Cloudnet@에서 진행하는 쿠버네티스 실무 실습 스터디를 진행하면서 작성한 글입니다.
스터디에서 사용하는 교재는 24단계 실습으로 정복하는 쿠버네티스 입니다.
Cloudnet@
24단계 실습으로 정복하는 쿠버네티스
쿠버네티스 모니터링
쿠버네티스 모니터링 솔루션으로는 프로메테우스(Prometheus), 스카우터(Scouter) 등과 같은 오픈소스 솔루션, 데이터독(DataDog), 뉴렐릭(new relic) 등의 상용 솔루션으로 분류됩니다.
쿠버네티스 환경의 모니터링 대상
- 노드와 컨테이너 자원 사용량 모니터링
- CPU, 메모리, 네트워크, 스토리지 등
- 클러스터 모니터링
- 쿠버네티스 오브젝트의 전체 수량, 종류 등 전반적인 현황과 피드 재시작, 이벤트 메시지 등, 장애와 관련된 모니터링
- 애플리케이션 모니터링
- 컨트롤 플레인 파드(etcd, apiserver, coredns),페이지 응답 속도, 세션 수, 데이터베이스 쿼리 응답 속도 등 사용자 체감 정보
실습 환경 배포
aws cloudformation deploy \
--template-file kops-oneclick-f1.yaml \
--stack-name mykops \
--parameter-overrides KeyName=kops-key \
SgIngressSshCidr=$(curl -s ipinfo.io/ip)/32 \
MyIamUserAccessKeyID=AKI... \
MyIamUserSecretAccessKey='o4H...' \
ClusterBaseName='imokapp.net' \
S3StateStore='imok-k8s-study' \
MasterNodeInstanceType=c5a.2xlarge \
WorkerNodeInstanceType=c5a.2xlarge \
--region ap-northeast-2
ssh -i kops-key.pem ec2-user@$(aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text)
kops validate cluster --wait 10m
kubectl ns default프로메테우스
Prometheus : SoundCloud에서 만든 오픈소스 시스템 모니터링 및 경고 툴킷
Features

- 시계열 데이터베이스(time-series database, TSDB) 사용
- 강력한 queries PromQL 사용
- 다양한 애플리케이션 익스포터 제공 - HAProxy, StatsD, MySQL
- Pull 방식 - 중앙 서버가 모니터링 대상의 정보를 직접 가져오는 방식 ( <> Push 방식 - 에이전트가 중앙 서버로 모니터링 정보를 전달하는 방식 )
- 서비스 디스커버리 - 개별 모니터링 대상을 서비스 엔드포인트로 등록해 자동으로 변경 내역 감지
Architecture

프로메테우스 설치
프로메테우스-스택 설치 : 모니터링에 필요한 여러 요소를 단일 스택으로 제공
# 모니터링
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
echo "alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN"
# 설치
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > ~/monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.$KOPS_CLUSTER_NAME
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.$KOPS_CLUSTER_NAME
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.$KOPS_CLUSTER_NAME
paths:
- /*
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
EOT
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.7.1 \
--set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml --namespace monitoring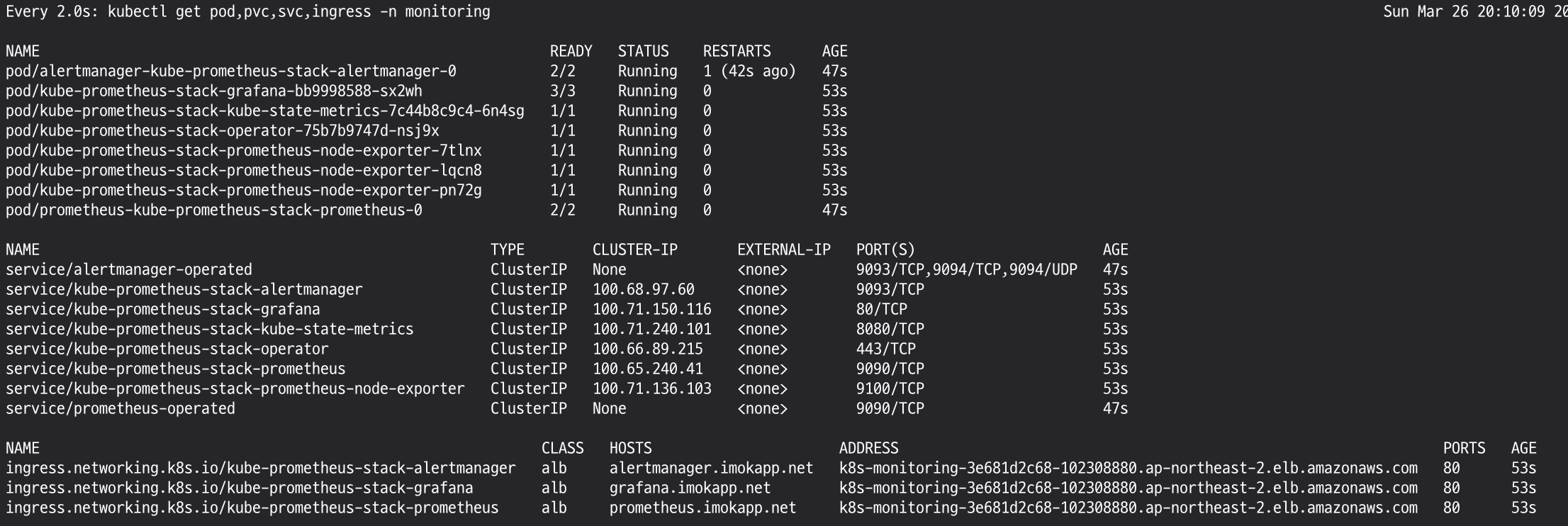
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
kubectl get pod,svc,ingress -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,alertmanager -n monitoring
kubectl get prometheusrule -n monitoring
kubectl get servicemonitors -n monitoring
kubectl get crd | grep monitoring프로메테우스 기본 사용
메트릭 정보 저장
- 모니터링 대상이 되는 서비스는 일반적으로 자체 웹 서버의
/metrics엔드포인트 경로에 다양한 메트릭 정보를 노출 - 이후 프로메테우스는 해당 경로에 http get 방식으로 메트릭 정보를 가져와 TSDB 형식으로 저장
# 아래 처럼 프로메테우스가 각 서비스의 9100 접속하여 메트릭 정보를 수집
kubectl get node -owide
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus-node-exporter
# 마스터노드에 lynx 설치
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME hostname
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME sudo apt install lynx -y
# 노드의 9100번의 /metrics 접속 시 다양한 메트릭 정보를 확인할수 있음 : 마스터 이외에 워커노드도 확인 가능
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME lynx -dump localhost:9100/metrics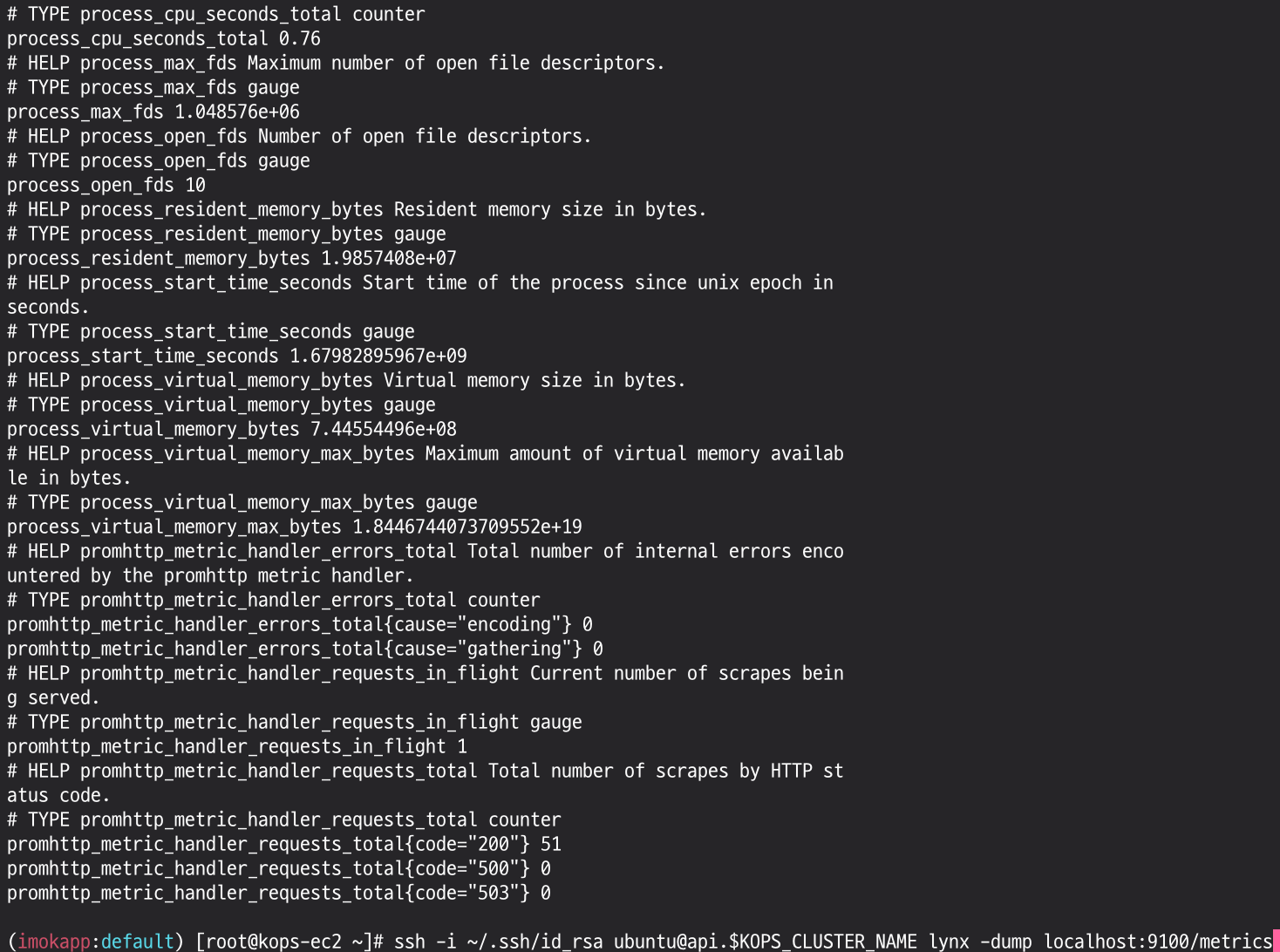
프로메테우스 도메인 접속
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-prometheus
kubectl describe ingress -n monitoring kube-prometheus-stack-prometheus
# 프로메테우스 ingress 도메인으로 웹 접속
echo -e "Prometheus Web URL = https://prometheus.$KOPS_CLUSTER_NAME"웹 상단 주요 메뉴 설명
- 경고(Alert) : 사전에 정의한 시스템 경고 정책(Prometheus Rules)에 대한 상황
- 그래프(Graph) : 프로메테우스 자체 검색 언어 PromQL을 이용하여 메트릭 정보를 조회 -> 단순한 그래프 형태 조회
- 상태(Status) : 경고 메시지 정책(Rules), 모니터링 대상(Targets) 등 다양한 프로메테우스 설정 내역을 확인 > 버전(2.42.0)
- 도움말(Help)
프로메테우스 설정 확인

메트릭을 그래프로 조회
Graph > 아래 PromQL 쿼리(전체 클러스터 노드의 CPU 사용량 합계)입력 후 조회 > Graph 확인
1- avg(rate(node_cpu_seconds_total{mode="idle"}[1m]))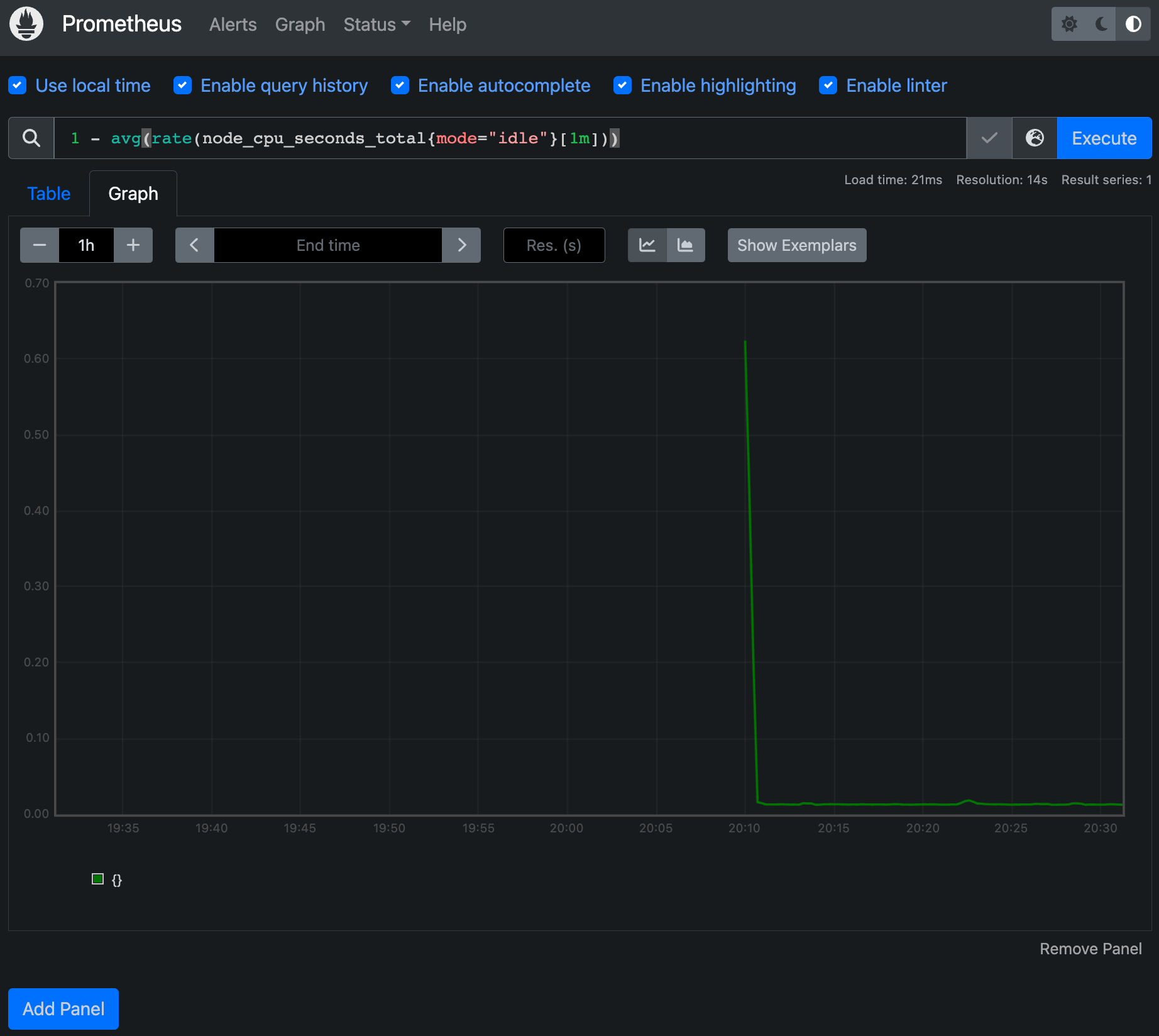
그라파나
그라파나는 다양한 데이터소스를 토대로 사용자 대시보드를 제공하는 솔루션입니다.
프로메테우스 데이터, 퍼블릭 클라우드, 라즈베리파이 등과 같은 데이터 소스, 로그, 메트릭 등 다양한 데이터 형식을 지원합니다.
TSDB 데이터를 시각화
다양한 데이터 형식 지원(메트릭, 로그, 트레이스 등)
그라파나는 시각화 솔루션으로 데이터 자체를 저장하지 않음
황금 신호(Golden-Signals)
구글이 공유한 모니터링 항목의 주요 요소
- 지연(Latency)
- 사용자 요청에 응답하는 소요 시간
- 데이터베이스가 웹 서비스의 쿼리에 응답하는 데 걸리는 시간
- 트래픽(Traffic)
- 웹 서비스에 대한 초당 HTTP 요청 또는 페이지 로드
- 데이터베이스, 스토리지 서비스에 대한 초당 트랜젝션
- 오류(Errors)
- 여러 가지 이유로 특정 요청이 실패했을 때 발생
- 포화도(Saturation)
- 트래픽 증가, 노드 장애 등의 상황이 발생했을 때 예비 노드에서 처리 가능한 시스템 자원 사용률
- 주어진 리소스가 한 번에 얼마나 많이 소비되고 있는지 측정
그라파나 기본 사용
접속 정보 확인 및 로그인 : 기본 계정 admin / prom-operator
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
# ingress 도메인으로 웹 접속
echo -e "Grafana Web URL = https://grafana.$KOPS_CLUSTER_NAME"
웹 주요 메뉴 설명
- Search dashboards : 대시보드 검색
- Starred : 즐겨찾기 대시보드
- Dashboards : 대시보드 전체 목록 확인
- Explore : 쿼리 언어 PromQL를 이용해 메트릭 정보를 그래프 형태로 탐색
- Alerting : 경고, 에러 발생 시 사용자에게 경고를 전달
- Configuration : 설정, 예) 데이터 소스 설정 등
- Server admin : 사용자, 조직, 플러그인 등 설정
- admin : admin 사용자의 개인 설정
Configuration → Data sources : 스택의 경우 자동으로 프로메테우스를 데이터 소스로 추가해둠

# 서비스 주소 확인
kubectl get svc,ep -n monitoring kube-prometheus-stack-prometheus
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-prometheus-stack-prometheus ClusterIP 100.70.252.201 <none> 9090/TCP 92m
NAME ENDPOINTS AGE
endpoints/kube-prometheus-stack-prometheus 172.30.55.6:9090 92m해당 데이터 소스 접속 확인
# 테스트용 파드 배포
kubectl apply -f ~/pkos/2/netshoot-2pods.yaml
kubectl get pod
# 접속 확인
kubectl exec -it pod-1 -- nslookup kube-prometheus-stack-prometheus.monitoring
kubectl exec -it pod-1 -- curl -s kube-prometheus-stack-prometheus.monitoring:9090/graph -v
# 삭제
kubectl delete -f ~/pkos/2/netshoot-2pods.yaml
대시보드 사용
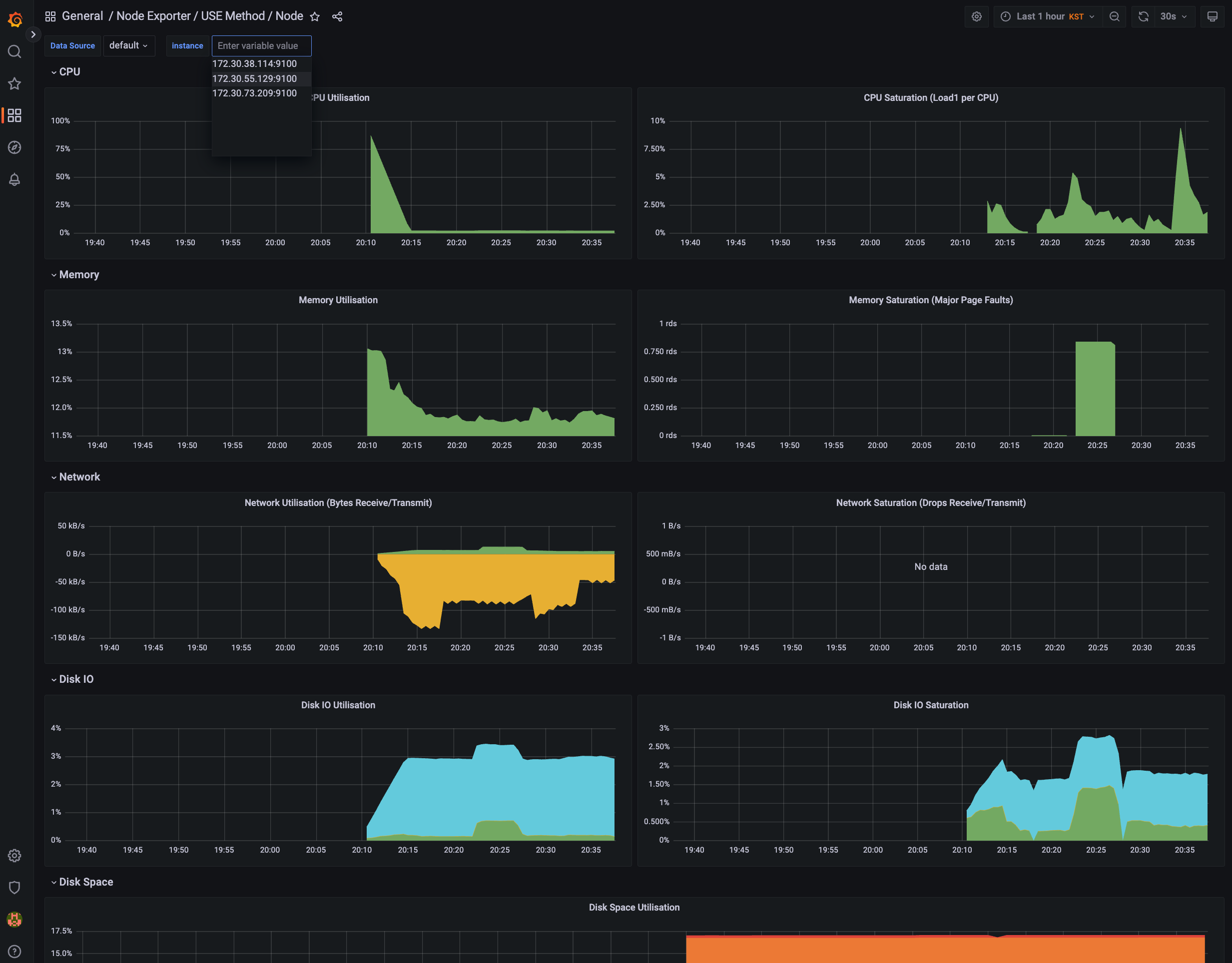
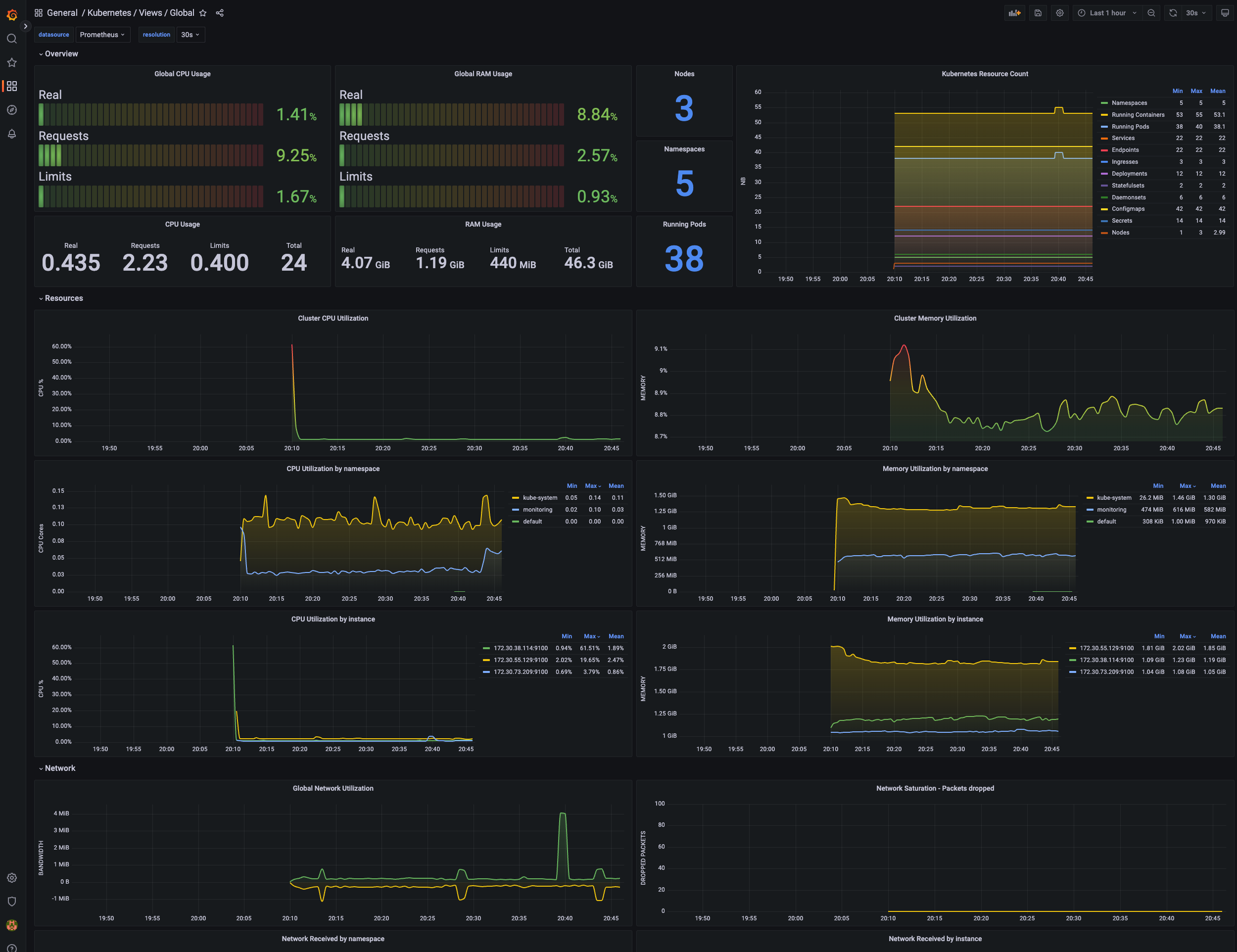
기본 대시보드
스택을 통해서 설치된 기본 대시보드 확인 : Dashboards → Browse
공식 대시보드 가져오기

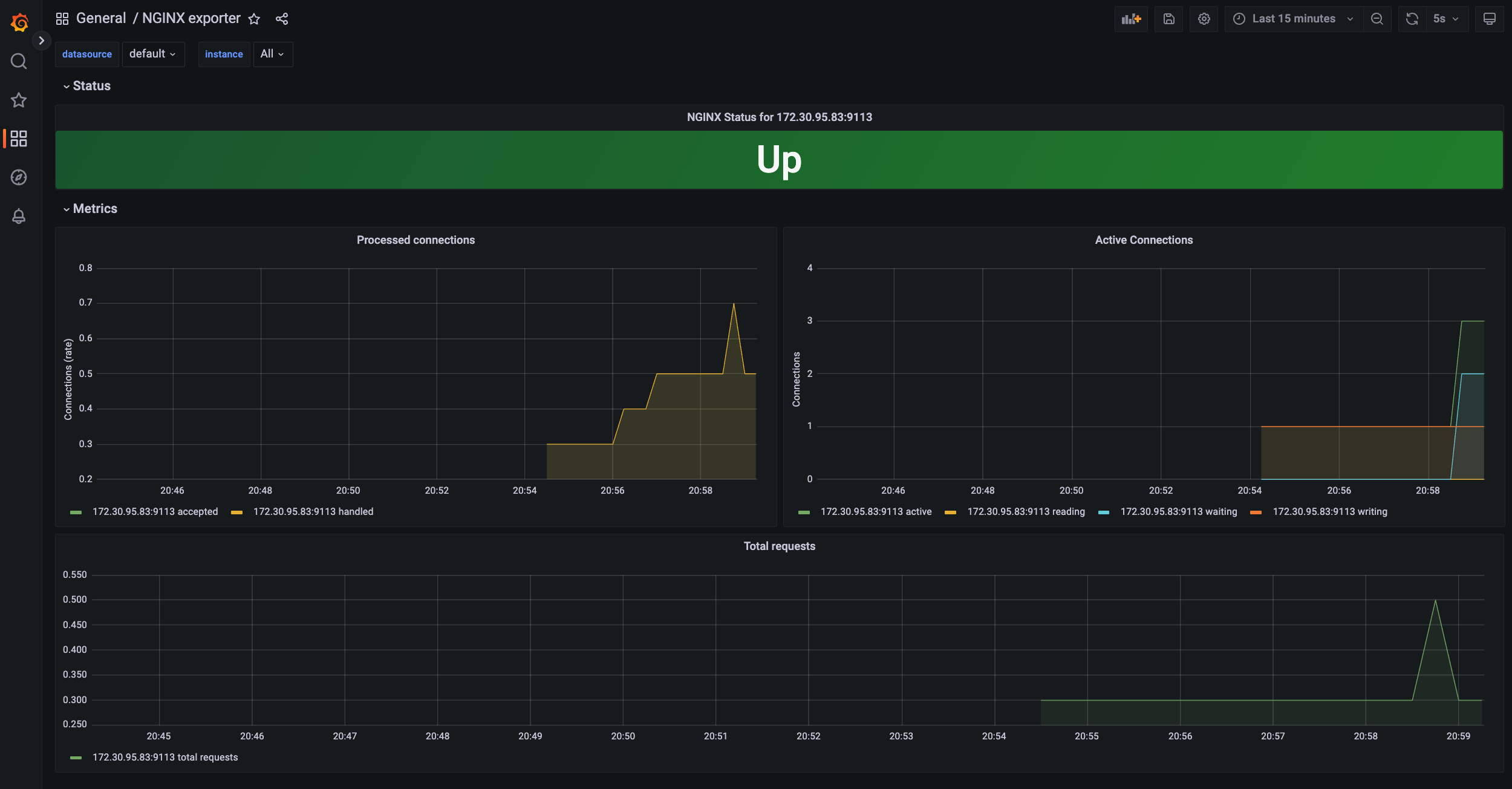
NGINX 웹서버 배포 및 애플리케이션 모니터링 설정 및 접속
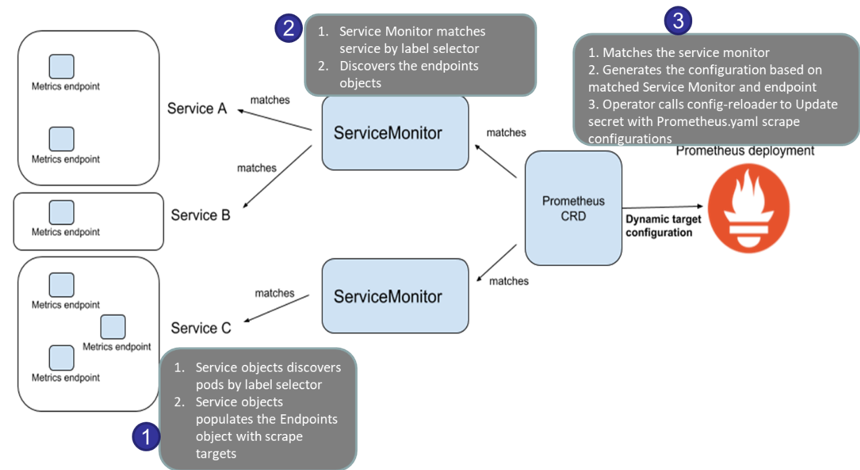
서비스 모니터 동작
cluster-monitoring-with-prometheus-operator
nginx 웹 서버 helm 설치
# help repo add
helm repo add bitnami https://charts.bitnami.com/bitnami
# 파라미터 파일 생성 : 서비스 모니터 방식으로 nginx 모니터링 대상을 등록하고, export 는 9113 포트 사용, nginx 웹서버 노출은 AWS CLB 기본 사용
cat <<EOT > ~/nginx-values.yaml
metrics:
enabled: true
service:
port: 9113
serviceMonitor:
enabled: true
namespace: monitoring
interval: 10s
EOT
# 배포
helm install nginx bitnami/nginx --version 13.2.23 -f nginx-values.yaml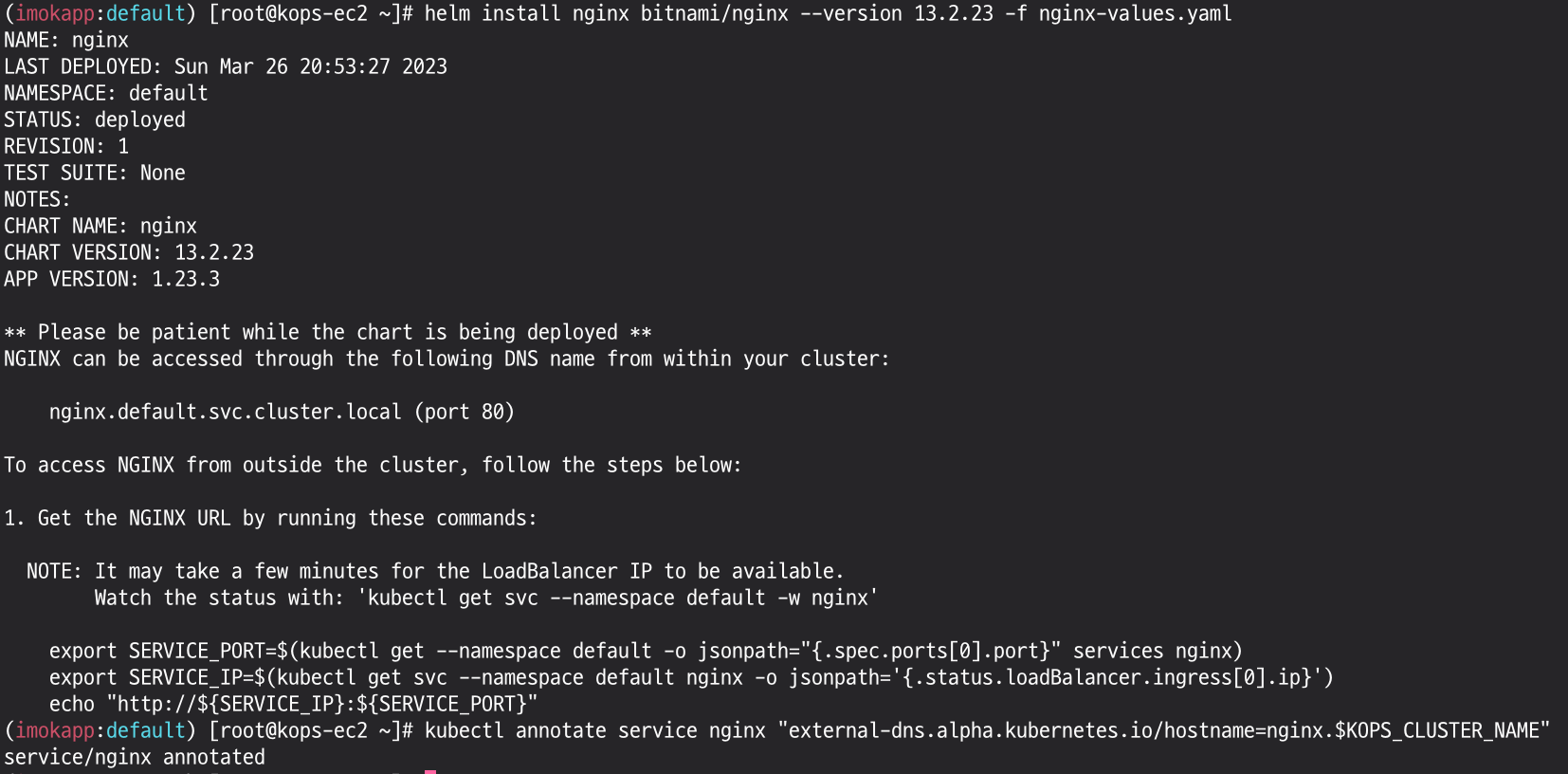
# CLB에 ExternanDNS 로 도메인 연결
kubectl annotate service nginx "external-dns.alpha.kubernetes.io/hostname=nginx.$KOPS_CLUSTER_NAME"
# 확인
kubectl get pod,svc,ep
kubectl get servicemonitor -n monitoring nginx
kubectl get servicemonitor -n monitoring nginx -o json | jq
# nginx 파드내에 컨테이너 갯수 확인
kubectl get pod -l app.kubernetes.io/instance=nginx
kubectl describe pod -l app.kubernetes.io/instance=nginx
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = http://nginx.$KOPS_CLUSTER_NAME"
curl -s http://nginx.$KOPS_CLUSTER_NAME
kubectl logs deploy/nginx -f
# 반복 접속
while true; do curl -s http://nginx.$KOPS_CLUSTER_NAME -I | head -n 1; date; sleep 1; done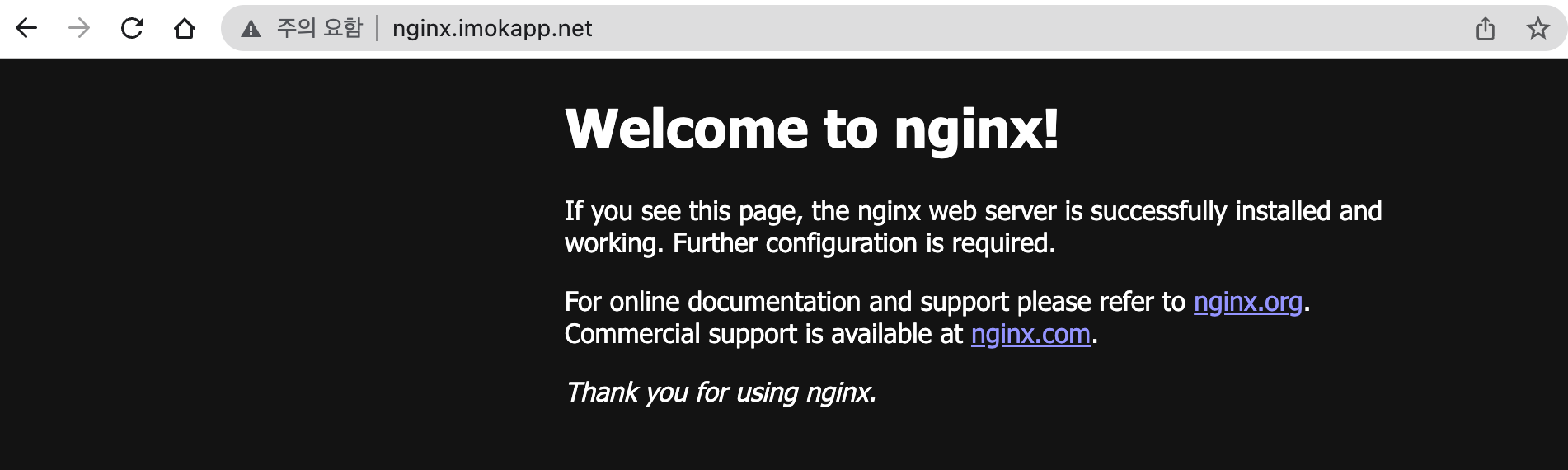
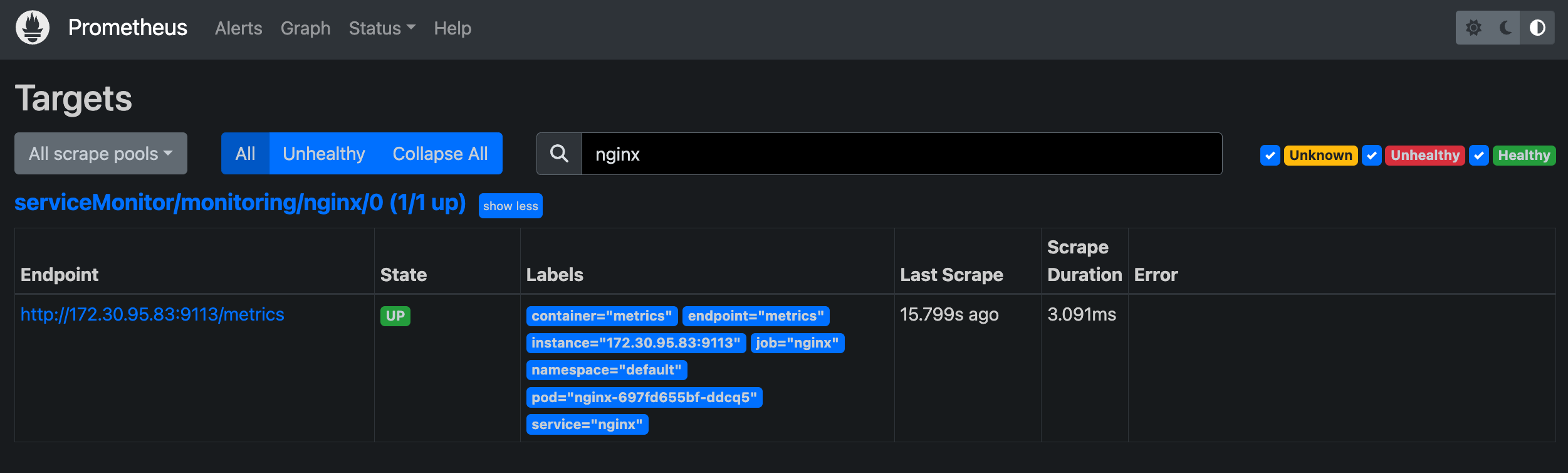
프로메테우스 웹서버 확인
state > target에 nginx 서비스 모니터 추가 확인
그라파나 대시보드 추가
12708 대시보드 추가