
정규표현식(RegExp)
정규식, Regular Expression
역할
- 문자 검색 (search)
- 문자 대체 (replace)
- 문자 추출 (extract)
테스트 사이트
정규식 생성
//생성자
new RegExp("표현", "옵션");
new RegExp("[a-z]", "gi") / // 대소문자 구분 x i 플레그
//리터럴
/표현 /옵션
[a - z] / gi;생성자 예시
const str = `
010-1234-5678
youtheyou@naver.com
https://regexr.com/
The quick brown fox the you.
abbccddd
`;
// 검색
const regexp = new RegExp("the", "");
console.log(str.match(regexp));콘솔에 찍어보면 배열을 반환한다.
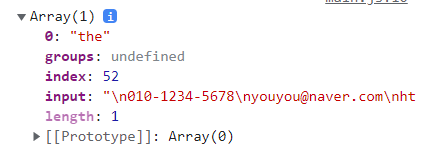
가장 처음 찾아진 the 의 각종 정보를 볼 수 있다.
찾고자 하는 the를 str에서 모두 찾으려면,
플래그(flag)를 사용하면 된다.
const regexp = new RegExp("the", "g");
console.log(str.match(regexp));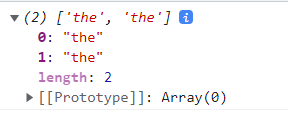
이렇게 g 플래그 옵션을 넣어주면,
해당하는 단어를 모두 배열로 반환한다.
length 를 이용해 갯수를 얻어낼 수도있다.
const regexp = new RegExp("the", "gi");
console.log(str.match(regexp));추가로 대소문자 구문을 하지 않는다는 i 옵션을 넣어주면 대소문자 구분없이 the 라는 문자를 모두 찾아 배열로 반환한다.
이것을 리터럴 방식으로 작성하면
const regexp = /the/gi;
메소드
| 메소드 | 문법 | 설명 |
|---|---|---|
| test | 정규식.test(문자열) | 일치 여부 불리언 반환 |
| match | 정규식.match(문자열) | 일치하는 문자의 배열 반환 |
| replace | 문자열.replace(정규식, 대체문자) | 일치하는 문자를 대체 |
예제
- test
const regexp = /fox/gi;
console.log(regexp.test(str)); // true
const regexp = /mingu/gi;
console.log(regexp.test(str)); // false- replace
const regexp = /fox/gi;
console.log(str.replace(regexp, "apple"));
console.log(str);fox 가 apple 로 대체되어 출력이 되고,
원본데이터는 수정하지 않는다.
원본을 수정하고 싶다면, 재할당이 가능하도록 let 으로 선언 후, str 에 재할당 하면 된다.
let str = `
010-1234-5678
youtheyou@naver.com
https://regexr.com/
The quick brown fox the you.
abbccddd
`;
const regexp = /fox/gi;
console.log(str.replace(regexp, "apple"));
console.log(str);플래그 (옵션)
| 플래그 | 설명 |
|---|---|
| g | 모든 문자 일치 검색 (global) |
| i | 대소문자를 구분 않고 일치 검색 (ignore case) |
| m | 여러 줄 인식 검색 (multi line) |
예제
현재 예제 str 은 줄바꿈이 되어있는 상태
console.log(str.match(/\.$/gim)); // [".","."](백슬래시) 를 이용해 이미 정해진 기능을 벗어나서 . 이 일반적인 문자로 적용될 수 있도록 한다.
(그렇지 않으면, .을 찾으라는 명령으로 인식한다.)
문자열이 끝나는 부분을 나타내는 $ 를 이용해 찾아주고,
m 플래그를 통해 줄바꿈을 인식하고, 찾아서 배열로 반환한다.
패턴 (표현)
^ab : 줄(line) 시작이 ab 로 일치하는 것
ab$ : 줄(line) 끝이 ab 로 일치하는 것
. : 임의의 한 문자와 일치
a|b : a 또는 b와 일치
ab? : b가 없거나 b와 일치
{3} : 3개 연속 일치
{3,} : 3개 이상 연속 일치
{3,5} : 3개 이상 5개 이하 연속 일치
[abc] : a 또는 b 또는 c
[a-z] : a 부터 z 사이의 문자 구간에 일치
[A-Z] : A 부터 Z 사이의 문자 구간에 일치
[0-9] : 0 부터 9 사이의 문지 구간에 일치
[가-힣] : 가 부터 힣 사이의 문자 구간에 일치
\w : 63개 문자에 일치
\b : 63개 문자에 일치하지 않는 문자 경계 (ex. 특수기호)
\d : 숫자에 일치
\s : 공백에 일치
(?=): 앞쪽 일치
(?<=) : 뒤쪽 일치
