[논문리뷰] Forecasting emerging technologies using data augmentation and deep learning
Paper Review
Introduction
다음 논문 리뷰는 아래 유튜브 논문 리뷰를 참고하였음.
Youtube
해당 논문은 Emerging Technologies의 Feature를 토대로 미래 가치가 있는지 없는지 판단하는 GAN+DNN Model 논문
Binary Classification
신기술 예측의 중요성과 기존 서지 정보 기반 연구가 진행되어 왔지만,
Text 정보는 다루는 경우가 거의 없었음이 확인
클러스터링 방법 또한 제시되었지만 클러스터링 이후 전문가의 해석이 들어가는 Bias가 생김
따라서 지도 학습 기반 모델로 위 한계점을 해결하는 시도가 등장했으나
양질의 Label Data가 부족한 문제가 발생
과거의 신기술 데이터가 적은 수로 제한되어 있다보니, 딥러닝을 활용한 방식에는 Overfiting Problem이 나타날 수 있음
Data 문제를 GAN (Data Argumentaion)으로 해결
GAN이 훈련 샘플을 효과적으로 증가시키고, 모델 성능또한 향상됨
Overview
- Emerging Technologie와 Non-ET를 Sample마다 Labeling
(Label은 Gartner의 Hype Cycle, Thomson Innovation 특허 DB 사용) - 각 기술 특허에 대한 Feature Selection
- Train-Test Set 구축
- GAN을 활용해 Data 증강 후 DNN 모델 학습
- Test Set으로 예측 모델 평가
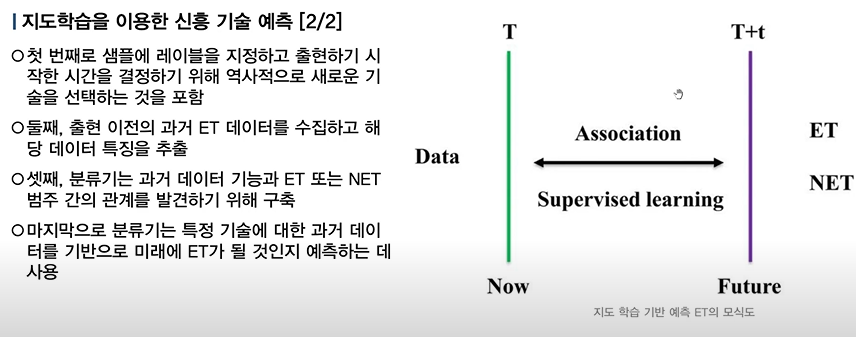
Methodology
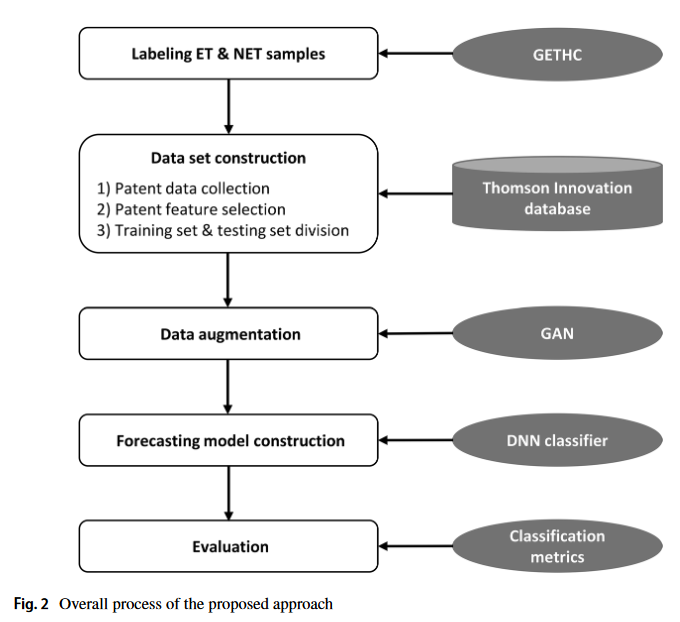
Labeling ET & NET sample
해당 Tech가 1년 후에도 Hype Cycle에 존재하는지를 기준으로 Labeling

Data set construction
1) Thomson Innovation DB에서 특허 수집 후
2) Feature Selection
3) Train / Test Set 구축
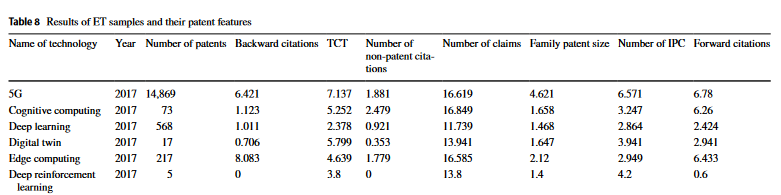
Feature Selection
Low-novelty (참신하지 않은 정도)
- Backward citations : 참조한 특허 수
Growth speed (성장 속도)
- Technology cycle time (TCT)
TCT는 동일 tech의 i번째와 j번째 patent의 시간 차들의 중앙값
Science-intensity (기술성)
- Number of non-patent citations : 특허가 아닌 것을 인용한 횟수
Scope and coverage
-
Number of claims : 청구항 수
-
Family patent size : 얼마나 다양한 국가에서 출원이 됐는지
-
Number of IPC : 얼마나 많은 기술 분야의 특허인지
Development capabilities (발전 가능성)
- Foward citations : 얼마나 많이 해당 특허가 인용 당했는지
Then
이렇게 모인 7개의 Feature들을 산술 평균으로 하나의 Tech Vector로 만듦
Data Augmentation
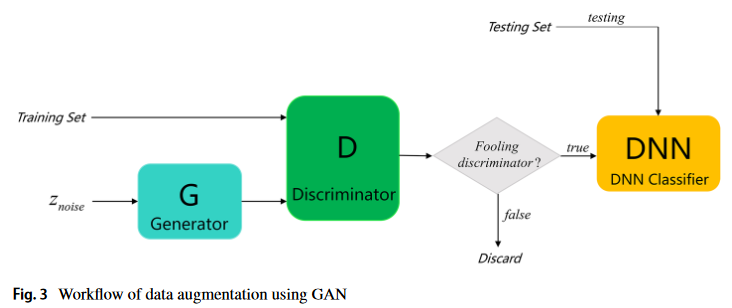
GAN을 간단하게 설명하자면 GAN 모델이 실제 데이터와 유사한 데이터를 만들고 (Generator), 만들어진 데이터가 실제 데이터인지 아닌지 (Discriminator)가 판단해 '진짜 같은 가짜'를 만들어 냄
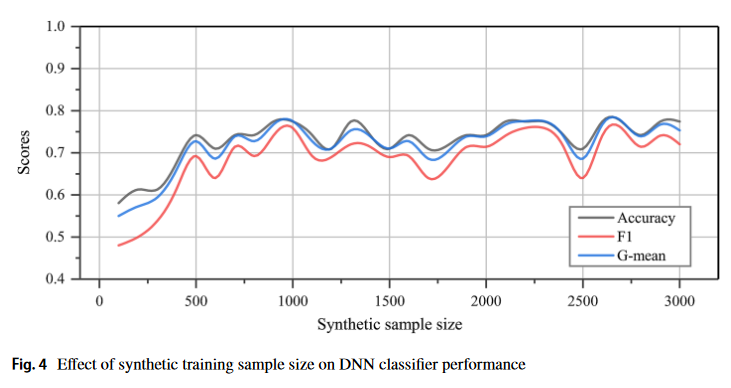
GAN 사용 결과 sample size가 1000개까지 증폭시킨 경우 성능이 향상됨을 확인
Forecasting model construction

Evalutaion
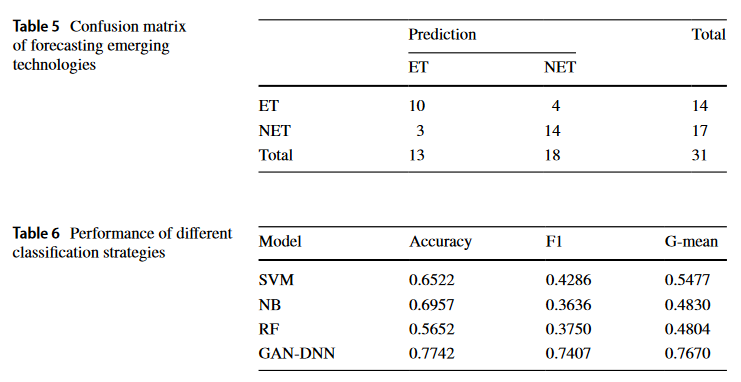
Result
Conclusions
Limitation
-
77% 성능을 보였다고 하지만, Binary Classfication 문제에서의 77% Accuracy는 다소 아쉬움
-
DNN 모델 이외의 Advanced Model이 있지 않을까?
-
Text를 사용했다고는 하나, Text Encoding이 아닌 Text 관련 Feature를 사용
-
기술이 Hype Cycle 내의 기술로 한정되어 있음
