5/2 SQL
RANK, DENSE_RANK, ROW_NUMBER : 데이터 값에 순위 매기기
RANK, DENSE_RANK, ROW_NUMBER는 데이터 값에 순위를 매기는 함수입니다.
순위를 매기는 것은 동일하지만 사용법이 조금씩 다릅니다.
즉, 공통 순위가 있을 때 출력을 어떻게 하느냐에 따라 용도가 달라집니다. 차이는 다음과 같습니다.
표 4-13 순위 함수의 출력 방법 차이
| 함수 | 설명 | 순위 예 |
|---|---|---|
| RANK | 공통 순위를 출력하되 공통 순위만큼 건너뛰어 다음 순위를 출력한다. | 1, 2, 2, 4, … |
| DENSE_RANK | 공통 순위를 출력하되 건너뛰지 않고 바로 다음 순위를 출력한다. | 1, 2, 2, 3, … |
| ROW_NUMBER | 공통 순위를 없이 출력한다. | 1, 2, 3, 4, … |
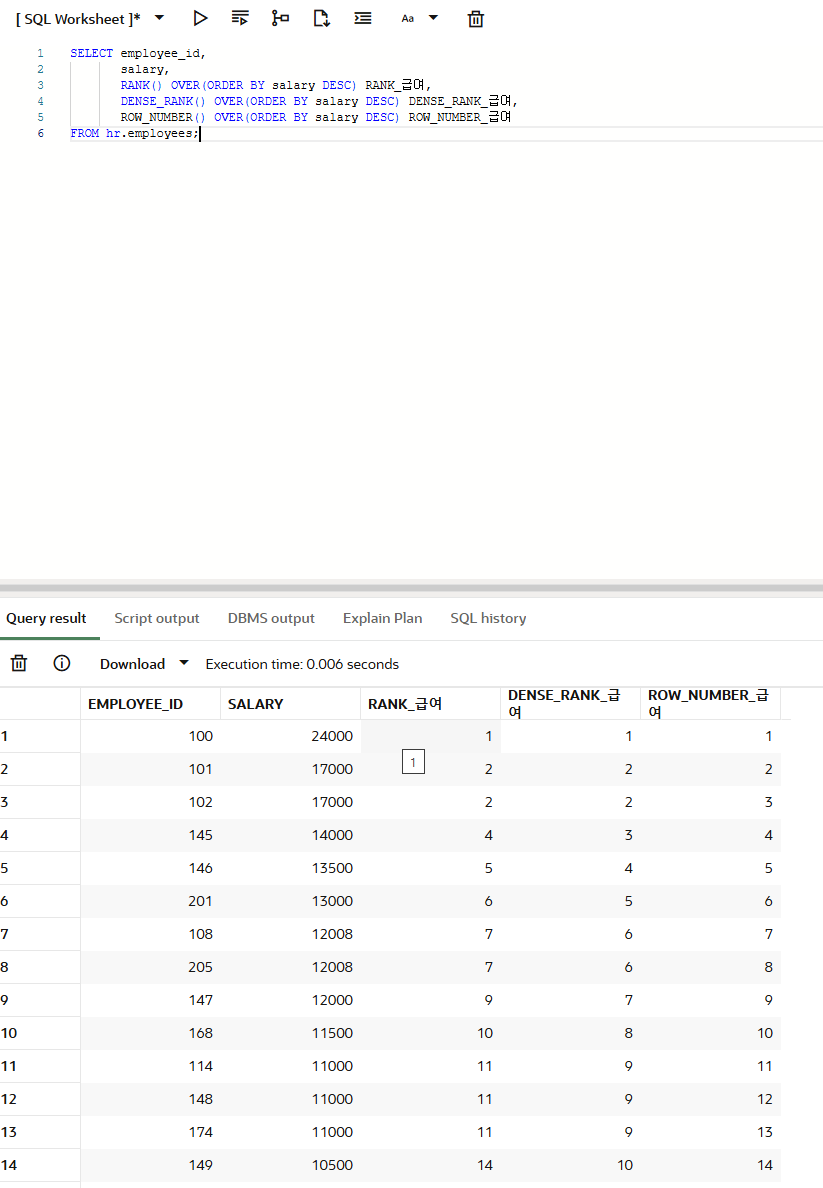
SELECT employee_id,
salary,
RANK() OVER(ORDER BY salary DESC) RANK_급여,
DENSE_RANK() OVER(ORDER BY salary DESC) DENSE_RANK_급여,
ROW_NUMBER() OVER(ORDER BY salary DESC) ROW_NUMBER_급여
FROM hr.employees;RANK : 공통 순위를 출력하되 공통 순위만큼 건너뛰어 다음 순위를 출력한다.
DENSE_RANK: 공통 순위를 출력하되 건너뛰지 않고 바로 다음 순위를 출력한다.
ROW_NUMBER: 공통 순위를 없이 출력한다.
순위 함수 안에 ORDER BY salary DESC 절을 이용해서 salary 값이 높은 순(내림차순)으로 정렬하고 순위를 매겼습니다.
순위 함수 안에 ORDER BY salary DESC 절을 이용해서 salary 값이 높은 순(내림차순)으로 정렬하고 순위를 매겼습니다.
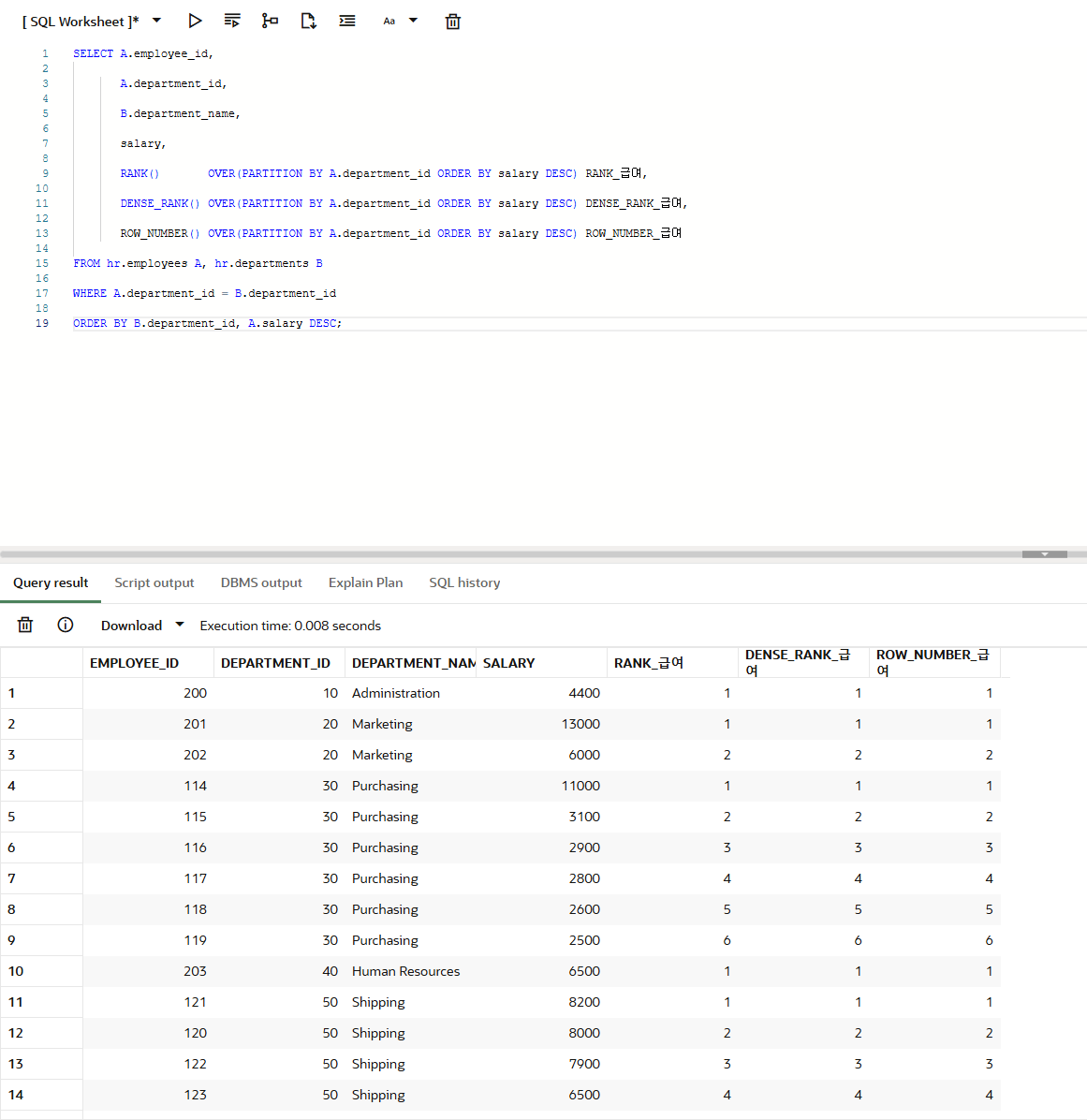
SELECT A.employee_id,
A.department_id,
B.department_name,
salary,
RANK() OVER(PARTITION BY A.department_id ORDER BY salary DESC) RANK_급여,
DENSE_RANK() OVER(PARTITION BY A.department_id ORDER BY salary DESC) DENSE_RANK_급여,
ROW_NUMBER() OVER(PARTITION BY A.department_id ORDER BY salary DESC) ROW_NUMBER_급여
FROM hr.employees A, hr.departments B
WHERE A.department_id = B.department_id
ORDER BY B.department_id, A.salary DESC;이번에는 전체가 아닌 PARTITION BY 절을 사용해 department_id, 즉 부서별로 그룹화한 후 salary 값이 높은 순(내림차순)으로 순
위를 매겼습니다.
그룹 함수 : 그룹으로 요약하기
그룹 함수는 단일 행 함수와 달리 여러 행에 대해 함수가 적용되어 하나의 결과를 나타내는 함수입니다.
집계함수라고 부르기도함.
(그룹함수 == 집계함수)
그룹 함수의 종류와 사용법
그룹 함수는 다음과 같은 기본 문법을 사용합니다. 굵게 표시된 부분이 필수 기본 문법입니다. 하나의 열 이름을 지정하면 하나의 결괏값을 출력합니다.
SELECT 그룹 함수(열 이름)
FROM 테이블 이름
[WHERE 조건식]
[ORDER BY 열 이름];
표 4-14 그룹 함수의 종류
| 함수 | 설명 | 예 | null 처리 |
|---|---|---|---|
| COUNT | 행 개수를 셈 | COUNT(salary) | (*)의 경우 null 값도 개수로 셈 |
| SUM | 합계 | SUM(salary) | null 값을 제외하고 연산 |
| AVG | 평균 | AVG(salary) | null 값을 제외하고 연산 |
| MAX | 최댓값 | MAX(salary) | null 값을 제외하고 연산 |
| MIN | 최솟값 | MIN(salary) | null 값을 제외하고 연산 |
| STDDEV | 표준편차 | STDDEV(salary) | null 값을 제외하고 연산 |
| VARIANCE | 분산 | VARIANCE(salary) | null 값을 제외하고 연산 |
COUNT 함수
COUNT는 지정한 열의 행 개수를 세는 함수입니다.
SELECT count(salary) salary행수
from hr.employees;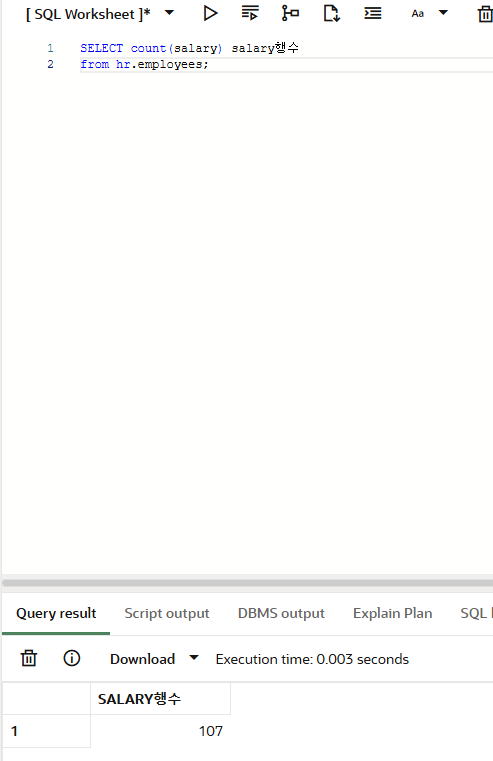
SUM, AVG 함수
SUM은 열의 합계를 구하는 함수고 AVG는 열의 평균을 구하는 함수입니다. 또한 그룹 함수의 결괏값끼리 계산할 수 있습니다.
SELECT sum(salary) 합계, avg(salary)평균, sum(salary)/count(salary) 계산된평균
from hr.employees;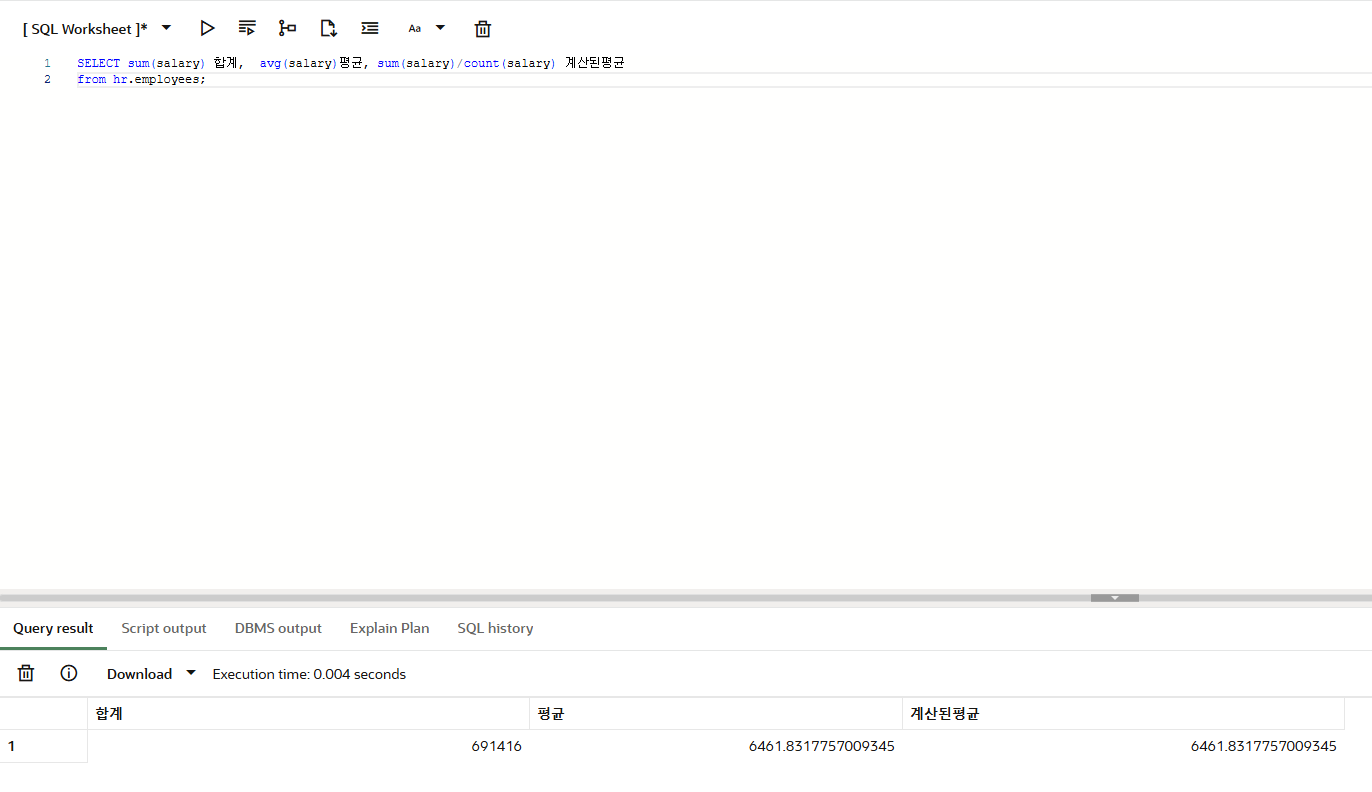
MAX, MIN 함수
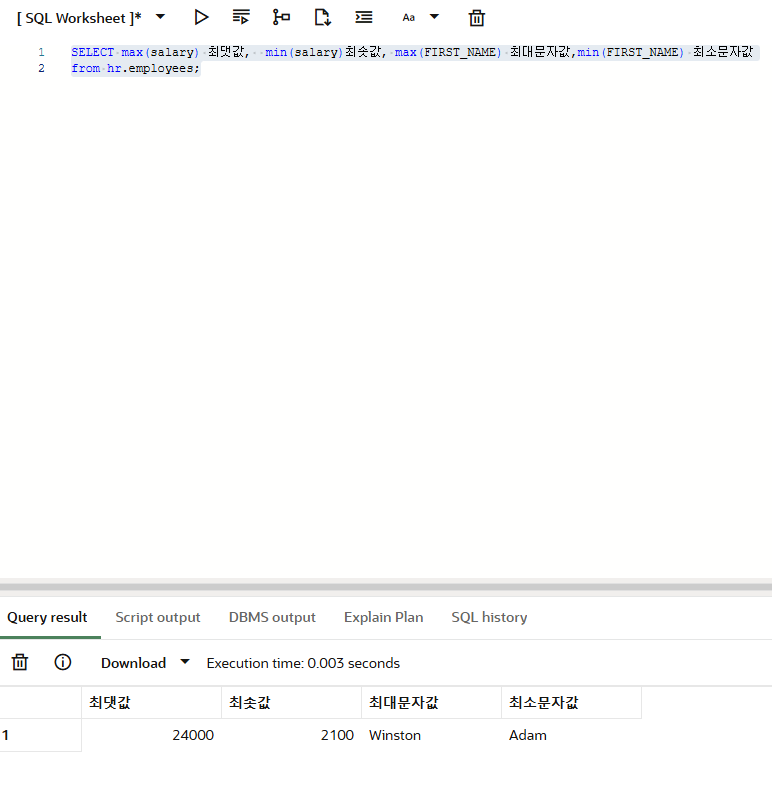
MAX는 최댓값을 출력하는 함수고 MIN은 최솟값을 출력하는 함수입니다. 모든 데이터 타입에 대해 MAX 함수와 MIN 함수를 사용할 수 있습니다.
문자 데이터 타입이나 날짜 데이터 타입과 같이 숫자가 아닌 값에 MAX 함수나 MIN 함수를 적용하면 -> 높고 낮은 순(알파벳순, 날짜순 등)에 대해 연산하여 결과가 출력됨.
SELECT max(salary) 최댓값, min(salary)최솟값, max(FIRST_NAME) 최대문자값,min(FIRST_NAME) 최소문자값
from hr.employees;