Introduction
U-Net 기반으로 Generation을 하거나, 여타 방법을 활용해서 Non-Autoregressive하게 upsampling을 해야 할 때 Conventional하게 사용하는 방법에는 Transposed Convolution (DeConvolution)이나 Interpolation 등이 있다. Transposed Convolution은Parallel Computing에 유리하고, Channel size를 내재적으로 조절할 수 있기에 잘 사용하지만 Checkerboard Artifacts를 피할 수 없다. 
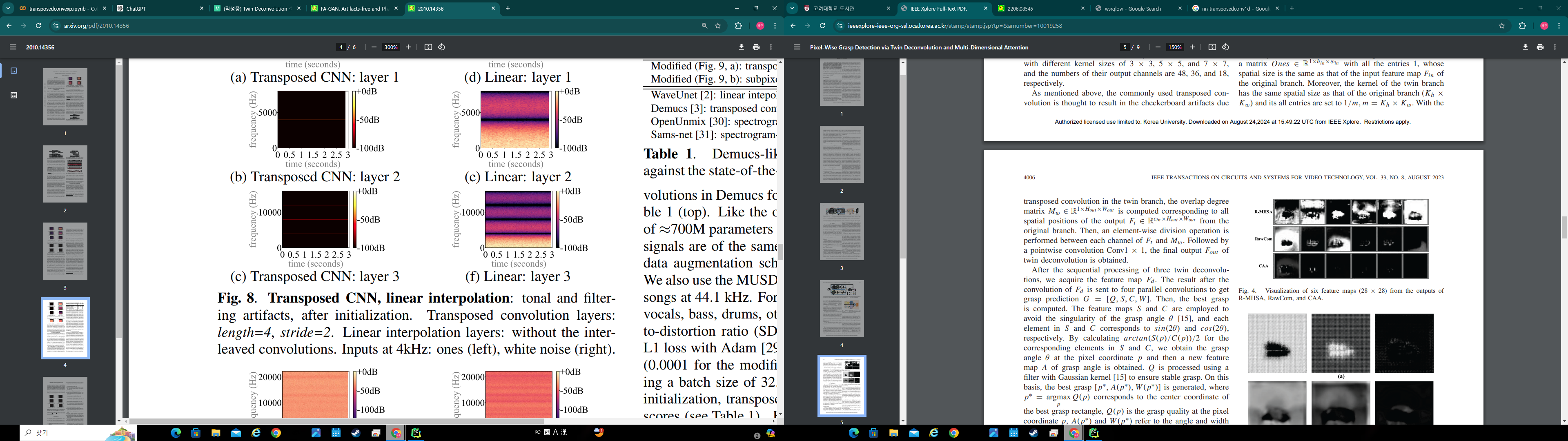
위 그림은 UPSAMPLING ARTIFACTS IN NEURAL AUDIO SYNTHESIS(Pons et al., ICASSP, 2021) 에 나오는 그림으로 Transposed Convolution이 어떻게 checkerboard artifacts를 만드는지 표현하고 있다. Deconvolution 하기 위해 Input Feature maps 에서 매번 anchor를 설정할 때, 해당 anchor의 위치가 바깥쪽인지 안쪽인지에 따라서 Convolution 연산에 이용되는 참조 횟수가 다르기 때문에 벌어지는 일이다.
Interpolation은 좋고 parameter-free라 빠르지만 내재적으로 channel upsampling을 수행할 수 없다는 점에서 실용성이 낮다.
최근 Vision 분야에서는 Sub-pixel convolution 등의 방식으로 이를 대체하는 경우도 많이 있으나, Sub-pixel convolution 역시 checkerboard artifacts에 robust하지 못하다.
따라서 오늘은 Pixel-Wise Grasp Detection via Twin Deconvolution and Multi-Dimensional Attention (Ren et al., 2023, TCSVT) 에서 소개된 Twin Deconvolution이 어떻게 이 문제를 해결하는지 설명하고 1D 차원으로 전용해서 코드 구현 해 보겠다 (1D로 하는 것은 내 domain은 오디오이기 때문이다.)
Twin-Deconvolution
아이디어는 꽤나 간단하다. Transposed Convolution을 수행할 때 Input feature map에 존재하는 각 pixel이 참조된 횟수가 달라도 같은 정도의 크기를 유지할 수 있게끔 참조된 횟수가 적으면 가중치를 크게 부여해 value를 키워주고, 참조된 횟수가 많으면 가중치를 적게 부여해 value를 낮춰주는 것이다.
이를 위해서 기존의 Transposed Convolution은 그대로 사용하고, 가중치 계산을 위해 추가로 Twin-deconvolution 모듈을 고안한다.
import torch.nn as mm
from torch.nn import ConvTranspose1d
import torch
tdconv1 = ConvTranspose1d(1, 24, kernel_size = 8, stride = 2, padding = 3)
tdconv2 = ConvTranspose1d(1, 24, kernel_size = 8, stride = 2, padding = 3)
#tdconv2가 twin deconvolution module이후 twin deconv module은 가중치를 1/8, 즉 kernel size의 역수로 설정해 준다.
uniform_value = 1 / 8 #kernel size의 역수
with torch.no_grad():
tdconv2.weight.fill_(uniform_value)만일, x가 입력 데이터라고 했을 때, 그냥 transposed convolution에 넣었다고 생각해 보자.
x = torch.abs(torch.rand([32, 1, 25600])) # [B, C, L]
vanilla_result = tdconv1(x)
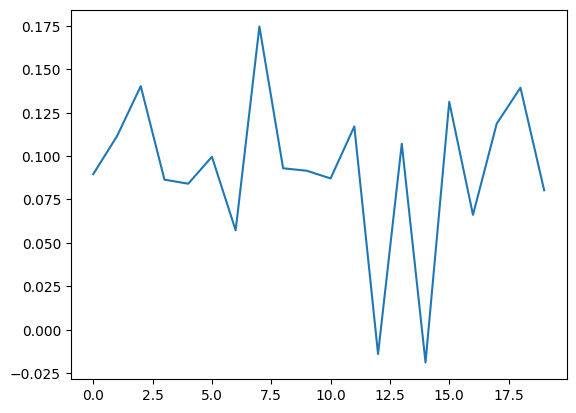
plt.plot(vanilla_result[0, 0, :20].detach().numpy())1채널의 값만 임시로 출력해 보았는데, 그림에서 초반 인덱스의 부분은 참조를 덜 하게 된다. 이를 해결하기 위한 것이 twin deconvolution이다.
ones = torch.ones([1, 1, 25600])
values = tdconv2(ones)
import matplotlib.pyplot as plt
import numpy as np
array_1d = values.squeeze(0)[0].detach().numpy()
plt.plot(array_1d)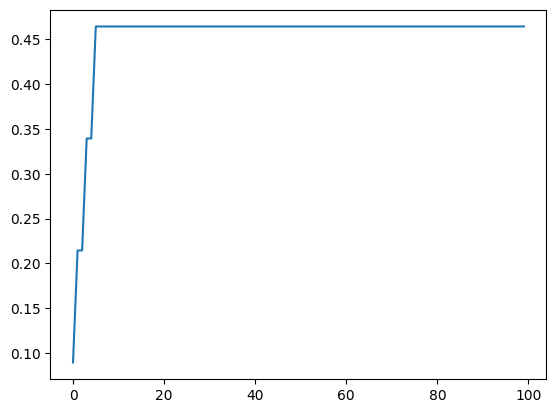
아까 이야기했듯이, ones로 이루어진 값들을 twin deconvolution에 넣고 앞부분 출력만 확인하면 다음과 같다. twin deconv의 결과로 나온 벡터를 확인하면 이렇게 생겼다. 중심부에서 먼 인덱스의 값일수록 가중치가 커지는 것을 확인할 수 있다.
이제 마지막으로 main module에서 twin deconv module의 값을 나눠줄 것이다.
result = (vanilla_result/values)
plt.plot(result[0, 0, :10].detach().numpy())
이렇게 하면 참조가 덜 된 부분에 가중치를 더 두어 amplitude 자체를 크게 만들고, 반대로 참조가 많이 된 부분에 가중치를 덜 두는 방식을 이용하게 된다. 이 개념을 활용하면 Upsampling의 연속성을 더 두어 모델링에 이용할 수 있게 된다.
class twinupsampling(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, upsample_rates, padding):
super(twinupsampling, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.upsample_rates = upsample_rates
self.padding = padding
self.tdconv1 = ConvTranspose1d(self.in_channels, self.out_channels,
kernel_size=self.kernel_size, stride = self.upsample_rates, padding = self.padding)
self.tdconv2 = ConvTranspose1d(self.in_channels, self.out_channels,
kernel_size=self.kernel_size, stride = self.upsample_rates, padding = self.padding, bias = False)
self.pointwiseconv = Conv1d(self.out_channels, self.out_channels, kernel_size = 1, stride = 1, padding = 0)
uniform_value = float(1/self.kernel_size) + 1e-12
with torch.no_grad():
self.tdconv2.weight.fill_(uniform_value)
for param in self.tdconv2.parameters(): # Weight Freezing
param.requires_grad = False
def get_device(self):
# Check the device of the first parameter
return next(self.parameters()).device
def forward(self, x):
# [B, C, L]
device = self.get_device()
ones = torch.ones(x.size()).to(device)
x = self.tdconv1(x)
weights = self.tdconv2(ones)
x = x / weights
x = self.pointwiseconv(x)
return x최종 코드이다.
