※ 이클립스에서 프로젝트명 바꿔줄 때 할 것
C:\Users\bitcamp\git\bitcamp-Study\java-lang-boot\settings.gradle
C:\Users\bitcamp\git\bitcamp-Study\java-lang-boot\app\build.gradle
위 2개의 파일에서 프로젝트명을 변경해 준 후, $ gradle eclipse 명령어 사용한다.
(1) 문자 리터럴
- ex)
@RestController
@RequestMapping("/lang/literal/exam5")
public class Exam5 {
@GetMapping("/test1")
public String test1() {
return "문자1: " + 'A' + '가';
//문자1: A가
}
@GetMapping("/test2")
public String test2() {
return "문자2: " + '\u0041' + '\uac00';
// 문자에 대한 유니코드 값 지정해도 됨
// 문자2: A가
}
@GetMapping("/test3")
public String test3() {
return "문자3: " + (char)0x41 + "," + (char)0xac00;
// 문자 코드를 정수값으로 지정한다. 대신 문자 코드임을 표시해야 한다.
// 문자3: A,가
}
@GetMapping("/test4")
public String test4() {
return "문자4: " + (char)65 + "," + (char)44032;
// 문자 코드값은 그냥 정수값이다
// 문자4: A,가
}
}- 이때 'A' 대신 쓰인 '\u0041', 0041등은 문자에 대해 지정한 번호인 문자코드라고 한다.
(2) 값을 메모리에 저장하기 위해 2진수화 시키는 규칙
1) 정수
- 절대부호
- 1의 보수
- 2의 보수
- Excess-K
2) 부동소수점
- IEEE-754
3) 문자
- unicode (UTF-16BE = ucs2) : 자바 기본 규칙 (국제 표준)
- UTF-8 : 유니코드 변형규칙 (국제 표준)
- MS949(CP949) : MS 윈도우에서 사용하는 규칙 (비표준)
- EUC-KR(KSC5601) 예전 국가 표준 한글 규칙(국제 표준)
- 조합형 : HWP 규칙 (비표준)
- ISO 8859-1 (영어권 표준 규칙)
- ASCII (미국 규칙)
(3) 문자의 2진수화 규칙
- character set (문자집합) : 문자에 번호를 부여한 테이블을 말하고, 각각은 '문자 코드'의 형태로 저장된다.
1) ASCII (American Standard Code for Information Interchange)
- 7비트 크기의 번호를 부여한다.
2) ISO-8859-1 (ISO-latin-1) (8비트 크기의 번호를 부여),
- ASCII에 유럽권 문자들을 추가한 규칙이다.
- 영어의 경우 보통 이 규칙을 사용한다.
3) EUC-KR (16비트 크기의 번호를 부여)
- ISO-8859-1에 한글 문자 규칙을 추가한 방식이다.
- 한글 2350자 대해서만 번호가 부여된다.
4) 조합형
- EUC-KR에 비해 부족한 한글이 대거 추가된 규칙이다.
- 16비트 크기의 번호를 부여하며, 초성, 중성, 종성 각 5비트로 번호가 부여된다.
5) MS949(CP949)
- EUC-KR에 문자들이 추가된 방식이다.
- MS 윈도우즈에서 추가한 규칙이다.
- 16비트 크기의 번호를 부여한다.
- 11172자의 한글 음절에 대해 번호가 부여된다.
- 표준 규칙이 아니라 유닉스, 리눅스등서 사용이 불가하다.
6) UNICODE(UCS2=UTF-16)
- 16비트 크기의 번호를 부여한다.
- 국제표준규칙으로 한글에 대해 번호를 다시 붙힌다.
- 영어도 16비트 크기의 번호를 부여한다.
- JVM은 이 규칙을 사용한다.
7) UTF-8 (유니코드 변형 포맷)
- 1~4 바이트 크기의 번호를 부여한다.
- 영어는 1바이트를 사용한다.
- 한글은 2바이트서 3바이트로 변경 및 재정의된다.
- 현엽, 일반 프로그램에서 많이 사용된다.
(4) ASCII character set
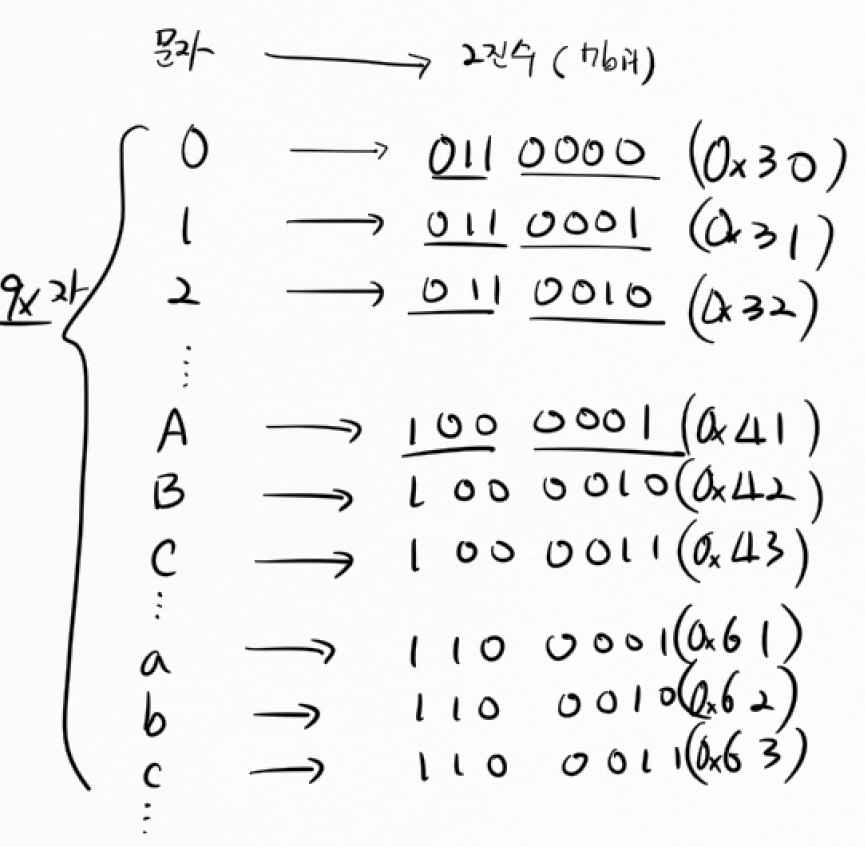
-
'A'라는 문자를 저장할때도, 출력할때도 무조건 같은 규칙을 따라야 한다.
-
7비트는 0 ~ 127의 최대 128자가 저장이 가능하다. 이중에서 95개의 공백을 포함한 출력 가능 문자와 (영어 대소문자(52), 아라비아 숫자(10), 특수문자(32), 공백(1)) 33개의 출력 불가능 제어 문자로 이루어진다.
(5) iso-8859-1
-
우리나라도 영어엔 이 방식을 사용한다.
-
영어 프랑스어 이탈리아어 등 8bit로 이루어진다.(256자)
-
ASCII 128자 + 프랑스어등 128자 => 256자
-
한글 음절에 대한 규칙이 없다.

(6) EUC-KR
-
iso-8859-1 에 한글음절 2350자가 포함된 규칙이다. (2byte)
-
국제표준이어서 리눅스나 유닉스를 지원한다.
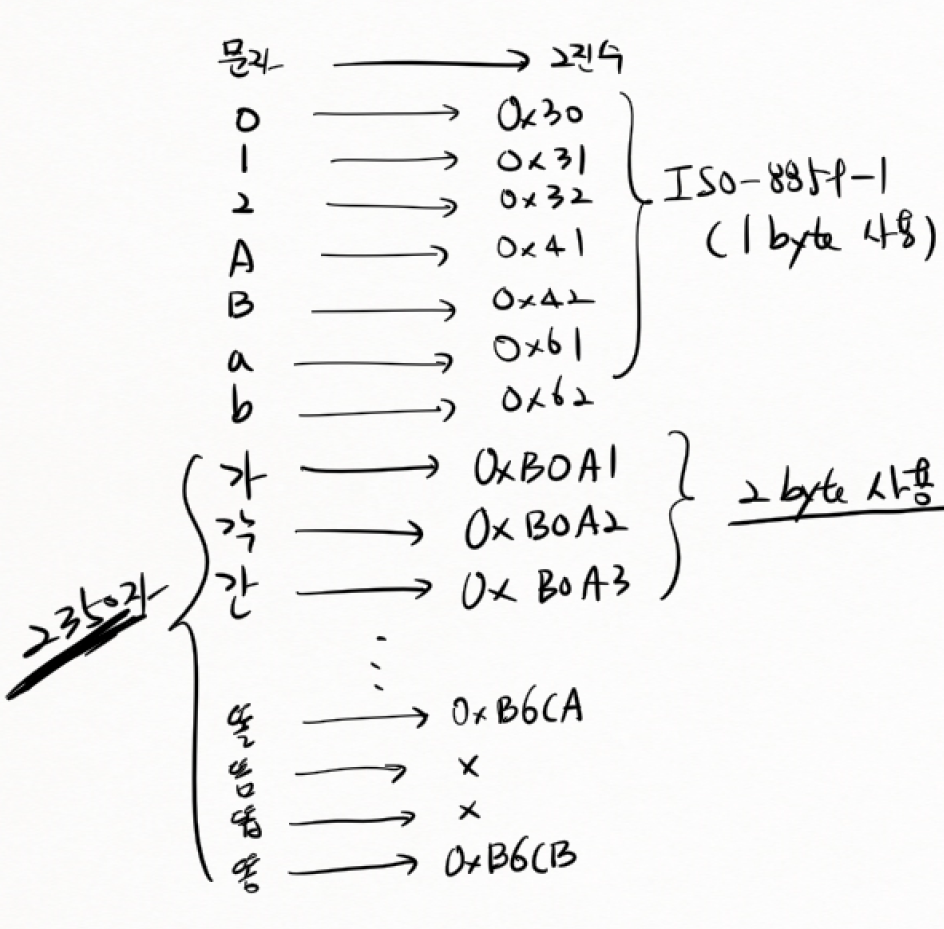
-
2350자가 정의될 당시엔 모든 한글이 다 정의되지 않았다. 따라서 숫자가 지정되지 않아 입출력이 되지 않는 경우가 있어 "똠방각하"의 경우 "또ㅁ방각하" 이런식으로만 써야 한다.
(7) 조합형
-
초성 5비트 + 중성 5비트 + 종성 5비트 = 16비트(2byte)에 저장되는 방식이다.
-
첫 비트는 구분용으로, 한글인 경우 첫 비트가 1로 시작한다.
-
Windows 3.1까지 사용했었다.

-초성, 중성, 종성에 부여된 숫자를 합해서 문자 코드를 정한다.
-가장 한글다운 방식이지만, 16비트중에서 1로 시작하는 절반의 값을 한글이 모두 사용한다. 다른 나라의 문자를 넣을 공간이 없어서 국제표준은 될 수 없다.
-국제표준이 아니므로, MS 워드등에서 사용할수 없다.
(8) MS949
-
EUC-KR 에 한글을 추가하여 만든 방식이다. (한글 합쳐서 11172자)
-
윈도우 95 부터 사용을 시작했다.
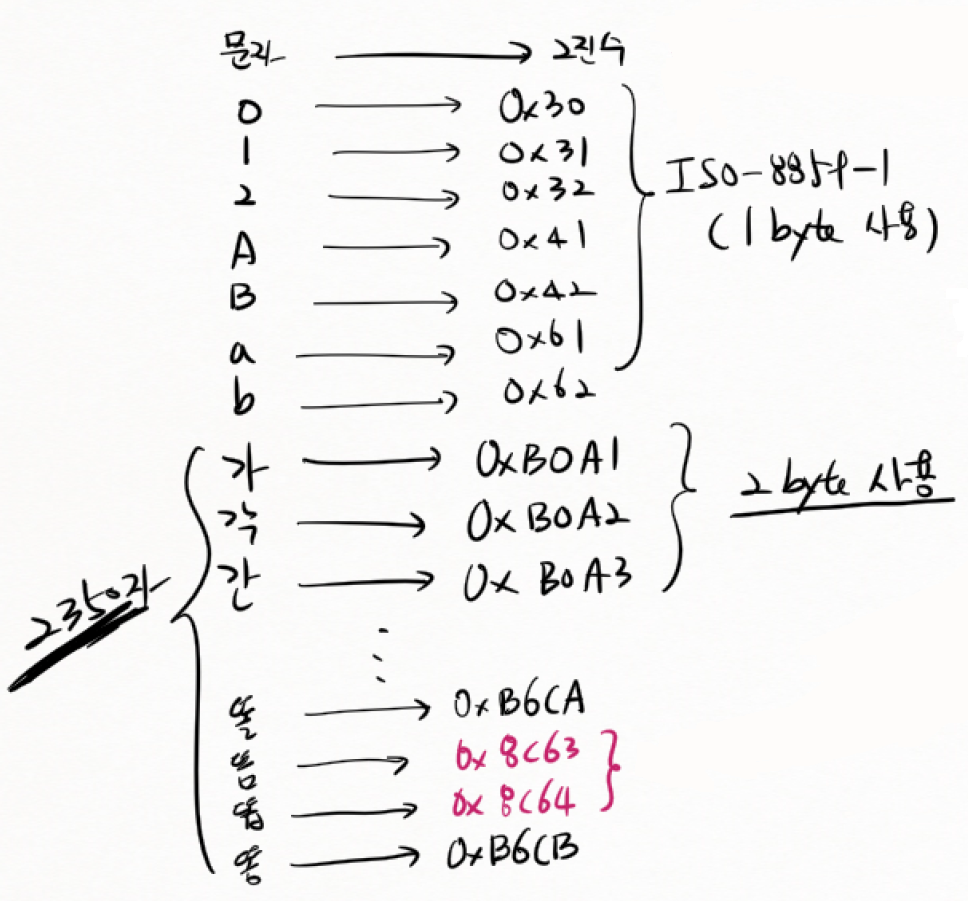
- MS949에서 새로 추가한 문자에 대해, 사용되고 있지 않은 번호를 부여했다.
-- 그래서 번호가 순서대로 부여되지 않는다.
-- 대신 기존 EUC KR 규칙과 호환된다. 즉, MS949규칙에 따라, 문자를 저장 하더라도, EUC-KR에 정의된 문자는 기존과 같은 번호를 사용한다. 대신 일련번호가 좀 뒤죽박죽일 수 있다.
(8) unicode (UTF-16) = ucs2
- 한글, 영어 모두 2바이트로 저장된다.
-> 기존의 ISO 8859-1 문자도 2바이트 숫자를 사용한다.
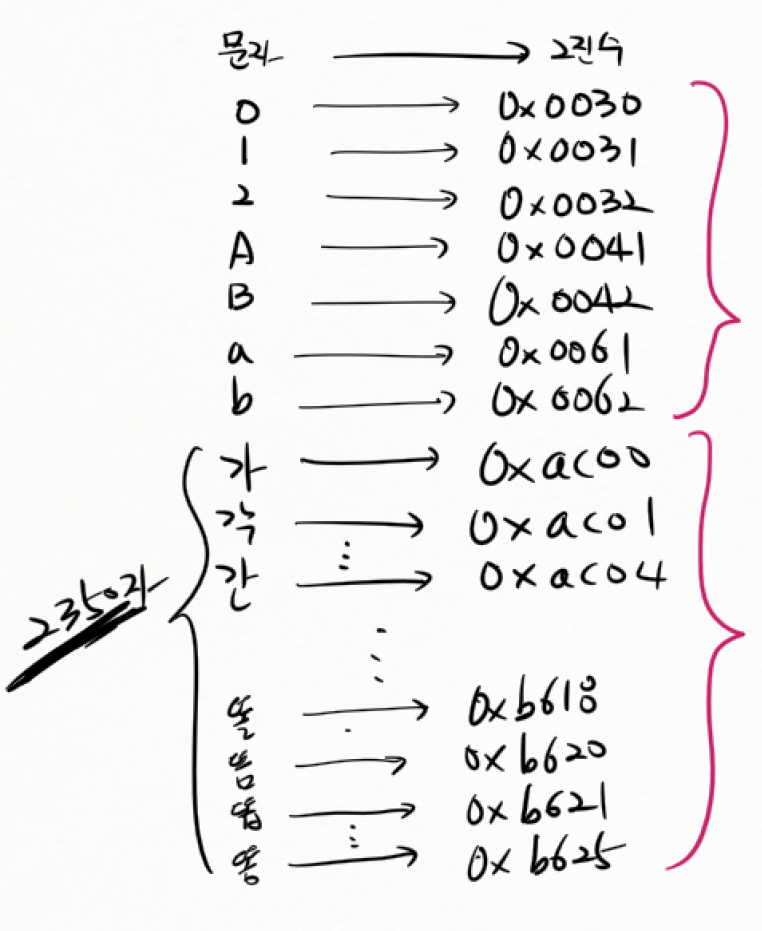
- 11172자의 한글 음절에 대해 새로 번호를 부여했다.
-> EUC-KR과 호환되지 않는다.
(9) unicode (UTF-8)
-
8비트 숫자로 정의 가능한 것은 그대로 8비트를 사용한다.
-
ISO-8859-1 문자를 예전처럼 1바이트 사용
-> 영어권에서는 유니코드를 처리하기 위해 따로 작업할 필요가 없으며, ISO-8859-1과 호환된다.
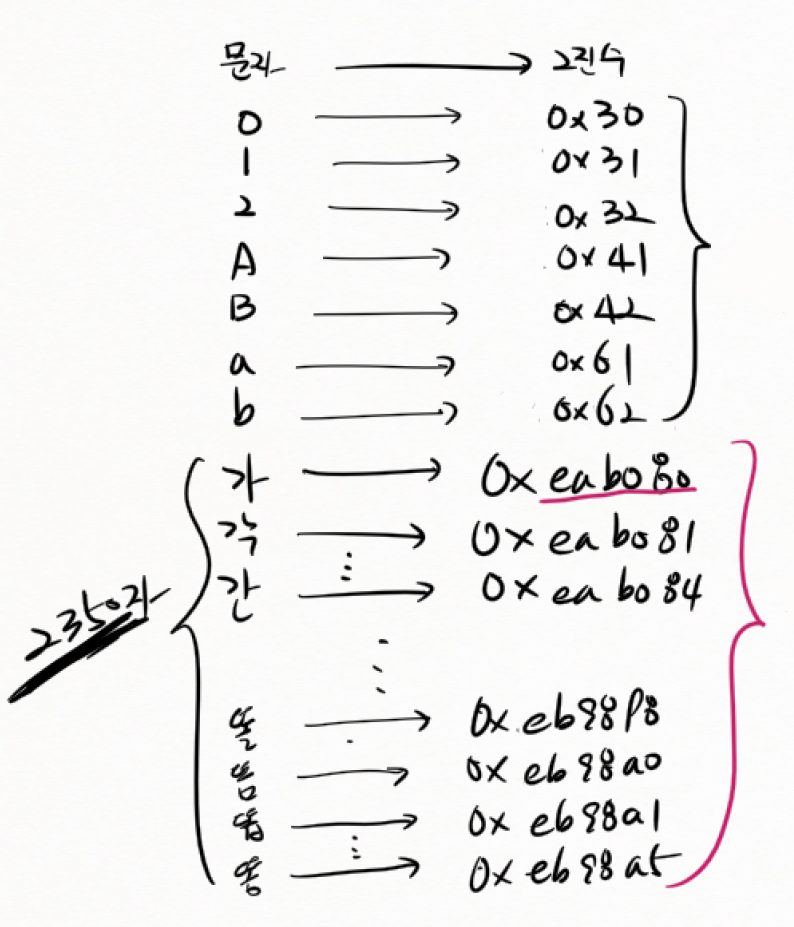
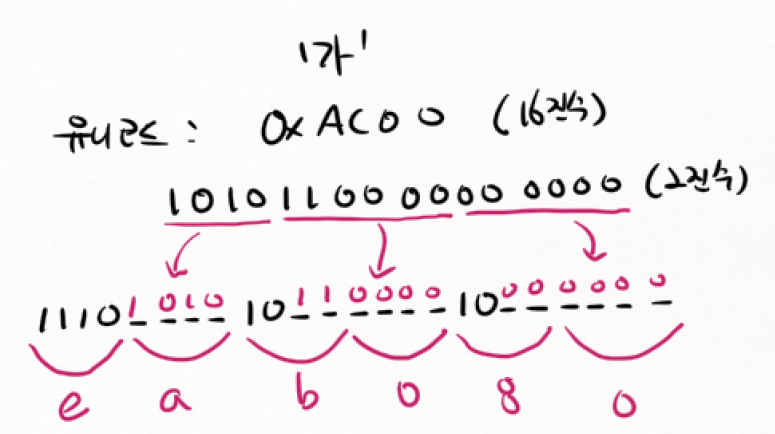
- 한글의 경우는, 한글의 utf-8 변환규칙에 따라 유니코드를 변환한다.
=> 2바이트 -> 3바이트 메모리 증가.
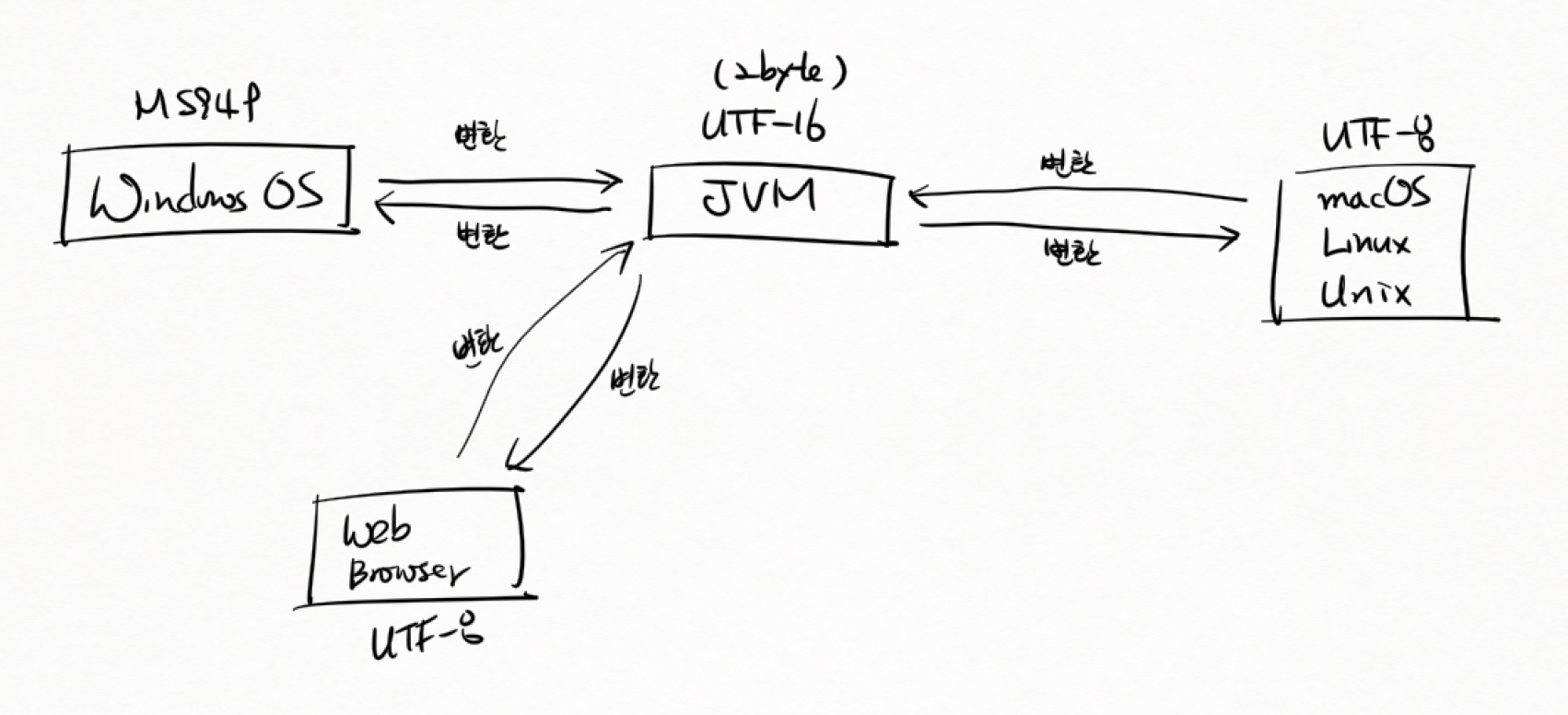
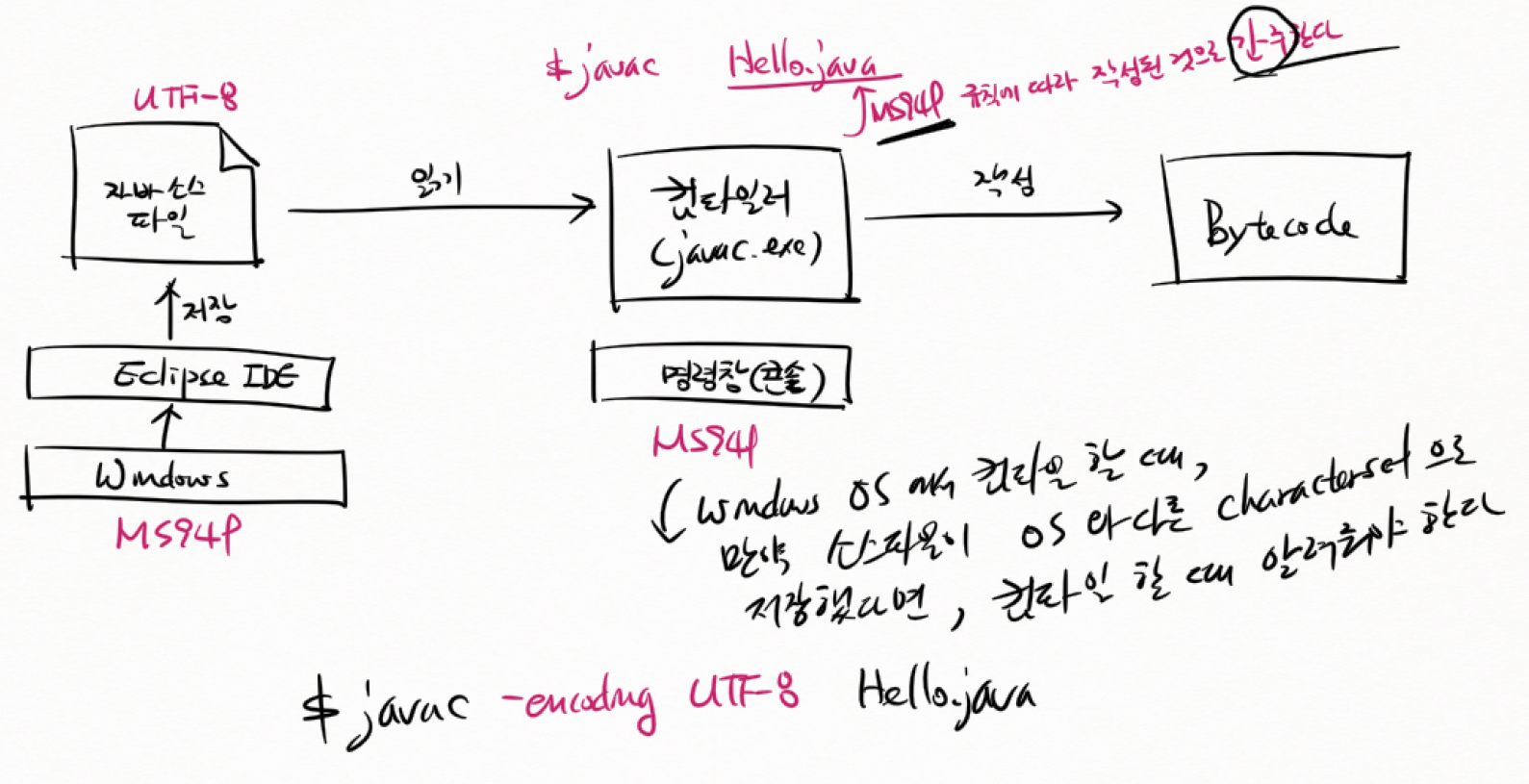
(10) JVM과 OS의 문자집합
(11) 컴파일과 문자집합
-
MAC OS
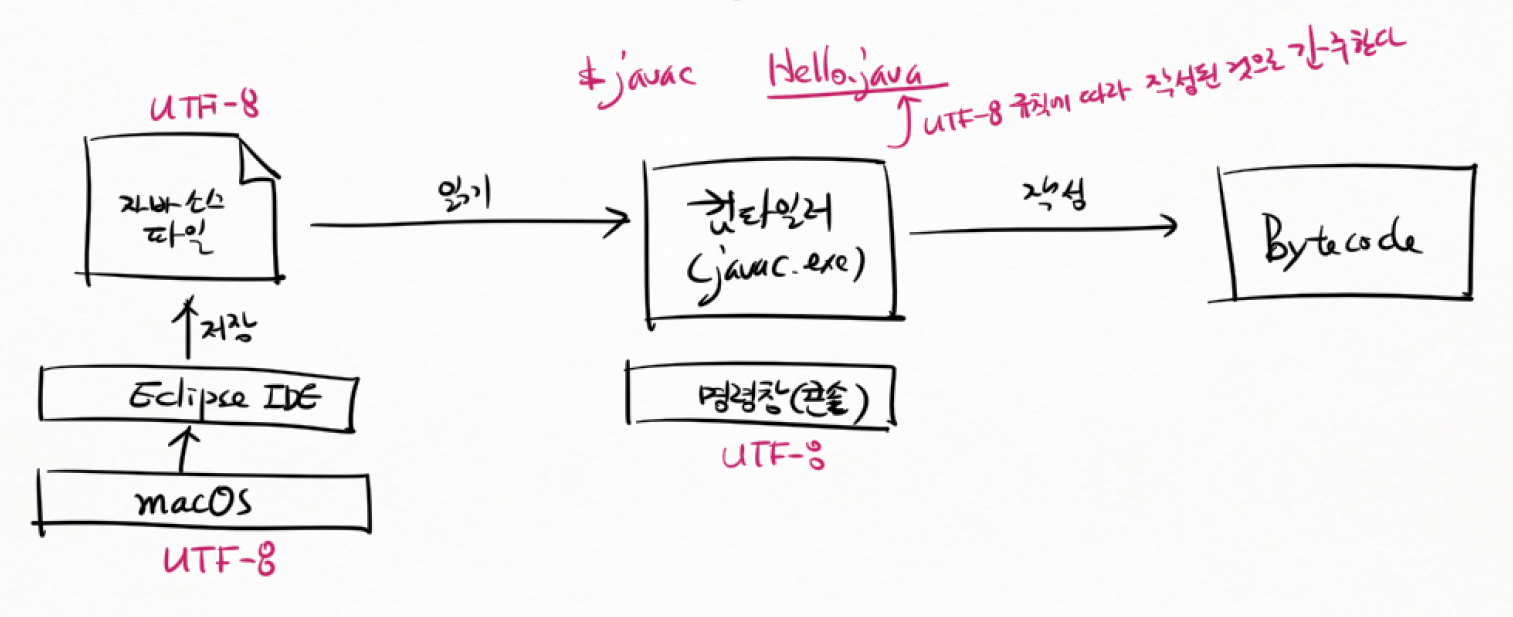
-
WINDOWS
(12) 제어코드
-
제어 명령을 수행하는 명령어 또한 숫자의 형태로 저장된다.
-
줄바꿈은 윈도우에서 0D0A,리눅스, 유닉스에서 0A로 표기되고,
전자를 CRLF (Carrage Return , & Line Feed) 후자를 LF라 한다. -
CR과 LF는 타자기의 동작을 모방한 것이다.
CR : 커서가 맨 왼쪽으로 이동
LF : 줄 한 줄 아래로 감 -
탭, 백스페이스 등등 모두 값이 있다.
(13) 변수 정의의 이유
-
4바이트에 값을 저장하고 나면, 이걸 정수, 부동소수점, 혹은 2개의 문자로 읽는지 알 수가 없다.
-
메모리에 저장된 값에 대해 정보가 주어지지 않으면 어떻게 읽어야 될지 알 수 없으므로, 값을 담는 메모리인 변수로 구분한다.
-
int v; 4바이트, 정수
long v; 8바이트, 정수
float v; 4바이트, 부동소수점
double v; 8바이트, 부동소수점
char v; 2바이트, utf-16 코드값
boolean v; 4바이트, true & false를 가리키는 숫자
byte v; 1바이트
short v; 2바이트 -
boolean의 경우 1바이트가 아니다.
--java SE 17에서도 몇바이트인지 써놓지 않았음.
--JVM Spec에선 boolean을 따로 고려하지 않았음.
--하나면 JVM의 int 데이터 타입의 값을 사용
--배열로 다루면 각각의 boolean은 byte 데이터 타입의 값을 사용.
