
Cloudnet@에서 진행하는 쿠버네티스 실무 실습 스터디를 진행하면서 작성한 글입니다.
스터디에서 사용하는 교재는 24단계 실습으로 정복하는 쿠버네티스 입니다.
Cloudnet@
24단계 실습으로 정복하는 쿠버네티스
kwatch
kwatch helps you monitor all changes in your Kubernetes(K8s) cluster, detects crashes in your running apps in realtime, and publishes notifications to your channels (Slack, Discord, etc.) instantly
# configmap 생성
cat <<EOT > ~/kwatch-config.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: 'https://hooks.slack.com/services/슬랙주소'
#title:
#text:
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOT
# 배포
kubectl apply -f kwatch-config.yaml
잘못된 이미지 파드 배포 및 확인
# 터미널1
watch kubectl get pod
# 잘못된 이미지 정보의 파드 배포
kubectl apply -f https://raw.githubusercontent.com/junghoon2/kube-books/main/ch05/nginx-error-pod.yml
kubectl get events -w
# 이미지 업데이트 방안2 : set 사용 - iamge 등 일부 리소스 값을 변경 가능!
kubectl set
kubectl set image pod nginx-19 nginx-pod=nginx:1.19
# 삭제
kubectl delete pod nginx-19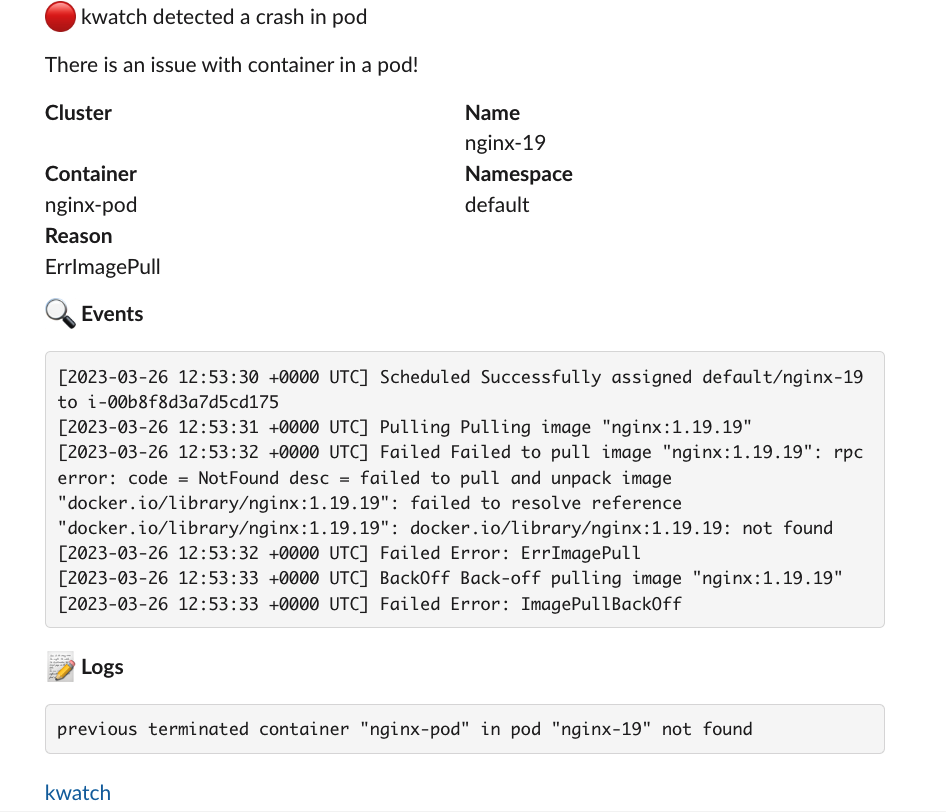
prometheus alertmanager
프로메테우스는 장애 등의 메시지 전달 기능을 얼럿매니저로 분리해서 관리합니다.
경고 메시지가 발생하면, 이를 얼럿매니저에 푸시 이벤트로 전달하고, 얼럿메니저는 이를 그룹화, 일시 중지(silence) 등의 가공 과정을 거쳐 이메일, 슬랙 등으로 전달합니다.
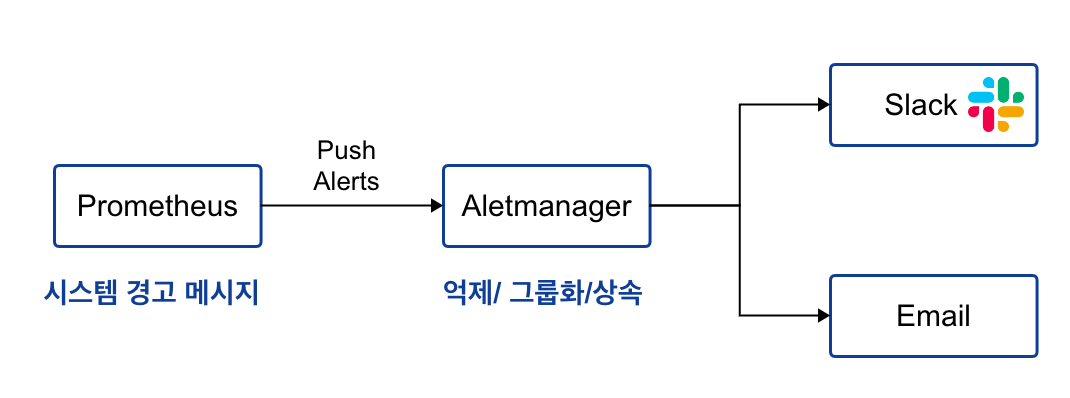
프로메테우스의 임곗값 도달 시 경고 메시지를 얼럿매니저에 푸시 이벤트로 전달 -> 얼럿매니저는 이를 가공후 이메일/슬랙 등에 전달
워커 노드 3번 추가 링크
- 노드 추가 시 프로메테우스의 Target들이 자동으로 발견(Auto Discovery)되어서 등록이 되고, 메트릭 수집이 되는지 확인
# EC2 인스턴스 모니터링
while true; do aws ec2 describe-instances --query "Reservations[*].Instances[*].{PublicIPAdd:PublicIpAddress,InstanceName:Tags[?Key=='Name']|[0].Value,Status:State.Name}" --output text | sort; echo "------------------------------" ;date; sleep 1; done
# 인스턴스그룹 정보 확인
kops get ig
# 노드 추가
kops edit ig nodes-ap-northeast-2a --set spec.minSize=2 --set spec.maxSize=2
# 적용
kops update cluster --yes && echo && sleep 3 && kops rolling-update cluster
# 워커노드 증가 확인
while true; do kubectl get node; echo "------------------------------" ;date; sleep 1; done얼럿매니저 웹 접속 & 얼럿매니저 대시보드 karma 사용
얼럿매니저 웹 접속
# ingress 도메인으로 웹 접속
echo -e "Alertmanager Web URL = https://alertmanager.$KOPS_CLUSTER_NAME"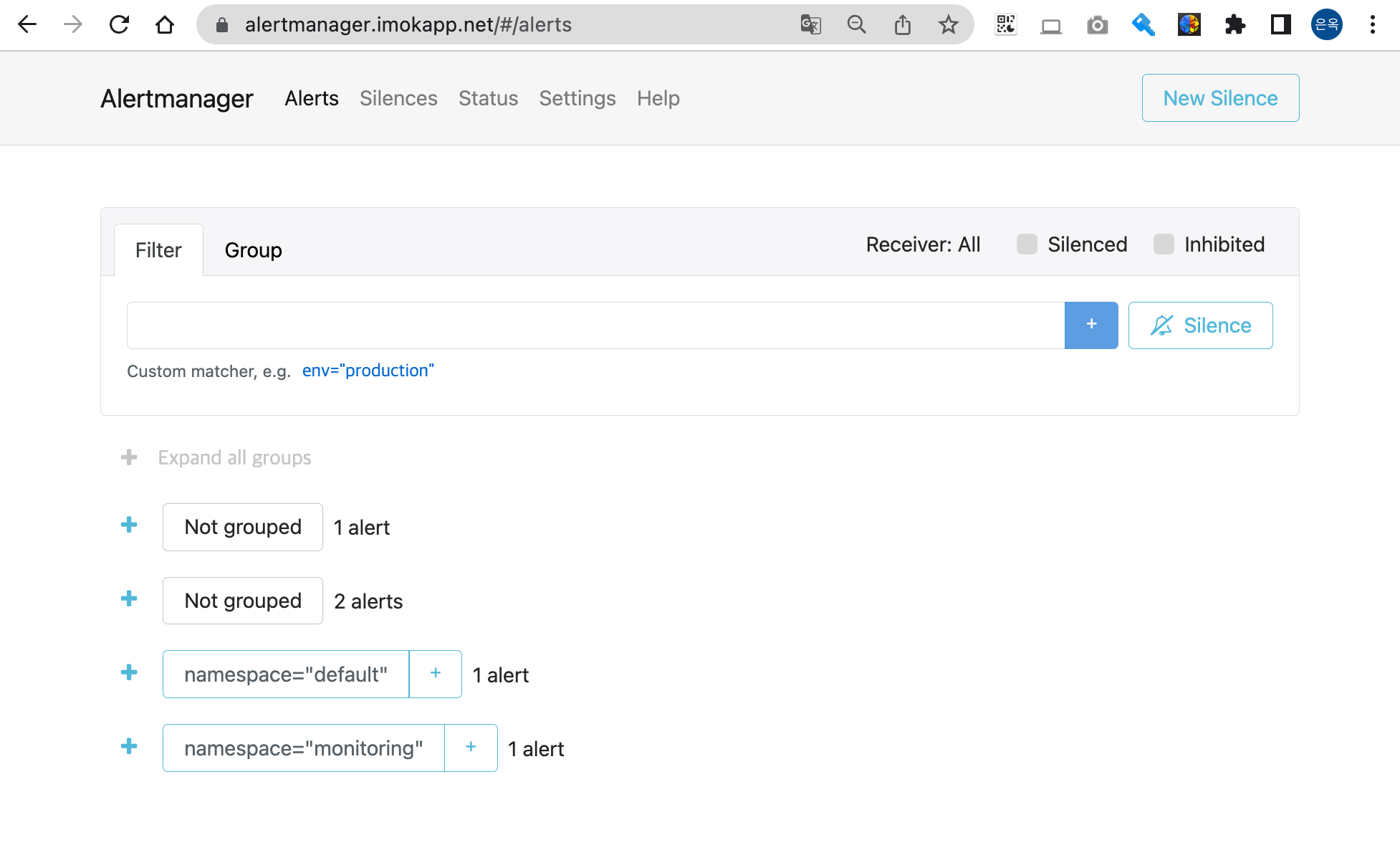
- Alerts 경고: 시스템 문제 시 프로메테우스가 전달한 경고 메시지 목록을 확인
- Silences 일시 중지 : 계획 된 장애 작업 시 일정 기간 동안 경고 메시지를 받지 않을 때, 메시지별로 경고 메시지를 일시 중단 설정
- Statue 상태 : 얼럿매니저 상세 설정 확인
얼럿매니저 대시보드 karma 컨테이너로 실행
# 실행
docker run -d -p 80:8080 -e ALERTMANAGER_URI=https://alertmanager.$KOPS_CLUSTER_NAME ghcr.io/prymitive/karma:latest
# 확인
docker ps
# karma 웹 접속 주소 확인
echo -e "karma Web URL = http://$(aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text)"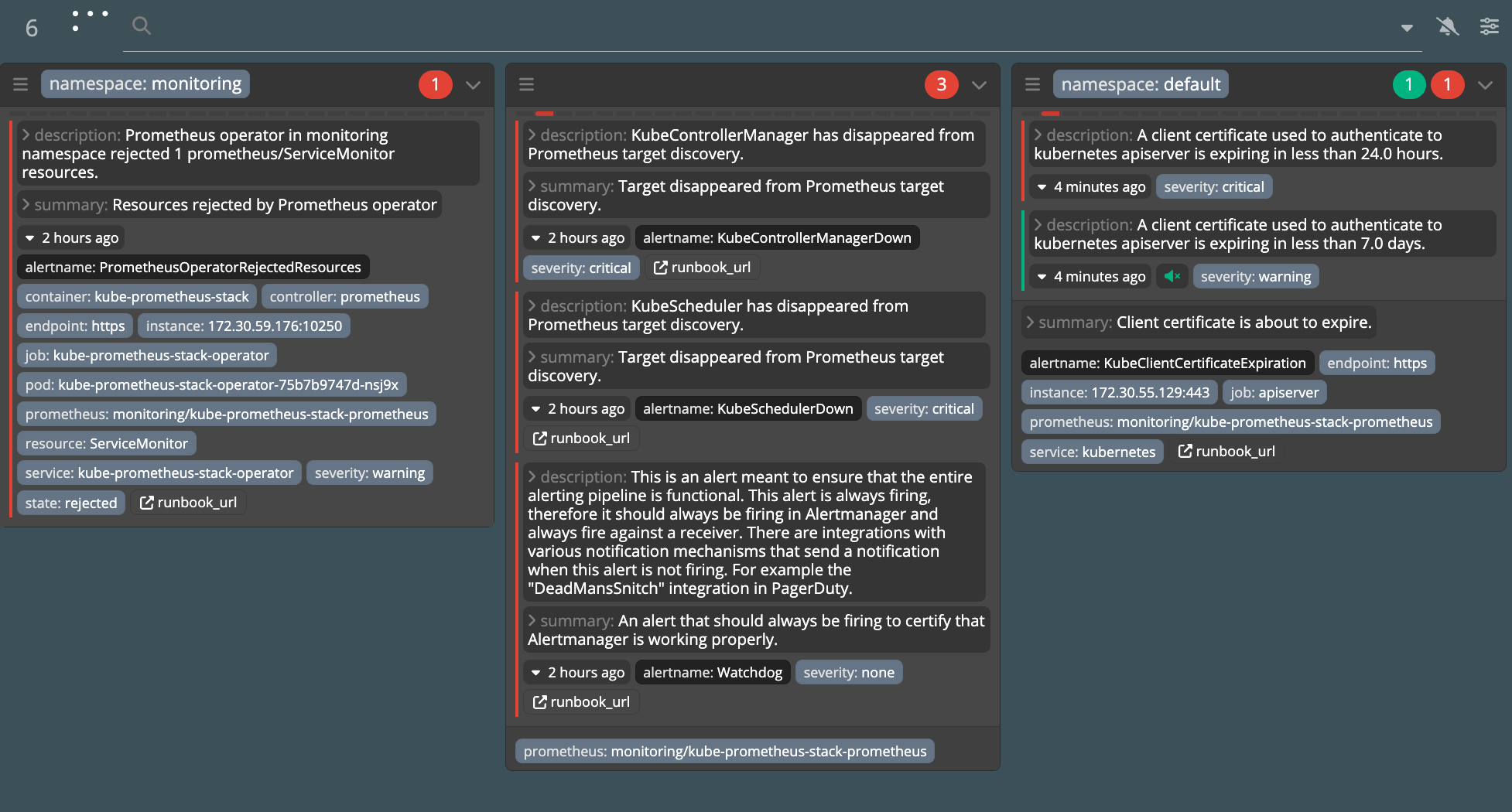
프로메테우스 웹 Alert & 얼럿매니저 웹 karma
프로메테우스 웹 접속 후 상단 Alert 메뉴 확인
- Inactive 비활성화 : prometheusrules 중 경고가 활성화되지 않은 정상적인 상태
- Pending 지연 : 설정한 임곗값을 초과해 경고 상황이지만 경고 메시지를 전달하기까지 임곗값 시간을 초과하지 않은 상태, 이를 통해 오탐과 자동 복구된 에러 메시지를 처리
- Firing 경보 : 임곗값과 임곗값 시간을 초과해서 경보가 발생한 메시지. 해당 메시지는 얼럿매니저에 전달되어 얼럿매니저를 통해 전파됨

# 프로메테우스 룰 확인
kubectl get prometheusrules -n monitoring
kubectl get prometheusrules -n monitoring kube-prometheus-stack-kubernetes-system-controller-manager -o json | jq
# 룰 전체 확인
kubectl get prometheusrules -n monitoring -o json | more
# 메트릭 이름 확인
kubectl get prometheusrules -n monitoring -o json | grep '"record":' | sed 's/^ *//'
kubectl get prometheusrules -n monitoring -o json | grep '"record":' | sed 's/^ *//' | wc -l
# 얼럿 이름 확인
kubectl get prometheusrules -n monitoring -o json | grep '"alert":' | sed 's/^ *//'
# 얼럿 갯수 확인
kubectl get prometheusrules -n monitoring -o json | grep '"alert":' | sed 's/^ *//' | wc -l
134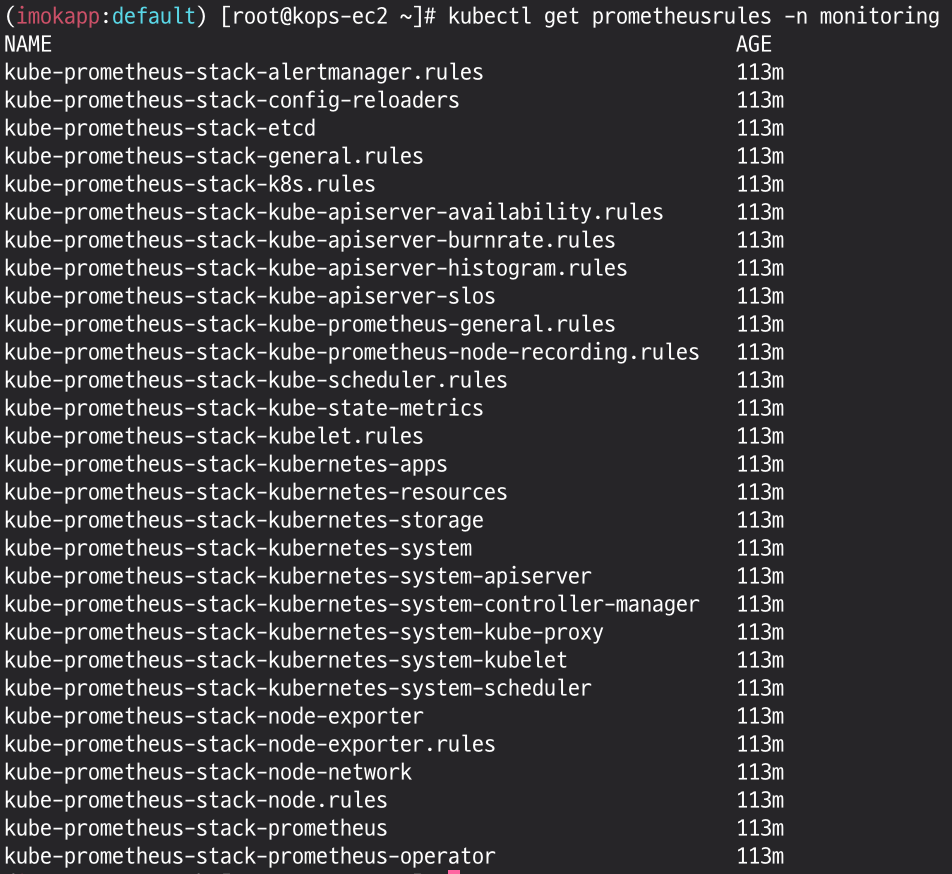
얼럿매니저 대시보드 karma 웹 접속 확인

ImOk👌