
1. 컬렉션 중심 프로그래밍의 4가지 유형과 함수
1. 수집하기
- map, values, pluck 등
2. 거르기
- filter, reject, compact, without 등
3. 찾아내기
- find, some, every 등
4. 접기
- reduce, min, max, group_by, count_by
💌 첫 번째 : 수집하기
1) map, values
// 1. 수집하기 - map
function _values(data) {
return _map(data, function (val) { return val; });
}
console.log(users[0]);
console.log(_keys(users[0]));
console.log(_values(users[0]));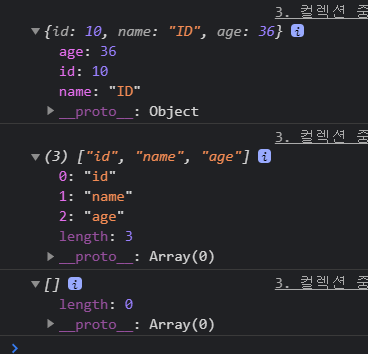
※ identity를 사용해서 코드 간략화
function _identity(val) {
return val;
}
var a = 10;
console.log(_identity(a));이미 a의 값을 알고 있는데 뭣하러 _identity를 써야 하나 싶은데
이걸 쓰면 _values 작성에 필요한 내용을 대체할 수 있음
즉,
function _values(data) {
return _map(data, _identity);
}으로 간략화할 수 있다.
🔸🔹🔸🔹
더 간단히 적을 수도 있다!
var _values = _map(_identity);2) pluck
배열(users) 내부에 있는 객체에 있는 이 키('age')에 의해 꺼내진 값들을 수집하는게 pluck
function _pluck(data, key) {
return _map(data, function (obj) {
return obj[key];
});
}
_pluck(users, 'age');
console.log(_pluck(users, 'age'));
console.log(_pluck(users, 'name'));
이-지 하니까 실무에서도 자주 쓰인다고 한다.
※ _get함수로 코드 간략화
function _pluck(data, key) {
return _map(data, _get(key));
}💌 두 번째 : 거르기
1) reject
filter의 반대라고 생각하면 쉽다.
/* filter */
console.log(
_filter(users, function (user) {
return user.age > 30;
})
)
/* reject */
function _reject(data, predi) {
return _filter(data, function (val) {
return !predi(val); //반대로 뒤집음
})
}
console.log(
_reject(users, function (user) {
return user.age > 30;
})
)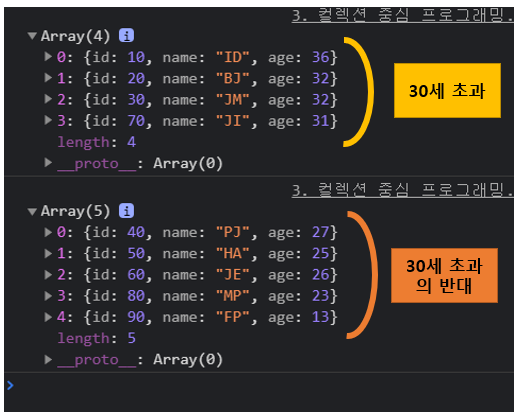
위에가 filter, 아래가 reject
※ _negate함수로 코드 간략화
/* 간략화하기 */
function _reject(data, predi) {
return _filter(data, _negate(predi));
}
function _negate(func) {
return function (val) {
return !func(val);
}
}💌 세 번째 : 찾아내기
1) find
- 배열안에 있는 값을 돌면서 처음으로 predicated를 넘겼을 때 true로 평가되는 값을 만나면 그 값 하나를 꺼내는 함수
filter와 비슷하지만 filter는 predicate와 맞는 모~든 값을 거른다 는 점과 달리 find는 하나의 값만 리턴 된다.
function _find(list, predi) {
var keys = _keys(list);
for (var i = 0; i < list.length; i++) {
var val = list[keys[i]];
if (predi(val)) return val
}
}
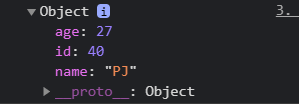
console.log(
_find(users, function (user) {
return user.age < 30;
})
)
🔸🔹🔸🔹
이런식으로 사용한다.
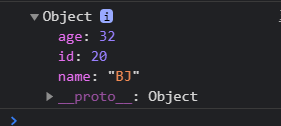
console.log(
_find(users, function (user) {
return user.id == 20;
})
)
2) find_index
- 해당하는 값을 처음 만났을 때의 index 값을 리턴
function _findindex(list, predi) {
var keys = _keys(list);
for (var i = 0; i < list.length; i++) {
if (predi(list[keys[i]])) return i;
}
return -1;
}
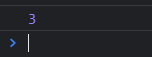
console.log(
_findindex(users, function (user) {
return user.age < 30;
})
)
3) some
function _some(data, predi) {
return _find_index(data, predi) != -1;
//하나라도 만족해서 true인 index가 있다면 -1이 아니겠지
}
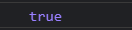
console.log(
_some([1, 2, 5, 10, 20], function (val) {
return val > 10;
}));
4) every
function _every(data, predi) {
return _find_index(data, _negate(predi)) == -1;
//하나도 false인 값을 찾지 못했다 -> true
}
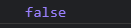
console.log(
_every([1, 2, 5, 10, 20], function (val) {
return val > 3;
}));
💌 네 번째 : 접기
1) min, max, min_by, max_by
(1) min, max
function _min(data) {
return _reduce(data, function(a, b) {
return a < b ? a : b;
});
}
function _max(data) {
return _reduce(data, function(a, b) {
return a > b ? a : b;
});
}
console.log(_min([1, 2, 4, 10, -3, -8]));
console.log(_max([1, 2, 4, 10, -3, -8]));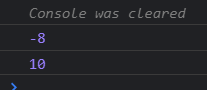
(1) min_by, max_by
function _min_by(data, iter) {
return _reduce(data, function(a, b) {
return iter(a) < iter(b) ? a : b;
});
}
function _max_by(data, iter) {
return _reduce(data, function(a, b) {
return iter(a) > iter(b) ? a : b;
});
}
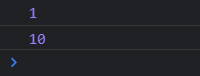
console.log(_min_by([1, 2, 4, 10, -3, -8], Math.abs));
console.log(_max_by([1, 2, 4, 10, -3, -8], Math.abs));배열 요소의 절댓값의 크기를 비교하고 싶은데 음수값이 있다.
(-1)을 곱해 데이터를 바꿔버리면 나중에 다른 코드 짤 때 곤란하다.
이 때 쓰기 위해 min_by와 max_by 함수를 정의한다.
이들은 데이터를 제멋대로 변형하지 않고도 비교해준다.
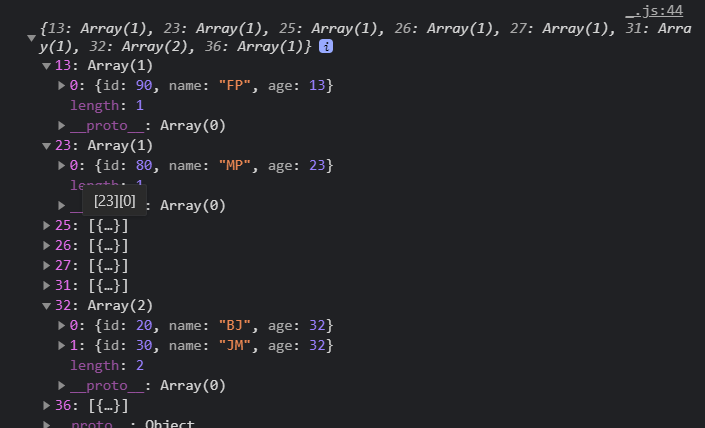
2) group_by, push
특정 조건을 통해서 그룹을 만든다.
접기 (reduce)에 특화된 함수
/* 나이로 그루핑 */
var _group_by = _curryr(function (data, iter) {
return _reduce(data, function (grouped, val) {
var key = iter(val);
(grouped[key] = grouped[key] || []).push(val);
//그룹된 객체에 key가 있는지 확인
//원래 있던 key에 넣을지 || 새로운 키가 필요한지
return grouped;
}, {});
});
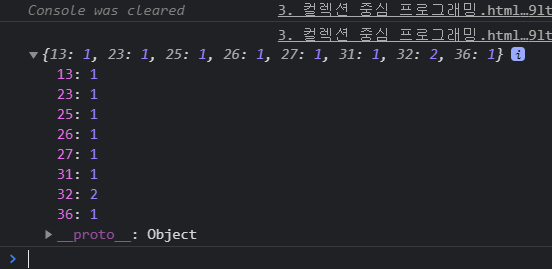
3) count_by, inc
var _count_by = _curryr(function(data, iter) {
return _reduce(data, function (count, val) {
var key = iter(val);
count[key] ? count[key]++ : count[key] = 1;
//key가 있다면 거기에 ++, 없다면 1
return count;
}, {});
});
console.log(_count_by(users, function (user) {
return user.age;
}));
※ increase 함수로 코드 간략화
// 동일한 코드이다.
var _inc = function (count, key) {
//증가시키는 함수
count[key] ? count[key]++ : count[key] = 1;
return count;
}
var _count_by = _curryr(function(data, iter) {
return _reduce(data, function (count, val) {
return _inc(count, iter(val));
}, {});
});
I can be your Genie🧞♀️ How ‘bout Aladdin? 🧞♂️