text-based inflation exposure measure
- 가격 변화에 대한 정보를 earnings conference call에서 추출하는 이유는 크게 두 가지가 있음
- (Bowen et al. 2002, Brown et al. 2004) 논문에 증명되어 있음
- 첫째, 기업 경영진, 분석가의 견해가 녹아있음
- 둘째, earnings conference call은 제약이 없어 솔직한 이야기가 많이 포함 되어있고 투자자와의 소통도 가능함 (Q&A section)
- 따라서 가격 변동과 관련된 기업의 부담 및 조치에 대한 논의는 컨퍼런스 콜에서 유연하게 이루어짐
Whole Process
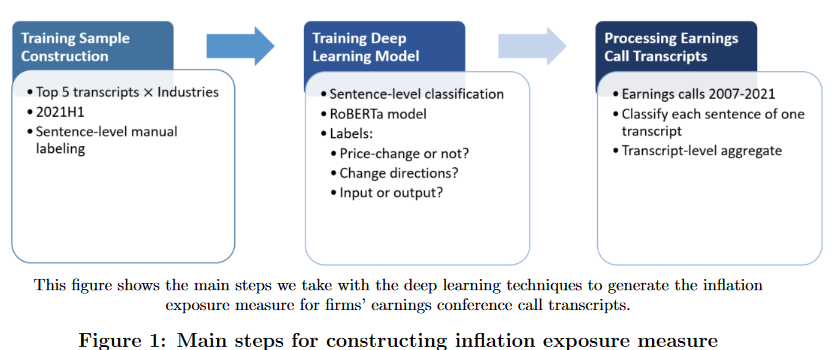
2.2.1 Why do we need deep learning classification?
- 뭐가 가격과 관련된 문장인지 찾기 어려워서 모델을 사용
- 특히나 가격 변동을 서술하는 방식이 저마다 다르기 때문에 BoW로는 한계가 있고, 문맥에 순서 및 단어의 순서도 패턴화 해야 함
- 물론 Rule-based model로 BoW 해도 성능 변화는 있을 수 있겠지만
- 모든 단어의 의미를 포착하는데에는 한계가 있음
- 또, price를 "가격이 오르다"라는 동사로 표현하는 사람도 있어 이러한 noise를 최대한 줄여야 함
- 이러한 난제를 해결하기 위해 정보해석, 감정분석, Q&A에 사용되는 BERT, RoBERT 모델을 채택
- 이 모델들은 몇 가지 이점들이 있음
- 1) pre-trained 된 모델들은 거대 언어 모형을 이미 학습한 상태임
- 2) Label이 지정된 Train sample을 fine-tuning하며 학습해 classification task 하기 수월함
- 3) 단방향 학습 모델 GPT와 달리 양방향 언어 학습을 모델이므로 여러 의미를 이해함 (Word2Vec, Glove와 다른 점)
Result
Matching Earnings Conference Calls to GVKEY

개발 새발
아주 유익한 내용이네요!