라즈베리파이에서 카메라 모듈로 촬영한 약 사진을 받아 와서, 텍스트를 추출해 해당 약에 대한 정보를 DB에서 찾는 기능을 구현해야 했다.
이 때, 사진에서 약 이름 텍스트를 추출하는 과정을 구현한 과정에 대해 작성해보고자 한다.
이미지에서 텍스트를 추출하는 기술인 OCR(Optical Character Recognition) API로는 Tesseract-OCR과 Google Vision API 등이 있다.
먼저 Tesseract-OCR은 OCR API 중 오픈소스로 가장 유명한 API이다. 그에 비해 Google Vision API는 딥러닝(Deep Learning) 기술을 이용해서 텍스트 추출에 대한 학습을 하여 최적의 텍스트 추출을 위한 기능을 제공하고 있다.
📌 tesseract.js
먼저 tesseract.js는 머신러닝 기반의 이미지(동영상) - 텍스트 검출 라이브러리이다.
tesseract.js는 CDN, Node.js를 지원한다.
⚙️ 기능 구현 과정
1. tesseract.js 라이브러리 설치
npm install tesseract.js
2. 예제 코드 테스트
// imgToText.js
import { createWorker } from 'tesseract.js';
const worker = await createWorker({
logger: (m) => console.log(m),
});
(async () => {
await worker.loadLanguage('eng');
await worker.initialize('eng');
const {
data: { text },
} = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png');
console.log(text);
await worker.terminate();
})();-
테스트 코드 실행
node imgToText.js
-
이미지

-
텍스트 추출 결과
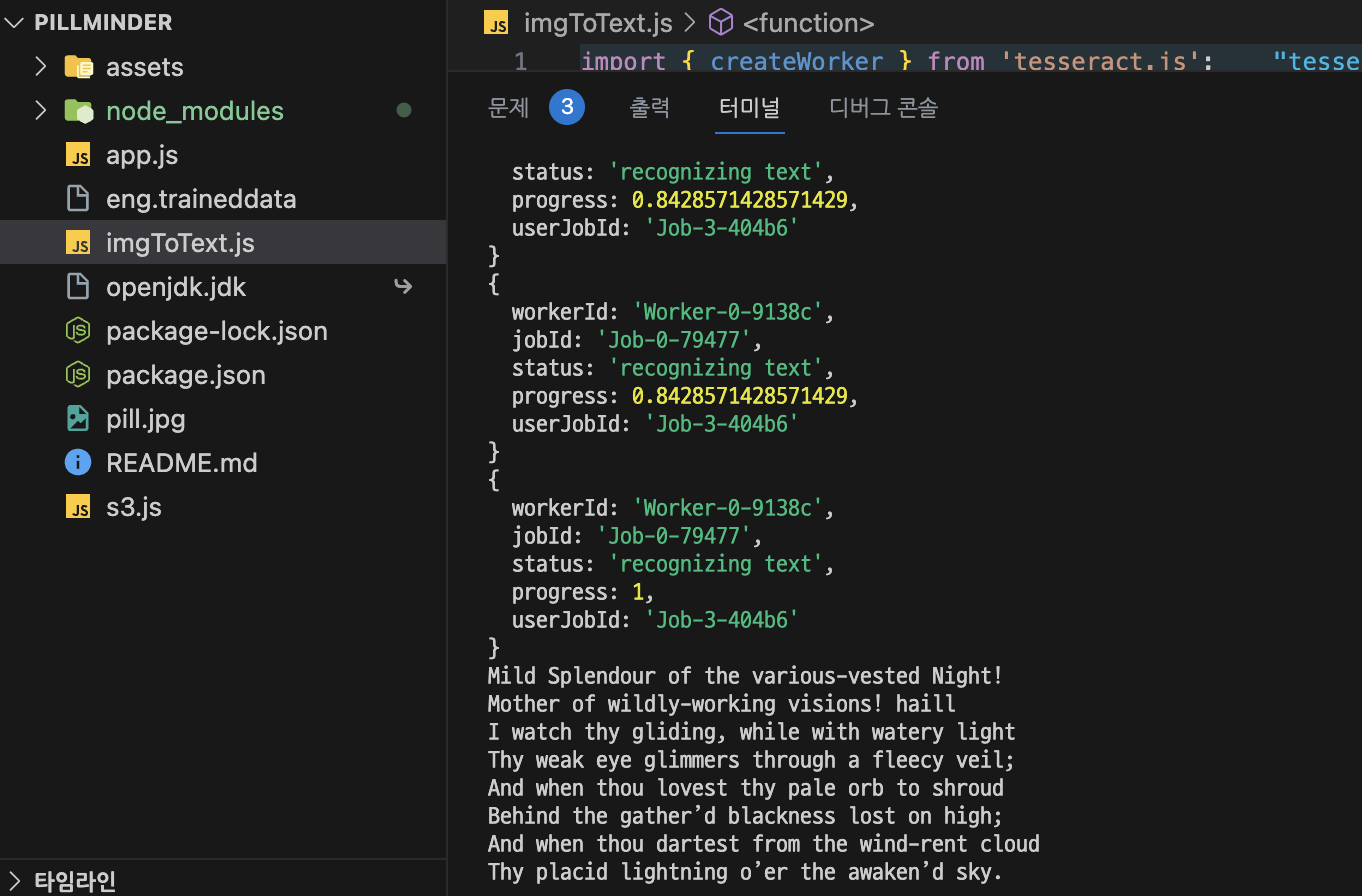
eng.traineddata라는 파일이 생기고, 콘솔을 통해 추출 결과를 확인할 수 있다.
- 한글 이미지 텍스트 추출
await worker.loadLanguage('kor');
await worker.initialize('kor');- 이미지


- 텍스트 추출 결과
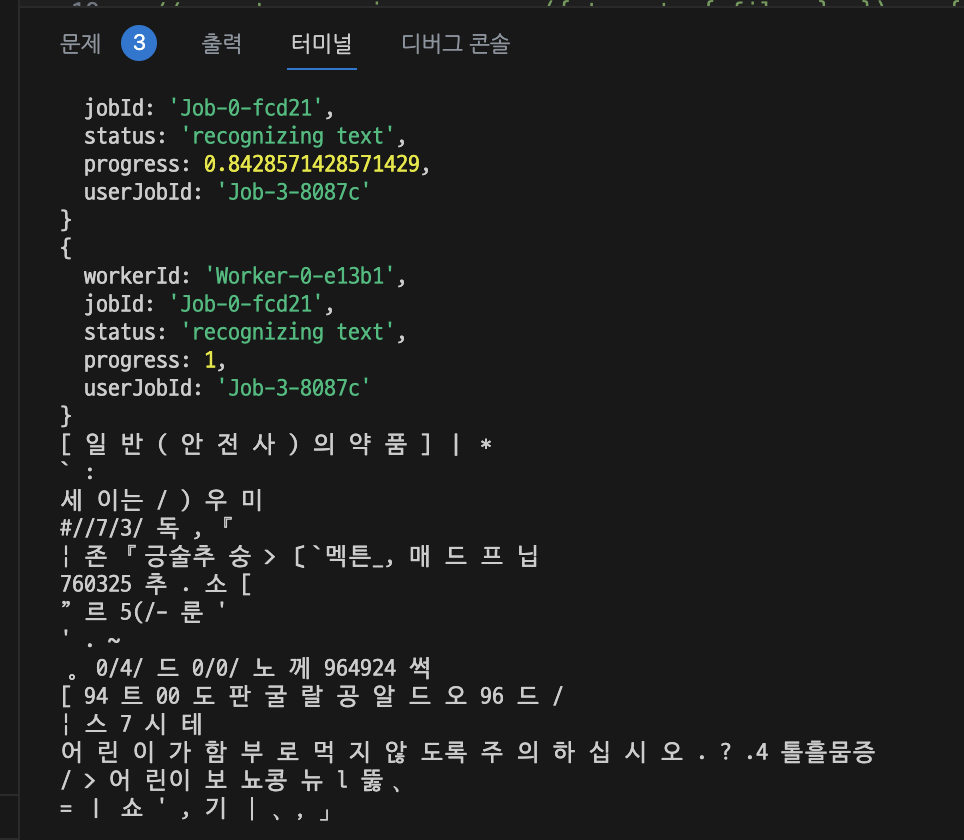
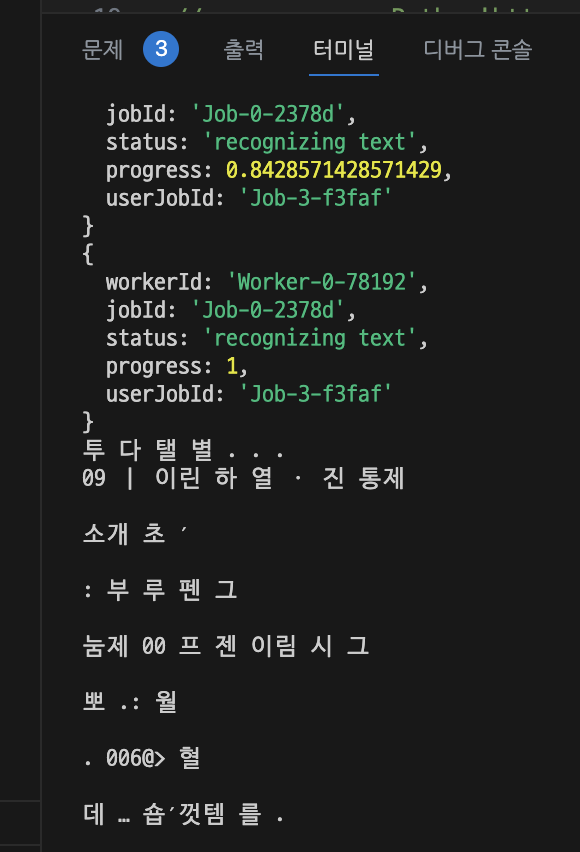
하하...^^
^^^
이게 제대로 추출된게 맞나 싶을 정도로 정확도가 너무 떨어졌다.
그래서 Google Vision API로 텍스트를 추출하는 방법으로 변경해보았다.
📌 Google Vision API
Google Vision API는 Google Cloud에서 제공하는 서비스 중 하나로, API를 사용할 때마다 일정 요금이 부과되는 서비스이다. Google Cloud를 최초에 가입할 경우에는 무료 Credit을 부여하기 때문에 일정 기간 또는 용량 범위 내에서는 무료로 사용이 가능하다. 1000회까지는 무료, 그 이후부터는 월 $1.5의 요금이 청구된다.
Vision API는 사실 이미지에서 텍스트를 추출하기 위한 전용 기술은 아니다. 이미지에 대한 다양한 처리를 수행하며, 그 중에서 텍스트 추출은 그 기능의 일부분이다.
일반적으로 Vision API에 대한 이미지 처리는 이미지 데이터를 request로 받으면 이에 대한 response를 JSON 형태의 데이터로 반환하도록 구성되어 있으며, REST Framework를 많이 사용한다. 하지만 그 외에도 C#, GO, Java, Node.js, PHP, Python, Ruby 언어도 지원한다.
⚙️ 기능 구현 과정
1. Google Cloud 계정 만들기
Google Cloud Vision API를 사용하려면 Google Cloud 계정이 필요하다.
https://console.cloud.google.com
해당 사이트에서 회원가입을 진행한다.
2. 프로젝트 및 인증 정보 설정
좌측 메뉴에서 API 및 서비스 > 사용자 인증 정보 탭을 클릭하고 서비스 계정을 생성한다.
계정 생성 후 키 탭으로 이동하면 인증 키가 담긴 JSON 파일이 다운로드된다.
3. @google-cloud/vision 패키지 설치
npm install @google-cloud/vision
4. 인증 정보 로드
다운로드한 서비스 계정 키 JSON파일을 Node.js 프로젝트 내에 저장한 뒤 아래 코드를 통해 인증 정보를 불러온다.
const { ImageAnnotatorClient } = require('@google-cloud/vision');
const client = new ImageAnnotatorClient({
keyFilename: 'path/to/service-account-key.json',
});
5. 이미지에서 텍스트 추출
OCR을 수행할 이미지를 로컬에 저장하고 client.textDetection 메서드를 사용하여 이미지에서 텍스트를 추출한다.
async function detectText() {
const [result] = await client.textDetection('path/to/image.jpg');
const annotations = result.textAnnotations;
console.log('Text:');
annotations.forEach(annotation => {
console.log(annotation.description);
});
}
detectText();- 텍스트 추출 결과
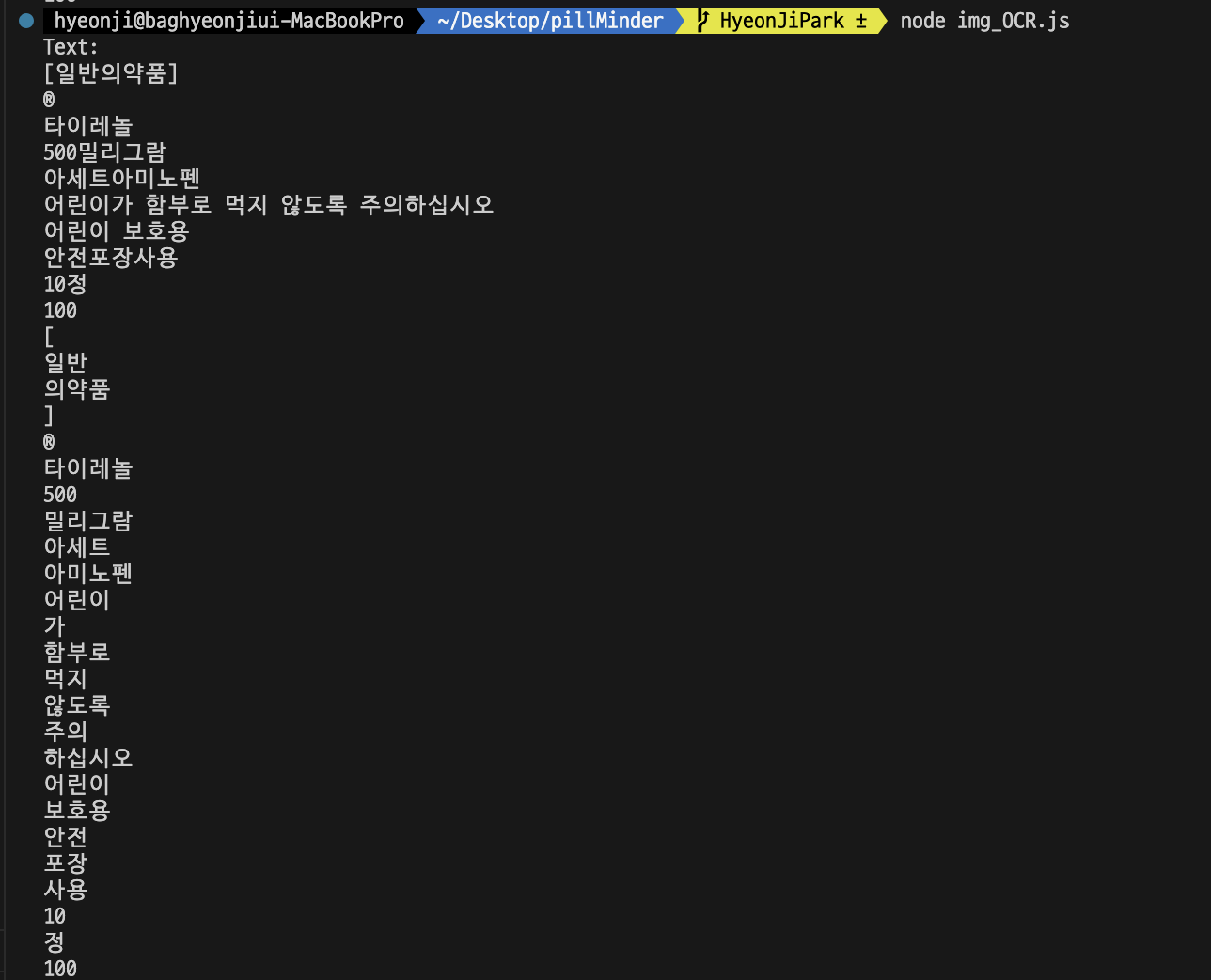
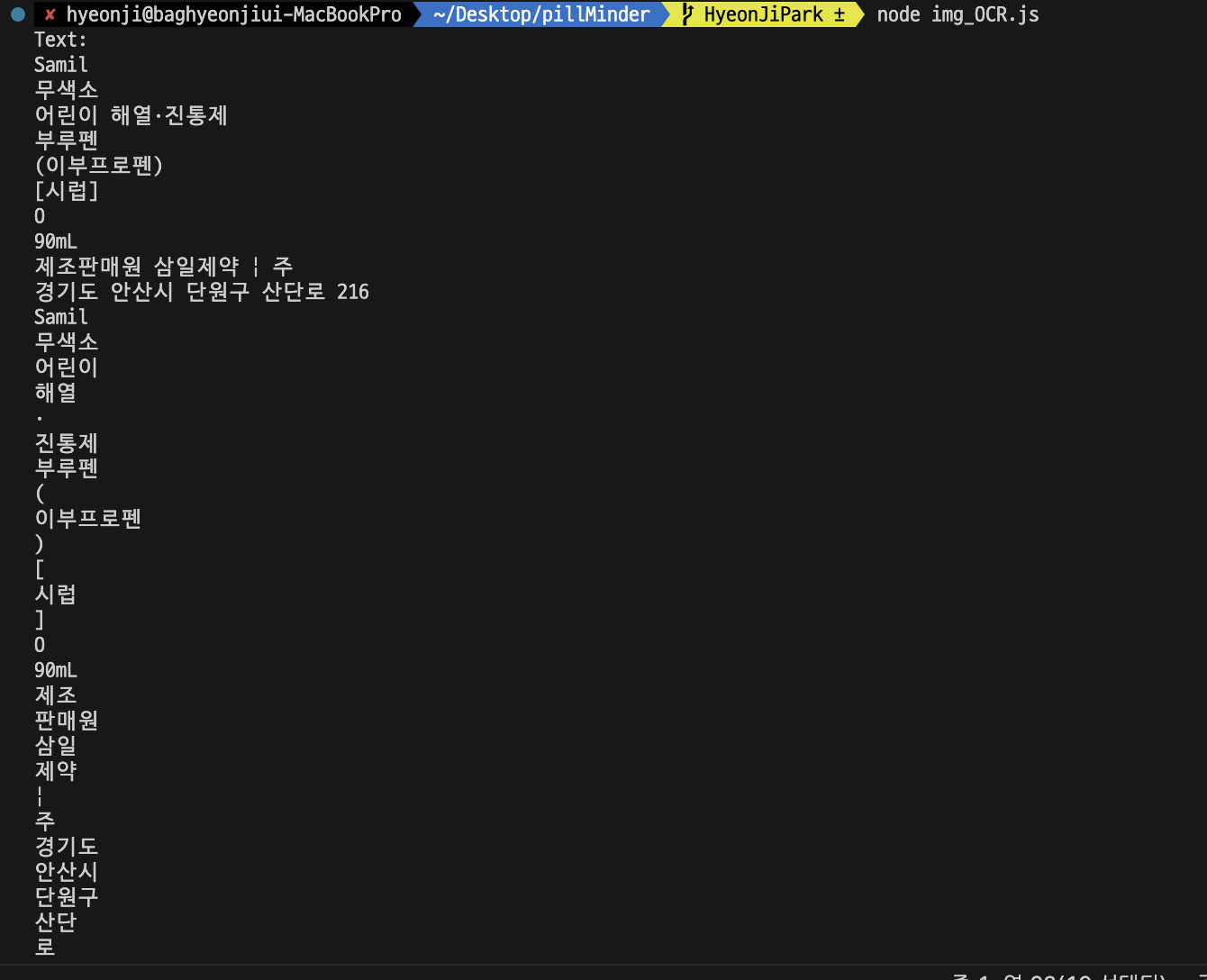
위 tesseract.js와 동일한 사진으로 OCR을 수행한 결과이다.
tesseract.js에 비해 훨씬 높은 정확도를 보여주었다. 역시 구글...ㅋㅋ
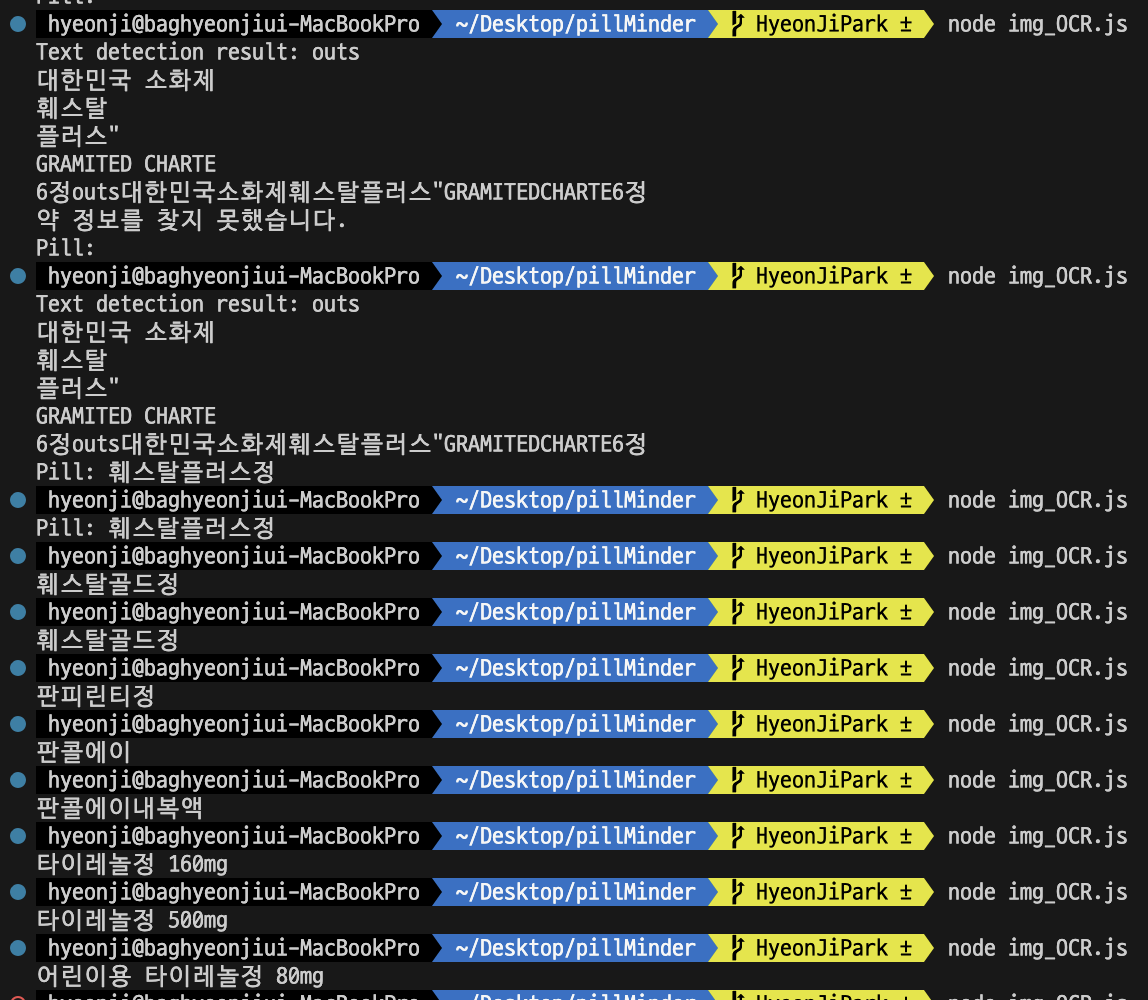
💊 추출한 텍스트를 통해 약 정보 저장하기
저장할 약 정보를 미리 저장해두고, 사진에서 특정 키워드가 추출되면 해당 약의 이름을 리턴하는 방식으로 구현하였다.
함수는 아래와 같이 나누었다.
1. 이미지에서 텍스트를 추출하는 함수
2. 추출한 텍스트에서 pill 정보를 찾는 함수
3. 찾은 pill 정보를 리턴하는 함수
const { ImageAnnotatorClient } = require('@google-cloud/vision');
const client = new ImageAnnotatorClient({
keyFilename: '키 JSON 파일',
});
const PILLS = [
{ name: '닥터베아제정', keywords: ['보강된2단계빠른소화제베아제'] },
{ name: '베아제정', keywords: ['위와 장에서 작용하는 2단계 빠른 소화제'] },
{ name: '어린이 타이레놀 무색소현탁액', keywords: ['현탁액'] },
{ name: '어린이 부루펜시럽', keywords: ['부루펜'] },
{ name: '어린이용 타이레놀정 80mg', keywords: ['80밀리그람아세트아미노펜'] },
{ name: '타이레놀정 160mg', keywords: ['타이레놀정160밀리그람'] },
{ name: '타이레놀정 500mg', keywords: ['타이레놀정500밀리그람'] },
{ name: '판콜에이내복액', keywords: ['판콜에이'] },
{ name: '판피린티정', keywords: ['판피린'] },
{ name: '훼스탈골드정', keywords: ['훼스탈골드정'] },
{ name: '훼스탈플러스정', keywords: ['훼스탈플러스'] },
];
let imagePath = './images/닥터베아제정.png';
// 이미지에서 텍스트를 추출하는 함수
async function detectText(imagePath) {
try {
const [result] = await client.textDetection(imagePath);
const annotations = result.textAnnotations;
return annotations.map((annotation) => annotation.description).join('');
} catch (error) {
console.error('텍스트 추출 중 오류가 발생했습니다.', error);
throw error;
}
}
// 추출한 텍스트에서 pill 정보를 찾는 함수
function findPill(text) {
let pill = '';
PILLS.forEach((item) => {
const isMatch = item.keywords.some((keyword) => text.includes(keyword));
if (isMatch) {
pill = item.name;
}
});
return pill;
}
// 찾은 pill 정보를 리턴하는 함수
async function detectPillFromImage(imagePath) {
try {
const textResult = await detectText(imagePath);
const pill = findPill(textResult);
if (pill === '') {
console.log('약 정보를 찾지 못했습니다.');
} else {
console.log(pill);
return pill;
}
} catch (error) {
console.error('오류가 발생했습니다.', error);
}
}
detectPillFromImage(imagePath);
11가지 종류의 약 사진으로 테스트 결과 모두 성공!!