연구 배경 및 목적
-
특허가 급격히 증가하며 특허 정보를 효과적으로 검색하고 분석하는 데 많은 비용이 소모 됨.
-
도메인 전문가만 해결할 수 있던 작업들을 자동화하여 비용을 줄이는 것을 목표
-
딥러닝을 활용한 특허 분석 조사 결과들을 소개
-
데이터셋, 표현 방법, 딥러닝 구조, 그리고 대상이 되는 특허 분석 작업에 따라 40개의 논문을 범주화
1. The patent life-cycle and tasks for automation
-
특허 신청서에는 발명에 대한 원하는 보호 범위를 정의하는 클레임(청구항)이 포함
-
청구항에 기존 보다 새롭고 창조적인 주제를 명시하는 경우에만 특허가 부여
-
같은 아이디어를 설명하기 위해 다른 단어를 하므로 단순한 키워드 검색은 한계점 존재
-
국제특허분류(IPC)는 검색 시 관련 범위로 제한하는데 도움
-
특허 신청서가 특허청에 제출된 후에는, 기술적으로 숙련된 검사관이 특허 가능성을 평가
-
검사관은 주로 책이나 학회 논문보다는 이전에 출판된 특허나 특허 출판물을 인용
-
특허자료만해도 (유럽특허청(EPO) 1억 1천만 개의 문서이 있음
-
특허 심사 결과와는 무관하게, 특허 출원 후 18개월이 지나면 해당 출원 내용이 공개
-
심사 과정에서 밝혀지지 않은 관련된 이전 기술(prior art)을 찾아내어 특허를 무효화
-
prior art가 발견되면, 특허는 사후 절차에서 무효화될 수 있음
1.1 Patent analysis tasks
많이 다뤄지고 이슈가 있는 Task
-
전처리, 추가 분석을 위한 정보 추출, 다른 언어로 특허 번역 등의 지원 작업
-
특허 분류 : 발명 분야에 따라 계층적으로 분류하는 작업
-
특허 검색, 이전 기술 검색, 자동화된 특허 지형도 작성, 침해 검색, 자유 운영 검색, 구절 검색 등의 작업
-
특허 가치 평가 및 시장 가치 예측 : 특허의 내용과 서지 정보를 분석하여 특허 애플리케이션의 품질을 분석하고, 이를 시장 가치에 추가하여 회귀 문제로 해결하는 혁신적인 연구
-
기술 예측 : 특허를 사용하여 기술 지형을 평가하고 새로운 또는 트렌디한 기술을 파악하는 작업
-
특허 텍스트 생성 : 공개된 특허 문서의 구조와 스타일을 사용하여 특허 청구서 작성 프로세스를 자동화하는 작업
-
소송 분석, 잠재적인 특허가 두 회사 간의 분쟁이나 소송으로 이어지는 법적 프로세스
-
컴퓨터 비전 작업, 텍스트 대신 특허 문서의 그림과 도면을 다루는 작업
1.2. Patent offices
기업뿐 아니라, EPO, 미국 특허청(USPTO), 세계 지적재산권 기구(WIPO) 또한 이러한 노력을 하고 있음

1.3 Related surveys
Joho et al. [43]
- 특허 검색에 있어서 필요한 사항
- functionalities of patent users
- 특허 전문가의 인구통계와 그들의 특허 검색 능력간의 관계
- 이상적인 patent search system에 대해 서술
Abbas et al. [1]
- 텍스트 마이닝 및 시각화 기반 접근 방식
- semantics-based 접근 방식의 단점
Zhang et al. [101]
- 분류, 시각화, 검색 및 평가 작업에 대한 기술적인 문제, 솔루션
- 사용자 애플리케이션
검색엔진 방법론
- 쿼리 재구성
- pseudo-relevance feedback,
- semantics-based
- metadata-based
- interactive methods
"딥러닝 접근 방식은 거의 없다"
Dataset
2.1. Granted patents and patent applications
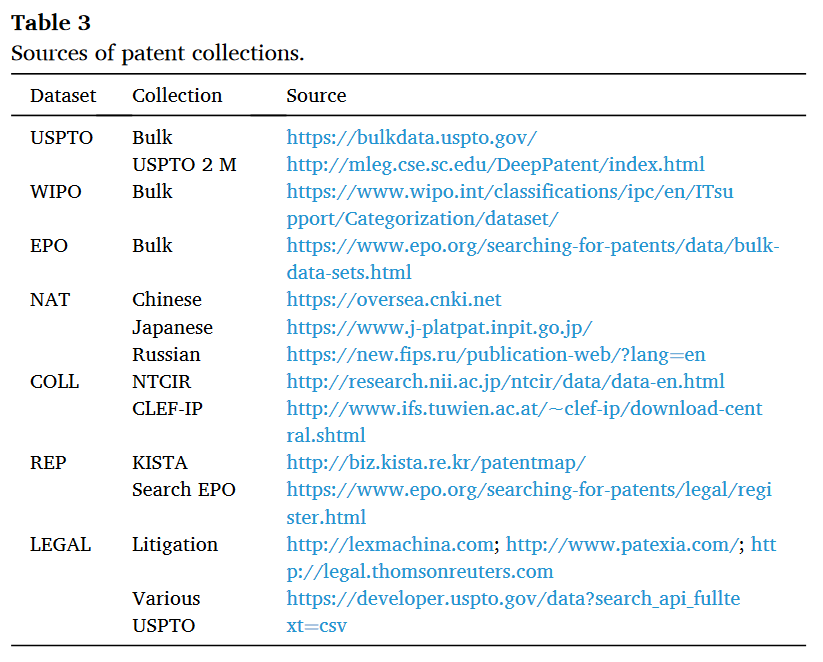
2.3 Reports
한국 지적재산청 (KIPO)
- 매년 트렌드 보고서 (KISTA) 및 랜드스케이핑 보고서 (KIPRIS)를 발표
Gartner의 Hype Cycle: Gartner
EPO Search Reports
- 새로 나온 특허가 처음 보는 사람 입장에서는 이해하기 힘드므로
관련 특허를 검색하는 방법론을 제공
2.4. Post-grant documents
-
특허 부여 이후의 시점부터의 법정 공방을 다룬 데이터
PTAB -
특허 소송 절차에서 방어 전략으로 경쟁사는 특허의 유효성을 찾음
-
대부분 특허 침해 주장으로 인한 소송 절차를 다룸
-
판례와 당사자 제출물을 포함
-
USPTO는 1963년부터 2016년까지 제출된 8만 1천 개 이상의 고유한 지방 법원 사건에 대한 상세한 특허 소송 데이터를 제공
-
데이터에는 당사자 및 변호사, 행위 원인, 위치 및 소송 역사 등 다양한 정보가 포함
2.5 Copyright
-
특허 분야에는 공개된 특허 문서가 많이 있어 이를 활용할 수 있으며, 이러한 문서는 저작권 보호에서 제외
-
특허 문서를 재생산하고 활용하는 데 저작권 문제가 크게 제한되지는 않지만 인용 시 출처를 밝혀야 함
3.Representations
-
특허 문서는 텍스트 데이터, 메타데이터, 이미지 데이터로 구성
-
Patent -> Vector 임베딩 과정이 필요
-
전통적인 방법 (word2vec, doc2vec)과 임베딩 표현을 결합
3.1 Numerical feature
- 인용 횟수
- 날짜 [61], claim 수
- 메타데이터에서 도출된 다른 수치
카테고리 특성 (one-hot)
- Ref.
- class code
3.2 Citation networks
-
참고문헌(References)
-
참고문헌들을 추출하여 인용 네트워크(citation network) 제작
3.3 Image data
3.4 Word embeddings
특허 분야에서는 word2vec, fastText, GloVe와 같은 임베딩 방법을 사용
3.5 Document embeddings
문단 또는 전체 문서를 나타내는 방법
-
텍스트의 단어 임베딩 벡터의 평균 텍스트
(단어의 순서를 고려하지 않음) -
doc2vec
3.6 Graph embeddings
- citation network를 어떻게 Vector화 할 것인지
3.7. Contextual word embeddings
- 문맥 의존적인 단어 임베딩은 텍스트 데이터를 효과적으로 표현하는 방법
- BERT와 같은 모델은 문장 내 단어 간의 관계를 고려하여 단어 벡터를 학습
5. Patent analysis task
Patent 관련 주요 과제
- supporting task, 분류, 검색, 가치 분석, 기술 예측, 데이터 생성, 소송 분석, 컴퓨터 비전
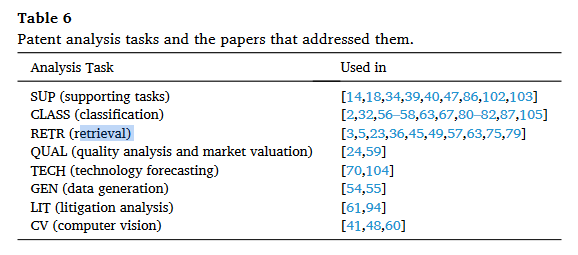
5.1 Supporting task
Extraction
- 화학적 명명된 개체나 생물의학적 명명된 개체를 추출
- 한 쌍의 단어 사이의 관계도 추출
Segmentation
- semi-structured 형태인 patent는 여러 섹션이 나뉘어져 있음
- 디지털화가 되지 않은 부분들은 OCR 기법을 사용해서 텍스트로 추출할 필요가 있음
Translation
특허가 특정 언어로만 제공되는 경우 하나의 언어로 통일
5.2 Classification
- IPC 또는 CPC 분류 체계를 기반으로 특허 문서에 분류 코드를 할당
- 실제로 특허 문서는 수동으로 분석 후, 지원자와 특허 담당자에 의해 분류 코드가 할당
5.3 Retrieval
Prior art search
- 특정 날짜 이전에 공개된 정보를 찾아 기술의 신규성을 확인하는 작업
- 관련 작업 검색, 신규성 탐지, 유효성 검사, 침해 검색
- 전문가가 생성한 쿼리나 용어 기반 검색 방법을 통해 이루어졌고, 인력과 도메인 전문 지식을 필요로 했음
Landscaping
- 특허 문서를 조사하여 관련된 기술 특허를 찾고 이를 분석하는 과정
- 특정 기술 분야의 트렌드를 파악하고 침해 문제를 피하는 데 도움
- 기술 동향을 이해하고 경제 및 정책 영향을 평가하는 데 사용
Passage Retrieval
- 특허 문서에서 관련 있는 단락(문장 또는 문단)을 찾는 작업
- 특허 출원 및 관련 기술 이전 특허와 같은 문서 간에 해당 특허의 신규성을 판단
Clustering
5.4. Quality analysis and market valuation
-
특허의 가치를 탐지하기 위한 신뢰할 수 있는 지표로 특허 내의 참고 문헌 인용을 사용
-
기타 지표로는 quality of the claims, family size of the patent 및 특허의 유효성
-
특허의 참고 문헌 네트워크를 통해 해당 특허의 가치를 평가
-
다른 접근법은 추상 및 클레임 텍스트와 수작업으로 생성된 특징을 사용하여 특허 가치의 지표로 전방 인용 횟수를 예측하려고 시도합니다.
5.5. Technology forecasting
5.6. Data generation
- 특허 클레임을 자동으로 생성
5.7. Litigation analysis
- 소송 확률 예측
- 리스크 분석
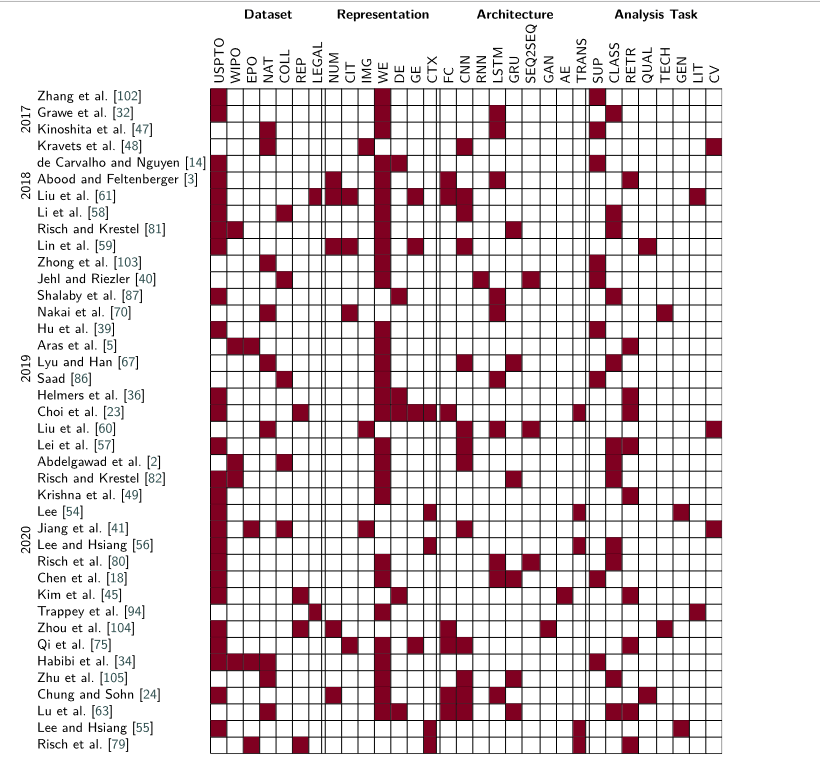
6. Literature discussion
7. Trends and conclusion
CNN과 LSTM과 같은 클래식 네트워크 아키텍처가 많이 사용
특히 ENDEC와 GAN 아키텍처는 전문화된 작업에 사용되며, 모든 작업에 적합하지는 않다.
분류는 특허 분석에서 가장 인기 있는 작업 중 하나이며, 이 작업은 모든 특허에 클래스가 할당되어 있기 때문에 많은 주석이 달린 학습 데이터를 가지고 있으므로 상대적으로 간단함
특허 텍스트 생성 및 구절 검색과 같은 작업에 대한 더 많은 딥러닝 접근법이 개발될 것으로 예상됩니다.
AI 법률가가 특허소송 처리하는 데 도움이 될 것으로 기대
Review
-
전반적으로 특허를 다루는 일련의 과정에서 벌어지는 모든 문제를 ML/DL로 해결하려는 움직임을 서술한 논문이었으나, 특허 데이터를 타 분야와 접목하려는 시도를 담은 내용은 많지 않아 아쉬움
-
Quality analysis and market valuation, Technology forecasting 관련한 Reference Paper를 읽다보면 인사이트가 생기지 않을까 싶음.
-
특허 관련한 term이나 실제 특허가 어떤 Form으로 제공되는지 볼 필요가 있음.
