1. learing rate
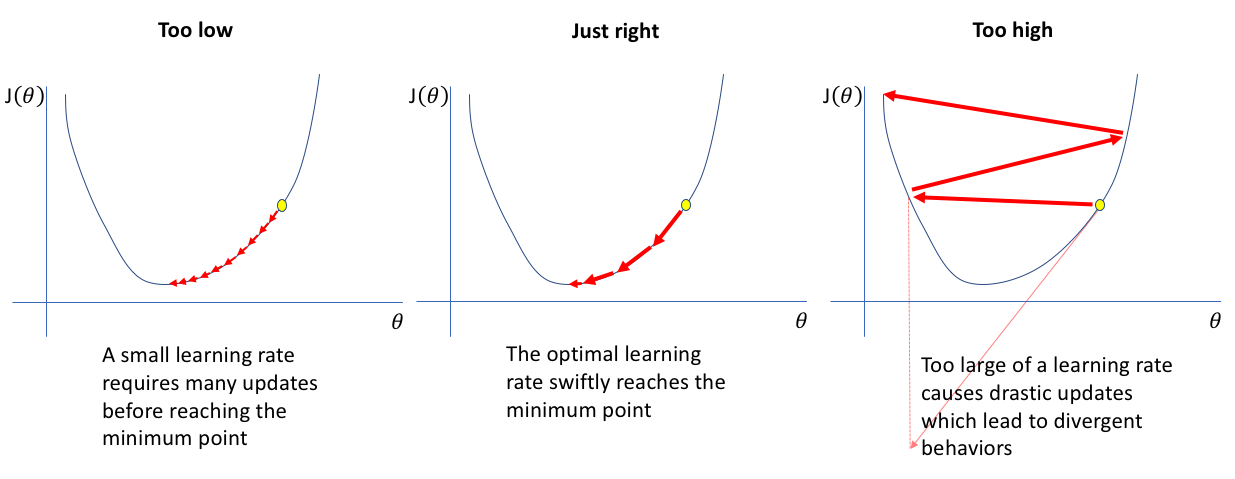
- Too low
전역 최적점에 도달하기까지 매우 오랜 시간이 걸린다.
- Too high
전역 최적점으로 수렴하지 않고 발산 하게 된다.
-> 처음에는 높게, 이후에는 조금씩 줄이는것이 논리적.
2. SGD
- SGD는 train dataset 중 랜덤하게 일부만 뽑아 loss에 대한 gradient를 계산
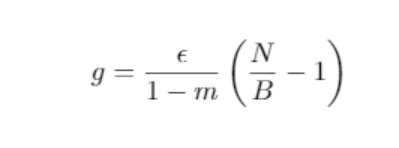
위 식은 scale of random fluctuation으로 랜덤성을 나타냄
m - momentum , N = train data size
e = lr , B = batch size
N(5000~)은 일반적으로 B(8, 16, 32, 64)보다 크므로
근사시키면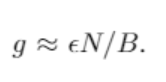
따라서 lr의 감소와 B의 증가는 같은 효과
하지만 B의 증가는, 메모리가 허락하는 한 학습의 속도를 증가시키기 때문에 N의 감소보다 효율적이다.

천재(진)