5/7 sql 2,3교시
GROUP BY : 그룹으로 묶기
지금까지 배운 그룹 함수는 하나의 열을 그룹화하여 함수를 적용했음
특정 열의 데이터 값을 기준으로 그룹화하여 다른 열에 그룹 함수를 적용해야 한다면?
SQL에서는 같은 데이터 값을 갖는 행끼리 묶어서 그룹화한 다음, 그에 해당하는 다른 열의 데이터 집합을 그룹 함수에 전달하여 연산할 수 있음 -> 이런 경우 GROUP BY 절 사용
GROUP BY 절은 기준 열을 지정하여 그룹화하는 명령어
SELECT 절에 열 이름과 그룹 함수를 함께 기술했다면 GROUP BY 절을 반드시 사용해야함
그룹화는 열 이름이 기술된 순서대로 수행됨
논리 순서
SELECT 열 이름, 그룹 함수(열 이름) ----➍
FROM 테이블 이름 ----➊
[WHERE 조건식] ----➋
GROUP BY 열 이름 ----➌
[ORDER BY 열 이름]; ----❺
➊ 테이블에 접근합니다.
➋ WHERE 조건식에 맞는 데이터 값만 골라냅니다.
➌ 기술된 기준 열을 기준으로 같은 데이터 값끼리 그룹화합니다.
➍ 결과를 출력합니다.
➎ 오름차순(기본, ASC) 혹은 내림차순(DESC)으로 정렬합니다.
GROUP BY 절의 특징
-
SELECT 절에 기준 열과 그룹 함수가 같이 지정되면 GROUP BY 절에 기준 열 이름이 반드시 기술되어야 합니다(SELECT 절에 그룹 함수만 기술되고 열 이름이 기술되지 않으면 GROUP BY 절을 반드시 기술할 필요는 없음).
-
WHERE 절을 사용하면 행을 그룹으로 묶기 전에 앞서 조건식이 적용됩니다.
-
SELECT 절에 그룹 함수를 사용하지 않아도 GROUP BY 절만으로도 사용할 수 있습니다.
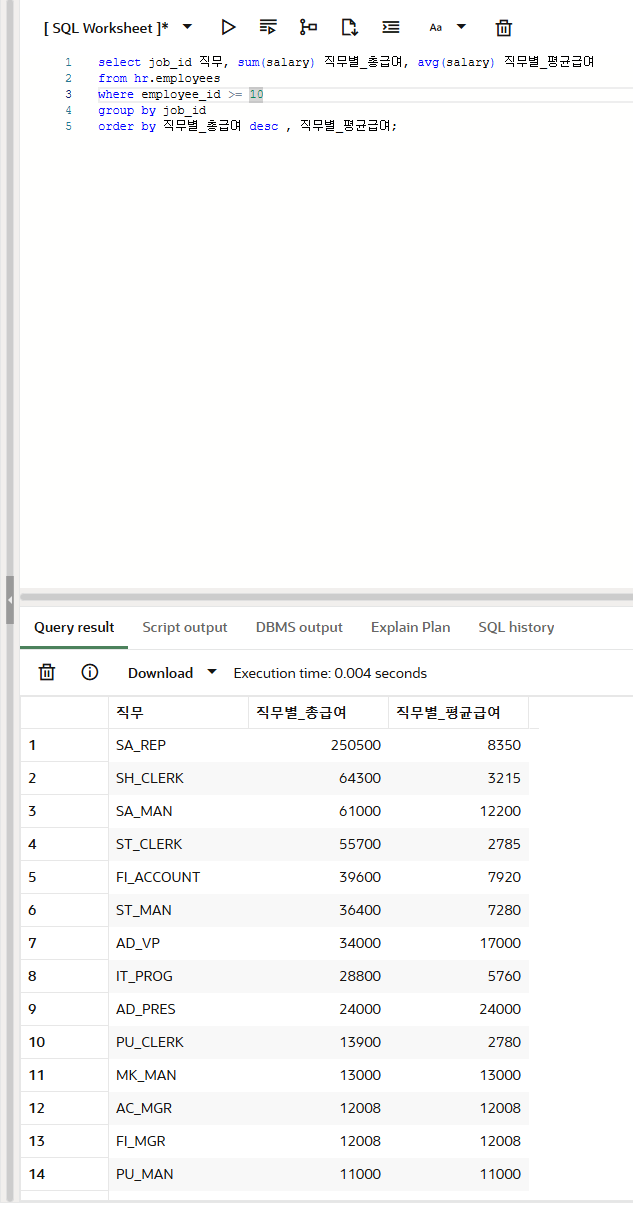
select job_id 직무, sum(salary) 직무별_총급여, avg(salary) 직무별_평균급여
from hr.employees
where employee_id >= 10
group by job_id
order by 직무별_총급여 desc , 직무별_평균급여;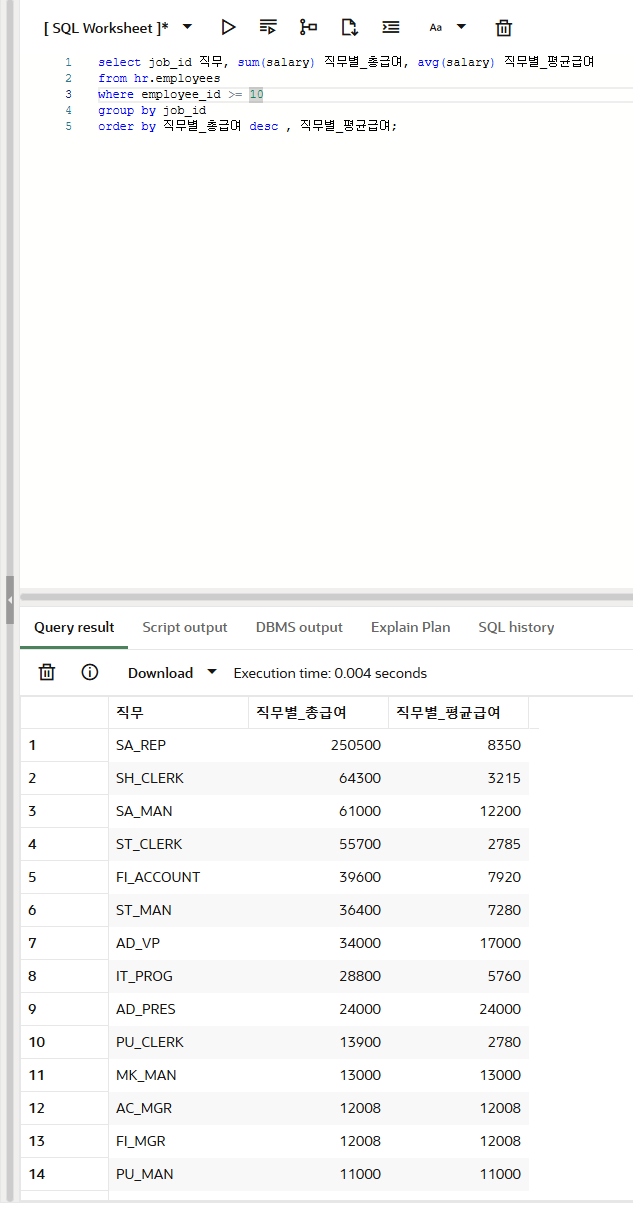
select job_id job_id_대그룹,
manager_id manager_id_중그룹,
sum(salary) 그룹핑_총급여,
avg(salary) 그룹핑_평균급여
from hr.employees
where employee_id >= 10
group by job_id,manager_id
order by 그룹핑_총급여 desc , 그룹핑_평균급여;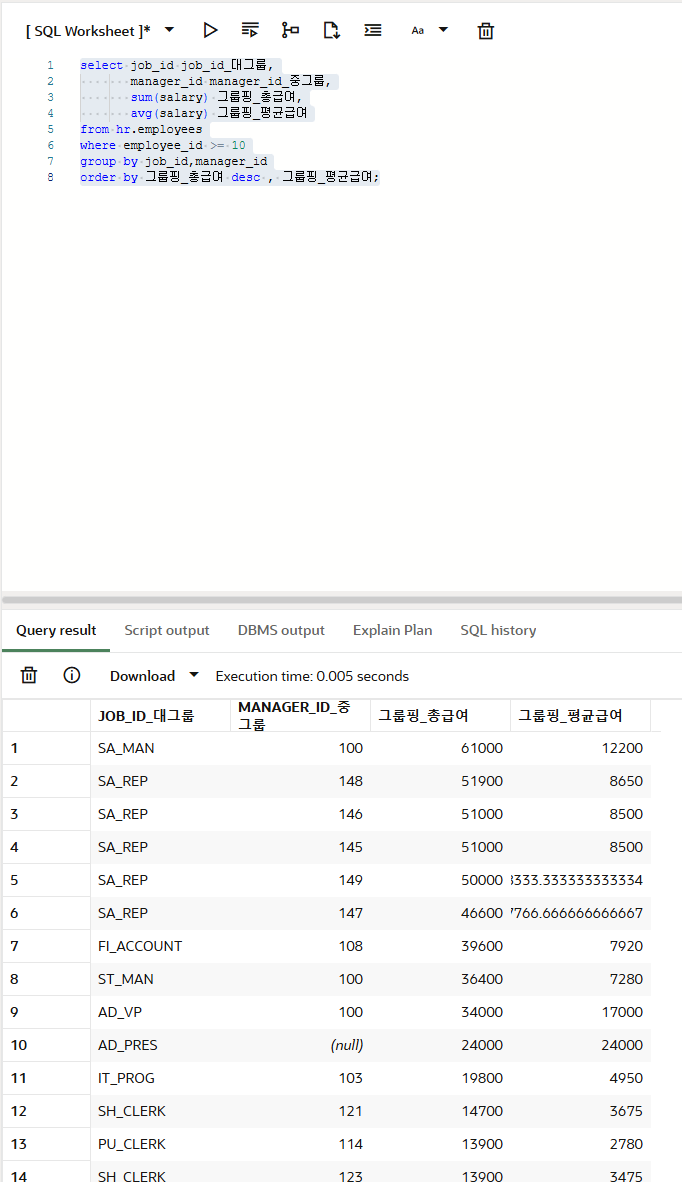
HAVING : 연산된 그룹 함수 결과에 조건 적용하기
HAVING 절은 그룹화된 값에 조건식을 적용할 때 사용합니다. 즉, WHERE 절에서는 그룹 함수를 사용할 수 없으므로 HAVING 절을 사용해 그룹 함수의 결괏값에 대해 조건식을 적용합니다.
일반적으로 HAVING 절은 GROUP BY 절 다음에 기술하는 것이 논리적이고 가독성도 좋다.
SELECT 열 이름, 그룹 함수(열 이름) ----❺
FROM 테이블 이름 ----➊
[WHERE 조건식] ----➋
GROUP BY 열 이름 ----➌
[HAVING 조건식] ----➍
[ORDER BY 열 이름]; ----➏
➊ 테이블에 접근합니다.
➋ WHERE 조건식에 맞는 데이터 값만 골라냅니다.
➌ 기술된 기준 열을 기준으로 같은 데이터 값끼리 그룹화합니다.
➍ 그룹화된 값에 대해 조건식을 적용합니다.
❺ 결과를 출력합니다.
➏ 오름차순(기본, ASC) 혹은 내림차순(DESC)으로 정렬합니다.
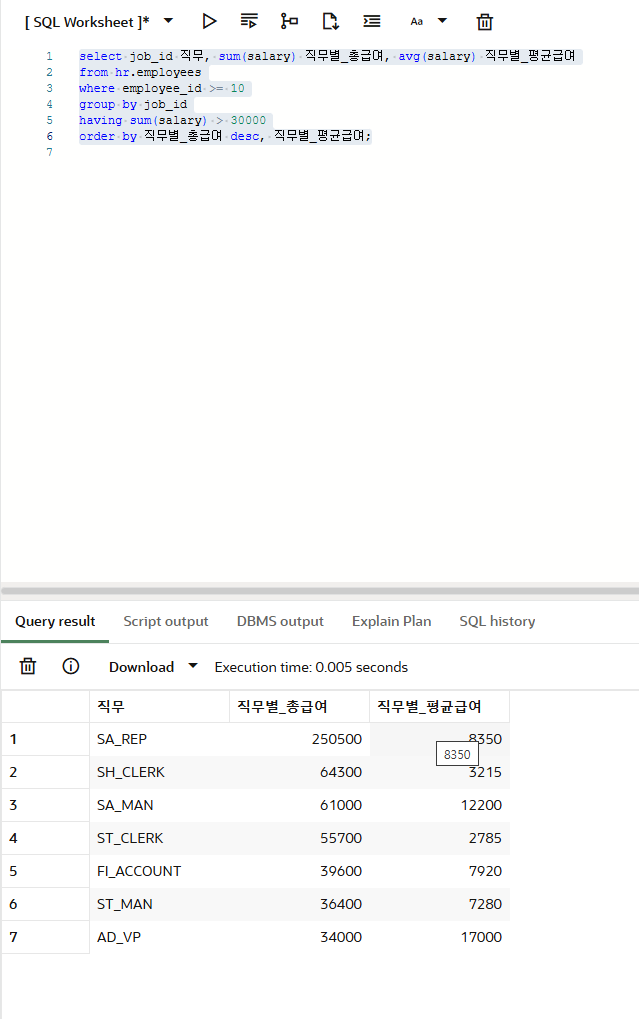
select job_id 직무, sum(salary) 직무별_총급여, avg(salary) 직무별_평균급여
from hr.employees
where employee_id >= 10
group by job_id
having sum(salary) > 30000
order by 직무별_총급여 desc, 직무별_평균급여;
ERD: 데이터베이스 개체 설계도
ERD(Entity Relationship Diagram)는
개체(테이블) 간의 관계를 이해하기 쉽게 그림으로 표현한 것으로 데이터를 조작하고 분석하는 기초 자료로 활용됩니다. = 데이터베이스의 설계도면
ERD를 해석할 수 있다면
테이블 간의 연관성과 관계의 전체적인 모습을 파악하고 데이터의 흐름과 프로세스를 확인하여 데이터를 효율적으로 조작하고 분석할 수 있음
1. 행 : 특정 employee(직원)에 대한 모든 데이터를 나타내는 단일 행(row,로우)입니다. employee_id 값에 의해 유일하게 식별됩니다.
2. 기본 키(primary key): employee_id 열은 employee_id 데이터 값들로 구성되어있습니다. employee_id 열은 유일하게 데이터를 구분한다고 해서 기본키 또는 주 키라고 부릅니다. 기본키는 데이터를 식별하는 '식별자' 역할을 합니다. 기본키는 중복값을 가질수없고(unique), null 값을 가질 수 없으며 변경 될 수도 없습니다. = 주민등록 번호와 같은 개념
3. 키값이 아닌 일반 열 입니다. phone_number, hire_date,salary, commission_pct 열도 일반열에 속합니다.
4. 고유 키(unique key): 행에서 유일한 값을 갖는 데이터 값으로 구성된 열입니다. 중복값이 없는 유일한 값을 갖지만 기본키가 아닌 데이터 값이 존재합니다. 유니크 값 또는 유니크 키라고 부르기도 합니다.
5. 외래 키(foreign key): job_id, department_id, manager_id 열은 테이블 간에 서로 연결 관계를 정의하는 외래 키 입니다. 외래키는 참조 테이블의 기본키 또는 고유 키를 참조 합니다. 테이블의 구성열이자 다른 테이블과 연결을 위한 열입니다.
표 5-1 제약 조건의 종류
| 제약 조건 | 내용 |
|---|---|
| 기본 키(primary key) | UNIQUE + NOT NULL을 만족하며 테이블을 대표하며 각 행을 유일하게 식별하는 값 |
| 외래 키(foreign key) | 열 값이 부모 테이블의 참조 열 값을 반드시 참조하며, 참조되는 열은 유니크(unique)하거나 기본 키(primary key)임(null 허용 가능) |
| 고유 키(unique key) | 중복된 값을 허용하지 않음, 유일한 값으로 존재(null 허용 가능) |
| NOT NULL | null 값을 허용하지 않음, 값 입력 필수 |
| CHECK | 범위나 조건을 설정하여 지정된 값만 허용 |
관계 : 개체 관계 표기법
ERD = ER 다이어그램
E = 개체(entity)
R = 관계(relation)
개체는 정보를 저장하고 관리하기위한 집합이자 식별가능한것
ERD는 개체가 담고 있는 내용과 이들간의 관계를 표현하는 수단
➊ 사각형으로 표현된 것은 개체(테이블)입니다. 테이블의 이름과 어떤 속성(열)을 가지고 있는지 표현합니다.
➋ 개체 간에는 관계(relation)가 있는데, 이러한 관계는 점선이나 실선으로 표현된 화살표 모양 선으로 나타냅니다. 관계를 표현하는 방법에는 Barker, Chen, UML, IE 등이 있고, 이러한 표기법을 이용하여 관계를 다이어그램으로 쉽게 표현할 수 있습니다. 이 책에서는 Oracle SQL Developer에서 기본으로 쓰이는 관계형 모델 다이어그램을 기준으로 설명하겠습니다.
먼저 ERD를 통해 관계 차수(카디널리티, cardinality)와 관계 선택 사양(optionality)을 표현할 수 있습니다. 관계 차수는 1:1, 1:N, M:N 등 하나의 개체에 몇 개의 개체가 대응되는지를 표현하는 것을 말합니다. 관계 선택 사양은 관계가 필수인지 아닌지(없을 수도 있을지)를 표현하는 것을 말합니다. 화살표 방향은 어느 쪽에 속하는지를 나타냅니다.
그림 5-8 ERD 도식의 의미
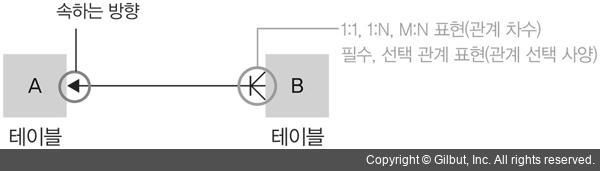
먼저 관계 차수 도식의 의미는 다음과 같습니다.
그림 5-9 관계 차수 도식(정보 공학 표기법 기준)
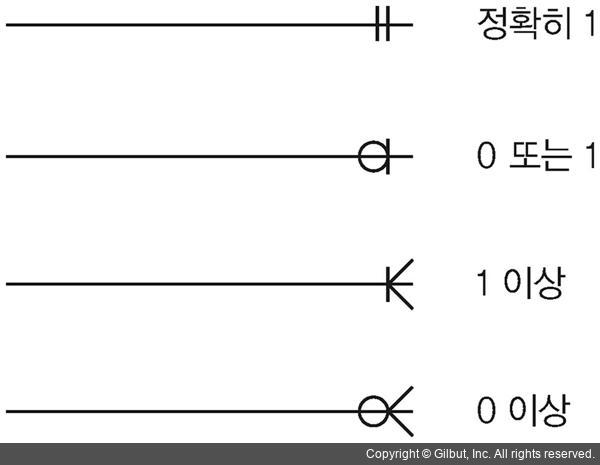
-
1 : 관계를 맺는 개체와 하나의 관계를 갖습니다.
-
0 또는 1 : 관계를 맺는 개체와 0이거나 1의 관계를 갖습니다.
-
1 이상 : 관계를 맺는 개체와 1이거나 여러 개의 관계를 갖습니다.
-
0 이상 : 관계를 맺는 개체와 0이거나 여러 개의 관계를 갖습니다
관계 선택 사양 도식의 의미는 다음과 같습니다.
그림 5-9 관계 선택 사양
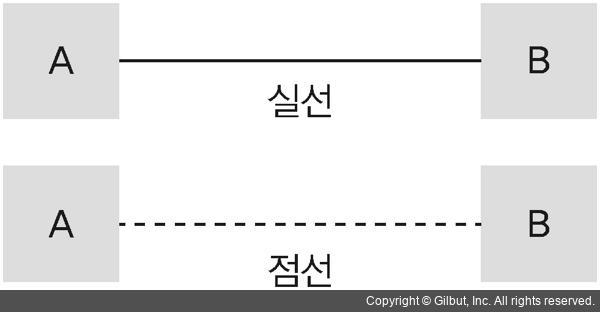
-
실선 : 필수 관계, 즉 A와 B가 필수 관계일 때 사용합니다. 예로 B가 존재하려면 A가 반드시 존재해야 합니다.
-
점선 : 선택적 관계, 즉 A와 B가 선택적 관계일 때 사용합니다. 예로 B는 A가 없어도 존재할 수 있습니다.
SELECT A.first_name, A.last_name, B.*
from hr.employees A ,hr.job_history B
where A.employee_id = B.employee_id
and A.employee_id = 101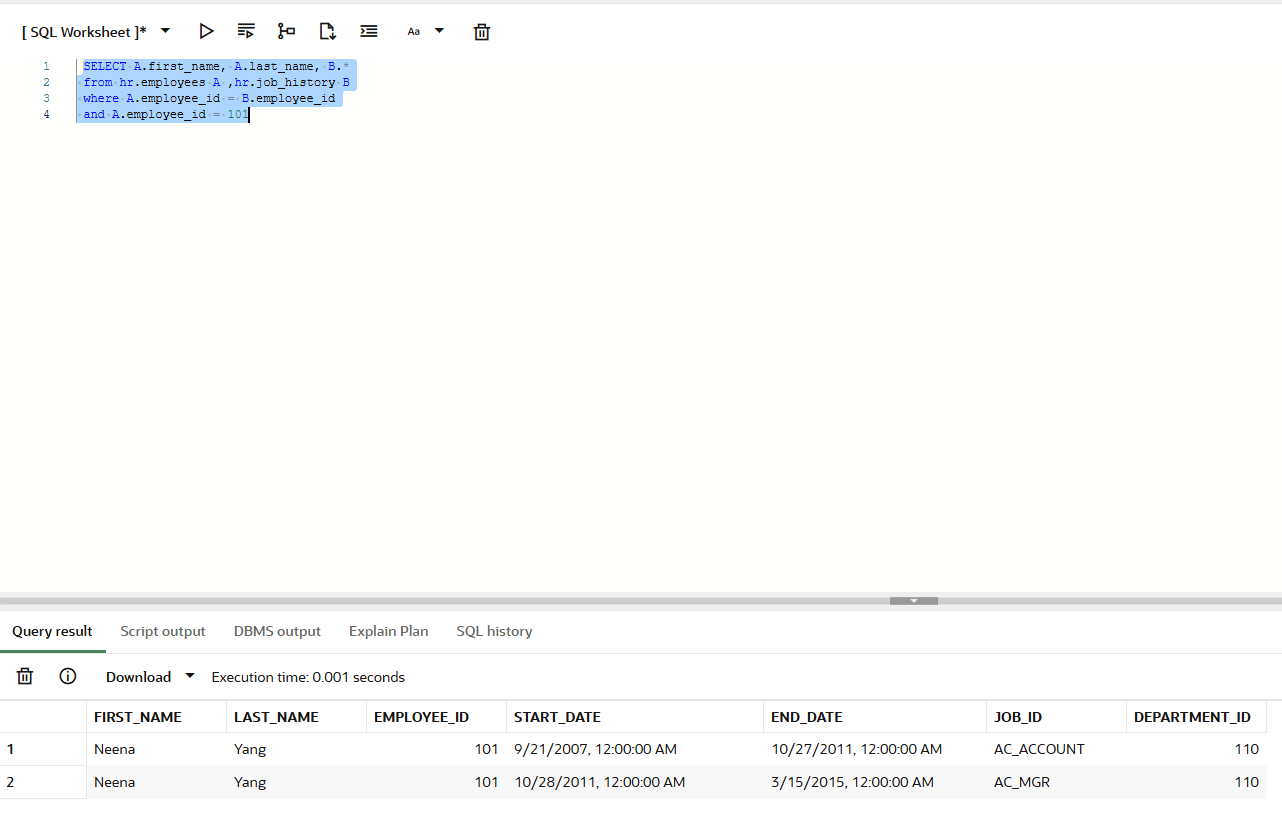

‘regions는 여러 개의 countries를 가질 수 있다.’, ‘countries는 여러 개의 locations를 가질 수 있다.’, ‘countries는 regions_id가 없어도 존재할 수 있고, locations 역시 countries_id가 없어도 존재할 수 있다’는 의미입니다.
이처럼 정보의 덩어리인 개체와 개체 간의 논리적인 관계를 그림으로 표현한 것이 ERD이다.
데이터베이스 설계자는 현실 세계에서 일어날 수 있는 다양한 현상을 데이터베이스로 구현하고 ERD로 표현할 수 있고, 사용자는 ERD를 해독하여 설계된 데이터베이스의 논리를 알 수 있습니다.
